
Augmenting Game AI with Deep Reinforcement Learning
Source: arXiv:2606.20210 · Published 2026-06-18 · By Alessandro Sestini, Joakim Bergdahl, Amir Baghi, Jean-Philippe Barrette-LaPierre, Florian Fuchs, Linus Gisslén
TL;DR
This paper explores the application of deep reinforcement learning (RL) to augment game AI in large-scale commercial AAA titles, specifically EA SPORTS FC 25 and Battlefield 6. The motivation is to overcome the limitations of traditional handcrafted game AI methods, such as finite state machines (FSMs), behavior trees (BTs), and goal-oriented action planning (GOAP), which are often brittle, hard to maintain, and lack realistic, human-like behaviors. The authors propose a framework for practical RL training designed around key industry constraints: short training times compatible with development cycles, modularity to integrate with existing AI systems, runtime inference constraints, and maintainability. They demonstrate case studies where RL enhances goalkeeper positioning in a football simulator and infantry locomotion in a first-person shooter. By employing techniques such as scenario-based training, replay across experiments, and compact neural networks, the RL models achieve human-like, authentic behaviors with improved performance and maintainability.
The results show that RL can outperform hand-coded AI on realism and adaptability, illustrated by a 10% increase in goalkeeper save ratio and smoother soldier locomotion trajectories resembling human players. Training time was reduced from days to feasible overnight schedules using modified SAC algorithms for the football game, and the locomotion system was trained efficiently with PPO in about 2 hours. The paper identifies bottlenecks such as expensive observation extraction, limited expressivity of occupancy maps, fine-tuning challenges, and balancing modular RL with traditional AI components. It also outlines key future research directions to bridge the gap from academic RL to production-grade, deployable game AI systems.
Key findings
- RL-augmented goalkeeper positioning in EA SPORTS FC 25 achieved a 10% higher save ratio over existing hand-coded FSM AI.
- Modified Soft Actor-Critic (SAC) training reduced training time from 4 days to ~12 hours, enabling overnight retraining compatible with development cycles.
- Fine-tuning using scenario-based learning and Replay across Experiments (RaE) allowed behavioral fixes in 2–4 hours, significantly faster than standard SAC fine-tuning.
- Battlefield 6 RL-based locomotion trained with Proximal Policy Optimization (PPO) in ~2 hours, outperforming NavMesh-based BT locomotion in producing smoother, more human-like trajectories.
- Using occupancy maps for state representation in Battlefield 6 was about 2× faster computationally than raycast observations, while achieving similar performance (Fig 4).
- The RL-based locomotion system integrated modularly as a BT leaf node, maintaining interoperability and achieving win rates comparable to hand-coded AI in 1-on-1 scenarios.
- The compact MLP network for EA SPORTS FC 25 goalkeeper inference ran within a 200 µs budget (170 µs observed), ensuring runtime efficiency for on-device deployment.
- Repeated fine-tuning risks catastrophic forgetting, highlighting a limit to iterative behavior correction using current RL techniques.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicitly the changing game environment and natural challenges in game development, requiring RL methods that cope with evolving game dynamics, limited compute, and integration with existing AI. There is no external attacker model, but constraints include limited inference time, developer control, and maintainability over time.
Data: Training data comes solely from interaction with the actual game environments (EA SPORTS FC 25 and Battlefield 6). In EA SPORTS FC 25, a low-resolution configuration of the full game is used for training to speed up simulation at up to 120fps. Five parallel game instances run per training session. For Battlefield 6, up to 240 agents run concurrently on a headless server version with no graphics output.
Architecture / Algorithm:
- EA SPORTS FC 25 uses Soft Actor-Critic (SAC) algorithm with a 5-layer MLP (256 units each) with SiLU activations and layer normalization, totaling ~300k parameters.
- Battlefield 6 locomotion uses Proximal Policy Optimization (PPO) with a dual-input neural network: an MLP for auxiliary features and either a small CNN encoder for occupancy maps or an MLP for raycast observations.
- State representation:
- EA SPORTS FC 25 states encode relevant goalkeeper positioning features.
- Battlefield 6 uses occupancy maps (50 x 50) encoding agent, terrain, obstacles, and waypoint, cached at runtime from NavMesh data.
- Training Regime:
- EA SPORTS FC 25 RL agent trains with SAC for about 12 hours (down from 2-4 days) using offline data pre-collection, scenario-based training, and high update-to-data ratio with network resets.
- Fine-tuning for behavioral fixes can be done in 2-4 hours using scenario-based learning and RaE.
