
Detecting Hidden ML Training With Zero-Overhead Telemetry
Source: arXiv:2606.19262 · Published 2026-06-17 · By Robi Rahman, Sabiha Tajdari
TL;DR
The paper addresses the critical problem of reliably detecting when GPUs are executing ML training workloads versus inference or non-ML computations using only zero-overhead, privacy-preserving telemetry signals available from NVIDIA Management Library (NVML). This is an important foundational capability for proposals in AI compute governance that require monitoring, auditing, or restricting training runs above certain compute thresholds. The authors develop a random forest classifier leveraging 9 physical telemetry signals (power draw, temperature, utilization, clocks, PCIe traffic) sampled at 1 Hz with no runtime overhead or access to sensitive application data. They conduct extensive data collection across 9 GPU models spanning 4 architecture generations and over 1600 workload runs totaling roughly 117 GPU-hours. To evaluate robustness, they implement 20 families of adversarial evasion strategies evolving over 5 rounds of monitor–evader iteration. The hardened classifier achieves 98.2% accuracy on non-adversarial data, generalizes well to unseen hardware, and maintains detection rates between 43% and 87% against the most challenging unseen white-box evasion attacks. Their results demonstrate that content-agnostic, low-cost hardware telemetry is sufficient to detect hidden ML training workloads at scale with high accuracy and defend against sophisticated evasion attempts, thus providing a practical foundation for enforceable AI governance mechanisms.
Key findings
- Random forest classifier achieves 98.2% binary accuracy at detecting ML training vs. inference/non-ML across 9 NVIDIA GPU types (Ampere through Blackwell) using only 9 NVML signals sampled at 1 Hz without runtime overhead.
- Leave-one-strategy-out (LOSO) evaluation on 20 families of adversarial evasion strategies yields mean detection accuracy of 95.2% on unseen evasion techniques and 43-87% accuracy against white-box evaders with full classifier knowledge.
- Cross-GPU transfer learning generalizes well, achieving 100% accuracy on hold-out GPUs in 8 of 9 models, and ≥99.4% on the remaining model in the LOGO (leave-one-GPU-out) setting.
- Multi-GPU distributed training evasion attacks are detected with 99.6%-100% accuracy, outperforming easier-to-hide single-GPU evasion cases.
- Adding physics-based features (cumulative energy, power-memory correlation, pre-allocation memory plateau) enables detection of the hardest single-GPU disguises.
- Latency analysis shows classifier obtains 98.15% accuracy with 5-second telemetry windows and 98.21% at 30 seconds, enabling near real-time detection.
- Iterative adversarial training over 5 rounds hardens classifier against utilization manipulation, memory reduction, training-as-inference dilution, composite evasion strategies, and white-box attacks.
- White-box evader tactics (e.g., running training in short windows to avoid fixed-size telemetry sampling) can evade baseline classifiers up to 94%, but retraining against these recovers 43-87% detection of unseen white-box evasion.
Threat model
The adversary is either (1) a cloud tenant who controls user-space software but cannot tamper with host OS, hypervisor, or hardware telemetry, or (2) a hardware operator who controls the entire software stack but cannot circumvent hardware-enabled mechanisms (HEMs) that guarantee untampered NVML telemetry readings and prevent injection of synthetic telemetry signals. Adversaries seek to disguise hidden ML training workloads as inference or non-ML to evade detection by the classifier. The fundamental constraints are that physical power and utilization profiles impose limits on obfuscation, as training’s backward pass requires significantly more FLOPs and energy than inference. Attacker read/write capabilities and evasion are bounded by these constraints.
Methodology — deep read
The authors build a supervised classifier to determine if a monitored GPU workload is training or not, using only nine NVML telemetry signals (GPU utilization, memory utilization, memory used, power draw, temperature, SM clock, memory clock, PCIe TX and RX bandwidth) sampled at 1 Hz with zero runtime overhead. The threat model includes two adversaries: (1) cloud tenants who can modify user-space software but not host OS or hardware; and (2) hardware operators able to control the full software stack but assumed to be prevented from tampering with NVML telemetry via hardware-enabled mechanisms (HEMs). The classifier leverages physical constraints, especially that backward passes in training cause roughly 2x FLOPs and thus more power and distinct telemetry traces.
