
No Two Developers Think Alike: How Problem-Solving Styles and Experience Shape Needs in Conversational Interaction with Copilot
Source: arXiv:2606.19216 · Published 2026-06-17 · By Jonan Richards, Bruno Alves de Oliveira, Iury Oliveira, Igor Wiese, Mairieli Wessel
TL;DR
This paper studies how developers with different problem-solving styles and experience interact with conversational programming assistants, focusing on GitHub Copilot Chat. Through a mixed-methods think aloud study of 27 professional developers and students performing code change tasks, the authors identify five distinct interaction modes by analyzing prompt content and sequences using topic modeling. The modes range from exploratory codebase navigation to full problem automation. Additionally, they inductively uncover ten underlying developer needs (e.g. need for ability, agency, assurance) that shape these interaction styles. The authors link interaction modes and needs to developers’ cognitive diversity—measured via problem-solving style questionnaires and experience profiles—highlighting how diverse cognitive factors drive different uses and expectations of AI assistants. The resulting conceptual model explains interrelations between interaction patterns, user needs, experience, and cognitive styles.
The study reveals significant heterogeneity in how developers engage with Copilot Chat, with interaction modes distributed differently across practice vs. full tasks and correlated to individual cognitive traits. For instance, the Autopilot mode—delegating end-to-end solutions—was more common in full tasks and among those with lower need for control, while Deputy mode—collaborative incremental problem solving—was dominant overall. Participants’ needs for agency, experimentation, and assurance influence their willingness to delegate tasks to the assistant or control its outputs tightly. This analysis provides an empirically grounded, nuanced understanding of how cognitive diversity shapes conversational programming assistant usage, relevant to designing more inclusive AI tooling.
Key findings
- Five interaction modes with GitHub Copilot Chat were identified: Navigator, Autopilot, Deputy, Technician, and Scholar (Fig 2, 3).
- Deputy mode dominated overall usage and involved collaborative incremental problem solving with many prompts per task (Fig 2).
- Autopilot mode, featuring high-level prompts and usage of the 'apply' button, was used more in full tasks, involving fewer prompts per task (Fig 3).
- Participants showed high diversity in cognitive profiles measured by experience (PCA composite) and problem-solving style (GenderMag), explaining significant variation in interaction modes.
- Ten core developer needs were characterized (e.g. need for ability, agency, experimentation, assurance) that drive interaction mode choices (Fig 4).
- Need for agency and pride correlated with decreased delegation and higher need for control, whereas need for ability correlated with increased delegation (Fig 4).
- Prompt length and reuse patterns varied significantly between modes; Technician and Scholar modes had shorter, granular prompts (Fig 3).
- CLR-transformed mode distributions correlated significantly with experience, problem-solving style, cognitive load, perceived ease of use and usefulness (detailed in Section IV.C).
Threat model
n/a — the study does not focus on adversaries or attacker models but on developer cognition and interaction with AI programming assistant tools.
Methodology — deep read
Threat model & assumptions: The adversary model is implicit as the focus is on cognitive diversity influencing interaction with programming assistants, not security. The assumption is users have typical developer capabilities and use Copilot Chat in an IDE setting, with varying experience and cognition.
Data: 27 participants (18 professionals, 9 students) with diverse nationalities, genders, and programming backgrounds took part. Pre-study survey collected experience across JavaScript, React, web dev, and Copilot usage frequency. Cognitive diversity measured using GenderMag problem-solving style questionnaire (5 facets). Participants completed up to 6 code-change tasks on a React demo codebase, with 3 practice and 3 full tasks, over ~40 minutes.
Architecture / algorithm: Interaction mode discovery used natural language processing techniques on participant prompts. Each Copilot prompt was manually annotated along multiple semantic axes (intent, context, strategies). Latent Dirichlet Allocation (LDA) was applied to prompts to identify 16 prompt types, then Non-Negative Matrix Factorization (NMF) was used over sliding windows of prompt sequences to extract 5 interaction modes per participant-task via probability distributions.
Training regime: Topic modeling hyperparameters (number of topics, window size) were optimized empirically for interpretability and stability. Manual annotation was iteratively refined. Translation of transcripts from Portuguese to English used GPT-4o with human validation.
