
Towards an Agent-First Web: Redesigning the Web for AI Agents
Source: arXiv:2606.19116 · Published 2026-06-17 · By Eranga Bandara, Ross Gore, Ravi Mukkamala, Asanga Gunaratna, Safdar H. Bouk, Xueping Liang et al.
TL;DR
This paper addresses a fundamental challenge that the World Wide Web’s original design assumptions center on humans as primary content consumers, an assumption invalidated by the rapid rise of AI agents acting autonomously at scale. Today's web architecture at access, economic, and content layers blocks or treats AI agents as malicious or extractive intermediaries. The authors diagnose incompatibilities in three layers: at the access layer, absence of agent identification metadata results in blanket blocking; at the economic layer, AI-mediated zero-click consumption breaks the human attention value flow; and at the content layer, AI content reprocessing leads to self-reinforcing epistemic decay (epistemic recursion).
They propose a comprehensive redesign including introducing standardized agent identification headers (agent metadata) with agents.txt policies enabling graduated rate limiting rather than blocking; a token-based economic subscription model reflecting the intent of agent use keyed to the human user (agent-as-human-proxy principle); and a new semantic content format (Agent Text Markup Language, ATML) coupled with a four-level human supervision tier and cryptographic provenance chains to preserve epistemic integrity. Together these form ten design principles creating a web that treats AI agents as first-class citizens rather than nuisances. Empirical evidence from traffic analysis shows current infrastructure blocking rates and economic disruption caused by AI agent interaction, motivating the urgent need for this multi-layer redesign framework.
Key results include concrete proposals for HTTP metadata extensions for agent identity and intent, economic tiering to enable sustainable value exchange despite zero-click, and architectural defenses against epistemic recursion. The paper frames the problem as renegotiating the web’s foundational social contract rather than applying ad hoc patches. This systemic approach unifies prior isolated research into protocol, economics, and provenance into a consistent future-facing vision for an agent-first internet.
Key findings
- Cloudflare data (mid-2025) shows crawl-to-referral ratios: Googlebot 14:1, OpenAI crawler 1,700:1, Anthropic crawler 73,000:1, indicating massive economic asymmetry and content extraction without value return.
- Zero-click searches now account for ~60% of Google queries, rising to 93% in AI-native modes, with position one click-through rates declining from 27% to 11%, severely disrupting publisher revenue.
- Agent-optimized content delivery reduces token usage by 67.6% compared to standard HTML, implying significant computational and economic inefficiency in current web formats for agent consumption.
- The phenomenon termed epistemic recursion describes progressive degradation of web knowledge quality as AI-generated content recursively feeds further AI content generation, increasing bias and detachment from human ground truth.
- Between July 2025 and January 2026, websites blocking AI crawlers grew nearly sevenfold compared to those blocking traditional crawlers, exemplifying hostile agent access policies currently prevalent.
- Proposed agent identification metadata via HTTP headers and agents.txt policies enable graduated access management, replacing the binary block/allow model that treats all agents alike.
- Intent-based economic tiering and token-based subscription models align agent economic obligations with the human users they represent, addressing attribution and production problems in AI-mediated content consumption.
- The Agent Text Markup Language (ATML) along with a four-level supervision tier and cryptographic provenance chains creates machine-readable signals of human oversight to combat epistemic recursion structurally.
Threat model
Adversaries include automated agents interacting with the web: ranging from benign personal AI agents acting as proxies for humans, mass scraping training crawlers extracting content without returning value, to malicious bots conducting reconnaissance or denial-of-service attacks. The system assumes adversaries cannot cryptographically forge provenance metadata or human supervision attestations without detection. It does not consider internal agent compromise or sophisticated identity spoofing beyond proposed agent metadata protocols.
Methodology — deep read
The paper undertakes a conceptual and empirical diagnosis of the incompatibilities between existing web architecture assumptions and the emergent AI agent usage paradigm across three key layers: access, economics, and content.
Threat model and assumptions: The adversary context includes actors ranging from benign personal assistant agents acting on behalf of individual humans, commercial indexing and training crawlers extracting content at scale, to malicious bots scraping or probing. The critical assumption challenged is that all web visitors are humans, requiring redefinition of agent identity, intent, and accountability mechanisms.
Data and empirical evidence: The authors leverage large-scale web traffic data from infrastructure providers like Cloudflare and Semrush, analyzing crawl-to-referral ratios across major agents, trends in zero-click searches, publisher traffic declines, and crawl blocking statistics. Content delivery efficiency is measured via token usage with agent-optimized versus traditional HTML content formats. Prior academic studies on model collapse and provenance integrity inform epistemic recursion theory.
Architecture and algorithmic proposals: The access layer introduces standardized HTTP request headers for agents to declare identity, intent, and human representation, analogous to User-Agent headers in browsers. These pair with a new agents.txt access policy standard to enable graduated, intent-aware rate limiting rather than blanket blocking. Economically, they propose an intent-based tier framework that grounds an agent’s economic obligation equivalently to the human it proxies, realized via token-based subscriptions metering content access, plus commissioned content economies incentivizing human oversight within AI-generated content. The content layer proposes the Agent Text Markup Language (ATML), designed as a semantic, machine-readable format optimized for agent consumption, integrated with a four-level human supervision tier model, and cryptographic provenance chains for verifiable human oversight metadata.
