
VisDom: Sparse Novel View Synthesis with Visible Domain Constraint
Source: arXiv:2606.20531 · Published 2026-06-18 · By Mariia Gladkova*, Tarun Yenamandra*, Edmond Boyer, Robert Maier, Tony Tung, Daniel Cremers
TL;DR
This paper addresses the challenge of novel view synthesis (NVS) from sparse input views, where existing methods like NeRF and Gaussian Splatting (GS) struggle due to ambiguous 3D geometry recovery and artifacts caused by weak spatial constraints. Traditional visual hulls, built from multi-view silhouettes, are known but tend to overestimate object volumes especially in sparse-view scenarios, leading to degraded reconstructions. The authors propose VisDom, a learning-free geometric constraint that augments visual hull construction by requiring that voxels be observed by at least K views (the "visible domain"), drastically tightening the shape prior. VisDom can be applied as a preprocessing filter to restrict volumetric samples for NeRFs and guide Gaussian placement in GS, with no learned parameters and minimal computational overhead. Evaluations on three challenging datasets (MipNeRF360, Omni3D, ActorsHQ) demonstrate significant quantitative gains (up to 90% PSNR improvement at 4 views) and qualitative improvements in sparse settings, resurrecting general-purpose methods which otherwise fail and improving sparse-specific baselines. VisDom also achieves training time reductions of 10–22× compared to prior state-of-the-art sparse NVS models like GaussianObject. The method is domain-agnostic and requires only silhouettes, making it a broadly useful spatial regularizer to complement or replace learned priors in sparse view reconstruction.
Key findings
- Applying VisDom constraint raises PSNR of ZipNeRF from 12.44 to 24.10 dB at 4 views on MipNeRF360 (~90% PSNR gain).
- VisDom improves all tested methods, including CoR-GS and 3DGS-GO, with CoR-GS+VD achieving best mean PSNR on MipNeRF360, and 3DGS-GO+VD leading on Omni3D and ActorsHQ.
- 3DGS-GO+VD trains in 2 minutes per scene, 10× faster than Instant-NGP+VD and 22× faster than GaussianObject+VD, while maintaining or improving reconstruction quality.
- Silhouette-only constraints (+mask) sometimes degrade PSNR compared to vanilla NeRF training under extreme sparsity; VisDom constraint (+VD) avoids this failure by removing ambiguous volume.
- Increasing the minimum number K of observing cameras from 1 to 3 substantially improves visual hull tightness, with K=3 providing best average PSNR balance without overcarving.
- VisDom requires only 2-second visual hull computation as preprocessing and adds zero learned parameters or training overhead.
- VisDom remains effective and complementary when added on top of learned-prior-based methods like GaussianObject, especially on out-of-distribution data like humans where learned priors degrade.
- Qualitative evaluations show VisDom reduces floating artifacts and enforces coherent geometry across views, producing sharper object reconstructions.
Threat model
N/A — the paper addresses an ill-posed 3D reconstruction problem rather than an adversarial security threat model. The "adversary" is the fundamental ambiguity arising from sparse inputs, and the approach counters geometric uncertainty rather than malicious attacks.
Methodology — deep read
The authors tackle sparse-view novel view synthesis where there is extreme ambiguity in reconstructing 3D scenes from few images. The adversary scenario here is the inherent ill-posed nature of recovering geometry from sparse input without additional cues. The data used includes three real-world object- and human-centric datasets: MipNeRF360, Omni3D, and ActorsHQ. Input consists of posed RGB images and multi-view silhouettes, either ground truth masks or from segmentation models. The method builds upon classical visual hull techniques that carve a 3D voxel grid consistent with silhouettes from multiple views. Unlike traditional visual hulls which consider occupancy if visible in any view (K=1), VisDom requires a voxel to be observed by at least K views (minimum multi-view visibility) to be considered part of the volume, forming a "visible domain" subset of the visual hull. This suppresses large ambiguous volumes that silhouettes alone cannot disambiguate under sparse views.
The pipeline first computes the visible domain visual hull using voxel-based occupancy and visibility votes, enforcing that occupancy votes ≥ 95% of visibility votes and visibility count ≥ K (typically K=3). Marching cubes extracts meshes from the voxelized visible domain hull.
