
Diffusion-Proof: Recipe for Formal Theorem Proving Beyond Auto-Regressive Generation
Source: arXiv:2606.19315 · Published 2026-06-17 · By Ruida Wang, Rui Pan, Pengcheng Wang, Shizhe Diao, Tong Zhang
TL;DR
Diffusion-Proof addresses inherent limitations of auto-regressive (AR) large language models (LLMs) in formal theorem proving, specifically their difficulty maintaining long-range coherence and inability to perform effective local proof corrections. It introduces a first-of-its-kind framework applying diffusion-based LLMs (dLLMs) to formal mathematics, leveraging their iterative denoising of multi-token blocks and bi-directional context awareness. Diffusion-Proof consists of two 7B-parameter models: dLLM-Prover-7B for whole-proof generation with improved tactic planning and coherence, and dLLM-Corrector-7B which performs in-filling corrections of proofs based on large diffusion blocks enabling local fixes informed by prefix and suffix context.
The framework is trained on a carefully curated dataset of 5.5 million Lean4 theorem proofs, subsampled to 300k strong supervision fine-tuning (SFT) records for the prover and 128k records with subgoal decompositions for the corrector. Experimentally, Diffusion-Proof outperforms an AR baseline fine-tuned on the same data by 6.14% absolute on MiniF2F-Test (50.0% vs 43.85% pass@32) and 1.61% on ProofNet-Test benchmarks. The corrector module contributes 1.64% improvement alone by fixing hard subgoal errors. Notably, Diffusion-Proof solves an IMO problem that state-of-the-art AR-based DeepSeek-Prover-V2-7B could not. This demonstrates the unique advantage of dLLMs’ iterative refinement and long-range, bi-directional reasoning capabilities for formal theorem proving.
Key findings
- Diffusion-Proof improves pass@32 accuracy by 6.14% absolute on MiniF2F-Test (50.00% vs 43.85%) and 1.61% on ProofNet-Test (7.53% vs 5.91%) compared to the AR baseline Qwen-2.5-Lean-SFT-7B.
- On MiniF2F-Test, Diffusion-Proof achieves 15.00% on IMO problems vs 5.00% for the AR baseline, a 10% absolute increase.
- The dLLM-Corrector-7B further contributes a 1.64% absolute gain on MiniF2F-Test by correcting local proof errors in 4 of 122 problems.
- Without the corrector, dLLM-Prover-7B alone still outperforms the AR baseline by 4.51% on MiniF2F.
- Loss analysis shows strong correlation between base AR and dLLM models but fine-tuned dLLM-Prover-7B achieves lower cross-entropy loss, indicating better modeling of formal proof sequences.
- Diffusion-Proof solves an IMO problem (imo_1962_p2) that the stronger DeepSeek-Prover-V2-7B fails, due to better consistent tactic planning via diffusion-based block generation.
- The dLLM-Corrector employs bi-directional context and large diffusion blocks (512 tokens) to effectively in-fill and correct proof subgoals.
- Block diffusion training with curriculum sorting by proof complexity stabilizes model training and improves long-range coherence.
Threat model
n/a; this is not a security-focused paper but a research study on improving formal theorem proving via machine learning.
Methodology — deep read
Threat Model & Assumptions: The adversary scenario is not directly security-related but the work assumes a setting of theorem proving where the model must generate logically sound, long-range coherent proofs verified by Lean4's formal system; errors such as tactic misuse or logic inconsistency are failure modes. The goal is to reduce such failures using diffusion LLMs beyond existing AR LLM limitations.
Data: The dataset consists of 5.5 million Lean4 code-completion theorem proofs collected from prior works, cleaned and filtered to extract 300k training records containing natural language (NL) and formal language (FL) mixtures, balanced roughly 1:2 between proofs with NL annotations and pure Lean code proofs. For the corrector model, 128k records with explicit subgoal decomposition (marked by 'have' keywords) were sampled and split into token blocks of size 256 with placeholders for masked proof segments. The benchmark evaluation uses publicly available MiniF2F-Test (244 theorems including IMO, AIME, AMC problems) and ProofNet-Test (186 advanced topics). The data preprocess includes rule-based extraction of NL, FL statements and proofs.
Architecture / Algorithm: Starting from Fast-dLLM-V2-7B (7B parameters), a block diffusion LLM framework is used that splits sequences into non-overlapping blocks of size B=32 during training, with bi-directional attention within blocks but causal masking across blocks to allow block-wise iterative generation. The diffusion training objective optimizes the denoising log-likelihood of masked tokens conditioned on noised input sequences at varying noise levels. For the corrector, the diffusion block size is extended to 512 tokens, targeting local proof subgoal corrections by in-filling masked proof segments. Key novelty is in leveraging large-block bi-directional diffusion generation for local in-filling correction, a capability missing from AR models.
