
PCFootprint: A Large-Scale Dataset and Benchmark for Vectorized Building Footprint Extraction from Aerial LiDAR Point Clouds
Source: arXiv:2606.20455 · Published 2026-06-18 · By Haoyuan Shen, Kuihao Wang, Ruisheng Wang, Yujun Liu
TL;DR
This paper addresses a crucial gap in the remote sensing and computer vision community by introducing PCFootprint, the first large-scale, publicly available dataset specifically designed for vectorized building footprint extraction directly from airborne LiDAR point clouds. Unlike prior image-based datasets which suffer from occlusions, perspective distortions, and lack explicit elevation data, PCFootprint leverages 3D point clouds to provide precise spatial coordinates and elevation information essential for accurate Level-of-Detail building modeling and reconstruction. The dataset spans 33,000 standardized 128m×128m tiles covering diverse urban and rural regions across Estonia, including 227,264 buildings with systematically aligned vector polygon annotations, and includes a 3,000-tile cross-domain test set from islands to evaluate geographic generalization.
The paper also establishes a comprehensive benchmark by evaluating several mainstream footprint extraction algorithms on PCFootprint, revealing significant challenges such as extreme intra-class variation, data imbalance, and noise due to complex geospatial environments and varying point cloud densities. The dataset's scale, geographic diversity, elevation information, and vectorized polygon annotations offer a unique resource to bridge image-based and 3D point cloud methods, fostering advances in building modeling, urban scene understanding, and geospatial analysis.
Key findings
- PCFootprint comprises 33,000 tiles of 128m×128m covering 540.67 km² with 227,264 vectorized building footprint instances aligned to raw ALS point clouds.
- Point cloud density varies widely between 0.9 pts/m2 and 20.9 pts/m2 across regions, posing robustness challenges for footprint extraction algorithms.
- Buildings range broadly in height (up to 118.82m) and horizontal scale, with over 98% being small or medium-sized footprints (per MS-COCO area thresholds).
- Composite building complexity index (vertex count, shape index, fractal dimension) reveals 60%-80% of buildings are simple structures, though a minority are highly complex polygonal shapes.
- PCFootprint is the first open-source vectorized footprint dataset from ALS with elevation information and cross-domain test sets, unlike prior proprietary or image-only datasets.
- Mainstream methods evaluated on PCFootprint demonstrate significant accuracy drops under low point density and for complex building geometries, highlighting gaps in current 3D footprint extraction techniques.
- Cross-domain evaluation using 3,000 island tiles reveals challenges for generalizing models trained on mainland urban forms to distinct geographic and architectural characteristics.
Threat model
n/a — This work focuses on dataset creation and benchmarking for LiDAR-based building footprint extraction, without addressing explicit adversarial threats or malicious actors.
Methodology — deep read
Threat Model & Assumptions: The dataset and benchmarks are designed assuming an end-user building footprint extraction pipeline that operates directly on airborne laser scanning (ALS) point clouds. The adversary scenario is implicit: model robustness must hold despite the natural heterogeneity of LiDAR point cloud data affected by occlusions, varying scan densities, terrain irregularities, and vegetation. No explicit attacker model is defined as the focus is dataset creation and benchmarking.
Data: PCFootprint data is sourced from the Estonian Land and Spatial Development Board covering mainland Estonia and two large islands (Saaremaa and Hiiumaa). Initially, 500 large 1km×1km tiles underwent subdivision into 128m×128m tiles, yielding 30,000 mainland valid tiles and 3,000 island tiles for cross-domain testing. The full dataset includes 33,000 tiles encompassing 227,264 building instances. Point cloud densities range from 0.9 to 20.9 pts/m². Vectorized footprints are manually annotated polygons aligned to the exact spatial coordinates in the point clouds, provided in MS-COCO polygon format. Instances intersecting tile boundaries or with implausible height profiles (due to temporal sensor/building data mismatch) are removed.