Training and deployment: As this is a systems design and conceptual framework paper, it does not involve model training. Instead, it integrates evidence from empirical internet-scale data analyses and builds on prior work on AI agent protocols, web economics, and content provenance.
Evaluation protocol: Rather than experimental evaluation, the paper contextualizes its contributions with operational data (e.g., crawl ratios, blocking rates, traffic declines), supported by conceptual reasoning analyzing incompatibilities and architecture-level design. Efficiency gains (token savings) and structural threats (epistemic recursion) are quantified referencing existing benchmarks and prior empirical results.
Reproducibility: The paper does not mention code or dataset release, as the contributions are primarily architectural design proposals and conceptual frameworks supported by public and proprietary infrastructure data.
As a concrete example, at the access layer, the introduction of standardized agent identification HTTP headers is illustrated as an analog to traditional browser User-Agent strings, enabling servers to differentiate between human and agent visitors and apply graduated rate limiting instead of blanket blocking. The agents.txt policy file formalizes access tiers and intent, enabling automated enforcement via existing HTTP infrastructure. This contrasts with current robots.txt which lacks identity and intent metadata and enforcement mechanisms.
Overall, the methodology combines analysis of web-scale empirical traffic data, economic behavior metrics, and AI content generation phenomena with protocol and architectural design, informed by prior multidisciplinary literature across AI agents, web economics, and content provenance.
Technical innovations
- Standardized HTTP agent identification metadata and agents.txt access policy enable graduated, intent-aware rate limiting and dual-layer content serving, replacing binary block/allow models.
- Intent-based economic tier framework applying the agent-as-human-proxy principle aligns AI agent content access costs with the human user's economic obligations, implemented via token-based subscriptions.
- Agent Text Markup Language (ATML): a semantic web content format optimized for machine readability by agents, containing explicit metadata on provenance, derivation, and human oversight.
- Four-level human supervision tier coupled with a cryptographic provenance chain architecture to provide machine-verifiable evidence of human oversight, countering epistemic recursion and model collapse.
Datasets
- Cloudflare internet traffic logs (mid-2025) — crawl-to-referral ratios and blocking rates — proprietary infrastructure dataset
- Google search query logs — zero-click search statistics — publicly reported by Semrush and Google
- Agent content delivery benchmarks measuring token usage — from prior published studies in references [15,55]
- Prior model collapse and provenance detection data — from referenced academic works such as Shumailov et al. [51], Kirchenbauer et al. [39]
Baselines vs proposed
- Googlebot crawl-to-referral ratio = 14:1 vs OpenAI crawler 1,700:1 and Anthropic crawler 73,000:1 (Fig 1)
- Click-through rate at position 1 decreased from 27% (human web) to 11% (AI-native search modes)
- Agent-optimized content reduces token usage by 67.6% compared to HTML standard formats
- Between July 2025 and Jan 2026, websites blocking AI crawlers grew 7x more than sites blocking traditional crawlers
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19116.
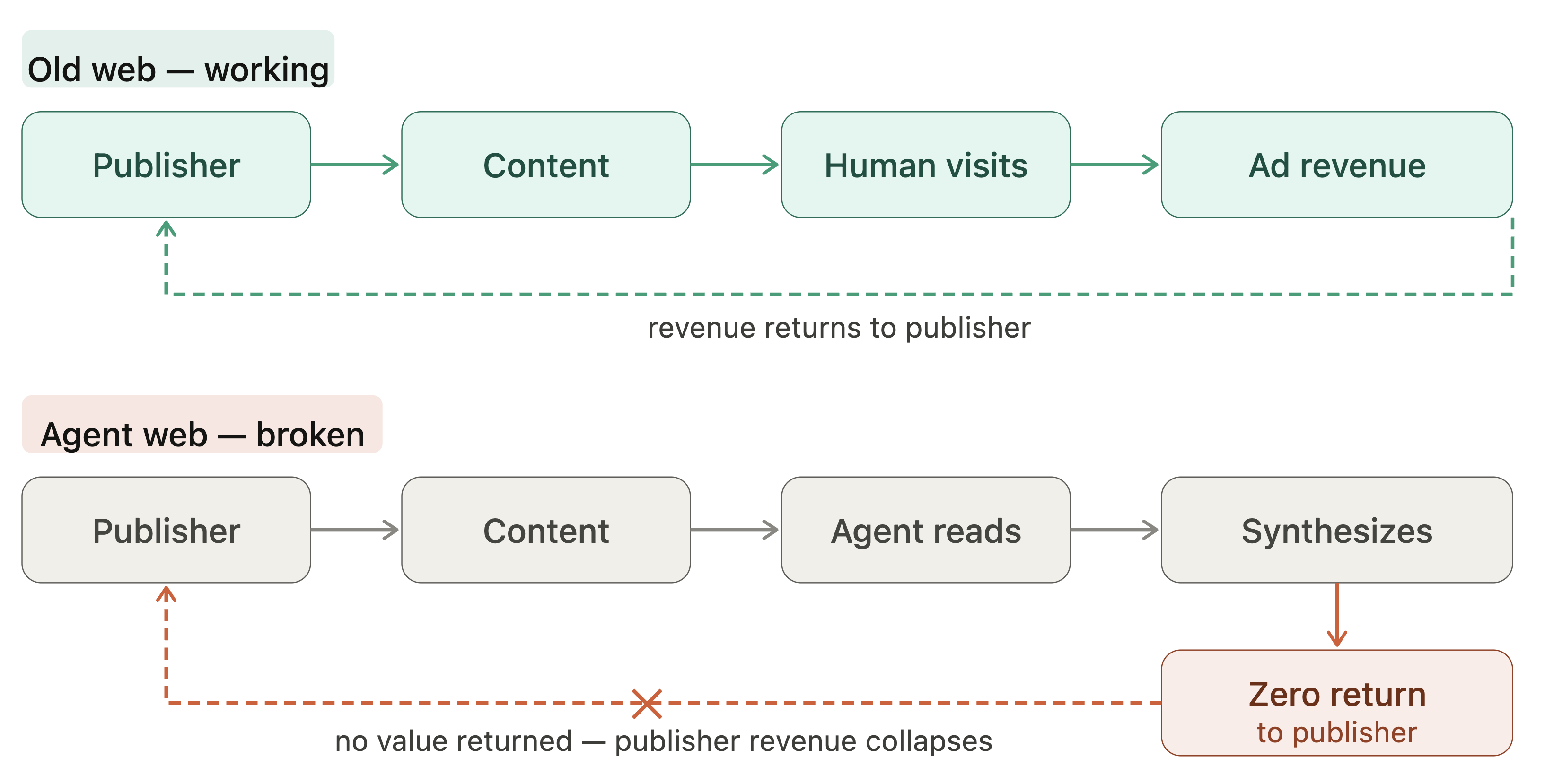
Fig 1: The broken economic loop.
