
Rethinking Text-to-Image as Semantic-Aware Data Augmentation for Indoor Scene Recognition
Source: arXiv:2606.18555 · Published 2026-06-17 · By Trong-Vu Hoang, Quang-Binh Nguyen, Dinh-Khoi Vo, Hoai-Danh Vo, Minh-Triet Tran, Trung-Nghia Le
TL;DR
This paper addresses the challenge of limited and diverse training data in indoor scene recognition by proposing a novel semantic-aware data augmentation approach using Stable Diffusion (SD), a state-of-the-art text-to-image generative model. Leveraging textual prompts extracted from existing indoor images, they generate a large set of synthetic indoor scenes that capture realistic variations in lighting, textures, and object arrangements. These synthetic images are then filtered for duplicates and outliers to ensure dataset coherence. Experiments on the MIT Indoor Scene dataset show that augmenting training data with SD-generated images improves deep model accuracy, especially when real image availability is limited.
To counteract risks from misuse of synthetic images (e.g., malicious impersonation), the paper also introduces a defense based on Diffusion Reconstruction Error (DIRE). DIRE measures reconstruction discrepancies when an image is processed by a pretrained diffusion model. Using DIRE-based representations, lightweight classifiers like MobileNetV3 can detect Stable Diffusion generated images with perfect accuracy (100%), outperforming naive RGB-based classifiers. Overall, the work presents a dual contribution of enhancing indoor scene recognition via generative data augmentation and securing against synthetic image misuse through an effective detection mechanism.
Key findings
- Using Stable Diffusion generated images as 1:1 augmentation to real training data improves EfficientNetV2 test accuracy on MIT Indoor Scene dataset from 83.5% to 84.2%, a +0.7% absolute gain.
- With limited real data (50% subset), adding generated images raises accuracy from 71.9% to 73.8%, a +1.9% improvement, averaging over 5 random samplings.
- Duplicate and outlier removal using CLIP features with cosine similarity threshold β=0.9825 removes 10% of generated images to maintain diversity and coherence.
- Feature visualization using CLIP embeddings and t-SNE shows augmented images form clusters nearly overlapping with original images, indicating high fidelity of synthetic scenes.
- Recognition of SD-generated images using DIRE representations achieves 100% accuracy with MobileNetV3, training only 2,562 parameters, outperforming larger models trained on RGB images (e.g., ResNet50 achieves 94%).
- Fine-tuning only the last classifier layer on DIRE images yields higher accuracy than training all layers on RGB images, demonstrating DIRE's generalization benefit.
- MobilenetV3 with 4 million parameters surpasses larger networks (>20 million params) in detecting synthetic images using DIRE, making it both effective and computationally efficient.
Threat model
The adversary is assumed to generate synthetic indoor scene images using Stable Diffusion to augment, manipulate, or maliciously repurpose datasets. They can produce realistic images from semantic prompts but cannot directly tamper with DIRE-based detection models trained by defenders. The defender aims to detect and filter synthetic images produced by SD to prevent misuse. The threat model excludes stronger attackers capable of breaking or inverting DIRE representations or black-box attacking detection networks.
Methodology — deep read
Threat Model & Assumptions: The work assumes an adversary capable of generating realistic indoor scene images using Stable Diffusion to augment or manipulate datasets for malicious purposes (e.g., deception). The defender’s goal is twofold: augment limited training data effectively, and detect synthetic images to prevent misuse. Attackers do not have access to the DIRE-based detection mechanism internals but can fully generate synthetic images.
Data: The experiments focus on the MIT Indoor Scene dataset, containing 15,620 images from 67 indoor categories, with 80 training and 20 testing images per category. Augmented images are generated to mirror the original training set size. Prompt generation for SD is done by extracting textual captions from images using CLIP text decoder, rather than random or class name-based prompts, supporting semantic fidelity.
Architecture / Algorithm: The data augmentation pipeline has 3 phases: prompt generation (via CLIP text decoder), image generation (using Stable Diffusion with Realistic Vision checkpoint), and duplicate/outlier removal. Removal operates on extracted CLIP B-L/16 512-D image features, calculating cosine similarity between pairs. Images outside similarity bounds [α,β] and with fewer neighbors are discarded to ensure diversity (β=0.9825, 90% retention rate).
For synthetic image recognition, DIRE images are computed by measuring reconstruction error of images processed through pretrained diffusion-based DDIM inversion. DIRE images serve as input to lightweight classifiers (MobileNetV3) trained to distinguish real from SD-generated images, leveraging compressed but informative synthetic artifact signatures.
Training Regime: Deep classifiers (EfficientNetV2, MobileNetV3, ResNet50, ViT-small, Swin-tiny) pretrained on ImageNet are fine-tuned for 20 epochs with AdamW optimizer, learning rate 0.001, batch size 128. Sparse categorical cross-entropy loss is used. For synthetic image detection, experiments vary training parameters (last layer only vs all layers). MobileNetV3 uses only 2,562 trainable parameters when fine-tuning last layer on DIRE images.
Evaluation Protocol: Train/test splits from MIT Indoor Scene are used for recognition tasks. Augmentation benefit is tested by training models with and without synthetic images at full and 50% real data scales, averaging five random runs at the smaller scale. Synthetic image recognition accuracy is compared across multiple architectures and RGB vs DIRE inputs.
Reproducibility: The paper does not explicitly mention code or data release, but uses publicly known datasets (MIT Indoor Scene) and open models (Stable Diffusion, CLIP, MobileNetV3). Specific SD checkpoint and pipeline details are provided (Realistic Vision checkpoint, CLIP B-L/16). Concrete hyperparameters and steps are described for reproducibility.
Concrete Example: For a single category in MIT, textual prompts are generated from real image captions by CLIP text decoder, then fed into SD to synthesize new images. Generated images undergo feature extraction by CLIP and pairwise similarity analysis; duplicates or outliers are removed below threshold. The filtered synthetic images are combined with original training data to train EfficientNetV2 for indoor category classification. Testing on held-out MIT images shows an accuracy increase from 83.5% (no augmentation) to 84.2% with augmentation. Separately, SD-generated and real images are passed through a pretrained diffusion model to compute DIRE images, then MobileNetV3 is trained on DIRE inputs to discriminate real vs synthetic, achieving 100% classification accuracy. This pipeline highlights both augmentation efficacy and synthesized image detection capability.
Technical innovations
- Use of Stable Diffusion with semantic prompts extracted from real images (via CLIP text decoder) to generate high-fidelity, diverse indoor scene augmentations for improved model training.
- A duplicated and outlier removal scheme based on CLIP image feature cosine similarity thresholds to ensure quality and diversity in synthetic data augmentation sets.
- Application of Diffusion Reconstruction Error (DIRE) representation as a compact and effective feature to detect Stable Diffusion generated images, enabling lightweight classifier usage.
- Demonstration that fine-tuning only the last layer of lightweight models (e.g., MobileNetV3) on DIRE images can achieve 100% synthetic image detection accuracy, outperforming larger RGB-based models.
Datasets
- MIT Indoor Scene — 15,620 images across 67 indoor categories — public
Baselines vs proposed
- EfficientNetV2 without augmentation: accuracy = 83.5% vs with SD augmentation: accuracy = 84.2%
- EfficientNetV2 50% real data without augmentation: accuracy = 71.9% vs with SD augmentation: accuracy = 73.8%
- MobilenetV3 RGB detection (fine-tune last layer): accuracy = 91.2% vs MobilenetV3 DIRE detection (fine-tune last layer): accuracy = 97.2%
- ResNet50 RGB detection (fine-tune last layer): accuracy = 94.0% vs ResNet50 DIRE detection (fine-tune last layer): accuracy not specified
- MobilenetV3 RGB detection (fine-tune all layers): accuracy = 99.9% vs MobilenetV3 DIRE detection (fine-tune all layers): accuracy = 100%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18555.