For integration with neural volumetric radiosity fields (NeRF), the ray sampling bounds along each camera ray are restricted to intersections with the visible domain hull, reducing volumetric sampling in ambiguous space. The authors apply this to ZipNeRF and Instant-NGP models, adding a silhouette binary cross-entropy loss for masks and optimizing the standard photometric losses.
For explicit 3D Gaussian Splatting (3DGS), VisDom guides initialization by restricting the Gaussian placements to the visible domain hull and applies silhouette mask losses on novel interpolated views to penalize opacity outside the hull, preventing floating artifacts.
Training uses original hyperparameters of the base methods, with silhouette loss weighting λ=0.1 for NeRF and λ2=0.1, λ3=0.01 for 3DGS. Training occurs on an RTX 4090 GPU with no additional overhead as the visible domain hull is computed once (2 seconds).
Evaluation benchmarks VisDom-enhanced models against sparse-specific NVS baselines like VaxNeRF, ZeroRF, SplatFields, FSGS, CoR-GS, and GaussianObject on three datasets with 4 to 12 views. Metrics include PSNR for photometric accuracy. Ablations vary the minimum camera count K for the visible domain. Qualitative results show visual artifact reduction and geometry consistency.
Reproducibility: The authors use publicly known datasets and standard segmentation masks but do not explicitly state released code or pretrained weights. VisDom itself requires no learning, so reproducibility depends on base NeRF/3DGS codebases. Key novel components are well described and computational overhead minimal.
Technical innovations
- Definition of visible domain constraint that tightens classical visual hull by requiring voxels to be observed by at least K (>1) cameras, removing ambiguous regions from sparse silhouettes.
- Plug-and-play integration of visible domain constraint into NeRF volumetric sampling by clipping ray sampling bounds to visible domain intersections.
- Extension of visible domain constraint to explicit 3D Gaussian Splatting by restricting Gaussian placement and applying novel silhouette mask loss on interpolated views.
- Demonstration that silhouette-only losses degrade sparse reconstructions due to overly permissive visual hulls, while VisDom overcomes this without learned priors.
- Efficient, learning-free preprocessing step (2 seconds) that imposes strong geometric priors with zero additional model parameters or training overhead.
Datasets
- MipNeRF360 — 4-9 views per scene — public benchmark with diverse object and large-scale scenes
- Omni3D — 4-9 views per scene — large-scale 3D object detection in the wild
- ActorsHQ — 5-12 views per scene — human-centric 3D reconstruction dataset
Baselines vs proposed
- VaxNeRF (Instant-NGP base): PSNR = 18.14 (4 views on MipNeRF360) vs CoR-GS+VisDom: 24.04
- ZeroRF: PSNR = 14.17 vs CoR-GS+VisDom: 24.04 (MipNeRF360, 4 views)
- SplatFields: PSNR = 22.24 vs CoR-GS+VisDom: 24.04 (MipNeRF360, 4 views)
- GaussianObject (GO): PSNR = 30.37 vs 3DGS+VisDom: 30.32 (Omni3D, 4 views)
- ZipNeRF vanilla: 12.44 dB PSNR vs ZipNeRF+VisDom: 24.10 dB (MipNeRF360, 4 views)
- Instant-NGP vanilla: 13.67 dB vs Instant-NGP+VisDom: 21.53 dB (MipNeRF360, 4 views)
- 3DGS-GO vanilla: 23.53 dB vs 3DGS-GO+VisDom: 24.06 dB (ActorsHQ, 5 views)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.20531.