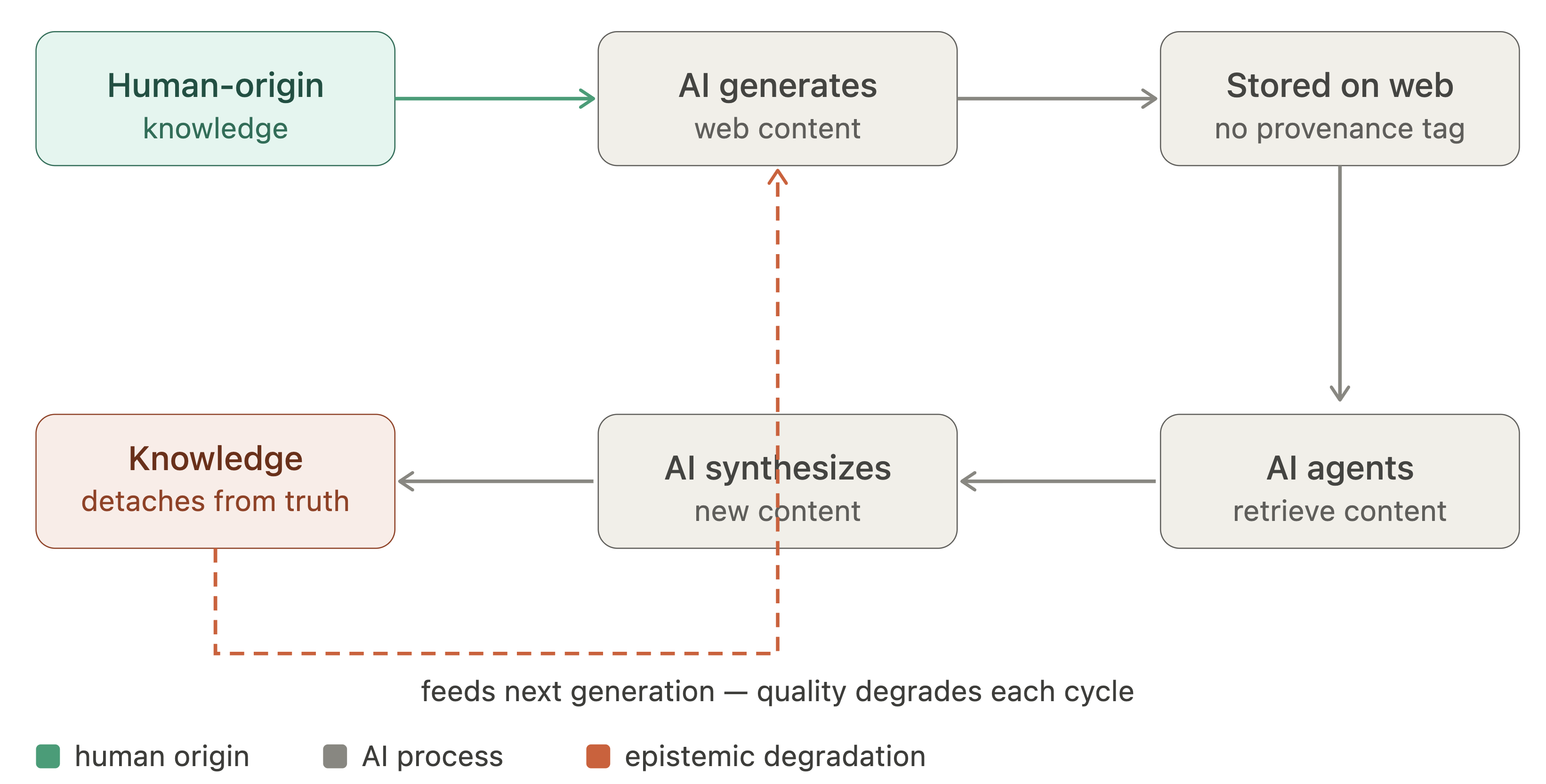
Fig 2: The epistemic recursion loop. Human-origin knowledge enters the web through
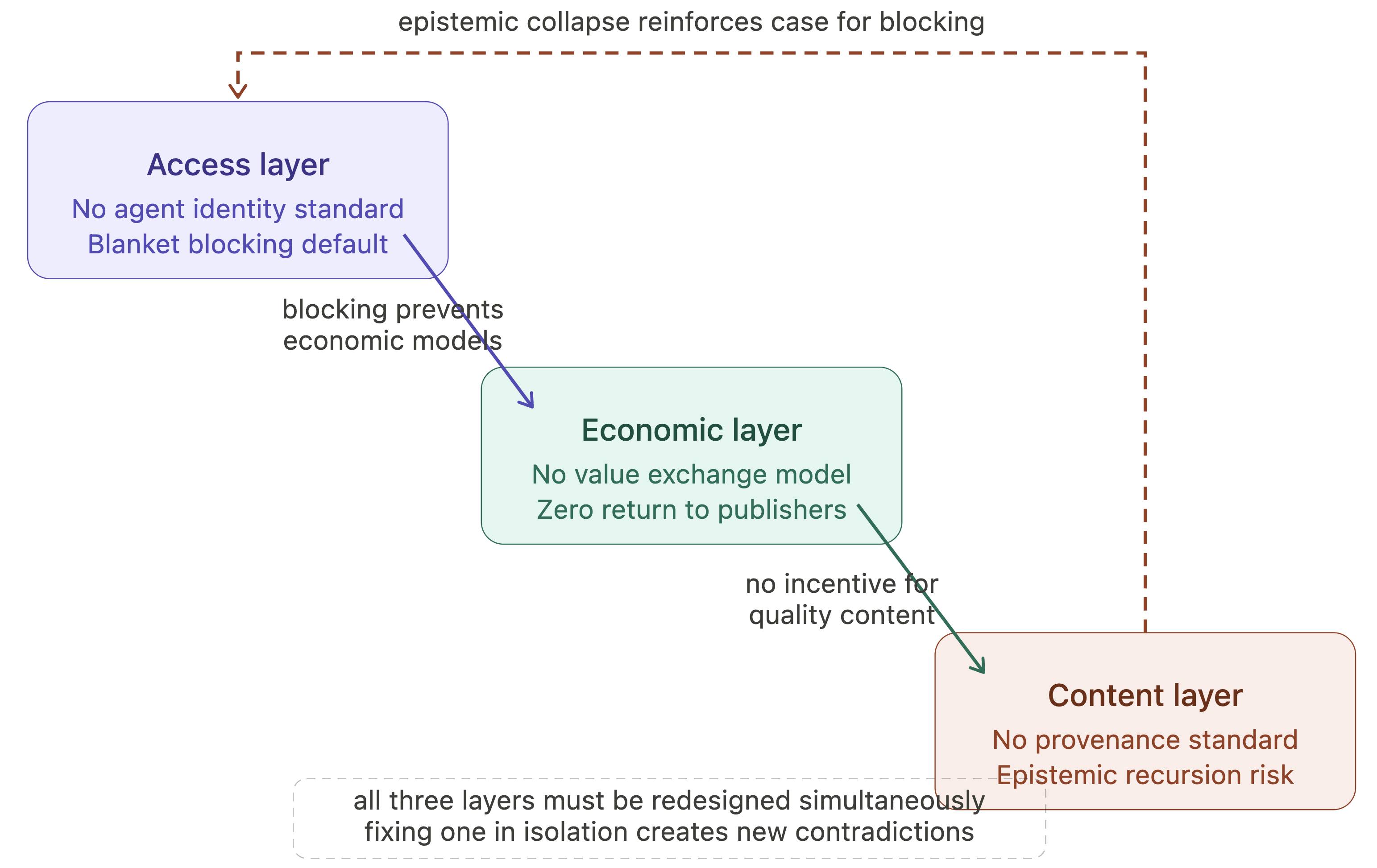
Fig 3: Three-layer failure coupling. The access, economic, and content layer failures of
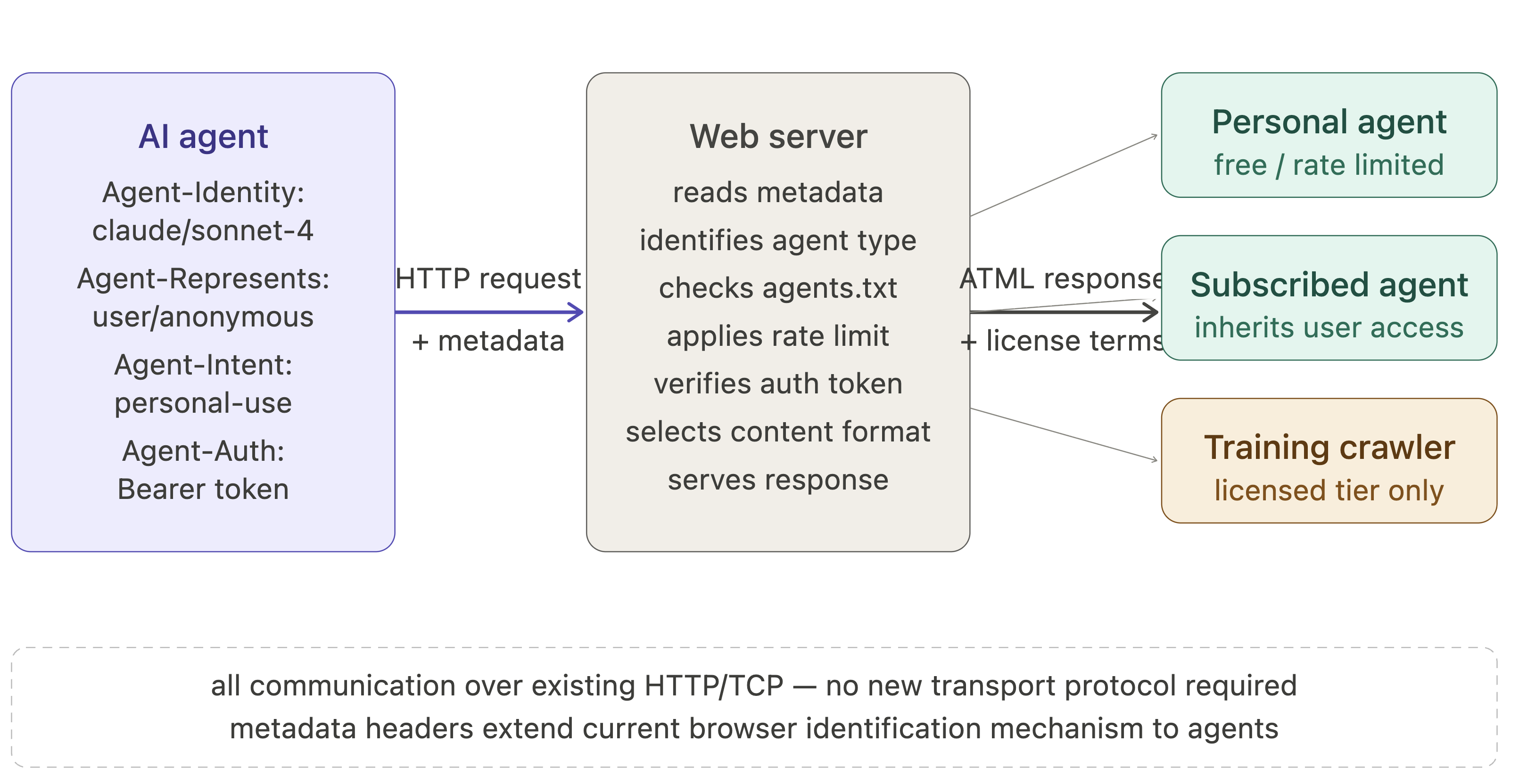
Fig 4: Agent identification metadata flow. An AI agent sends standardized metadata
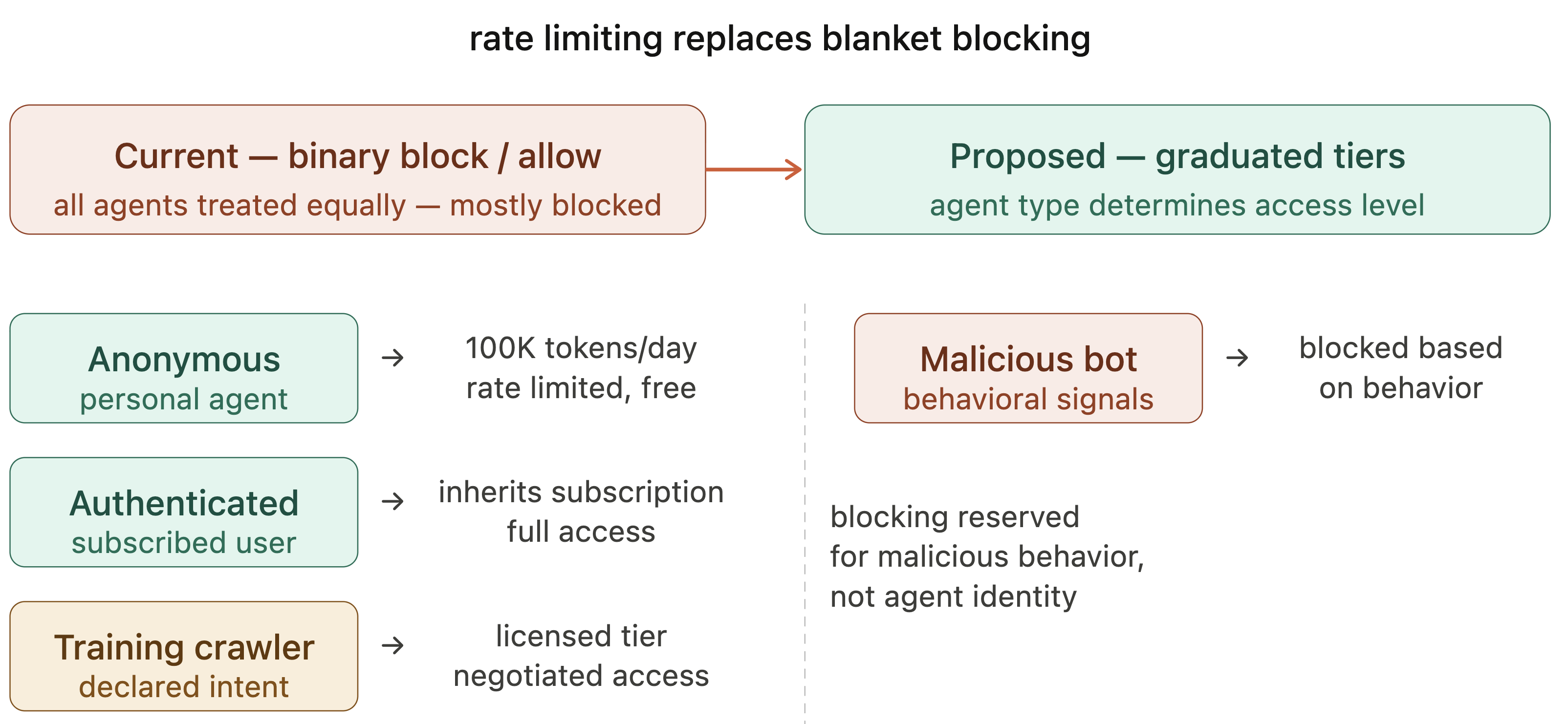
Fig 5: Graduated rate limiting model replacing blanket blocking. Agent access is tiered
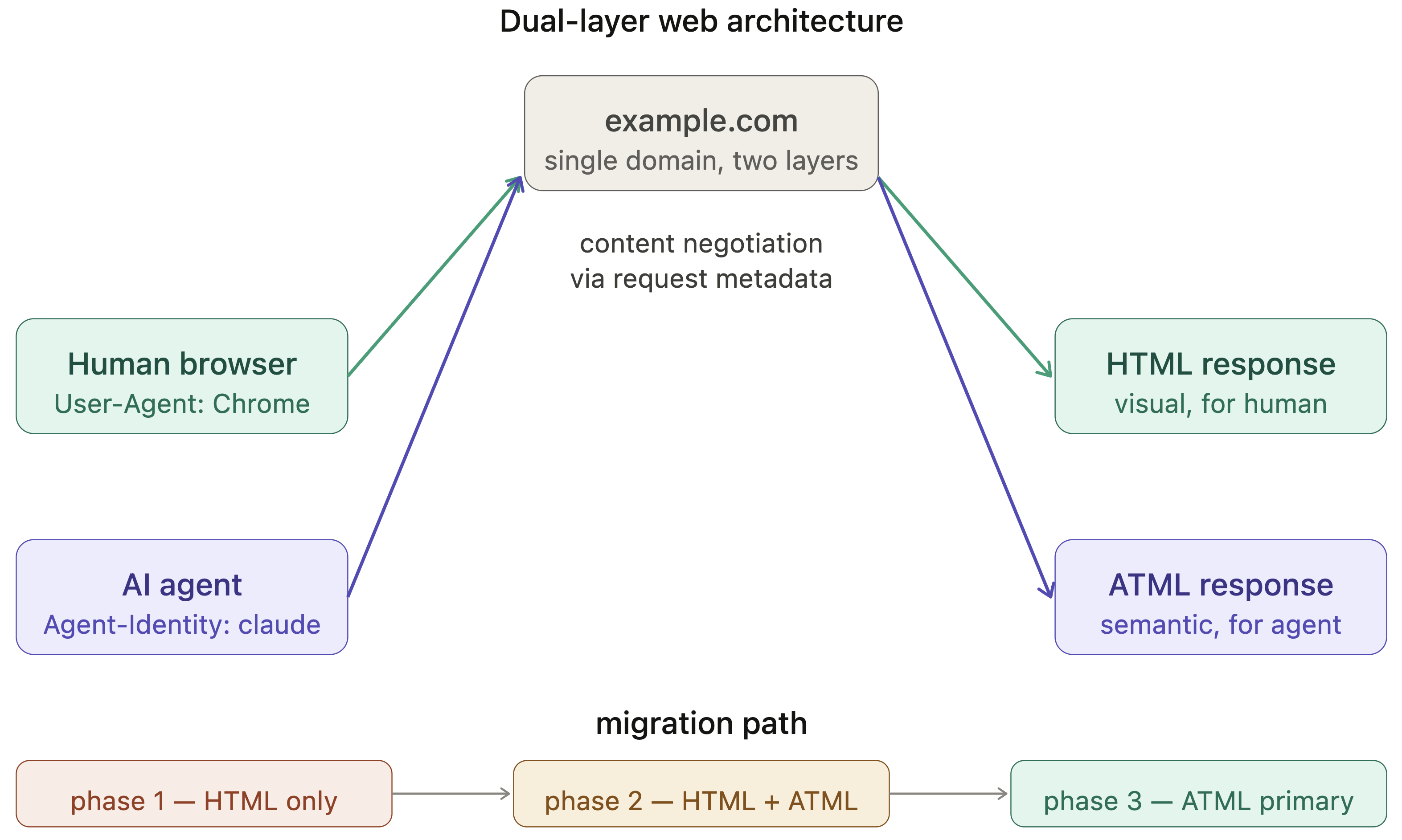
Fig 6: Dual-layer web architecture and migration path. The same domain serves HTML
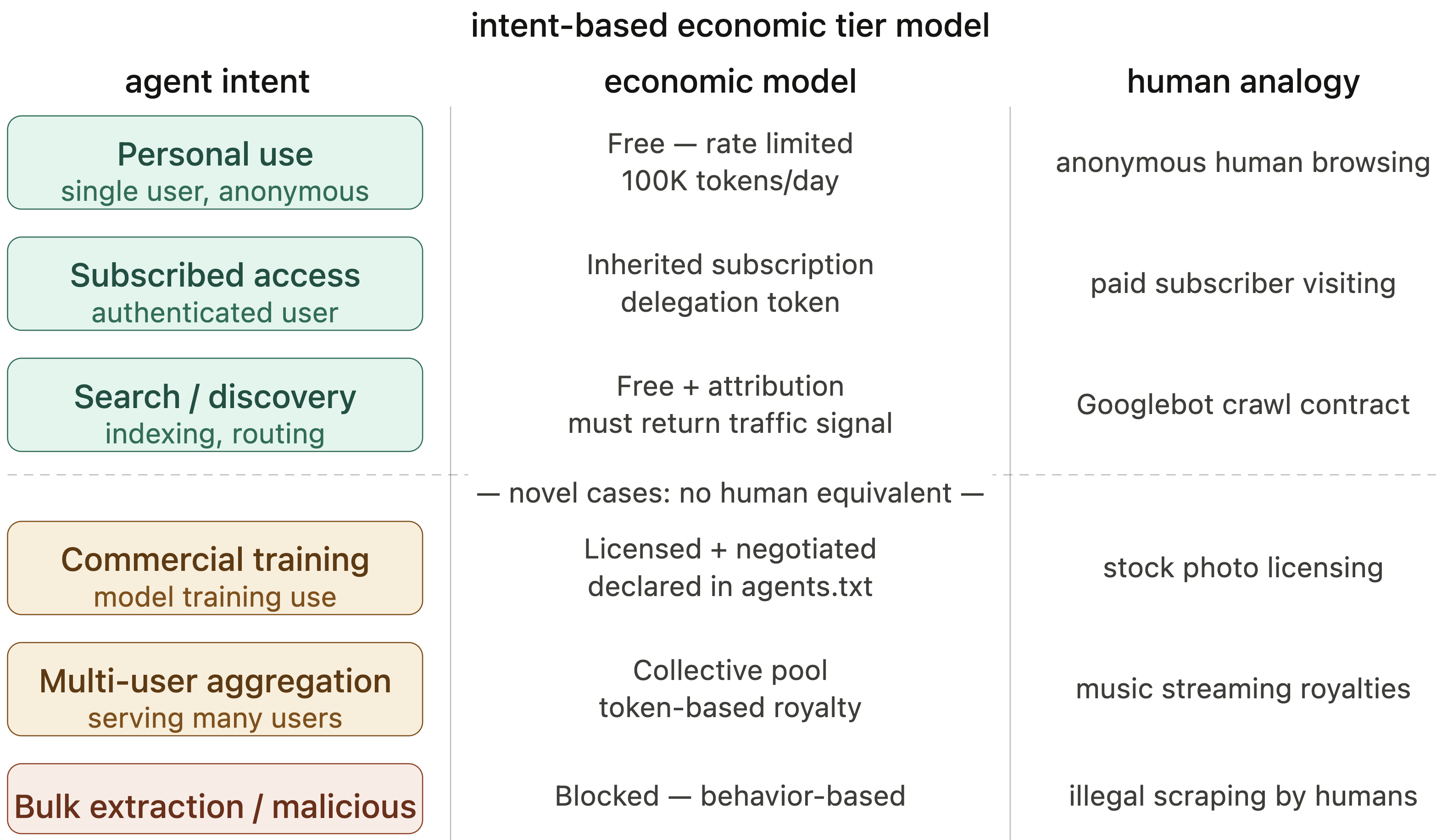
