
SCAN: Enhance Time Series Anomaly Detection via Multi-Scale Neighborhood-Centered Clustering
Source: arXiv:2606.19255 · Published 2026-06-17 · By Xingze Zheng, Hanyin Cheng, Siyuan Wang, Yiting Hao, Peng Chen, Yuan Jun et al.
TL;DR
This paper tackles fundamental challenges in unsupervised time series anomaly detection using reconstruction-based methods. Such methods face a trade-off between over-generalization—where anomalous patterns are reconstructed too well, causing false negatives—and under-generalization—where complex normal patterns are poorly reconstructed, causing false positives. The authors propose SCAN, a novel approach that integrates multi-scale clustering both at the representation learning and anomaly scoring levels to address these issues. By leveraging neighborhood-centered representations to improve clustering quality and fusing cluster center information into the reconstruction process, SCAN constrains the model's reconstruction objectives to representative normal patterns and supplements reconstruction error with a clustering-derived anomaly confidence score. Extensive experiments on seven real-world time series datasets show SCAN consistently outperforms 22 strong baselines in anomaly detection metrics, achieving considerable improvements in VUS-ROC and VUS-PR. The design effectively balances the trade-off, enhancing detection accuracy and stability while maintaining computational efficiency. Ablation studies further confirm the contribution of key components such as multi-scale modeling, trusted pseudo-label supervision, and hierarchical cluster fusion.
Key findings
- SCAN achieves top performance on 7 real-world datasets including SMD, MSL, SMAP, PSM, SWAT, GECCO, and SWAN, outperforming 22 baselines in VUS-ROC (0.9081 on SMD) and VUS-PR (0.3203 on SMD).
- Multi-scale modeling boosts average VUS-ROC from 0.7196 to 0.7356 and VUS-PR from 0.3497 to 0.3802 (PSM, SMAP, GECCO datasets).
- Incorporating pattern clustering further increases average VUS-ROC to 0.7575 and VUS-PR to 0.3994.
- Trusted pseudo-label supervision improves average VUS-ROC and VUS-PR by +1.49% and +9.42% respectively over pattern clustering without it.
- Cluster center representation fusion into reconstruction raises average VUS-ROC by +2.01% and VUS-PR by +8.63%.
- Removing multi-scale cluster fusion reduces performance, validating its role in enriching normal pattern modeling.
- SCAN offers faster training (15.11s) and inference (0.15s) versus other transformer and CNN-based methods while maintaining fewer or comparable parameters (1.76M).
- Visualization shows clustering-based anomaly confidence scores reduce false positives and false negatives in complex anomalies compared to traditional reconstruction error.
Threat model
The model assumes an unsupervised setting where only normal time series samples are available during training, with rare or unknown anomalies appearing at test time. The adversary could be any unknown process generating anomalous temporal patterns. The model does not assume any prior knowledge of anomaly types or labels and relies exclusively on learning normal pattern distributions and detecting deviations. The adversary cannot tamper with training data or cluster assignments during training.
Methodology — deep read
Threat Model & Assumptions: The adversary is unspecified explicitly since this is unsupervised anomaly detection. Assumes training data consists only of normal patterns with anomalies being rare and unknown at training time. The model cannot depend on labeled anomalies and must detect deviations at test time.
Data: Evaluated on seven public benchmark datasets with multivariate time series from diverse domains: SMD, MSL, SMAP, PSM, SWAT, GECCO, SWAN. Data preprocessing includes reversible instance normalization (RevIN), patch embedding into d-dimensional space. Labels are binary anomaly annotations for test sets only.
Architecture & Algorithm:
- Multi-scale modeling creates j time series scales by non-overlapping average pooling with varying kernel sizes, capturing patterns at different temporal resolutions.
- Each scale is split into patches and embedded into representations Ei.
- Neighborhood-Centered Clustering module extracts two neighborhood-centered representations (Esim, Etim) based on similarity and temporal adjacency matrices, highlighting patch deviations from neighbors in respective views.
- Independently cluster original and neighborhood-centered representations into K clusters using cosine similarity and masked cross-attention which refines cluster centers weighted by membership probabilities and cluster masks.