- Battlefield 6 locomotion agent trains with PPO in about 2 hours on multiple concurrent agents.
- Evaluation Protocol:
- For FC 25, performance is measured by save ratio increase relative to hand-coded goalkeeper AI, as well as player perception of believability and human-likeness.
- For Battlefield 6, locomotion quality is assessed qualitatively by smoother trajectories reminiscent of human players versus rigid NavMesh paths, as well as average episodic reward and success rate in reaching waypoints.
- Additional evaluation includes 1-vs-1 matches showing that RL-augmented locomotion wins 11 out of 20 episodes against hand-coded AI.
- Ablations compare raycast versus occupancy map perceptions, standard SAC versus modified SAC, and fine-tuning strategies.
- Reproducibility:
- The paper does not mention public code or dataset release.
- Environments are commercial AAA games not publicly available for independent reproduction.
- Training relies on proprietary internal game versions with low-res configurations or headless servers.
Example end-to-end: In EA SPORTS FC 25, the goalkeeper’s positioning subsystem (an existing FSM) is replaced by an RL agent trained with SAC on a low-res physics-based simulation running at 120fps. The agent receives observations about ball position, player positions, and game state, outputs continuous 2D movement commands within each timestep (every 5 frames). The reward function, designed by domain experts, encourages positioning that blocks shot angles and saves goals. Training occurs over 12 hours with multiple parallel instances. The resulting policy is integrated modularly back into the game AI pipeline, achieving a 10% save rate improvement and more realistic movement, while maintaining inference under 200 µs for on-device deployment.