Evaluation protocol: Interaction modes characterized by prompt length, number of prompts, example prompts (Fig 3). Needs driving interactions identified by qualitative grounded theory analysis on think aloud and interview transcripts, coding expressed motivations and preferences into 10 need categories. Correlations between transformed mode distributions and cognitive profiles, task load (NASA TLX), and Technology Acceptance Model (TAM) scores were calculated using Spearman's rank.
Reproducibility: Extensive replication package released including study materials, anonymized transcripts, chat logs, adapted telemetry extension, and codebase. Data collected March-May 2025. Data and code public at reference [30].
Empirical Example: One participant using Deputy mode would issue a sequence of incremental prompts referencing code in the active file, manually copy/pasting partial solutions, and frequently ask for explanation of Copilot’s outputs. Their transcripts reveal need for agency and assurance guiding their interaction, fitting the qualitative conceptual model. This contrasts with an Autopilot mode user copying entire task instructions to Copilot and applying suggested code wholesale with minimal prompts.
Technical innovations
- Combined manual semantic annotation of LLM programming assistant prompts with multi-level topic modeling (LDA followed by NMF on prompt sequence windows) to identify developer interaction modes.
- Introduced a conceptual model linking quantified interaction modes and inductively derived developer needs to cognitive diversity measures (experience and problem-solving styles).
- Applied centered log-ratio (CLR) transformation and correlation analyses to compositional interaction mode distributions for rigorous quantitative linkage.
- Integrated qualitative grounded theory coding of think-aloud and retrospective interview data with quantitative NLP-based interaction mode extraction for mixed-methods insight.
Datasets
- 27 professional and student developers — 27 participants — recruited via professional networks and snowball sampling, data collected remotely using GitHub Codespaces
- React TodoMVC demo codebase — medium-scale popular open source project — used for coding tasks
Baselines vs proposed
- No direct competitive baselines reported; comparison derived from task-level variation and participant cognitive profiles correlated with usage metrics.
- Compared interaction modes quantitatively by prompt count and length (Fig 3).
- TAM and NASA-TLX scores correlated with mode distributions demonstrating validity of identified interaction modes against perceived ease of use and cognitive load.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19216.
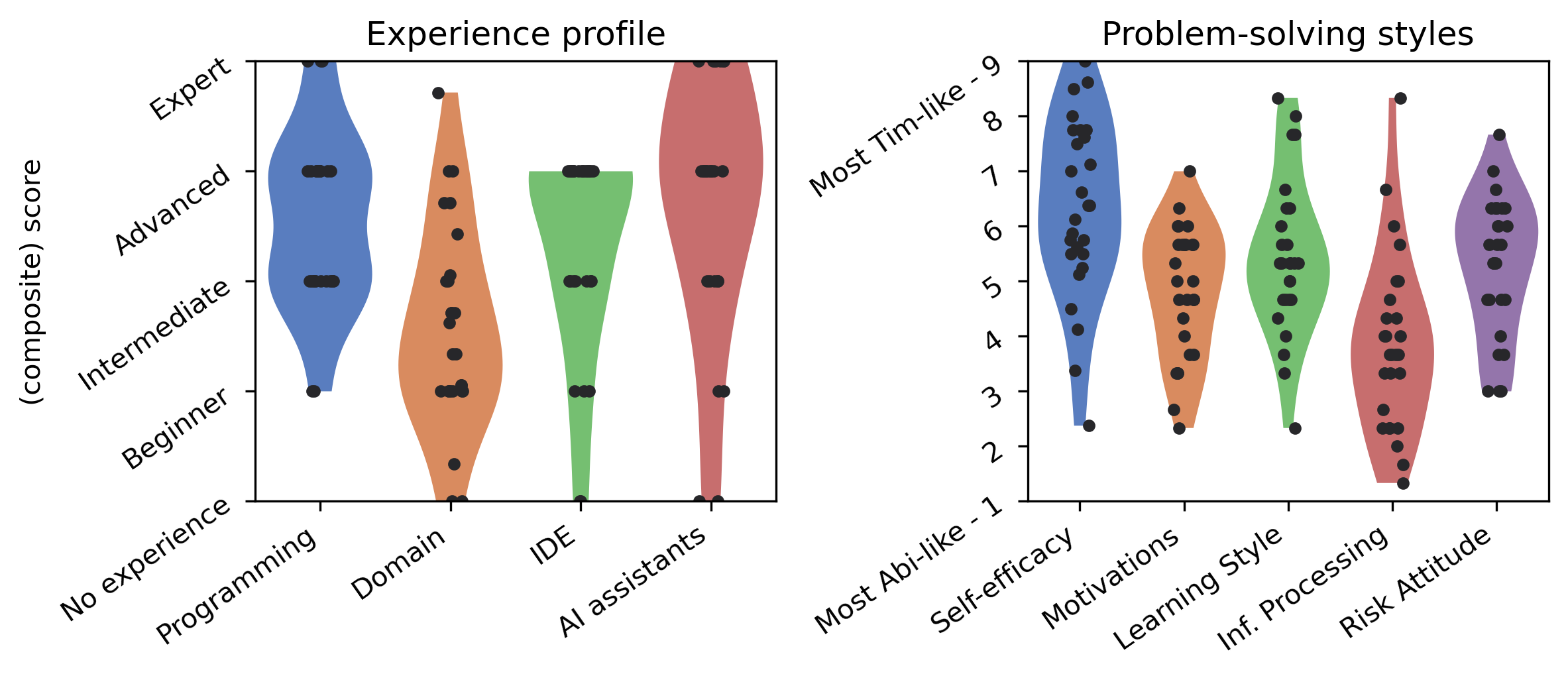
Fig 1: shows broad variation in our participants’ experi-
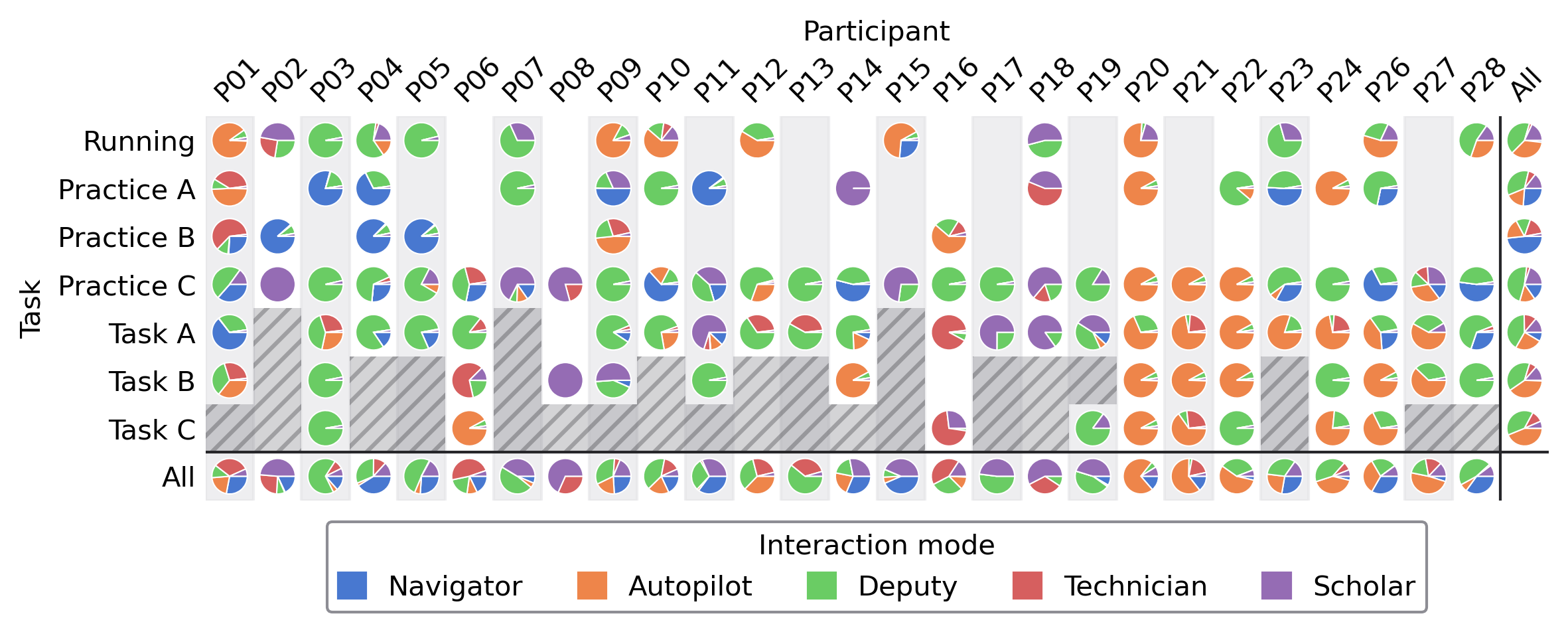
Fig 2: shows participants’ interaction modes per task,
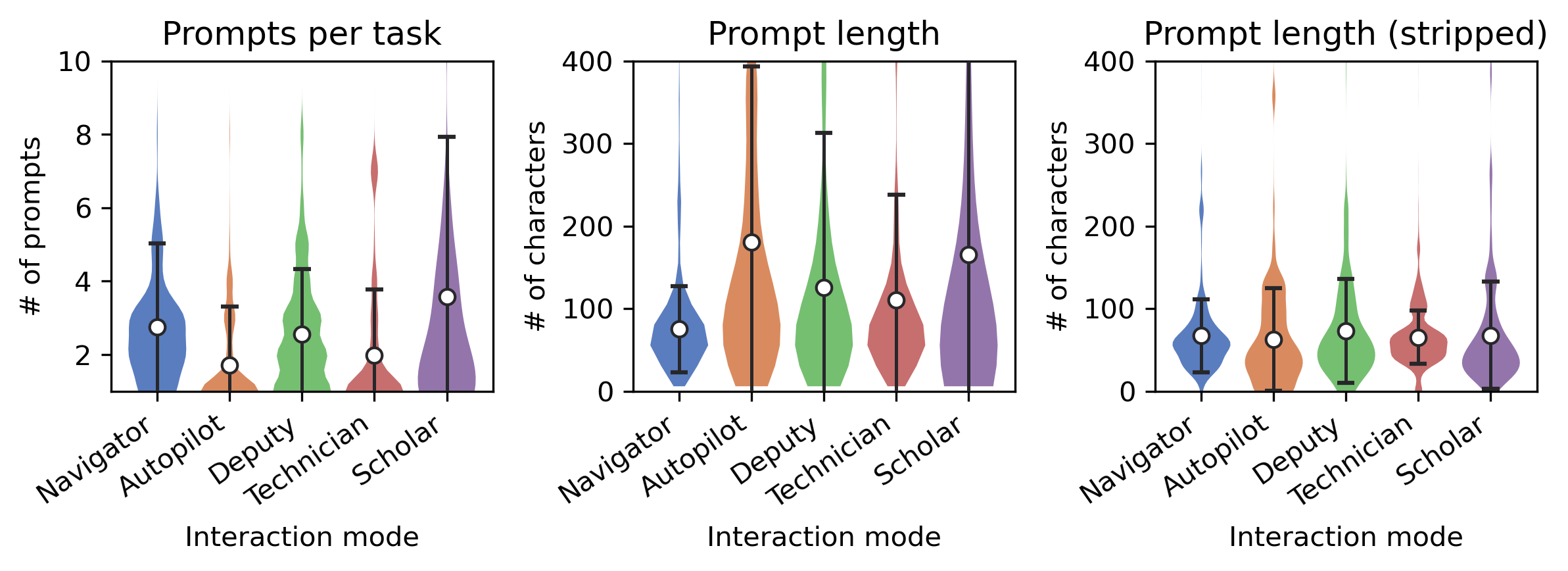
