
JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
Source: arXiv:2606.19830 · Published 2026-06-18 · By Jianwen Sun, Chuanhao Li, Zizhen Li, Yukang Feng, Fanrui Zhang, Yifei Huang et al.
TL;DR
This paper addresses the gap in AI-driven game development regarding project-level code engineering on professional game engines by introducing JamSet and JamBench, the first large-scale dataset and benchmark tailored for professional-grade game engine code generation. The authors leverage the Godot engine's text-based project format and its headless execution mode to design a deterministic verification pipeline that filters and verifies 8,133 high-quality, runnable open-source projects from an initial pool of over 240,000 repositories collected primarily from Game Jam competitions. They curate JamBench, a manually verified subset of 300 projects, which is used to define theme-driven generation and code completion tasks, evaluated with new metrics capturing both static code structure and runtime behavior alignment. Evaluation of 9 state-of-the-art models reveals a significant performance drop as project scale increases, and while Code Agents improve compilation rates substantially, they fail to improve runtime behavioral quality, highlighting that current models struggle more with architectural and semantic correctness than syntax. Fine-tuning on JamSet data demonstrates measurable improvements in compilation success and structural completeness.
The core contributions are the construction of a large verified dataset for project-level game code, a fully automated and deterministic evaluation methodology for game projects using runtime behavior, and empirical insights showing the limits of current LLMs and Code Agents on complex, multi-file game projects. Collectively, this work provides an essential resource and evaluation framework for advancing AI game code generation on professional engines beyond simple asset or mini-game tasks.
Key findings
- From 240,000+ candidate repositories, only 8,133 projects (3.4%) pass a strict multi-level verification pipeline covering file integrity, compilation, and 30s runtime stability.
- JamBench, a 300-project manually verified subset, achieves 100% pass rate under verification, forming a reliable benchmark for evaluation.
- Runtime compilation pass rates for state-of-the-art LLMs drop sharply from 80.4% on small projects to 5.7% on large projects in function-level code completion (Task 2a).
- Code Agents boost compilation verification pass rates by over 30 percentage points but do not improve Structural Completeness Scores (SCS) or Behavioral Alignment Scores (BAS).
- Structural Completeness Score (SCS) and Behavioral Alignment Score (BAS) reveal models frequently generate runnable shell projects lacking proper behavioral functionality.
- Fine-tuning Qwen3.5-27B on JamSet increases input action abstractions from 0.08 to 3.44 per project and autoload script usage from 55.1% to 77.1%, reflecting improved engineering practices.
- Function-level completion (Task 2a) demands higher contextual precision than script-level (2b) or full-script-level (2c) completion, contrary to intuitive difficulty assumptions.
- Deterministic behavior collection over 60 seconds using rule-based input strategies enables scalable, reproducible assessment of runtime behavior alignment.
Threat model
The adversary is an AI-driven generative model producing multi-file Godot game projects, attempting to generate compilable and runnable games matching given themes or completing missing parts in real projects. The adversary lacks ability to intervene in the deterministic verification pipeline or modify runtime environment beyond standard code generation. It cannot manipulate evaluation inputs, external dependencies, or privileged engine internals. The goal is to evaluate how well AI models can autonomously produce high-quality, architecturally sound game code frameworks under these constraints.
Methodology — deep read
The authors first define a threat model targeting AI-driven generation of complex, multi-file professional game projects on the Godot engine, assuming adversaries are generative models producing code that must compile and run correctly without relying on handcrafted test suites or subjective evaluations. They collect candidate projects from major Game Jam platforms (Ludum Dare, itch.io, Global Game Jam, GMTK, Godot Wild Jam, etc.) and GitHub, totaling over 240,000 repositories. Pre-filtering selects only 2D Godot 4.x projects with game code lines ≥ 1,200 and limited plugin dependencies based on correlation to quality metrics.