Fig 7: Intent-based economic tier model. Agent content access behaviors are classified
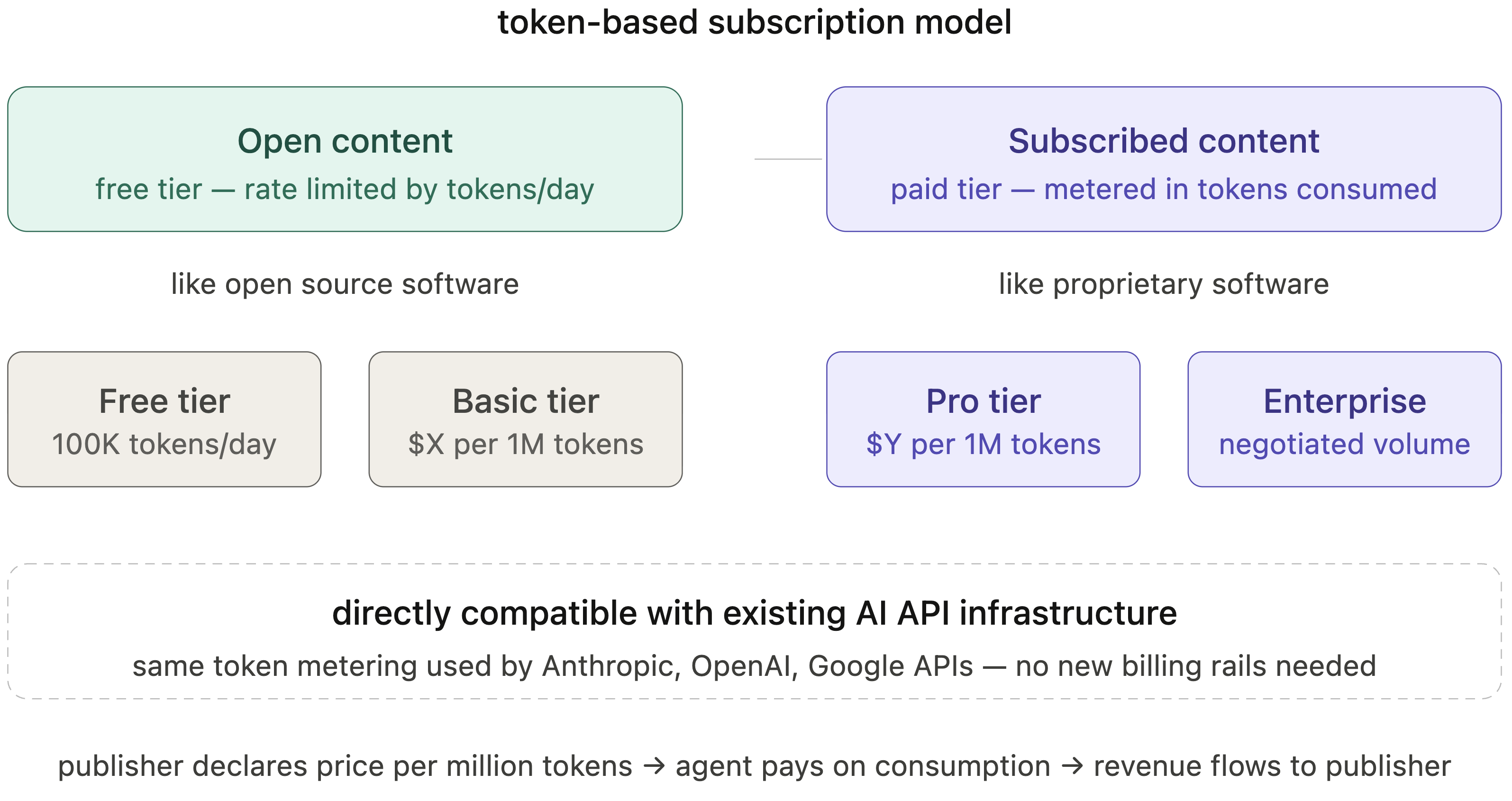
Fig 8: Token-based subscription model. Content access is metered in tokens consumed
Limitations
- The proposals are conceptual and architectural without deployed prototype evaluations or real-world trials.
- Empirical data is largely sourced from commercial infrastructure providers, potentially limiting replicability and independent validation.
- The economic model considers intent tiers but may not fully capture complex commercial relationships or incentivization dynamics in practice.
- Epistemic recursion prevention mechanisms rely on adoption of ATML and provenance chains, which have no current standardization or deployment.
