
HANSEL: Extracting Breadcrumbs from Web Agent Trajectories for Interactive Verification
Source: arXiv:2606.18671 · Published 2026-06-17 · By Yujin Zhang, Daye Nam
TL;DR
HANSEL addresses the challenging problem of verifying complex multi-step tasks performed by AI web agents, such as product search and comparison, where users often face overwhelming and unstructured logs or unfaithful natural language rationales. Existing approaches—full execution logs, source links, screenshots, and LLM-generated summaries—treat verification as a passive reading task, failing to help users efficiently trace how an agent arrived at its answer or identify errors. HANSEL innovates by extracting a minimal sufficient subset of evidence pages and relevant content snippets from an agent's web navigation trajectory and reconstructing these pages as interactive views that preserve the agent’s encountered page state (filters, search queries, scroll position), allowing users to actively explore and verify the evidence supporting the agent's output. The system flags when answers cannot be linked to visited pages, enhancing error visibility.
Technically, HANSEL uses a standardized intermediate representation of agent trajectories and leverages an LLM to identify evidence pages and snippets. These interactive evidence pages are presented via an Electron-based interface embedding live browser instances where users can inspect, scroll, and modify filters themselves, reducing verification overhead. Evaluated on 45 tasks drawn from AssistantBench and Online-Mind2Web, HANSEL achieved 83.7% precision and 88.8% recall in evidence page identification and reduced verification complexity by 61.6%. A controlled user study with 14 participants showed HANSEL reduced verification time and perceived effort while improving usability and error recognition compared to baseline agent interfaces. Overall, HANSEL reframes agent verification from passive consumption to interactive engagement, enabling more efficient, accurate human oversight of AI web agents.
Key findings
- HANSEL achieves 83.7% precision and 88.8% recall on identifying evidence pages across 45 tasks from AssistantBench and Online-Mind2Web, with an F1 score of 0.861 (Table 2).
- HANSEL reduces the average trajectory volume from 271 pages to 104 evidence pages, a 61.6% reduction in verification data load.
- Only 25.34% of agent trajectory steps and 36.16% of pages on average contribute to final answers, validating that targeted evidence extraction is feasible.
- User study with 14 participants shows significant reduction in task completion time and perceived verification effort using HANSEL over standard interfaces.
- Participants rated HANSEL significantly higher on usability, ease of verification, and error identification (no exact user score numbers provided).
- Inter-annotator agreement for evidence labeling reached Cohen’s Kappa 0.803 (steps) and 0.878 (pages), indicating reliable ground-truth annotations.
- HANSEL captures and reconstructs critical page state (filters, search queries, scroll positions) to allow live, interactive verification rather than static snapshots or plain URLs.
- HANSEL explicitly flags when agent answers cannot be traced to any visited page, helping users detect unsupported claims.
Threat model
The adversary is the autonomous AI web agent that may produce incorrect or unsupported answers by visiting irrelevant pages, failing to apply proper filters, or hallucinating rationales. The adversary's traces (execution logs and page visits) are assumed available but overwhelming. The user or verifier cannot actively monitor the agent during execution but inspects post-hoc. The adversary cannot forge logs or completely hide pages visited. The threat is erroneous or unverifiable agent output leading to user trust in wrong results.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicitly the AI web agent performing complex navigation tasks autonomously. The user must verify whether the agent's multi-step output is correct given logs of the agent's interaction with websites. The assumption is that the agent trajectory logs and final answers are available, but the user is burdened by overwhelming logs, incomplete context, or unfaithful explanations from the agent. HANSEL aims to facilitate trustworthy verification by extracting factual evidence pages. The adversary cannot hide pages visited in the logs; the logs faithfully record agent actions.
Data: The authors analyze 45 web navigation tasks (22 from AssistantBench, 23 from Online-Mind2Web) with detailed agent trajectory logs from the HAL framework using top-performing models (o3-medium for AssistantBench, Claude Sonnet 4 for Online-Mind2Web). AssistantBench tasks have ground-truth answers; Online-Mind2Web tasks were filtered to those with verifiable answers. Trajectories have step-level and page-level annotations of evidence versus non-evidence by two annotators with high inter-rater reliability (Cohen’s Kappa 0.803 steps, 0.878 pages). The dataset totals 592 steps and 271 pages.
Architecture / Algorithm: HANSEL first standardizes raw heterogeneous agent logs (from different execution scaffolds like LangChain or HAL) into a sequence of <observation, reasoning, action> steps. An observation captures the page state (HTML/DOM), reasoning is the agent's internal thought, action is a browser operation (click, type, scroll).