Data was collected on 9 NVIDIA GPU models across 4 generations including consumer GPUs (RTX 4050, 5080, 5090) and datacenter GPUs (A100, H100, H200, B200). The dataset consists of 1404 runs of 162 workloads totaling ∼117 GPU-hours and 445,310 telemetry readings. Labels include 867 runs of ML training (including supervised training, distributed data parallel, fully sharded and LoRA fine-tuning), 352 runs of inference over various model families, and 185 runs of non-ML workloads including HPC, crypto-mining, rendering, and idle states. Adversarial workloads (421 runs) cover 20 evasion family strategies such as utilization modulation, memory minimization, clock throttling, workload mimicry, training-as-inference dilution, multi-GPU evasion, and white-box attacks.
The final classifier is a 400-tree random forest trained on features extracted from rolling telemetry windows of 5 to 30 seconds, combining a "roofline" layer capturing arithmetic intensity via mean power and utilization, and a set of time-domain features reducing overfitting. Several other models were evaluated (XGBoost, SVM, logistic regression) but RF performed best. Training uses 5-fold grouped cross-validation, ensuring runs remain within folds, with hyperparameters tuned through iteration during 5 rounds of monitor-evader co-evolution.
The evaluation protocol is based on out-of-distribution adversarial generalization: for each evasion family, classifiers are trained on all other families plus clean workloads, then tested on the held-out evasion strategy (leave-one-strategy-out). This simulates discovering novel evasion in deployment. They analyze precision, recall, accuracy, false-positive rates, and latency tradeoffs. Cross-GPU transfer learning is tested by leave-one-GPU-out (LOGO) evaluations.
The iterative adversarial process involves the defender retraining a hardened classifier against increasingly sophisticated evaders adapting to previous detection techniques, culminating in a white-box attacker with full classifier knowledge attempting to evade detection via short-window training bursts and run-time classifier evasion.
All workload source code and telemetry data for adversarial runs are available in the authors’ public repository. Details on feature engineering and classifier hyperparameters are described in appendices. Exact hyperparameters for random forest: 400 trees, no maximum depth specified. No statistical hypothesis tests or distribution shift benchmarks beyond LOSO methodology were reported. The approach emphasizes reproducibility using only NVML signals easily accessible on Nvidia GPUs Pascal and newer, with zero overhead.
Technical innovations
- Leveraging zero-overhead, privacy-preserving NVML hardware telemetry signals at 1 Hz sampling for high-accuracy GPU workload classification distinguishing training from inference/non-ML without accessing model internals.
- Developing an iterative 5-round monitor–evader co-evolution protocol evaluating 20 adversarial evasion strategy families across multi-generation GPUs including white-box attacks, enabling hardened classifier robustness.
- Introducing physics-based features such as cumulative energy consumption, power-memory correlations, and pre-allocation memory plateau metrics capturing fundamental computation invariants resistant to evasion.
- Demonstrating cross-architecture generalization with leave-one-GPU-out evaluation showing a single classifier trained on diverse GPUs can detect training on unseen hardware without retraining.
Datasets
- Internal dataset — 162 workloads (1404 runs) spanning ML training, inference, and non-ML across 9 GPU models — sourced by authors from self-conducted experiments.
Baselines vs proposed
- Baseline random forest classifier (trained on non-adversarial data): accuracy = 97.6% on held-out real workloads vs. Proposed classifier (hardened after adversarial rounds): 98.2% accuracy across all workloads
- Round 1 evasion (utilization manipulation): baseline detection 6-96% vs hardened classifier 100% in-distribution, 59-100% on unseen evasion
- Round 3 evasion (training-as-inference dilution): baseline detection 52-60% vs hardened classifier 100% in-distribution, 87-100% on unseen
- Round 4 multi-GPU evasion strategies: baseline detection 71-100% vs hardened classifier 100% detection
- Round 5 white-box evasion: previous classifier 6-100% detection vs hardened classifier 100% on seen evasion, 43-87% on unseen white-box attacks
- Cross-GPU transfer accuracy (LOGO): ranges from 95.14% to 100% depending on GPU; datacenter GPUs perform near-perfectly, consumer GPUs generalize well only when pooled data is used
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19262.