Technical innovations
- A practical RL training framework designed specifically for production game development constraints, including short retraining times, modular integration, runtime inference efficiency, and maintainability.
- Applied scenario-based training combined with Replay across Experiments (RaE) fine-tuning to rapidly adapt RL policies to behavioral fixes within hours.
- Use of occupancy map state representations cached from NavMesh data for efficient obstacle perception, reducing computational overhead by ~2× compared to raycasting.
- Integration of RL agents as modular components within existing AI systems (FSM and behavior trees) rather than end-to-end replacements, enabling composability with hand-coded logic.
Baselines vs proposed
- EA SPORTS FC 25 baseline hand-coded FSM goalkeeper save ratio: baseline vs RL agent: +10%
- EA SPORTS FC 25 training time standard SAC: 2-4 days vs modified SAC: ~12 hours
- EA SPORTS FC 25 fine-tuning standard SAC: >4 hours vs scenario-based RaE fine-tuning: 2-4 hours
- Battlefield 6 locomotion baseline NavMesh + BT qualitative realism: rigid movements vs RL + occupancy map: smoother, more human-like
- Battlefield 6 observation extraction raycast time: ~27 µs vs occupancy map time: ~14 µs
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.20210.

Fig 1: Environments used as research testbeds. For this study, we use two
Fig 2 (page 1).
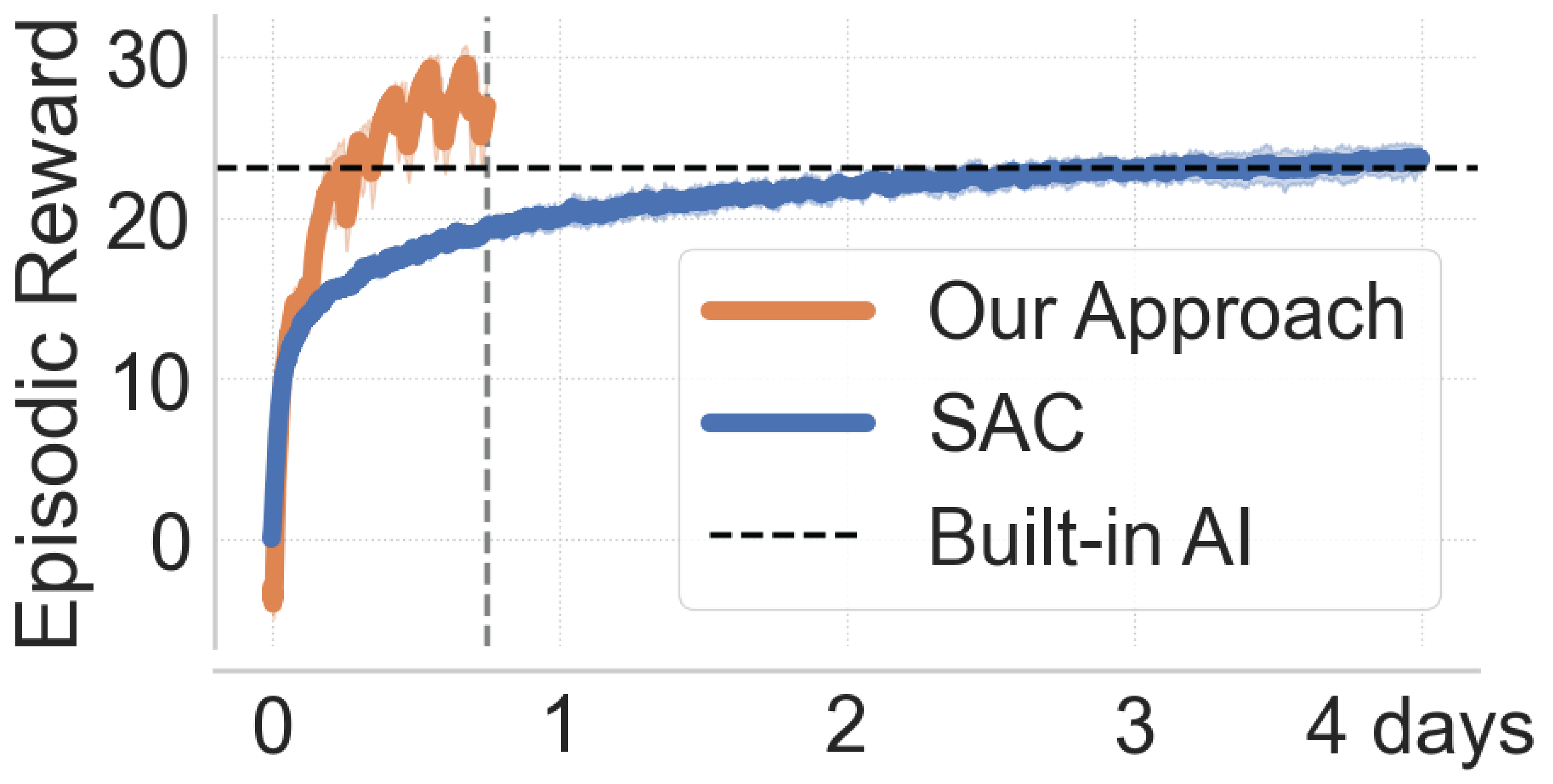
Fig 2: Training performance using our approach in EA SPORTS FC 25.