Fig 1: Our learning-free geometric constraint, derived purely from silhouettes, enables

Fig 2: Visual hull reconstruction in 2D (left part) and top-view in 3D (right part). Left
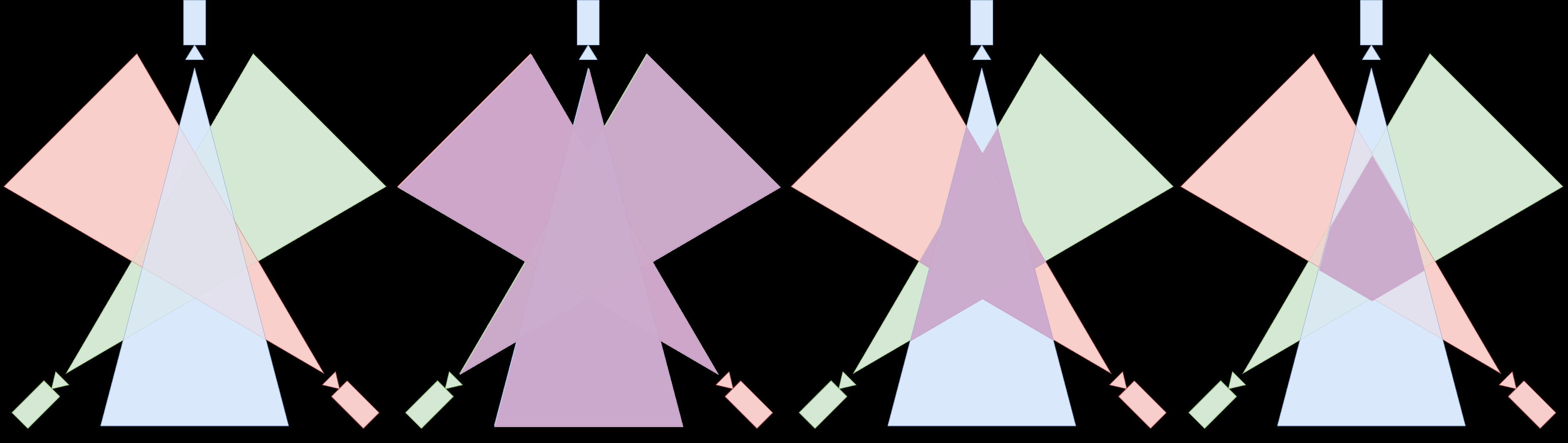
Fig 3: A 2D example of the visible domain

Fig 4: Our VisDom visual hull (left)

Fig 5 (page 6).
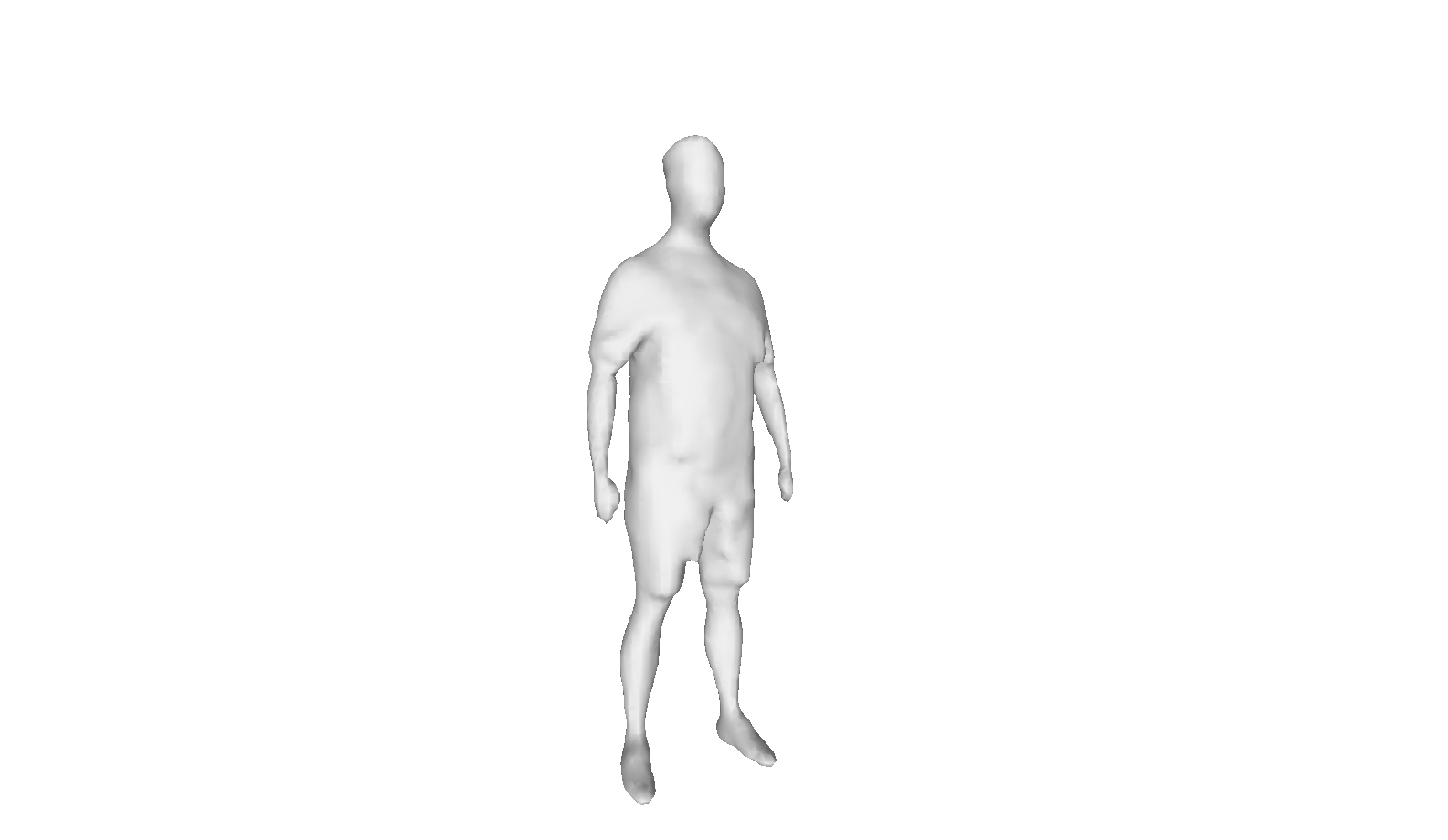
Fig 6 (page 6).
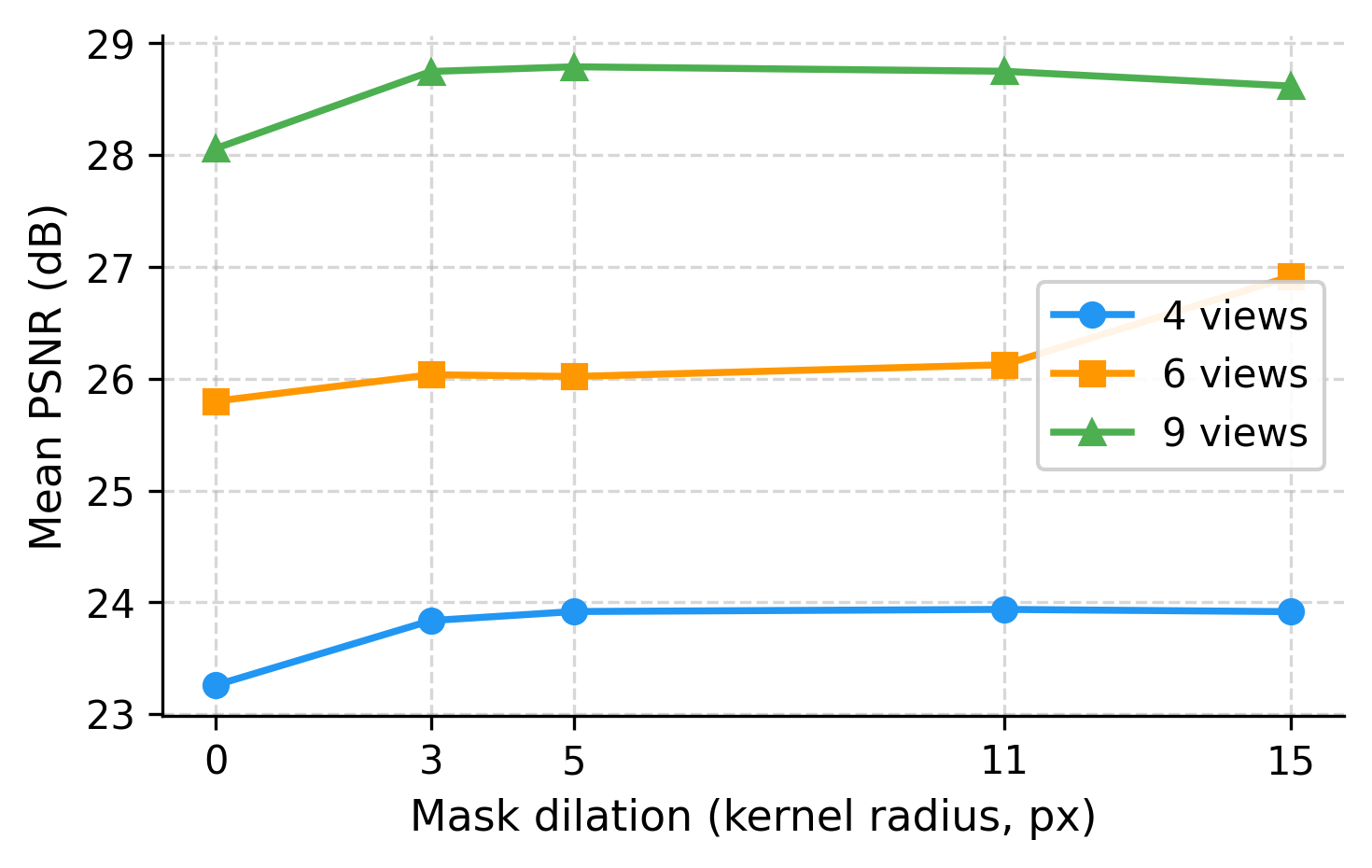
Fig 7: Effect of mask dilation on ZipNeRF + VisDom for MipNeRF360 dataset, mea-

Fig 8: Qualitative results of the visual hull reconstructed using different algorithms,
Limitations
- VisDom effectiveness degrades below 4 input views; silhouettes become too sparse for reliable hulls.
- Geometric constraints alone insufficient in scenes with strong inter-view lighting variation, limiting reconstruction quality without generative priors.
- The visible domain is limited by silhouette quality; errors or noise in segmentation masks propagate into hull inaccuracies.
- No evaluation of robustness to adversarial or erroneous camera pose estimates.