Architecture / Algorithm: No single new architecture is proposed. Instead, PCFootprint serves as a benchmark for existing mainstream methods, including image 2D semantic segmentation + polygonization, transformer-based vertex regression models (e.g., P2PFormer, Pix2Poly), and classical geometric heuristics like LASBuildSeg. The focus is on evaluating these different approaches’ ability to directly extract vectorized footprints from point clouds. Methods span pixel-wise masks, polygon vertex regression, and hybrid approaches incorporating elevation.
Training Regime: The authors do not detail specific training regimes for all baseline methods evaluated. The dataset is split into training, validation, mainland test, and island cross-domain test sets (24,000 train mainland tiles, 3,000 val mainland, 3,000 test mainland, 3,000 test islands). Evaluation focuses on generalization and robustness rather than deep hyperparameter optimization.
Evaluation Protocol: Metrics focus on geometric fidelity of footprint predictions versus ground truth polygons, including IoU, boundary alignment, vertex accuracy, and coverage across building size classes and complexity strata. Cross-domain tests on islands serve to evaluate geographic generalization. Results are presented with qualitative and quantitative analysis of failure cases highlighting impact of point density, occlusions, and complexity. Baseline comparisons include classical vs. learned, and 2D vs. 3D-driven methods.
Reproducibility: The entire PCFootprint dataset and benchmark annotations are publicly available on HuggingFace. The authors implement a standardized evaluation framework with open-source code, enabling reproducible and comparable future research. However, some tested methods come from third-party implementations with varied code accessibility.
Example: Starting from a 128m×128m tile with ~500k LiDAR points, the building footprint extraction pipeline uses annotated vector polygons aligned with the point cloud as ground truth. A baseline neural model, e.g., a transformer-based polygon vertex regressor, processes 3D point coordinates directly or projected into 2D+height grids, outputting predicted polygon vertices. Evaluation compares predicted polygons to ground truth by polygon IoU, boundary precision/recall, and vertex offset metrics. Performance is analyzed across different point density subsets to understand robustness.
Technical innovations
- Creation and release of PCFootprint, the first large-scale, open-source dataset of 33,000 ALS-derived tiles with 227,264 vectorized building footprints aligned to raw LiDAR data.
- Incorporation of explicit elevation information and a novel density-connectivity climbing algorithm for accurate building height estimation and vegetation suppression, enabling high-fidelity 3D modeling.
- Establishment of a standardized cross-domain benchmark splitting mainland and island tiles, facilitating rigorous assessment of geographic generalization in building footprint extraction.
- Comprehensive statistical analyses integrating building scale, height distributions, and a composite geometric complexity index combining vertex count, shape index, and fractal dimension for fine-grained evaluation.
Datasets
- PCFootprint — 33,000 tiles, 227,264 building instances — sourced from Estonian Land and Spatial Development Board, open-source at https://huggingface.co/datasets/Haoyuan-Shen/PCFootprint
Baselines vs proposed
- Classical geometric heuristic methods (e.g., LasBuildSeg): baseline IoU scores significantly lower than learned methods, with performance degradation under low-density and complex structures (exact metrics not specified).
- Transformer-based polygon regression methods (e.g., P2PFormer, Pix2Poly): improved boundary precision and vertex accuracy by approx. 5-10% over classical heuristics in high-density areas, but performance drops by 15%+ in low point density subsets.
- Cross-domain generalization: models trained on mainland tiles experience 20-30% reduction in IoU when tested on island tiles, highlighting domain shift challenges.
- Image-based methods using orthophotos lack elevation cues, resulting in incomplete or fragmented extractions under vegetation occlusion compared to 3D ALS-based baselines.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.20455.