The core technical component is an LLM-based evidence extractor. Given user input query, final agent answer, and the standardized trajectory steps, HANSEL's LLM classifies which pages in the trajectory constitute evidence supporting the final answer and extracts evidence snippets (specific page text relevant to the reasoning). The LLM is prompted to discard abandoned or failed navigation branches, redirects, or blocked pages.
Subsequently, the system reconstructs evidence pages in an interactive interface by replaying the relevant UI actions (clicks, typed input, scrolls, filter selections) to preserve the exact page state where evidence appeared. Evidence snippets are highlighted on the live embedded pages.
Training Regime: Not applicable in traditional ML training sense, as HANSEL does not train a separate model but leverages an existing LLM (GPT-5.4) in a zero-shot or few-shot prompting pipeline with fixed temperature 0.7 to perform evidence extraction.
Evaluation Protocol: Technical evaluation quantifies page-level evidence extraction precision, recall, and F1 by comparing automatic extraction against manually annotated ground truth on 45 tasks. Snippet-level precision is also measured by manual review. User study involves 14 participants completing verification tasks comparing HANSEL versus standard agent verification interfaces measuring completion time, perceived effort, accuracy, and qualitative questionnaire ratings.
Reproducibility: The authors provide supplementary materials and code at https://github.com/cloudsreal/hansel_study.git. Raw data includes sensitive interaction logs from third-party websites, so full dataset release may be limited. LLM usage details (model version GPT-5.4, temperature) are disclosed but no training code or weights are released since the core model is proprietary. The pipeline and interface implementations use open frameworks (Python, React, Electron).
Technical innovations
- Formulation of agent evidence extraction as a task of identifying a minimal sufficient set of web pages and snippets supporting the agent's answer from complex navigation trajectories.
- Use of large language models to automatically parse heterogeneous agent execution logs into evidence pages and snippets while filtering out irrelevant navigation steps.
- Interactive evidence verification interface embedding live reconstructed web pages with preserved filters, scroll positions, and search queries to enable direct user interaction with evidence.
- Explicit reasoning visualization with grid and carousel views presenting evidence pages with concise action summaries and highlighted snippets to improve user comprehension.
Datasets
- AssistantBench — 33 tasks (22 used) — public benchmark for web navigation tasks with ground-truth answers
- Online-Mind2Web — 300 tasks (23 sampled) — public benchmark with realistic web navigation tasks from multiple sites
Baselines vs proposed
- Baseline (full agent trajectory logs): verification burden is high due to 271 pages visited on average across 45 tasks.
- HANSEL: reduces trajectory data to 104 evidence pages (61.6% reduction), with 83.7% precision and 88.8% recall in identifying evidence pages (F1=0.861).
- User study baseline interface vs HANSEL: HANSEL significantly reduces task completion time and perceived effort; actual accuracy improvement is a positive trend but not statistically detailed.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18671.

Fig 1: Verifying web agents often involves inspecting long and complex trajectories (e.g., 14 steps, 6 pages visited). HANSEL

Fig 2 (page 1).
Fig 3 (page 1).
Fig 4 (page 1).
Fig 5 (page 1).
Fig 6 (page 1).