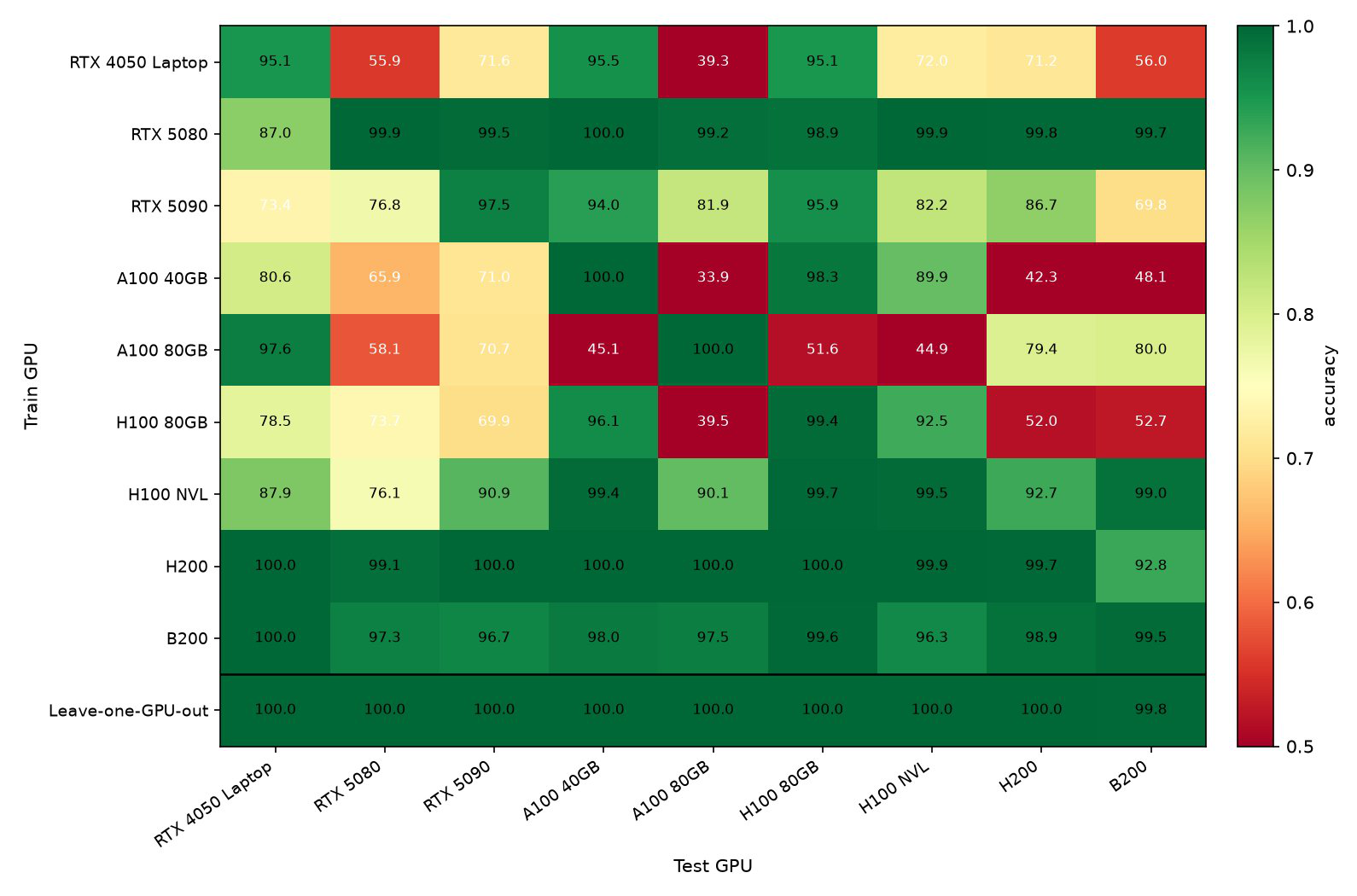
Fig 1: Cross-GPU transfer heatmap (binary RF, 30 s windows).