- Select high-quality pseudo-labels from neighborhood-centered clusters based on entropy-based uncertainty filtering and use them as trusted supervision to constrain clustering of original representation, via cross-entropy loss.
- Hierarchical Cluster Fusion aggregates cluster-weighted representations intra- and inter-scale using gating mechanisms balancing cluster center information and original embeddings, producing fused representations Zi for reconstruction.
- Reconstruction head projects Zi back to input space and trains with mean squared error loss.
- Total loss combines reconstruction loss, clustering loss enforcing intra-cluster compactness and inter-cluster separability, cross-entropy loss for pseudo-label guidance, and consistency loss aligning cluster membership across views.
Training regime: Hyperparameters include balance coefficients λ1, λ2, λ3 for loss terms, cluster number K preset, number of scales m. Models trained with mini-batches, on GPU hardware (details not fully specified). Dynamic label selection size Bsel based on quality scores per batch.
Evaluation: Used metrics include VUS-ROC and VUS-PR, robust to threshold settings, over 7 datasets. Compared against 22 baselines spanning classical (OCSVM, LOF) to advanced deep learning methods (TimesNet, CrossAD). Ablations tested effect of multi-scale modeling, clustering, supervision, fusion modules. Visualization compared anomaly score curves. No adversarial robustness tests or distribution shift evaluations are described.
Reproducibility: Code release is not clearly stated; datasets used are publicly available benchmarks. Details on seeds or training robustness not explicitly provided.
Example end-to-end: Given raw multivariate time series X, SCAN generates multi-scale inputs {X0, X1, X2} via pooling. Each scale is patched and embedded into Ei. Neighborhood-centered adjacency matrices (Asim, Atim) computed from weighted embeddings define neighbors. Neighborhood-centered representations are calculated as deviations from aggregated neighbors in similarity and temporal views. These are independently clustered, pseudo-labels filtered by entropy-derived quality scores. Trusted supervision trains original clustering branch with cross-entropy against pseudo-labels. Cluster centers from all scales produce cluster-weighted representations Gi, fused progressively inter-scale to Fi, then intra-scale fused with Ei to produce Zi for reconstruction. Reconstruction error and clustering-based anomaly confidence scores combine multiplicatively to produce final anomaly score. Points exceeding adaptive threshold delta determined by SPOT are marked anomalous.
Technical innovations
- Introduces multi-scale clustering integration within reconstruction-based time series anomaly detection to mitigate over- and under-generalization trade-offs.
- Designs neighborhood-centered representations that capture patch deviations in both similarity and temporal adjacency spaces to enhance clustering discriminability.
- Employs a novel trusted pseudo-label filtering mechanism based on entropy to supervise original representation clustering using higher-quality neighborhood-centered clusters.
- Develops hierarchical cluster fusion module utilizing gating mechanisms for progressive inter-scale and intra-scale aggregation of cluster center representations, improving reconstruction targets.
- Combines dual anomaly criteria integrating reconstruction reconstruction error with clustering-based membership confidence to deliver more robust anomaly scores.
Datasets
- SMD — multivariate time series — public benchmark
- MSL — multivariate time series — public benchmark
- SMAP — multivariate time series — public benchmark
- PSM — multivariate time series — public benchmark
- SWAT — multivariate time series — public benchmark
- GECCO — multivariate time series — public benchmark
- SWAN — multivariate time series — public benchmark
Baselines vs proposed
- OCSVM: VUS-ROC = 0.6451 (SMD) vs SCAN: 0.9081
- TimesNet: VUS-ROC = 0.8420 (SMD) vs SCAN: 0.9081
- CrossAD: VUS-ROC = 0.8580 (SMD) vs SCAN: 0.9081
- GPT4TS: VUS-PR = 0.1745 (SMD) vs SCAN: 0.3203
- ModernTCN: Training time = 22.75s vs SCAN: 15.11s (GECCO)
- AnomalyTransformer: Inference time = 15.05s vs SCAN: 0.15s (GECCO)
- KAN-AD: Total params = 0.41M vs SCAN: 1.76M
- Ablation without multi-scale modeling: Avg VUS-ROC = 0.7196 vs with SCAN full model: 0.7843
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19255.