- Security threats beyond blocking and rate limiting, such as agent impersonation or provenance forging, are not deeply addressed.
- The transition path to a dual-layer web serving human and agent content may face significant compatibility and adoption challenges.
Open questions / follow-ons
- How to incentivize widespread adoption of agent identification metadata and agents.txt access policies across heterogeneous web infrastructure?
- What governance frameworks and legal implications arise from recognizing AI agents as first-class web citizens equivalent to humans?
- How effective are cryptographic provenance chains and supervision tiers at preventing epistemic recursion in practice, especially under adversarial conditions?
- What are the implications of token-based metered economics on content accessibility and equity in diverse user populations?
Why it matters for bot defense
Bot-defense practitioners and CAPTCHA system designers should regard this paper as a foundational critique and alternative framework to the prevailing exclusionary approach of distinguishing human from non-human by blocking or challenge mechanisms. The proposed agent identification metadata and graduated rate limit approach suggest moving away from adversarial challenges towards more nuanced, declarative, and identity-based access controls that recognize legitimate AI agents acting for humans. This could reduce friction for authorized agents while preserving defense against malicious scraping.
Moreover, economic tiering and provenance frameworks offer new signals to detect and manage agent behavior beyond traditional CAPTCHAs, potentially integrating with behavioral analytics to better classify agent intent. The epistemic recursion problem also raises the need for bot-defense systems to consider the provenance and supervision metadata of content crawled or generated by agents, informing trust and reputation models. Overall, the paper encourages bot-defense engineers to rethink web interaction paradigms embracing agent-first design rather than adversarial human/agent binaries.
Cite
@article{arxiv2606_19116,
title={ Towards an Agent-First Web: Redesigning the Web for AI Agents },
author={ Eranga Bandara and Ross Gore and Ravi Mukkamala and Asanga Gunaratna and Safdar H. Bouk and Xueping Liang and Peter Foytik and Abdul Rahman and Sachini Rajapakse and Isurunima Kularathna and Pramoda Karunarathna and Chalani Rajapakse and Ng Wee Keong and Kasun De Zoysa and Tharaka Hewa and Amin Hass and Wathsala Herath and Aruna Withanage and Nilaan Loganathan and Atmaram Yarlagadda and Sachin Shetty },
journal={arXiv preprint arXiv:2606.19116},
year={ 2026 },
url={https://arxiv.org/abs/2606.19116}
}