
RECOM: A Validity Discrimination Tradeoff in Automatic Metrics for Open Ended Reddit Question Answering
Source: arXiv:2606.19218 · Published 2026-06-17 · By Pushwitha Krishnappa, Amit Das, Vinija Jain, Aman Chadha, Tathagata Mukherjee
TL;DR
This paper addresses a fundamental tension in automatic evaluation metrics for open-ended, opinion-driven question answering by Large Language Models (LLMs). Metrics are expected to simultaneously assess two properties: validity (distinguishing genuinely aligned answers from superficial or random coincidences) and discriminative power (reliably ranking models by quality). Using a newly introduced dataset, RECOM—a contamination-free collection of 15,000 Reddit r/AskReddit questions each paired with authentic community replies that postdate model training cutoffs—the authors systematically evaluate a suite of lexical, semantic, and inference-based metrics across five open-source LLMs (7B to 10B parameters). They find a pervasive tradeoff where metrics that excel at validity fail to discriminate effectively between models, while those that discriminate are less valid. For example, cosine similarity strongly separates real from random replies (Cohen's d ≈ 2) but barely ranks models (|d| < 0.1), whereas BERTScore precision ranks models moderately well (raw |d| up to 0.63) but much of this is explained by response length, collapsing to |d| = 0.09 once length is controlled, and its validity is weaker (d ≈ 0.8). This tradeoff is traced to representation design principles in the metrics rather than the models or data. An LLM-based judge validation corroborates the validity axis and weak model separation. The authors recommend reporting metrics with both validity and discrimination axes accompanied by explicit random baselines. RECOM is released publicly to enable robust evaluation research on open-ended QA tasks.
Key findings
- Cosine similarity attains a large real-vs-random separation with Cohen's d ≈ 2 but inter-model discriminative power is negligible with |d| < 0.1.
- BERTScore precision achieves up to |d| = 0.63 in inter-model discrimination before response length control, which collapses to |d| = 0.09 after residualizing length effects.
- Raw BERTScore F1 scores overstate alignment by 1–3 points compared to random baselines; baseline rescaling exposes a narrower genuine content signal of 6–13 points.
- Response length varies widely across models (mean 11.9 to 32.8 words despite fixed prompt constraints) and explains much of the apparent discriminative power for BERTScore.
- Lexical overlap metrics (BLEU, ROUGE) reliably distinguish real answers from random but do not strongly differentiate between models (e.g., BLEU-1 spans only 21.1%–22.6% across five models).
- MoverScore offers moderate discriminative power (|d| ≈ 0.34 when length-residualized) with a weaker validity gap (~5–6 points) than cosine similarity.
- LLM judges independently reproduce a strong validity gap (Cohen's d = 2.0–3.5) but separate the five models only weakly and with some length sensitivity noted in one judge.
- The validity–discrimination tradeoff stems from metric design, with contrastive sentence encoders amplifying real-vs-random contrast at the cost of between-model variance.
Threat model
The adversary in this context is the evaluation protocol and metric design, which may artificially inflate alignment scores via superficial surface signals or length-related artifacts rather than genuine content matching, potentially misleading model comparison. The authors assume no access to private training data or influence on the authentic Reddit replies used as references. The study presumes contamination-free evaluation by temporal disjointness but does not incorporate adversarial answer generation or attacks on the metrics themselves.
Methodology — deep read
Threat Model & Assumptions: The study is centered on open-ended, opinion-based question answering where ground truth is diffuse consensus rather than objective correctness. The assumed adversary is implicit in the automatic evaluation setting: spurious metric correlations and lack of contamination are addressed by ensuring all Reddit questions and replies (collected September 2025) postdate the training cutoffs (≥ 9 months) of all five evaluated LLMs, removing risk of test data leakage. No adversarial attacks or manipulation are modeled. The metric's role is to distinguish meaningful answer alignment from surface coincidences and rank model quality reliably.
Data: RECOM consists of 15,000 r/AskReddit posts randomly sampled from the top 25,000 posts by engagement collected in Sep 2025 via Pushshift API, filtered down to 11,528 after removing responses containing AI disclaimers or refusals. Each question is paired with its depth-1 community replies (median 14 replies per question, mean 56.2) serving as a multi-reference human ground truth set. This preserves opinion diversity and avoids synthetic references.
Models & Inference: Five open-source dense transformer LLMs between 7B to 10B parameters are evaluated—Mistral-7B, Qwen2.5-7B, Granite3.1-Dense-8B, Falcon3-10B, and Llama-3.1-8B—using uniform prompt instructions limited to under 50 words, identical inference parameters (temperature=0.8, top-p=0.9, top-k=40, seed=42), and served via Ollama on Nvidia RTX A5000 GPUs.