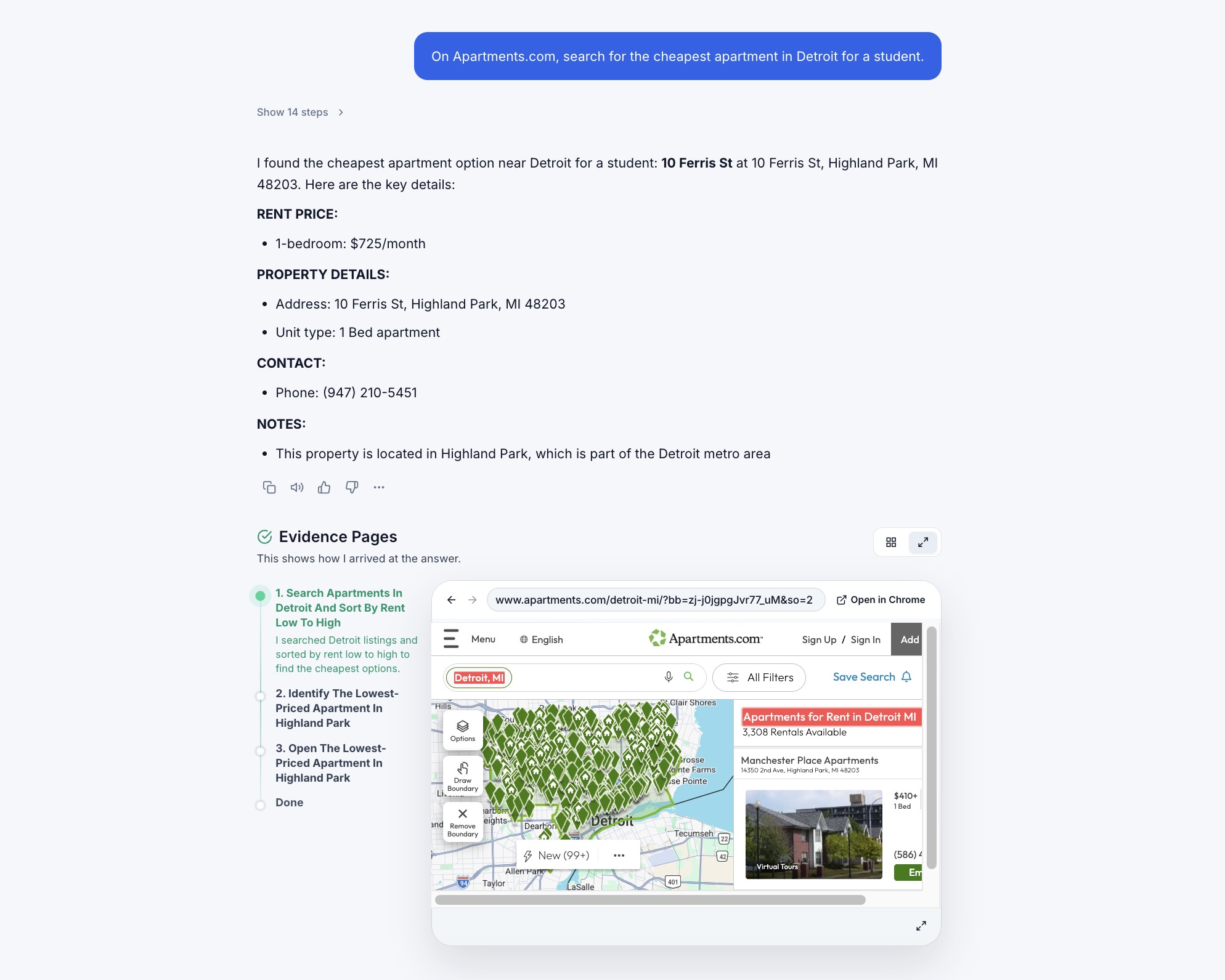
Fig 2: HANSEL identifies a subset of visited pages from web agent trajectories and presents them as interactive evidence
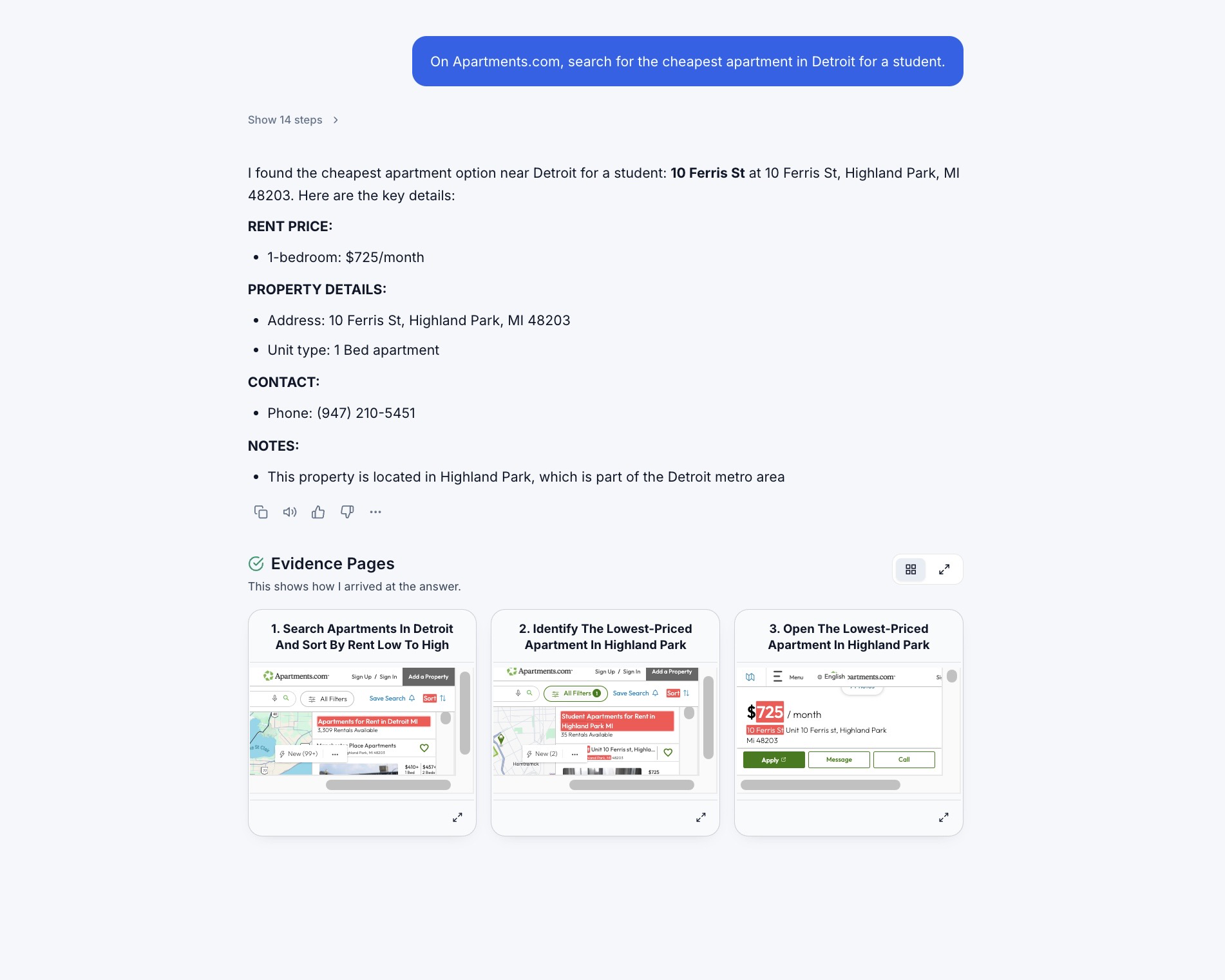
Fig 8 (page 5).
Limitations
- Limited sample size in user study (14 participants) may constrain generalizability of usability results.
- Evaluation focuses on multi-step web search/navigation tasks with verifiable ground truths; applicability to open-ended or creative tasks is unclear.
- Reliance on LLM (GPT-5.4) prompts for evidence extraction may be brittle or vary with model updates; no adversarial robustness testing reported.
- Partial reliance on manually annotated ground truth for evaluation means some subjectivity in evidence step/page labeling remains despite high agreement.
- Inability to fully capture dynamic or real-time web agent failures beyond navigation and filtering errors; deeper reasoning errors may be harder to detect.
- Potential limitations embedding live pages due to iframe restrictions requiring Electron-based desktop client could affect broad deployment.
Open questions / follow-ons
- Can LLM-based evidence extraction generalize to other agent modalities beyond web navigation, such as API calls or document interactions?
- How does HANSEL perform under adversarial agents explicitly attempting to deceive verification by obfuscating navigation steps?
- What is the effect of integrating real-time monitoring or mixed-initiative co-planning with post-hoc verification like HANSEL?
- Can evidence extraction and interactive verification scale to very long or parallel multi-agent trajectories without overwhelming users again?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, HANSEL's approach highlights the importance of interactive, context-preserving verification of automated agent actions rather than static logs or summaries that are prone to overload or hallucination. In complex web automation tasks where bots perform multi-step interactions, providing users with distilled interactive evidence supports better detection of bot misbehavior or manipulation by enabling active probing of bot decisions. Additionally, HANSEL’s method of preserving page state such as filters and query parameters is valuable where bot activity is subtle and embedded in filtering or navigation paths rather than brute force. While primarily aimed at legitimate AI assistants, the principles may inform defenses where verifying bot transparency or identifying unverifiable bot behavior is critical. This underscores that CAPTCHAs or bot challenges could be augmented with evidence-driven interfaces to expose suspicious or unverifiable automation traces interactively rather than only blocking or logging them passively.
Cite
@article{arxiv2606_18671,
title={ HANSEL: Extracting Breadcrumbs from Web Agent Trajectories for Interactive Verification },
author={ Yujin Zhang and Daye Nam },
journal={arXiv preprint arXiv:2606.18671},
year={ 2026 },
url={https://arxiv.org/abs/2606.18671}
}