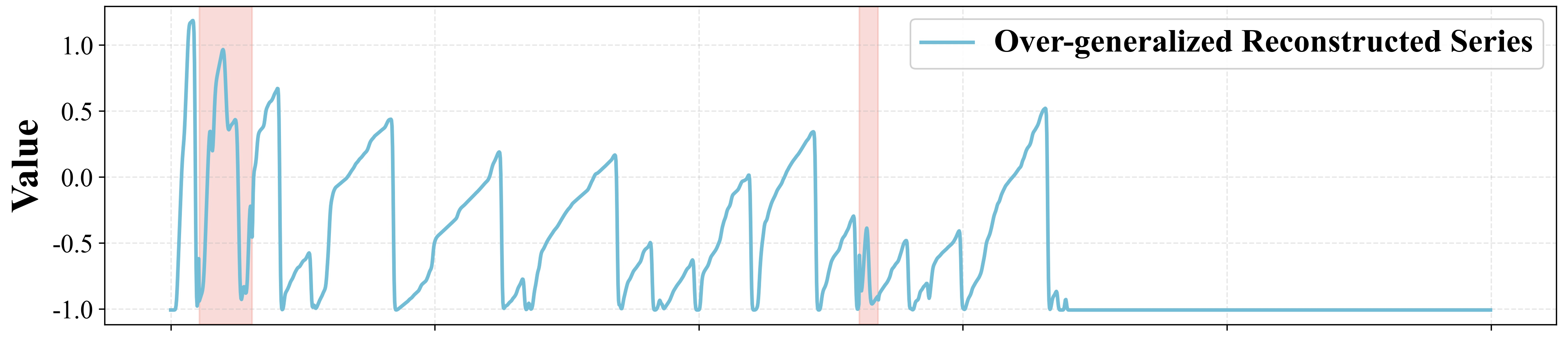
Fig 1: Example of over-generalization and under-generalization. From top to bottom: anomalous
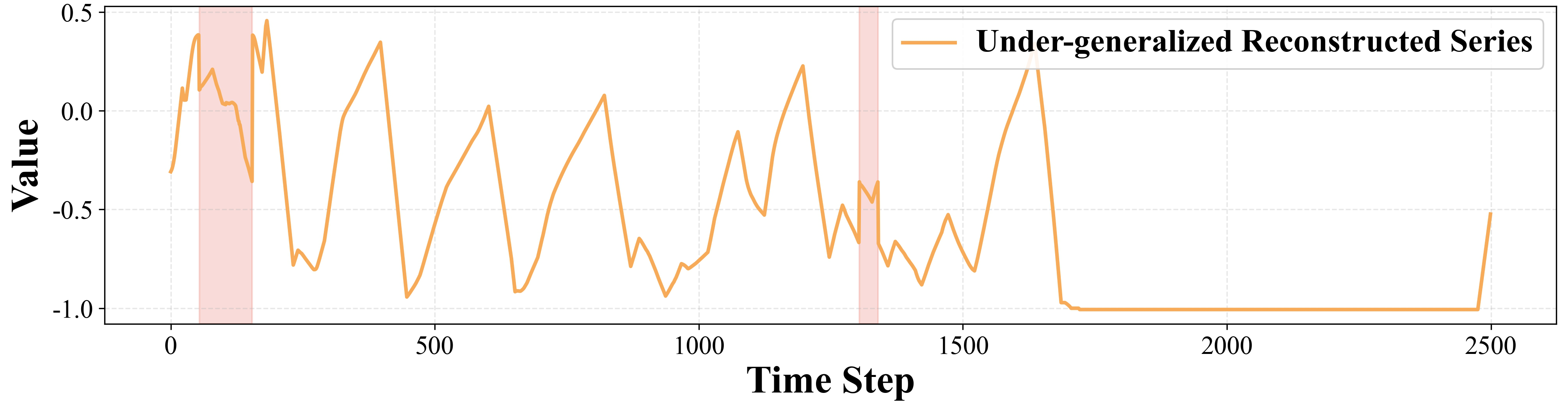