Fig 3: Expected distributions per mode of the number of prompts per task,
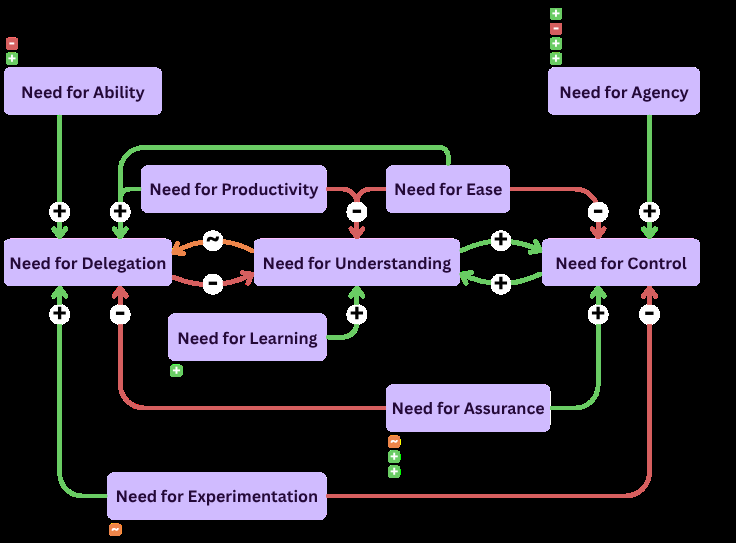
Fig 4: Developer needs (purple) and interaction modes (blue) when in-
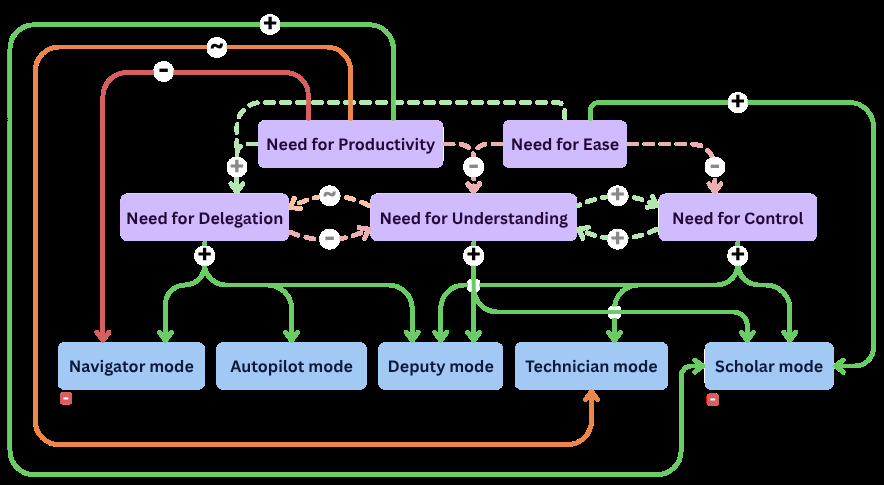
Fig 5: shows several significant weak to strong corre-

Fig 6 (page 8).
Limitations
- Sample size limited to 27 participants, with gender imbalance (only 4 female participants).
- Order effects present as practice tasks always occurred before full tasks, and not all participants completed all full tasks.
- Interaction limited to a single programming assistant (GitHub Copilot Chat) and one codebase domain (React demo), limiting generalizability.
- No adversarial evaluation or longitudinal usage data were collected.
- Task selection and structure constrained to code change tasks; other software engineering activities were not studied.
- Cognitive diversity measurement relied on GenderMag questionnaire that captures only some facets of cognitive style and stengths.
Open questions / follow-ons
- How do interaction modes and needs vary with other programming languages, domains, or more complex codebases?
- Can dynamic adaptation of conversational assistants improve support for diverse cognitive styles identified here?
- How stable are individual developer interaction modes over long-term continuous usage of AI assistants?