Metrics & Scoring: Models' generated answers are scored against every community reply using multiple families of metrics: lexical (BLEU-1-4, ROUGE-1/2/L), semantic (BERTScore precision, recall, F1 with RoBERTa-large; MoverScore on DistilBERT embeddings; cosine similarity via contrastive sentence transformers all-mpnet-base-v2 and all-MiniLM-L6-v2), and inference-based (natural language inference using BART-large-MNLI with sentence-wise entailment classification aggregated across replies). Scores per post are aggregated by max for lexical and BERTScore metrics (standard practice) or by mean for semantic and inference-based metrics.
Random Derangement Baseline: To quantify validity, a contamination-free noise floor is established by randomly pairing questions with generated answers from unrelated questions (no fixed points) to compute each metric's distribution on random unrelated content while preserving length and style.
Evaluation Protocol: The two key quantities are validity (effect size of metric difference real vs random answers) and discriminative power (max effect size distinguishing any two models' real outputs). Statistical tests use Wilcoxon signed-rank test with paired Cohen's d as effect size measure over n=11,528 posts.
Response Length Control: Because length varied widely (11.9 to 32.8 words) despite constraints, analysis residualized metrics against answer length per post to dissociate length artifacts from genuine rank signals, collapsing BERTScore discrimination but not validity.
LLM-as-Judge Validation: Three independent large LLMs (Phi-4 14B, Gemma-3 27B, Yi-1.5 34B) from different developers were used as human proxies, rating relevance (question-addressing) and faithfulness (alignment with community replies) on a 1–5 scale over 1,000 randomly sampled posts with deterministic zero-temperature prompts. Inter-judge reliability was high (Krippendorff's α≥0.85). Judges confirmed validity gaps but weak model separation. One judge showed slight length bias.
Reproducibility: RECOM and evaluation code are publicly released. Model weights are publicly available. Random seeds and inference parameters are fixed and reported. Some data refinements and prompt templates are detailed in appendices. The dataset and metrics are contamination-free per careful temporal cutoff verification.
Technical innovations
- Introduction of RECOM, a contamination-free, temporally fresh evaluation dataset of 15,000 open-ended Reddit questions paired with authentic human replies as multi-reference ground truth for open-ended QA evaluation.
- Proposal and empirical demonstration of a validity–discrimination tradeoff in automatic evaluation metrics: no metric simultaneously achieves strong separation of real vs random content (validity) and effective inter-model ranking (discrimination) on open-ended, opinion-based tasks.
- Use of a random-derangement noise baseline paired with Cohen’s d effect size to quantify both validity and discriminative power on a commensurate scale, enabling a two-dimensional evaluation of metrics.
- Baseline rescaling of metrics and rigorous response-length residualization to disentangle confounding effects in assessing discriminative power, revealing length-driven artifacts in semantic metrics like BERTScore precision.
- Independent LLM-as-judge protocol using three distinct large models to validate metric validity signals and disentangle length biases.
- Representation-design hypothesis linking the contrastive embedding geometries that enhance validity but collapse between-model variance explaining the observed tradeoff.
Datasets
- RECOM — 15,000 Reddit r/AskReddit questions with 11,528 used after filtering — public release at https://anonymous.4open.science/r/recom-D4B0
Baselines vs proposed
- Cosine similarity (MPNet): validity Cohen's d ≈ 2.0 (real vs random), discriminative power |d| < 0.1 versus best BERTScore precision raw inter-model |d| = 0.63 but length-residualized collapses to 0.09
- BERTScore precision raw: validity d ≈ 0.8, discriminative power |d| up to 0.63; after length control: validity weaker, discrimination collapses to |d| = 0.09
- BLEU-1 max aggregation across refs: real model scores cluster 21.09%–22.63%, random baseline 16.56%, inter-model Cohen’s d negligible (<0.14); no strong model ranking
- MoverScore has moderate discriminative power |d| ≤ 0.37 and validity gap ≈ 5–6 points but less than cosine similarity validity; length residualization leaves discrimination intact.
- LLM judges produce validity effect sizes d = 2.0–3.5 but separate models weakly; one judge shows low but notable correlation (ρ≈0.19) between relevancy and answer length.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19218.