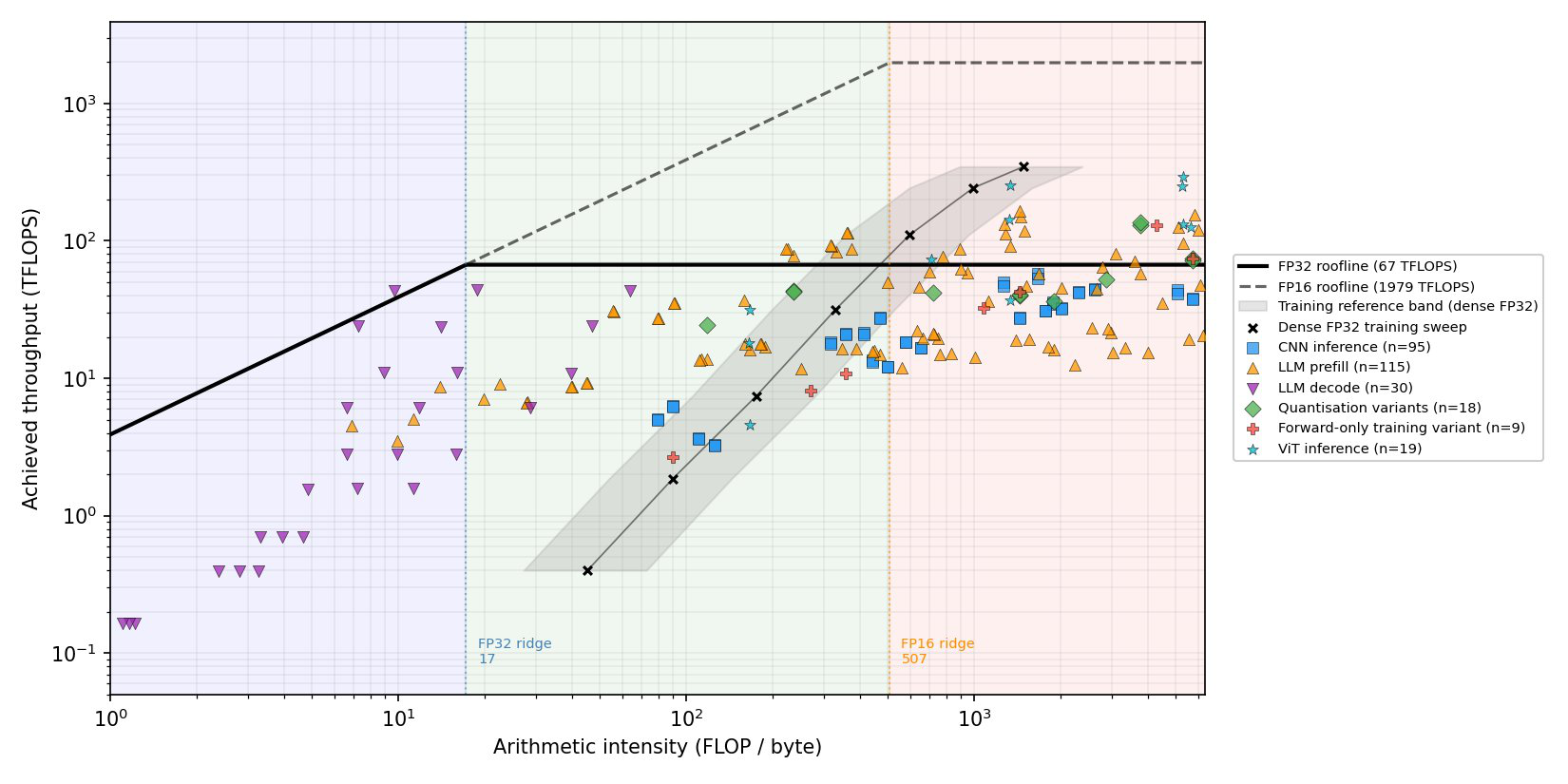
Fig 2: H100-NVL roofline with the 286 corner-case inference configurations overlaid on a dense-FP32 training reference sweep.