The verification pipeline is a key architectural element: Level 1 checks file integrity and project structure; Level 2 compiles in Godot's headless mode detecting syntax and resource errors; Level 3a runs a 30-second headless execution with no input to verify runtime stability; Level 3b performs deterministic input-driven execution for 60 seconds collecting multi-dimensional behavior signals (nodes added/removed, events, positions, velocities, signal triggers) for Behavioral Alignment Score (BAS) calculation.
JamBench benchmark defines two main tasks: Task 1 is theme-driven from-scratch project generation with two subtasks, Task 1a provided only a theme keyword, Task 1b additionally a gameplay description. Task 2 addresses multi-granularity code completion on real projects with function-, script-, and full-script-level missing code requiring filling while preserving scene files. Evaluation includes pass rates at each verification level (L1-L3a), and quantitative metrics: Structural Completeness Score (SCS) reflecting static code structure completeness, and Behavioral Alignment Score (BAS) capturing runtime behavior similarity to references.
The dataset is split into Small (<4k lines), Medium (4k-15k), and Large (>15k) tiers. Nine state-of-the-art LLMs plus one fine-tuned model and five Code Agent configurations are evaluated across tasks. Fine-tuning is performed with LoRA on JamSet. Code Agents employ iterative multi-turn debugging to improve compilation correctness.
Metrics use detailed definitions: SCS averages ratios of generated vs reference values over seven static structural dimensions; BAS averages similarity across several runtime metrics with deterministic, rule-based input generation ensuring reproducibility. The entire pipeline automates data collection, annotation (including theme matching via embeddings, gameplay description generation by LLMs, asset annotation combining VLM and heuristics), and evaluation to ensure scalability and objective benchmarking.
Insights arise from in-depth case studies illustrating outputs with plausible but minimal code, compilation errors due to engine-specific constraints, and incorrect semantic completions. These reveal the limitations of current LLMs in mastering architectural aspects unique to game engines which JamSet training partially alleviates.
Technical innovations
- A deterministic multi-level verification pipeline leveraging Godot's headless mode to filter and evaluate project-level game code from tens of thousands of noisy open-source repositories.
- Design of Structural Completeness Score (SCS) and Behavioral Alignment Score (BAS) metrics combining static structural analysis with runtime behavior similarity for holistic, automated quality evaluation.
- Collection and curation of a large-scale project-level game code dataset (JamSet) and a manually verified benchmark subset (JamBench) from Game Jam competitions on Godot, enabling training and evaluation beyond single-file snippets.
- Use of automated rule-based deterministic input strategies, seeded by offline LLM-generated config, to collect reproducible runtime behavior data from diverse 2D games in a headless engine environment.
- Empirical demonstration that Code Agents improve compilation pass rates but not behavioral or structural completeness, emphasizing architectural design challenges over syntax correction.
Datasets
- JamSet — 7,833 projects — large-scale training dataset from verified Godot Game Jam projects
- JamBench — 300 manually verified projects — benchmark subset with detailed annotations, runtime behavior and structural labels
Baselines vs proposed
- Claude Opus 4.6 (LLM) Task 1a L3a pass rate = 77.3% vs Agent mode = 82.7%
- Gemini 3.1 Pro (LLM) Task 2a Small projects L3a pass rate = 88% vs Medium = 32% vs Large = 7%
- Qwen3.5-27B (base) Task 2a Medium L3a pass rate = 26% vs Qwen3.5-27B-SFT fine-tuned pass rate = 31%
- Code Agents increase L3a pass rates on Task 2 by over 30 percentage points but show negligible change in SCS or BAS scores
- JamSet fine-tuning improves input action count from 0.08 to 3.44 and autoload usage from 55.1% to 77.1%, indicating better engineering practices
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19830.