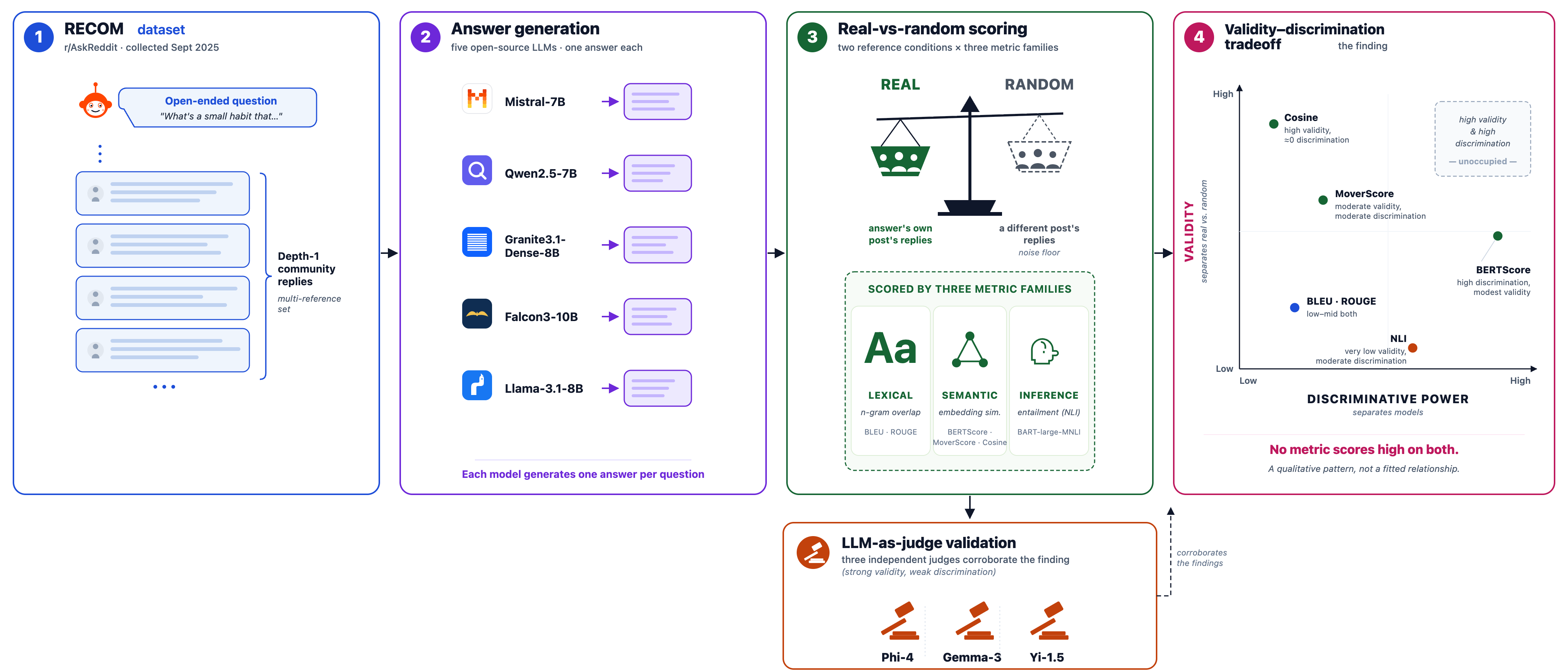
Fig 1: Overview of the RECOM evaluation pipeline: (i) extract Reddit questions and their depth-1 community

Fig 3: Cohen’s d for the real-vs-random difference,
Limitations
- LLM-as-judge validation performed on only 1,000 posts, not full dataset; no human rater calibration reported yet.
- RECOM dataset limited to English r/AskReddit, biased towards high-engagement posts and opinion-driven questions; findings may not generalize to factual QA or other domains.
- Evaluated models are all 7–10B parameter open-source LLMs with 4-bit quantization; wider quality range or non-quantized models might yield different effects.
- Single prompting strategy and decoding parameters used; alternative prompts or retrieval augmentation may influence results.
- Multi-reference evaluation with heterogeneous community replies mixes diverse styles and intentions, complicating aggregation and interpretation.
- Discriminative power axis largely confounded by response length for many metrics; disentangling genuine signal requires more diverse model quality levels.
- Validity axis shows separation of real vs random, but does not guarantee correlation with true answer quality or human preferences.
Open questions / follow-ons
- Does the validity–discrimination tradeoff extend to other open-ended generation tasks such as dialogue, summarization, or long-form QA beyond short opinion QA?
- Can alternative representation learning or metric designs break or mitigate the tradeoff by preserving between-system variance without sacrificing real-vs-random separation?
- How do human raters and calibrated assessments of true answer quality correlate with these automatic metrics’ validity and discrimination axes?
- Would broader LLM model quality ranges or retrieval-augmented prompting regimes produce larger inter-model effect sizes and clarify metric discriminative power?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners working with conversational or open-ended LLM outputs, this work highlights a critical limitation in relying on standard automatic metrics to both verify answer validity and reliably benchmark model quality. The RECOM dataset and paired noise baseline offer a practical framework to calibrate evaluation metrics’ signals and avoid overconfidence in superficial agreement scores. Understanding that metrics like cosine similarity excel in confirming genuine content alignment but fail to differentiate model quality prevents misleading conclusions in operational evaluation pipelines. Conversely, metrics that appear to rank models may conflate response length or fluency with substantive alignment, cautioning against using them alone for bot detection or quality assessment. Practitioners should adopt multi-axis metric reporting with explicit random baselines and consider human- or LLM-judge validations to robustly evaluate open-ended generation quality in security-relevant settings.
Cite
@article{arxiv2606_19218,
title={ RECOM: A Validity Discrimination Tradeoff in Automatic Metrics for Open Ended Reddit Question Answering },
author={ Pushwitha Krishnappa and Amit Das and Vinija Jain and Aman Chadha and Tathagata Mukherjee },
journal={arXiv preprint arXiv:2606.19218},
year={ 2026 },
url={https://arxiv.org/abs/2606.19218}
}