
Forged Calamity: Benchmark for Cross-Domain Synthetic Disaster Detection in the Age of Diffusion
Source: arXiv:2606.18554 · Published 2026-06-17 · By Duc-Manh Phan, Quoc-Duy Tran, Duy-Khang Do, Anh-Tuan Vo, Hai-Dang Nguyen, Trong Le Do et al.
TL;DR
This paper addresses the urgent challenge posed by highly photorealistic synthetic disaster imagery generated by state-of-the-art text-to-image diffusion models, which increasingly blur the line between real and fake content in critical domains such as cybersecurity, digital forensics, and disaster response. It introduces Forged Calamity, a novel large-scale benchmark dataset containing 30,000 images—6,000 real disaster images across fire, earthquake, flood, and thunderstorm categories from the Incident-1M dataset, and 24,000 synthetic counterparts generated by four modern diffusion models: Stable Diffusion 1.5, 2.0, XL, and PixArt. This comprehensive dataset enables rigorous evaluation of model generalization across both semantic (disaster category) and generative (diffusion model) shifts.
Through extensive empirical evaluations spanning both fine-tuned classifiers and zero-shot detectors using multiple vision backbones—including convolutional and transformer architectures, as well as state-of-the-art deepfake detection methods—the authors reveal persistent, severe generalization failures. Fine-tuned detectors achieve high accuracy when tested on in-distribution data from their training diffusion model and disaster category but lose up to 50% accuracy on unseen generators or disaster types, exposing overfitting to model-specific artifacts rather than universal cues. Zero-shot detectors demonstrate limited and inconsistent robustness across diffusion models, highlighting the current inability of forensic methods to handle the heterogeneous and evolving diffusion model landscape. These results lay bare critical bottlenecks in synthetic image detection and emphasize the need for domain- and model-agnostic approaches to reliably ensure visual authenticity in the diffusion era.
Key findings
- Forged Calamity benchmark dataset comprises 30,000 disaster images: 6,000 real and 24,000 synthetic from 4 diffusion models (SD 1.5, SD 2.0, SD XL, PixArt) across 4 disaster categories.
- Fine-tuned detectors achieve >90% accuracy in-distribution on training diffusion model and disaster category (e.g., SD 1.5 earthquake), but accuracy drops by up to 50% when evaluated on unseen generators or disaster categories.
- Transformer-based backbones (Swin, ViT) generalize better than CNNs (ConvNeXt, ResNet152), e.g., ConvNeXt accuracy falls from 98.1% to 49.7% on thunderstorm images from PixArt vs SD 1.5.
- State-of-the-art deepfake detectors like CGL and FreqNet excel on known generators but degrade sharply on newer generators (SD 2.0, SD XL), indicating overfitting to source model artifacts.
- Zero-shot generalized detectors (ADOF, SPAI, DAE) show partial robustness, with ADOF achieving near-perfect accuracy on some advanced diffusion models but inconsistently across categories.
- Semantic OOD (cross-disaster category) and generative OOD (cross-diffusion model) are both significant challenges, with consistent accuracy degradation in both scenarios.
- Failure cases reveal modern detectors struggle with nuanced artifacts, lighting composition, and fine details, often misclassifying photorealistic synthetic images that closely mimic real counterparts.
Threat model
The adversary can generate highly realistic synthetic images of natural disasters using state-of-the-art text-to-image diffusion models unknown to the detector. They may produce images across multiple disaster types and generator architectures. The defender’s detector has access to some real and synthetic samples from a single generator and category during training but cannot anticipate or fine-tune on unseen generators or disaster types during deployment. The adversary cannot manipulate metadata or embed cryptographic proofs but relies solely on visual fabrications.
Methodology — deep read
The study begins by defining the threat model: adversaries can generate highly photorealistic disaster images (fire, earthquake, flood, thunderstorm) using multiple advanced diffusion models unknown to the forensic detector, which must distinguish these fakes from real images collected from social media and Incident-1M datasets. The attacker aims to produce fake disaster images capable of misleading digital forensics and emergency responses.
Data collection sourced 6,000 real images (1,500 per disaster category) selected for quality and semantic relevance from Incident-1M and web sources. The synthetic dataset consists of 24,000 images (6,000 per diffusion model) generated via a two-stage pipeline: first, detailed textual prompts about disaster scenarios were crafted using Moondream and distilled with Llama 3 to concise text prompts suitable for text-to-image models. Four diffusion models (Stable Diffusion 1.5, 2.0, XL, and PixArt) each produced 1,500 images per disaster type, with similarity-based filtering to reduce redundancy, yielding a balanced dataset of real and synthetic images.