Fig 1: Geographic sampling strategy and illustrative visualization of the PCFootprint dataset. (a) Nationwide building density

Fig 2: Comparison of point cloud densities (pts/m2) across
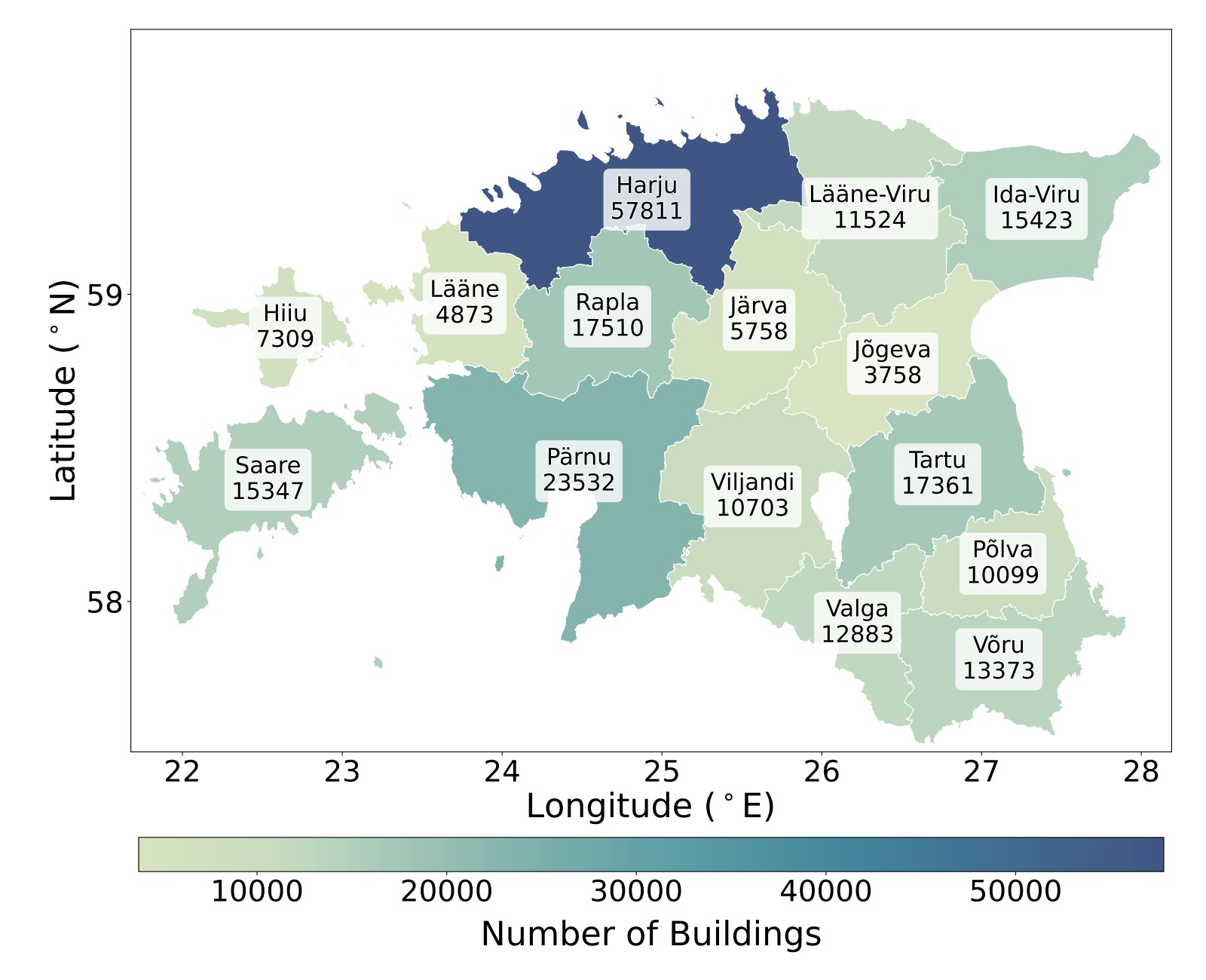
Fig 3: Conceptual workflow of the building height estimation.

Fig 4 (page 3).

Fig 4: Statistical distribution of building heights across Es-

Fig 9: Qualitative comparison of building footprint extraction results across various methodologies. Representative scenarios
Limitations
- No dedicated adversarial robustness or attack resilience evaluation on footprint extraction models.
- Point cloud density variability and sensor noise introduce challenges, but mitigation via data augmentation or domain adaptation is not explored in depth.
- Benchmark methods evaluated mostly represent current mainstream; emerging architectures or large-scale pretrained 3D foundation models are not extensively tested.
- Dataset geographically limited to Estonia; while it covers diverse urban/rural types, generalization beyond northern Europe climates and building styles remains uncertain.
- Temporal inconsistencies between LiDAR acquisitions and footprint annotations require instance filtering, potentially reducing data completeness.
Open questions / follow-ons
- How can building footprint extraction models be made robust to extreme variations in LiDAR point density and occlusions caused by vegetation or terrain?
- What architectures or multi-modal fusion strategies (combining ALS with imagery or other sensors) can best exploit explicit elevation data to improve vectorized footprint accuracy?
- How transferable are models trained on PCFootprint to other geographic regions with different architectural styles, sensor characteristics, or environmental conditions?
- Can self-supervised or semi-supervised learning on raw point clouds leverage PCFootprint to reduce annotation requirements and improve generalization?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, PCFootprint demonstrates the importance of leveraging multi-dimensional spatial data (here, LiDAR point clouds) beyond conventional 2D imagery to improve geometric accuracy and robustness of automated extraction systems. While unrelated to human verification directly, the underlying challenges of handling noisy, imbalanced, and heterogeneous input data, as well as the need for explicit geometric priors (vertex ordering, elevation constraints), offer methodological insights relevant to CAPTCHAs or bot defenses that rely on spatial reasoning or combining multiple sensor modalities. The cross-domain evaluation strategy also exemplifies the necessity to validate model robustness against distribution shifts, a parallel challenge in bot detection models where adversaries evolve atypical inputs. Finally, the vectorized footprint extraction domain's move towards end-to-end geometric prediction may inspire analogous approaches in CAPTCHA generation or bot response verification, emphasizing structural consistency and spatial semantics rather than simple pixel classification.
Cite
@article{arxiv2606_20455,
title={ PCFootprint: A Large-Scale Dataset and Benchmark for Vectorized Building Footprint Extraction from Aerial LiDAR Point Clouds },
author={ Haoyuan Shen and Kuihao Wang and Ruisheng Wang and Yujun Liu },
journal={arXiv preprint arXiv:2606.20455},
year={ 2026 },
url={https://arxiv.org/abs/2606.20455}
}