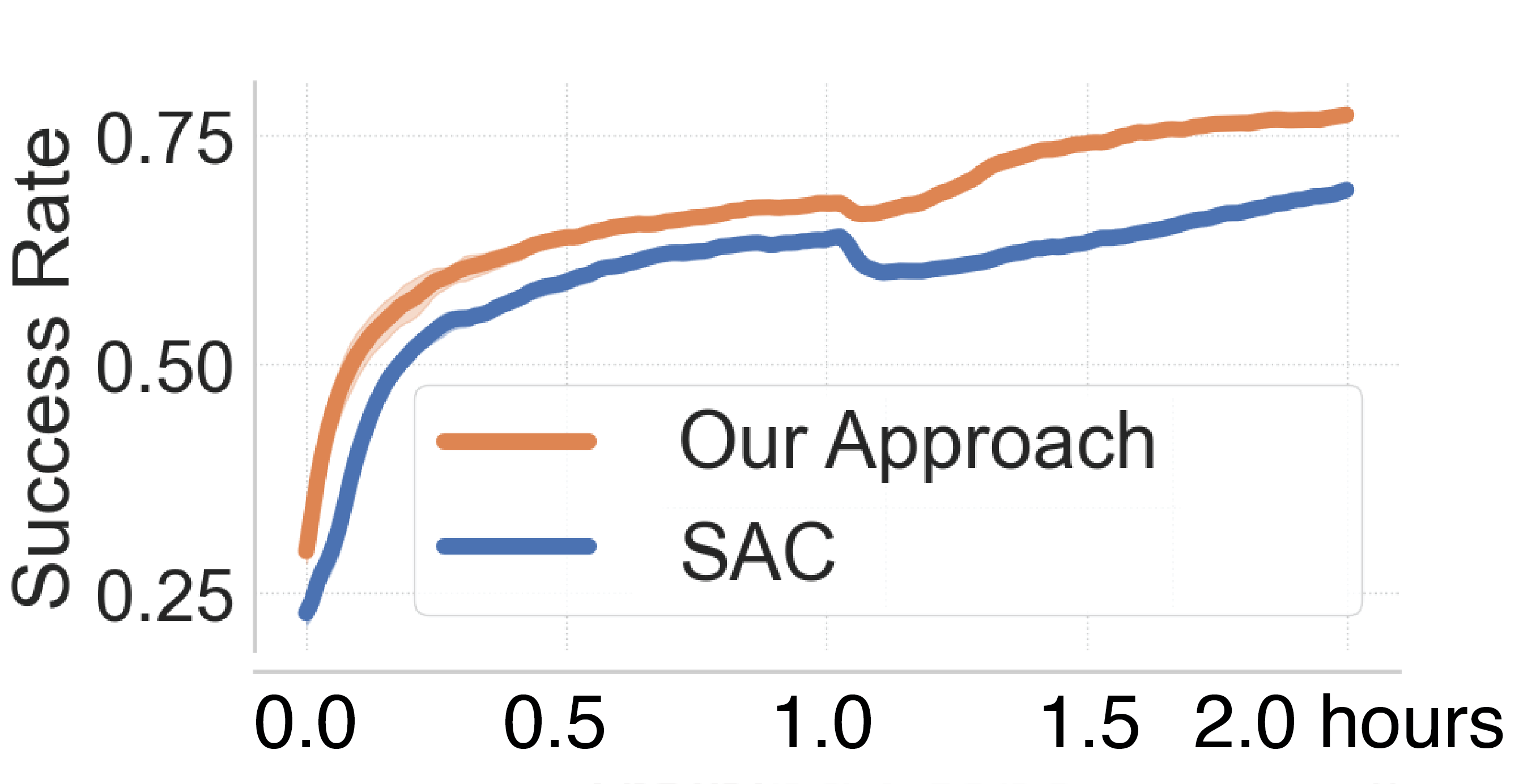
Fig 3: Modes of perception explored in Battlefield 6. Left Raycast fan of
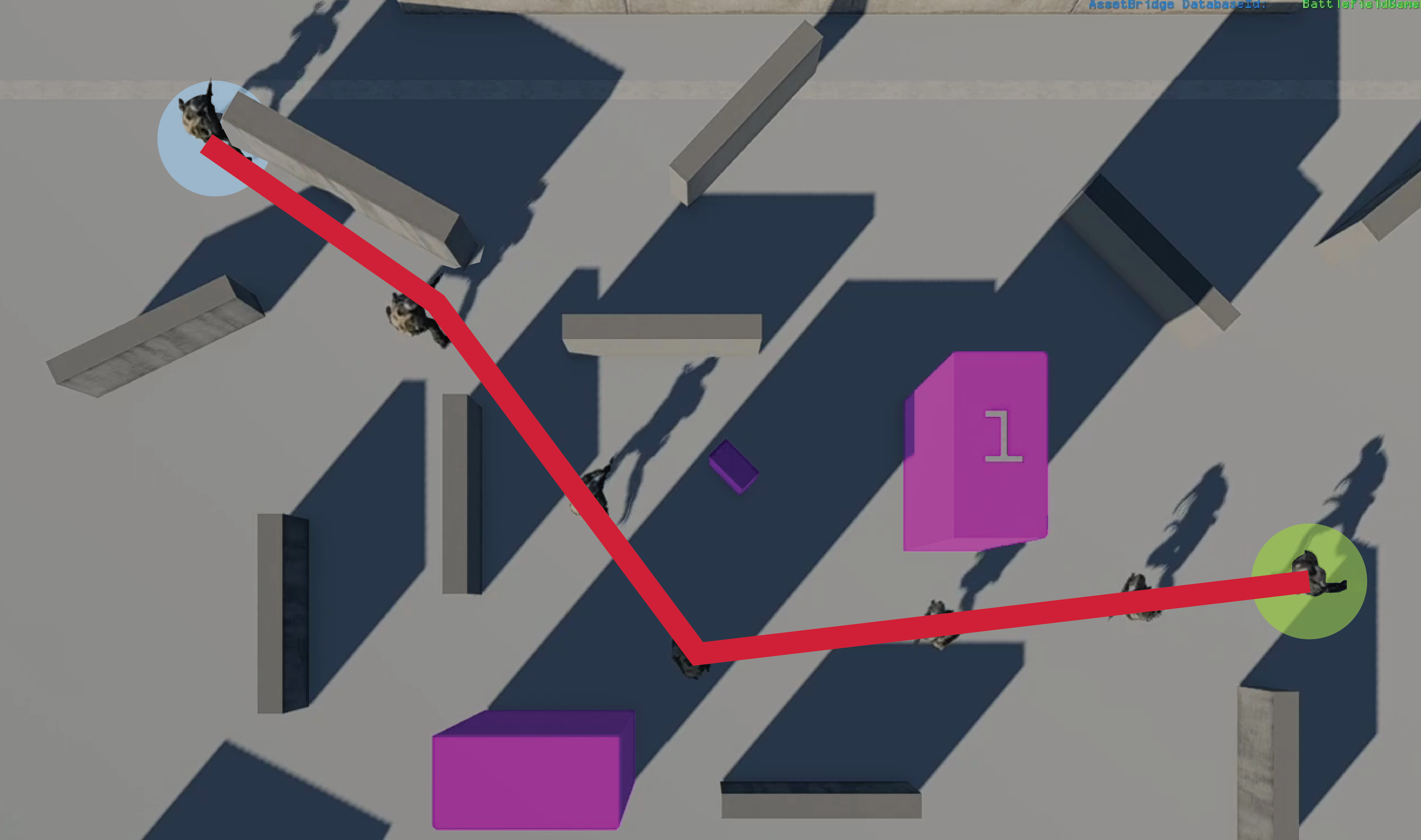
Fig 4: Comparison of agent training with raycasts (blue) and occupancy

Fig 5: Comparison of locomotion systems in Battlefield 6. Top: RL-

Fig 7 (page 5).
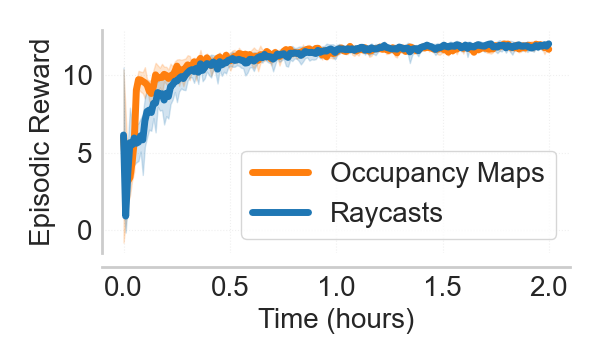
Fig 8 (page 5).
Limitations
- No public release of code or datasets, limiting reproducibility of experiments.
- RL agents trained and evaluated only within proprietary large-scale game environments, impacting generalizability to other genres or smaller games.
- Observations based on occupancy maps do not capture multi-layered environments, verticality, dynamic obstacles, or terrain irregularities, reducing representation fidelity.
- Fine-tuning approaches carry risks of catastrophic forgetting, making repeated behavioral corrections challenging over time.
- Evaluation focuses more on qualitative assessments and in-game performance metrics, lacking extensive user studies or adversarial testing scenarios.
- Training times, while improved, remain on the order of hours, which may still be restrictive for real-time iterative design without further efficiency gains.
Open questions / follow-ons
- How can designers provide effective qualitative feedback during RL training to shape authentic agent behaviors without extensive coding or long training cycles?
- What new state representations balance richness, computational efficiency, and dynamic environment awareness for use in large-scale game AI RL?
- How to develop systematic, production-friendly continual learning or fine-tuning methods that avoid catastrophic forgetting while enabling rapid behavior fixes?