Fig 2: Comparison of original and neighborhood-centered representation spaces. (a) Normal
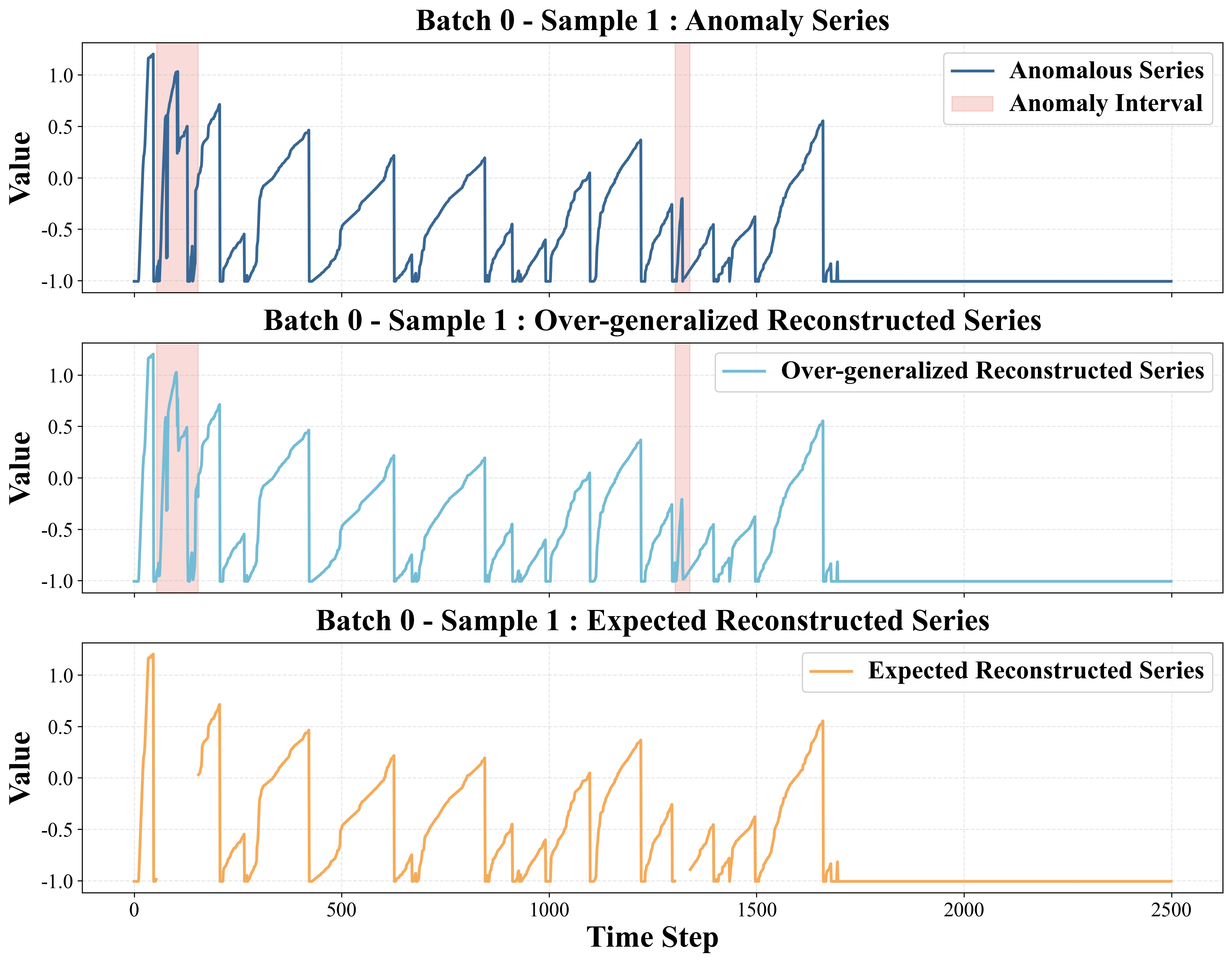
Fig 3: The architecture of SCAN, taking scale number j = 3 as an example.