Fig 1: Research landscape and our proposed solution.

Fig 2 (page 1).

Fig 3 (page 1).

Fig 4 (page 1).
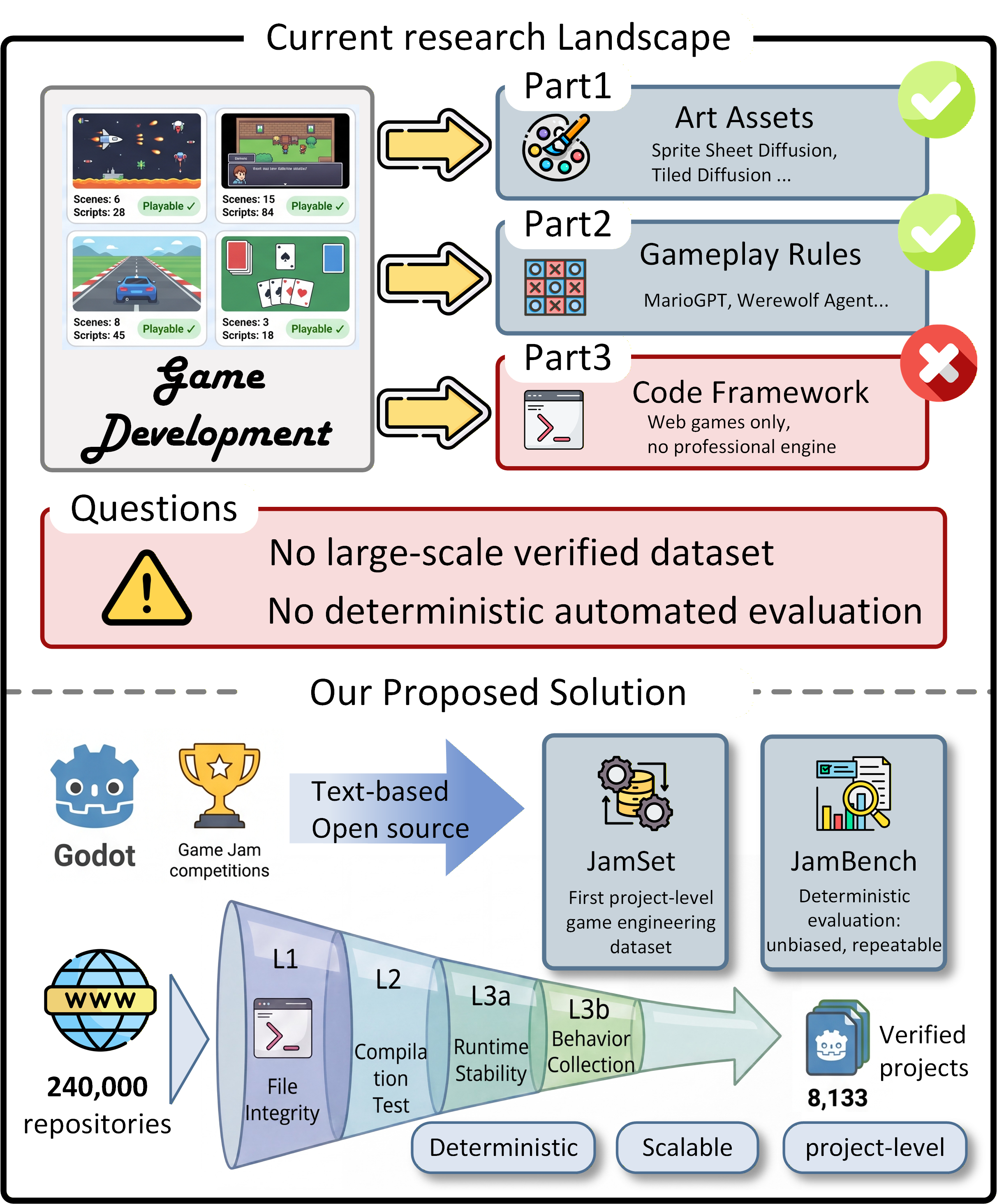
Fig 2: Overview of the GameJamBench pipeline. 1
Fig 3: (a) Engine usage trends in Game Jam repositories (2017–2025); (b) Code size vs. Ludum Dare rating; a

Fig 4: Representative case studies. Case 1 (➀➁): Passing verification but with minimal functionality. Case 2(➂):

Fig 8 (page 8).
Limitations
- Despite large-scale dataset, the focus is solely on Godot 4.x 2D projects, limiting generalization to 3D or other engines like Unreal or Unity.
- Behavioral Alignment Score depends on deterministic input strategies which may not fully cover or explore game mechanics, potentially missing some runtime behaviors.
- Evaluation tasks focus on compilation and short-duration runtime behavior; full game completion or player experience quality remains unassessed.
- Code Agents improve syntactic correctness but fail to improve architectural or semantic quality, evidencing current LLM limitations not addressed by the benchmark.
- JamBench manual verification ensures quality but is limited to 300 projects, a small fraction of total JamSet data; some noise may remain in the larger training set.
- The dataset and evaluation do not explicitly consider adversarial code generation or security risks inherent to game engine scripting.
Open questions / follow-ons
- How can models better capture architectural and cross-file semantic dependencies characteristic of large professional game projects to improve runtime behavior rather than just syntactic correctness?
- Can evaluation metrics be extended to assess deeper gameplay quality, player experience, and robustness beyond the first 60 seconds of runtime behavior?
- How well can similar datasets and deterministic pipelines be constructed and generalized to 3D games, other engines like Unreal or Unity, or different programming languages?
- What techniques beyond Code Agents, such as architectural conditioning or hierarchical generation, can bridge the identified capability cliff as project scale increases?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, this work underscores challenges in evaluating complex AI-generated software artifacts where traditional static correctness fails to capture meaningful functionality. The deterministic verification pipeline combining both static and runtime behavior analysis could inspire more robust and reproducible evaluation frameworks for AI outputs in complex environments, including CAPTCHAs or interactive bot detection games. Furthermore, the identification of a capability cliff and bottlenecks in architectural understanding suggests that AI systems manipulating multi-part codebases or game-like interactive puzzles will likely struggle beyond small scopes, guiding defensive strategies that escalate interaction complexity or require architectural coherence. JamSet and JamBench provide a potential training resource for models intended to resist or simulate human-like bot behavior within game or interactive content engines, which could be repurposed to test bot adaptability or improve CAPTCHA challenge generation for higher security.
Cite
@article{arxiv2606_19830,
title={ JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines },
author={ Jianwen Sun and Chuanhao Li and Zizhen Li and Yukang Feng and Fanrui Zhang and Yifei Huang and Yu Dai and Kaipeng Zhang },
journal={arXiv preprint arXiv:2606.19830},
year={ 2026 },
url={https://arxiv.org/abs/2606.19830}
}