- What are the impacts of identity factors beyond experience and problem-solving styles, e.g. gender, culture, or personality, on interaction with programming assistants?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study provides a nuanced understanding of how variation in user cognitive styles and experience can profoundly shape interaction patterns with conversational AI agents. While the paper focuses on programming assistants, the insights about diverse human-AI interaction modes and the underlying needs that drive user behavior have broader implications.
When designing AI-based user verification or anti-bot challenges that involve conversational or interactive elements, developers need to consider that users may approach tasks with different problem-solving styles—some more exploratory, some delegatory, some demanding incremental control. Applying thoughtful, flexible interaction designs that account for such cognitive diversity can improve inclusivity and reduce friction for genuine users while enhancing detection of automated or bot-like usage patterns. This work suggests that measuring user interaction modes or needs dynamically could inform adaptive bot-defense mechanisms as well.
Cite
@article{arxiv2606_19216,
title={ No Two Developers Think Alike: How Problem-Solving Styles and Experience Shape Needs in Conversational Interaction with Copilot },
author={ Jonan Richards and Bruno Alves de Oliveira and Iury Oliveira and Igor Wiese and Mairieli Wessel },
journal={arXiv preprint arXiv:2606.19216},
year={ 2026 },
url={https://arxiv.org/abs/2606.19216}
}