- Can modular RL components be jointly trained or composed to improve global AI performance without sacrificing interpretability or maintainability?
Why it matters for bot defense
Although this paper does not directly address bot defense or CAPTCHA systems, its insights into augmenting traditional rule-based AI with reinforcement learning under strict computational and maintainability constraints have parallels in bot detection domains. The modular integration approach—combining well-understood handcrafted systems with data-driven RL agents—could inspire the design of adaptive but interpretable bot detection pipelines. The emphasis on short training times, runtime inference budgets, and fine-tuning aligns with practical deployment challenges in live security systems where rapid iteration and control over behavior are essential. Moreover, the discussion around compact state representations and efficient observation extraction may inform approaches to real-time anomaly detection or user behavior modeling in bot-defense scenarios. Overall, practitioners can consider the identified bottlenecks and solutions as valuable lessons for deploying complex learning agents with strict production constraints, whether in games or security applications.
Cite
@article{arxiv2606_20210,
title={ Augmenting Game AI with Deep Reinforcement Learning },
author={ Alessandro Sestini and Joakim Bergdahl and Amir Baghi and Jean-Philippe Barrette-LaPierre and Florian Fuchs and Linus Gisslén },
journal={arXiv preprint arXiv:2606.20210},
year={ 2026 },
url={https://arxiv.org/abs/2606.20210}
}