Fig 1: The dataset synthesis process consists of three key phases: prompt generation, image generation, and duplicated &

Fig 2: SD generated image recognition process includes two phases: DIRE image creation and fake image recognition.
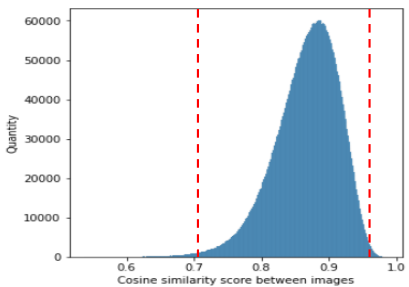
Fig 3: Examples of original images in MIT dataset [5] (top) and our augmented images (bottom).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).

Fig 7 (page 2).

Fig 8 (page 2).
Limitations
- Improvement in indoor scene recognition accuracy with augmentation is modest (+0.7% absolute at full data), limiting transformative impact.
- Duplicate and outlier removal thresholds are empirically chosen without exhaustive ablation or theoretical justification.
- Evaluation focuses only on one dataset (MIT Indoor Scene) and one domain (indoor images); generalization to other scene types or datasets is untested.
- No adversarial robustness testing of DIRE-based synthetic image detection is presented—attackers might adapt generation to evade detection.
- Code and generated synthetic datasets are not explicitly released, limiting immediate reproducibility and external validation.
- The reliance on SD Realistic Vision checkpoint may affect generation diversity and quality; results could vary with other checkpoints or models.
Open questions / follow-ons
- How transferable is the SD-based augmentation approach to other datasets or domains beyond indoor scenes, e.g., outdoor, medical images, or other specialized image types?
- How robust is the DIRE synthetic image detector against adaptive adversaries that attempt to reduce reconstruction error artifacts or mimic real image DIRE patterns?
- Can the duplicate and outlier removal process be further optimized via learned similarity thresholds or clustering to enhance augmentation quality?
- Does combining DIRE with other multi-modal features improve synthetic image detection beyond standalone DIRE?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work illustrates two relevant avenues. First, it shows how text-to-image diffusion models like Stable Diffusion can be harnessed as a powerful domain-specific data augmentation technique, significantly improving recognition model robustness when real data is limited. This is valuable for training robust perception modules in bot-detection or CAPTCHA-solving environments where diverse synthetic data can simulate rare or adversarial inputs.
Second, the DIRE-based synthetic image detection approach presents a lightweight, efficient method to reliably identify AI-generated images, which is crucial for defending against abuse or manipulation of visual CAPTCHA challenges through generative models. The ability to train compact models like MobileNetV3 on DIRE features to achieve near-perfect detection accuracy suggests practical deployability in resource-constrained environments. However, like all synthetic image detectors, ongoing evaluation under adaptive attack scenarios is necessary. Overall, the methods here provide both augmentation tools and detection mechanisms directly applicable to securing vision-based human verification systems against generative model threats.
Cite
@article{arxiv2606_18555,
title={ Rethinking Text-to-Image as Semantic-Aware Data Augmentation for Indoor Scene Recognition },
author={ Trong-Vu Hoang and Quang-Binh Nguyen and Dinh-Khoi Vo and Hoai-Danh Vo and Minh-Triet Tran and Trung-Nghia Le },
journal={arXiv preprint arXiv:2606.18555},
year={ 2026 },
url={https://arxiv.org/abs/2606.18555}
}