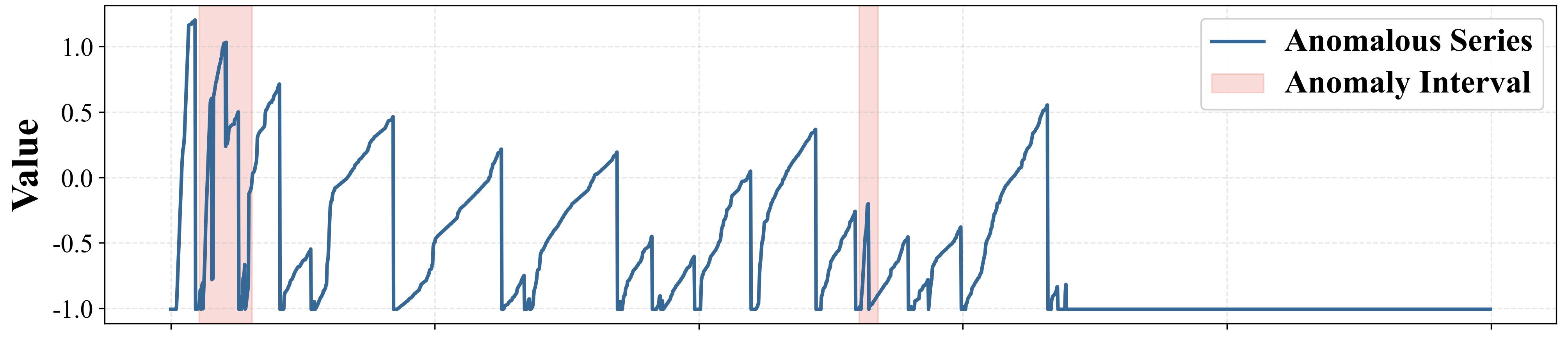
Fig 4 (page 2).
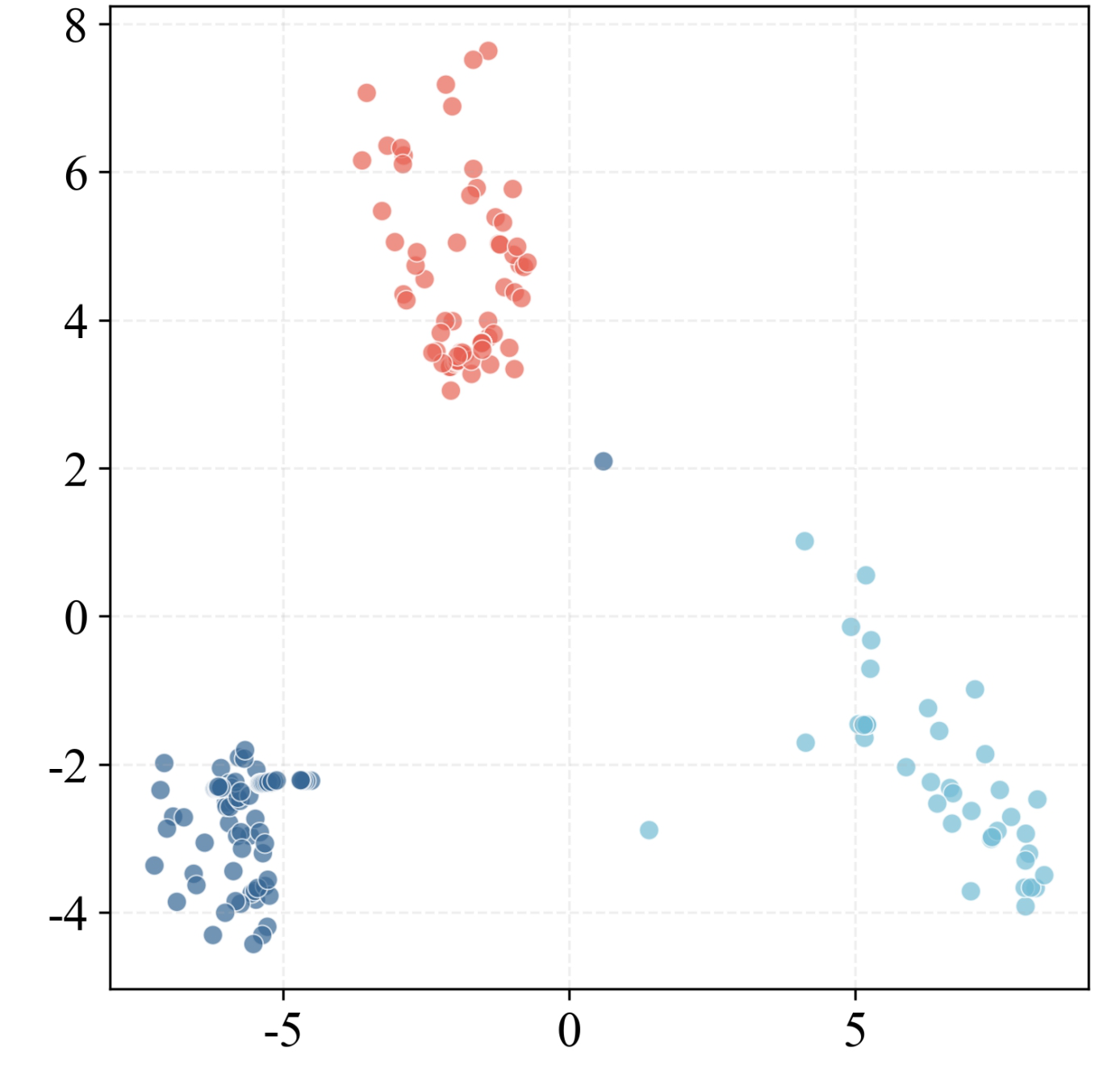
Fig 5 (page 3).
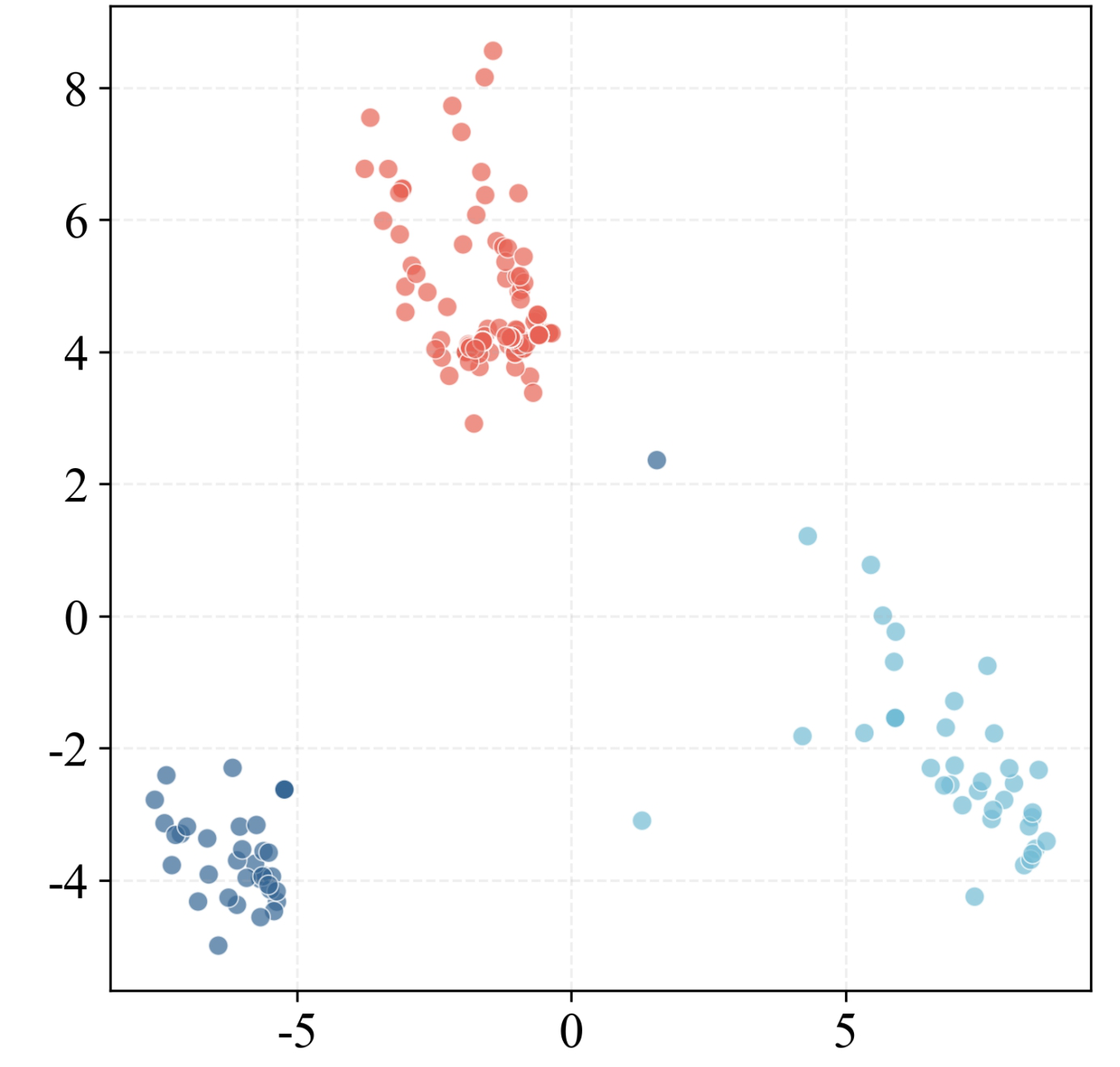
Fig 6 (page 3).
Fig 7 (page 3).

Fig 8 (page 4).
Limitations
- Requires predefining number of clusters K, limiting flexibility and adaptivity to changing normal pattern complexity.
- Clustering quality is crucial — poor clustering can degrade anomaly detection, especially in noisy or heterogeneous data.
- No evaluation under adversarial attacks or deliberate obfuscation of anomalies is presented.
- Lack of analysis on distribution shifts or changes in normal behavior over long-term deployments.
- Unclear if method generalizes well beyond benchmark datasets to extreme cases like high dimensionality or streaming scenarios.
- No explicit details on computational resource requirements or impact of hyperparameter tuning complexity.
Open questions / follow-ons