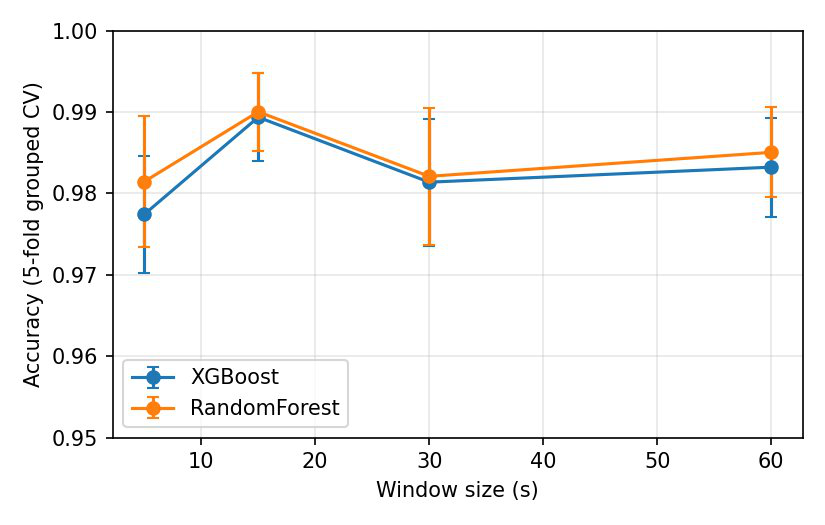
Fig 3: Accuracy vs. window size.
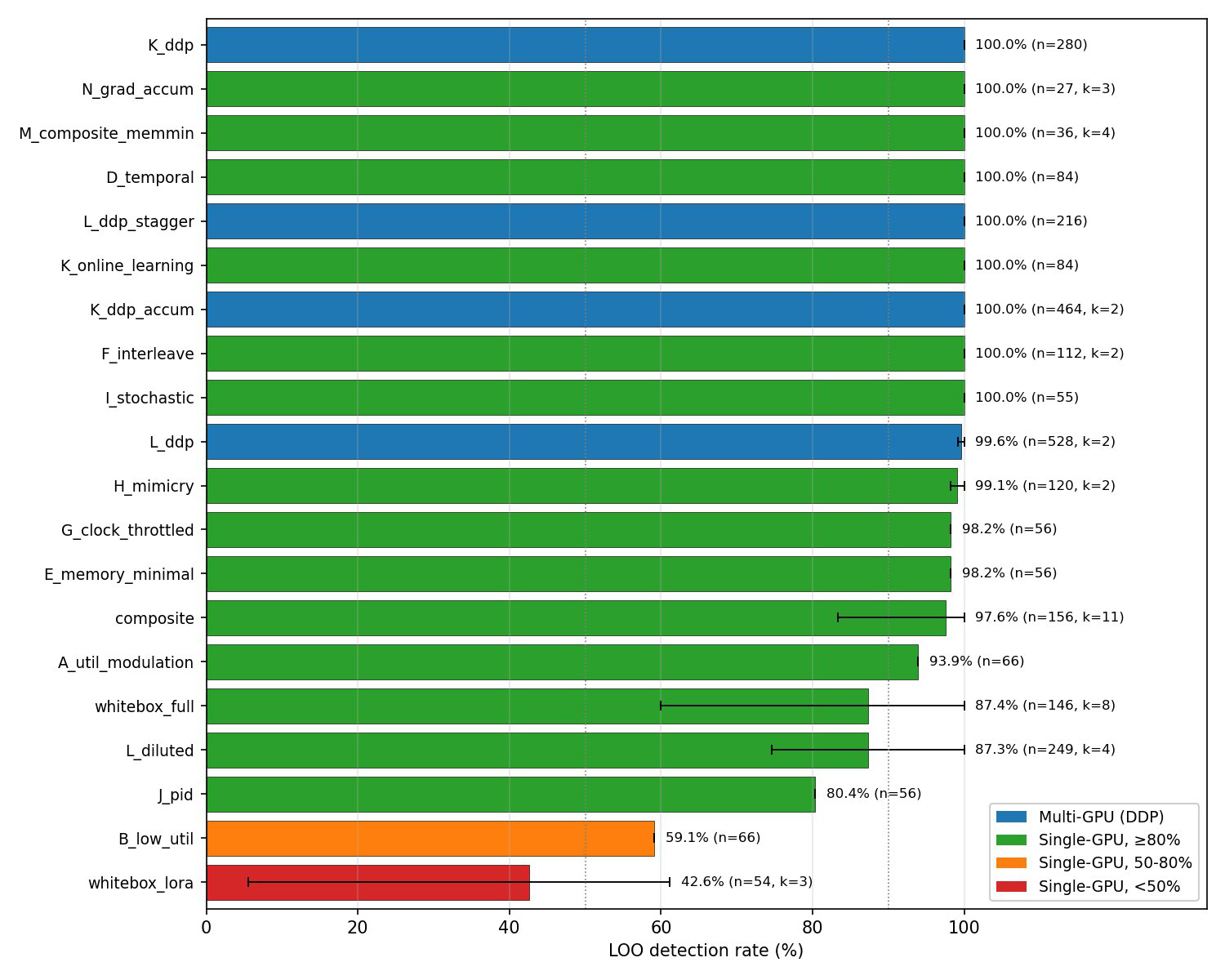
Fig 4: Detection rate in LOO evaluation by strategy family. Bar chart showing 20 families sorted by detection rate, with error bars
Limitations
- Assumes presence of hardware-enabled mechanisms (HEMs) to prevent undermining or tampering of NVML counters; without HEMs, adversaries controlling full software stack could manipulate telemetry.
- White-box evaders with full classifier internals can still evade detection to some degree (43-87% detection), indicating a residual vulnerability against informed attackers.
- Evaluation focuses on binary classification of training vs. non-training; does not distinguish fine-grained workload types or training phases.
- Dataset uses NVIDIA GPUs exclusively, limiting generalization to other hardware vendors or architectures.
- The evaluation does not test long-term concept drift or rapidly emerging new evasion techniques beyond the 5 iteration rounds reported.
- No extensive statistical testing or confidence intervals reported beyond cross-validation; real-world deployment variability not measured.
- Some evasion strategies rely on weakening telemetry features that may be difficult to fully counteract without additional hardware telemetry inputs.
Open questions / follow-ons
- How resilient is the classifier against emerging evasion techniques beyond the 20 families currently evaluated, especially those leveraging yet unknown side channels or hardware-level attacks?
- Can hardware telemetry from non-NVIDIA GPUs or different architectures achieve similar detection accuracy without retraining?