The central binary classification task is to detect real vs synthetic images. For training, the authors fine-tune classification models exclusively on the earthquake category generated by Stable Diffusion 1.5, using 1,500 real and 1,500 synthetic images. This controlled in-distribution setting measures baseline detection capability.
For evaluation, two out-of-distribution (OOD) scenarios were devised:
- Semantic OOD: testing on new disaster types (fire, flood, thunderstorm) with synthetic images from the known generator (SD 1.5).
- Generative OOD: testing on all disaster types generated by unseen diffusion models (SD 2.0, SD XL, PixArt).
Evaluation employed multiple deep vision backbones: CNNs (ResNet152, ConvNeXt), transformers (ViT, Swin), and foundation-model-based deepfake detectors (RINE, UA, LGrad, DIRE, FreqNet, ADOF, CGL) for fine-tuning setting. Zero-shot evaluation leveraged state-of-the-art pretrained synthetic image detectors (UniFD, DAE, SPAI, FatFormer, ADOF, CGL) without Forged Calamity fine-tuning to assess baseline robustness.
Models were trained with standard fine-tuning hyperparameters on GPUs from the Intelligent Systems Lab at VNU-HCM, with evaluation metrics focused on classification accuracy per test subset, highlighting generalization gaps. No mention of statistical significance tests or cross-validation; training used fixed seeds but details limited.
One concrete example: training a ConvNeXt classifier on earthquake images from SD 1.5 real and synthetic data, then testing on thunderstorm images from PixArt showed accuracy plummeting to 49.7%, emphasizing domain and generator shift issues.
Code or pretrained weights are not explicitly released, and the dataset will be maintained by the authors. The benchmark provides a reproducible framework for synthetic disaster detection research.
Technical innovations
- Creation of the Forged Calamity dataset, the first large-scale, balanced benchmark of synthetic disaster images spanning 4 disaster types and 4 state-of-the-art diffusion models, designed to study cross-domain and cross-model generalization in synthetic image detection.
- A rigorous evaluation protocol simulating realistic forensic scenarios with semantic and generative out-of-distribution testing to systematically quantify model generalization gaps across unseen disaster categories and diffusion architectures.
- Comprehensive empirical benchmarking of diverse vision backbones and specialized deepfake detectors under fine-tuned and zero-shot settings on the challenging Forged Calamity dataset, exposing systematic overfitting to diffusion model fingerprints.
- Demonstration that transformer-based architectures (Swin, ViT) surpass CNNs in synthetic disaster image detection generalization, emphasizing the importance of global attention mechanisms for recognizing subtle generative artifacts.
Datasets
- Forged Calamity — 30,000 images (6,000 real + 24,000 synthetic) — real images from Incident-1M dataset and web, synthetic from SD 1.5, SD 2.0, SD XL, PixArt diffusion models
- Incident-1M (subset) — 6,000 real disaster images filtered for relevance in four categories
Baselines vs proposed
- ConvNeXt: 98.1% accuracy on SD 1.5 earthquake (in-distribution) vs 49.7% accuracy on PixArt thunderstorm (unseen generator & disaster)
- ViT: 88.13% accuracy on real fire (unseen category) vs 68.0% on PixArt fire synthetic (unseen generator & category)
- CGL detector: near 100% accuracy on real unseen categories and SD 1.5 synthetic but drops to 0.70% on SD 2.0 fire synthetic
- ADOF zero-shot: nearly 100% accuracy on SDXL and PixArt images but drops on SD 2.0 fire images (~29.02%)
- RINE detector: 93.33% accuracy on PixArt earthquake but only 1.59% on FreqNet for Earthquake PixArt synthetic test
- FAFormer zero-shot detector: consistently low accuracy across all synthetic generators (below 30%)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18554.