- How to adaptively determine the number of clusters for varying data complexities without manual tuning?
- Can neighborhood-centered clustering be extended to streaming or online anomaly detection settings with evolving normal behavior?
- What is the robustness of SCAN against adversarial anomalies intentionally designed to evade detection?
- How does SCAN perform under distribution shifts or changes in normal operational modes over time?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, SCAN offers a sophisticated approach to detecting temporal anomalies by combining reconstruction with multi-scale clustering enhanced by neighborhood context. This dual-criterion approach robustly handles the ambiguity between normal variations and subtle attacks or automated behaviors that may otherwise evade detection due to over- or under-generalization. The neighborhood-centered clustering mechanism could inspire similar strategies in time-dependent bot behavioral analytics, helping improve false positive/negative trade-offs common in sequential event streams. However, adapting SCAN to real-time, low-latency CAPTCHA verification and bot detection pipelines would require further work on cluster count adaptivity and computational optimization. Overall, the paradigm of augmenting reconstruction error with clustering-based confidence scores is a promising concept for advanced bot behavior anomaly detection where temporal pattern heterogeneity and complexity challenge standard detectors.
Cite
@article{arxiv2606_19255,
title={ SCAN: Enhance Time Series Anomaly Detection via Multi-Scale Neighborhood-Centered Clustering },
author={ Xingze Zheng and Hanyin Cheng and Siyuan Wang and Yiting Hao and Peng Chen and Yuan Jun and Yang Shu },
journal={arXiv preprint arXiv:2606.19255},
year={ 2026 },
url={https://arxiv.org/abs/2606.19255}
}