- What are practical hardware-enabled mechanisms (HEMs) to ensure telemetry authenticity and integrity in hostile environments?
- How does classifier performance degrade over time due to concept drift in workloads or new ML model architectures?
Why it matters for bot defense
For practitioners focused on bot defense and CAPTCHA systems, this research highlights a promising approach to detect unauthorized or hidden ML training activity purely from hardware telemetry signals with zero runtime overhead and without accessing sensitive model internals or training data. Such detection could support compute governance policies that restrict or audit black-box training runs, potentially helping prevent adversarial actors from covertly training models that might later be used for bot evasion or bypass. The adversarial iterative evaluation shows the importance of continuously updating detection classifiers to counter sophisticated obfuscation tactics. The high accuracy on multi-GPU workloads and cross-device generalization suggest that scalable monitoring architectures based on telemetry signals are feasible in real-world data centers. However, the reliance on hardware-enabled integrity protection mechanisms reminds practitioners to carefully consider trusted telemetry collection and adversarial model hardening to prevent evasion. Overall, this work provides a solid empirical foundation for telemetry-based ML training detection as a practical trusted compute governance tool relevant to anti-bot and adversarial risk management contexts.
Cite
@article{arxiv2606_19262,
title={ Detecting Hidden ML Training With Zero-Overhead Telemetry },
author={ Robi Rahman and Sabiha Tajdari },
journal={arXiv preprint arXiv:2606.19262},
year={ 2026 },
url={https://arxiv.org/abs/2606.19262}
}