Fig 1: Representative examples of natural disaster categories from the Incident-
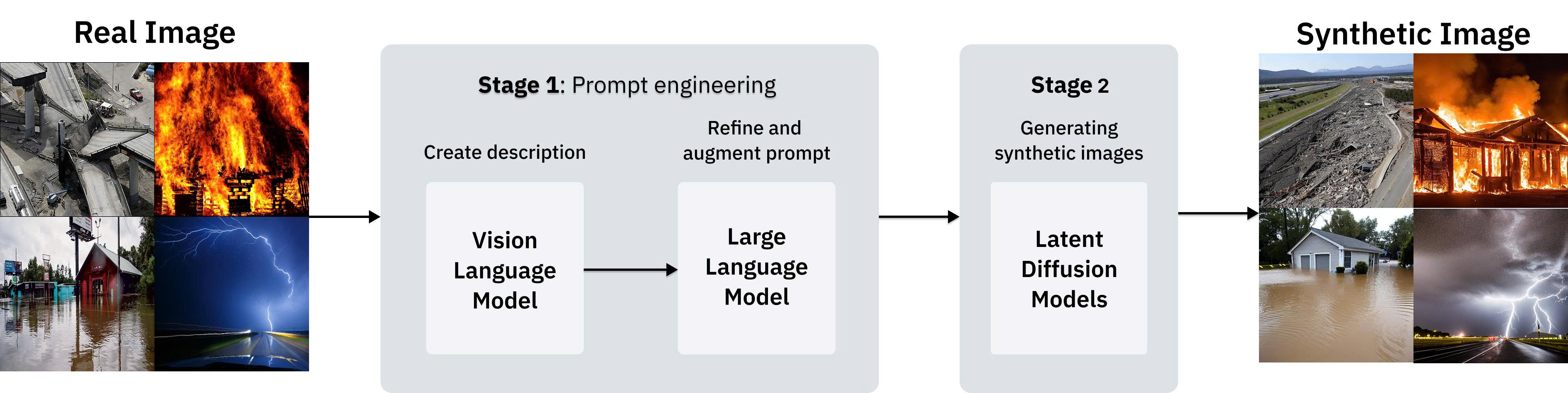
Fig 2: Overview of the synthetic image generation pipeline. The process consists

Fig 3: Examples of AI-generated images within our Forged Calamity dataset.

Fig 4: Failure cases, tested on SigLipv2.
Limitations
- Dataset limited to four disaster categories and four diffusion models; lacks other disaster types or newer diffusion architectures.
- Real images sourced only from Incident-1M and the web, which may lack real-world social media diversity and noisy metadata.
- No adversarial attack or robustness testing against adaptive generative methods designed to evade detection.
- Fine-tuning experiments performed with a single disaster type (earthquake) and single generator (SD 1.5), limiting coverage of multi-domain training effects.
- Zero-shot detectors evaluated using pretrained weights from other datasets, which may not reflect optimized performance for disaster imagery.
- No detailed statistical testing or confidence intervals reported for performance metrics, and no cross-validation results presented.
Open questions / follow-ons
- How can detectors be designed to extract domain-agnostic and generator-agnostic artifacts enabling better cross-model generalization?
- What role can multimodal signals (e.g., combining textual prompt data, metadata, and context) play in improving synthetic disaster image detection robustness?
- Can incorporating explainable AI or visual reasoning methods help forensic experts reliably identify subtle diffusion model-specific artifacts?
- How does training on multi-disaster-type and multi-generator synthetic data jointly affect detection generalization compared to single-domain training?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the acute challenge posed by the rising realism of diffusion-generated synthetic images, especially in high-stakes domains like disaster misinformation. It underscores that current visual forensic models, even those fine-tuned or using foundation models, are vulnerable to overfitting on specific model artifacts and fail to generalize reliably across new generators or semantic scenarios. This reveals a critical gap that a robust bot-defense system incorporating image authenticity analysis must overcome: detectors must not rely on brittle generator-specific signatures but instead develop model-agnostic features to flag synthetic content.
Practitioners should be cautious extrapolating existing synthetic image detectors trained on older GAN-based datasets or narrow domains, as diffusion-generated images present novel challenges. Integrating multi-generator and multi-domain benchmarks like Forged Calamity into evaluation pipelines is essential for deploying trustworthy bot-detection or image verification systems that can keep pace with rapidly evolving generative model capabilities.
Cite
@article{arxiv2606_18554,
title={ Forged Calamity: Benchmark for Cross-Domain Synthetic Disaster Detection in the Age of Diffusion },
author={ Duc-Manh Phan and Quoc-Duy Tran and Duy-Khang Do and Anh-Tuan Vo and Hai-Dang Nguyen and Trong Le Do and Mai-Khiem Tran and Vinh-Tiep Nguyen and Tam V. Nguyen and Isao Echizen and Minh-Triet Tran and Trung-Nghia Le },
journal={arXiv preprint arXiv:2606.18554},
year={ 2026 },
url={https://arxiv.org/abs/2606.18554}
}