Training Regime: Fine-tuning uses curriculum data sorting increasing from simpler to complex proofs based on proof length, stabilizing loss curves. Both prover and corrector models are trained on 4 H100 GPUs with global batch size 64, learning rates of 1e-5 (prover) and 5e-6 (corrector), with 3% warmup steps. The training dataset for the prover is 300k SFT records; the corrector trains on 128k subgoal-decomposed chunks. Each model trains for approximately one day. The base dLLM and the baseline AR model share comparable foundation and undergo no additional post-training.
Evaluation Protocol: The main evaluation metric is pass@32, measuring theorem proving success rate allowing up to 32 generated attempts per problem. The baseline is Qwen-2.5-Lean-SFT-7B, an AR model fine-tuned on the same dataset to ensure a fair generation paradigm comparison. Experiments include ablation on the corrector’s impact, analysis by problem type, and case studies versus both AR baseline and more advanced DeepSeek-Prover-V2-7B system. Validation loss comparisons use a causal mask to assess perplexity differences. Benchmarks cover MiniF2F-Test and ProofNet-Test. No explicit cross-validation is reported.
Reproducibility: The authors commit to releasing all training code, models, and datasets publicly. The base model Fast-dLLM-V2-7B is open-source. The datasets used, such as MiniF2F and ProofNet, are publicly known benchmarks. Exact training seeds/stochasticity details are not specified but training configurations are detailed in appendices.
Concrete Example: For a Lean4 theorem, the prover generates the entire proof in a block-diffusion manner, producing tactic sequences with global coherence. If the proof verification fails due to an incorrect subgoal proof, the faulty proof segment is masked out and the corrector is invoked. The corrector uses a 512-token diffusion block covering the subgoal to generate an infilled correction, leveraging bi-directional context from prior and subsequent tokens to produce coherent fixes. This two-stage pipeline enables better handling of long proofs and localized errors compared to left-to-right AR generation.
Technical innovations
- First application of diffusion large language models (dLLMs) for formal theorem proving, overcoming limitations of auto-regressive generation in long-range coherence and error accumulation.
- Novel large-block diffusion-based correction model (dLLM-Corrector-7B) that performs in-filling local proof corrections leveraging bi-directional context within large diffusion blocks.
- Integration of block-diffusion generation to enable iterative refinement and long-range coherent tactic usage in formal proof writing.
- Curriculum data sorting by proof complexity to stabilize training of diffusion LLMs on formal theorem proving datasets.
Datasets
- 5.5M Lean formal theorem proving records — from prior public research datasets (Wu et al., 2024; Wang et al., 2024)
- 300k SFT mixture data (NL + FL) for prover fine-tuning — derived and filtered from the above
- 128k subgoal decomposed proof blocks for corrector training — from the 300k SFT dataset
- MiniF2F-Test — 244 formalized theorems from math competitions and benchmarks, public (Zheng et al., 2021)
- ProofNet-Test — 186 theorems from college text topics, public (Azerbayev et al., 2023)
Baselines vs proposed