- Does not recover concavities or fine geometric details not visible in silhouettes due to inherent visual hull limitations.
- K parameter selection requires manual tuning to balance under- and over-carving; no automatic method proposed.
Open questions / follow-ons
- How does VisDom perform with noisy or imperfect silhouette masks in real-world uncontrolled settings?
- Can the visible domain constraint be integrated with learned generative priors to push sparse reconstructions below 4 views?
- What extensions enable recovery of geometric concavities or fine details beyond silhouette constraints?
- Can adaptive or dynamic selection of the minimum camera visibility parameter K improve robustness across diverse capture setups?
Why it matters for bot defense
For bot-defense and CAPTCHA systems involving novel view synthesis as a challenge or defense mechanism, VisDom offers a simple, parameter-free geometric constraint that significantly reduces artifacts and ambiguities from sparse multi-view input. Applying visible domain constraints can improve the fidelity and consistency of synthesized views from few inputs without requiring expensive learned priors, reducing training time and complexity. This could benefit CAPTCHA schemes that rely on generating or verifying consistent novel views under limited camera conditions or partial observations. Furthermore, because VisDom requires only silhouettes and no additional learned parameters, it can be integrated as a lightweight preprocessing or filtering step to strongly regularize geometry reconstruction, potentially making automated spoofing or adversarial manipulation more difficult by enforcing multi-view consistent 3D geometry. In short, VisDom provides an effective geometric regularizer to improve view synthesis robustness in sparse data regimes relevant to 3D CAPTCHA challenges and defenses.
Cite
@article{arxiv2606_20531,
title={ VisDom: Sparse Novel View Synthesis with Visible Domain Constraint },
author={ Mariia Gladkova* and Tarun Yenamandra* and Edmond Boyer and Robert Maier and Tony Tung and Daniel Cremers },
journal={arXiv preprint arXiv:2606.20531},
year={ 2026 },
url={https://arxiv.org/abs/2606.20531}
}