- Qwen-2.5-Lean-SFT-7B (AR baseline): pass@32 = 43.85% on MiniF2F-Test vs Diffusion-Proof: 50.00% (+6.14%)
- Qwen-2.5-Lean-SFT-7B (AR baseline): pass@32 = 5.91% on ProofNet-Test vs Diffusion-Proof: 7.53% (+1.61%)
- Diffusion-Proof without corrector: 4.51% improvement over AR baseline on MiniF2F-Test
- Corrector model alone: adds 1.64% absolute gain on MiniF2F-Test by local proof fixes
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19315.
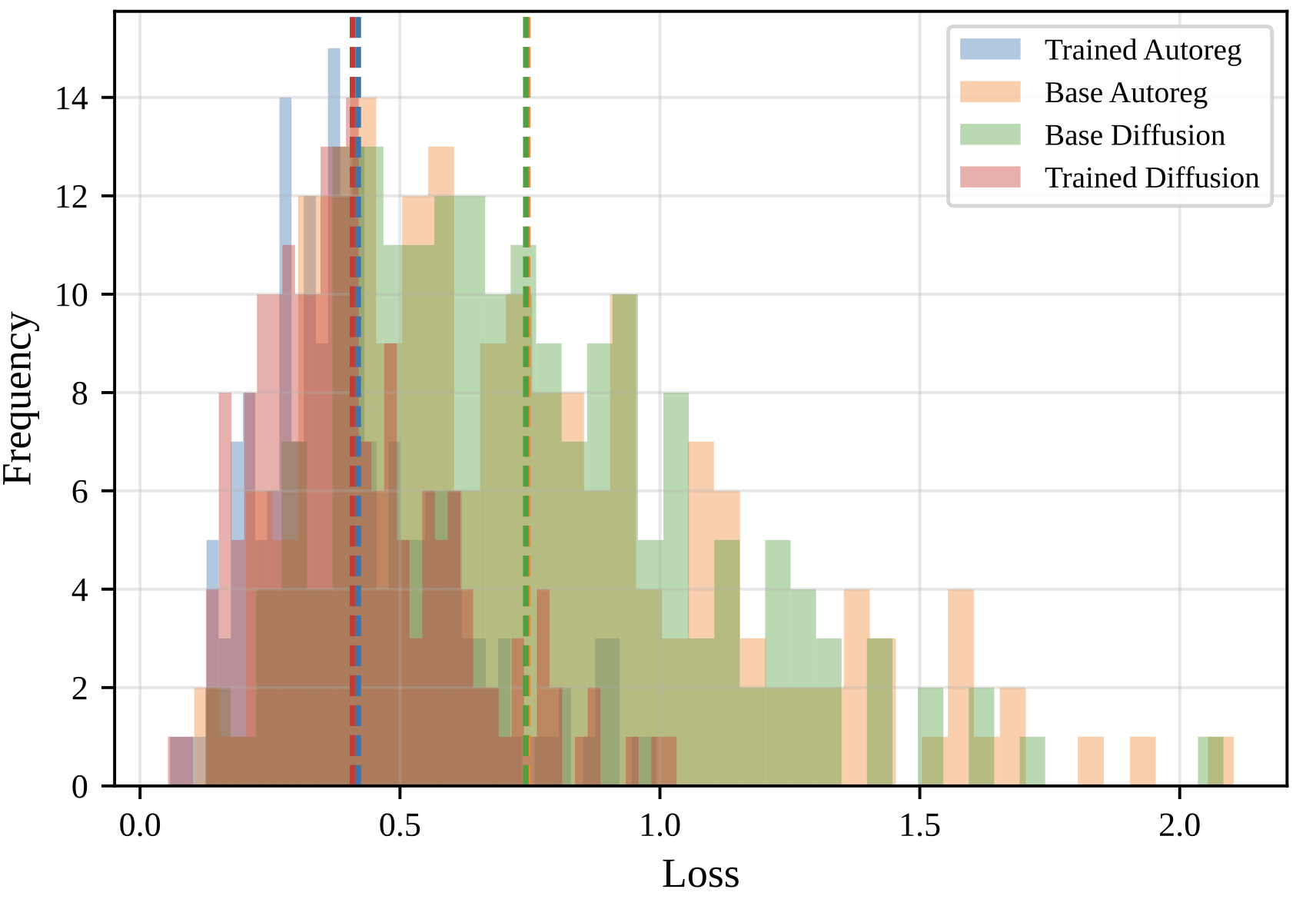
Fig 3: Validation loss for trained dLLM, trained AR
Limitations
- Training scale limited by compute resources below state-of-the-art large AR provers like Goedel-Prover-V2 and DeepSeek-Prover-V2, so performance gains may not generalize to larger models.
- Current base model's limited Long Chain-of-Thought (Long CoT) reasoning ability prevents full exploration of dLLMs for extended multi-step formal reasoning.
- Work focused exclusively on Lean4 formal language; applicability to other formal systems like Coq or Isabelle is untested.
- No adversarial or out-of-distribution robustness evaluation; performance under adversarial theorem modifications unknown.
- Lack of detailed statistical significance testing or cross-validation, though pass@32 metric is standard.
- Corrector does not improve results on ProofNet-Test, indicating local corrections may be less effective for some advanced knowledge domains.
Open questions / follow-ons
- How do diffusion LLMs scale with model size and training data beyond 7B parameters for formal reasoning tasks?
- Can diffusion-based theorem proving be extended to support longer CoT reasoning and multi-agent or interactive proof search?
- How well do diffusion LLMs generalize across different formal proof systems (e.g., Coq, Isabelle) beyond Lean4?
- What are the impacts of adversarial or noisy theorem inputs on diffusion LLM proof generation robustness?
Why it matters for bot defense
From a bot-defense or CAPTCHA practitioner perspective focused on robustness and automated challenge generation, this work shows that diffusion-based long-range generation models have intrinsic advantages in maintaining consistency and enabling local corrections in complex sequential reasoning tasks. Similar iterative denoising and block-wise generation strategies could inform advanced CAPTCHA or bot-detection systems needing to generate or verify highly structured responses with internal logical consistency. The demonstrated improvement over traditional left-to-right autoregressive models suggests diffusion approaches might produce more reliable proof-like or stepwise structured outputs resistant to simple generative shortcuts often exploited by bots. Additionally, the capability of local in-filling correction offers a pathway to interactive or adaptive CAPTCHA challenges that iteratively refine user responses to validate authenticity. However, direct application would require further exploration of adversarial robustness and efficiency, since theorem proving tasks differ substantially in nature from bot challenge-response scenarios.
Cite
@article{arxiv2606_19315,
title={ Diffusion-Proof: Recipe for Formal Theorem Proving Beyond Auto-Regressive Generation },
author={ Ruida Wang and Rui Pan and Pengcheng Wang and Shizhe Diao and Tong Zhang },
journal={arXiv preprint arXiv:2606.19315},
year={ 2026 },
url={https://arxiv.org/abs/2606.19315}
}