
Characterizing Narrative Content in Web-scale LLM Pretraining Data
Source: arXiv:2606.19468 · Published 2026-06-17 · By Teagan Johnson, Elliott Ash, Andrew Piper, Maria Antoniak
TL;DR
This paper addresses the largely unexplored question of narrative content composition in large-scale web-based corpora used for training large language models (LLMs). The authors develop a novel, fine-grained narrative annotation framework drawing on narrative theory that operationalizes three core narrative elements—agency, setting, and events—across 11 interpretable dimensions (e.g., focalization, emotion, concreteness, temporal ordering). They annotate a carefully sampled diverse set of 400 passages from DOLMA, an open 3-trillion-token pretraining corpus. Using these annotations, they finetune NarraBERT, a RoBERTa-based narrative classifier which they then apply to ∼3 million passages, producing NarraDolma, a large narrative-featured dataset.
Their large-scale analysis reveals that narrative structure in pretraining data can be represented as continuous multidimensional profiles rather than a binary concept. They identify three principal components capturing interiority (agent perspective and cognition), grounded eventfulness (causal/temporal events in a specific setting), and storyworld texture (sensory and concrete detail). Narrative qualities are unequally distributed across sources and topics within the corpus, with narrative-rich subcorpora like Reddit and Gutenberg showing high interiority but wide internal variance, and more factual sources like Wikipedia showing grounded eventfulness but little interiority. The study highlights that current data curation practices based on source or topic labels are too coarse to account for narrative heterogeneity, which may affect downstream LLM narrative reasoning capabilities.
Overall, this work provides the first systematic, scalable investigation and measurement framework of narrative content in web-scale LLM pretraining data, releasing both the labeled dataset and classifier to catalyze further research on narrative-aware data curation and model evaluation.
Key findings
- NarraBERT achieves inter-annotator agreement on agency and setting dimensions with mean Krippendorff's alpha around 0.66 and mean absolute error approx. 0.57, comparable to human-level agreement.
- Event relation classification by NarraBERT underperforms its LLM teacher GEMMA: mean F1=0.63 vs 0.78 on temporal and causal labels, likely due to class imbalance.
- PCA on 10 narrative dimensions shows first three components account for ~72% variance, interpretable as narrative interiority, grounded eventfulness, and storyworld texture.
- Narrative-rich categories like Reddit and Gutenberg have >50% of documents in top quartile of interiority PC vs under 5% for factual sources like Wikipedia and Politics.
- Factual and technical domains (e.g., Wikipedia, Software Dev.) exhibit low narrative interiority and storyworld texture but high grounded eventfulness.
- Large internal variance of narrative features within categories (average standardized within-category SD=0.87) indicates high heterogeneity not captured by corpus/source labels.
- NarraDolma dataset contains ~3M passages from ~785K documents sampled stratified by source and topic with 11 narrative feature annotations per passage.
- LLM annotator model GEMMA4-31B was used for large-scale labeling, with validation against human annotations yielding mean F1 0.78 for event relations and Krippendorff's alpha 0.71 for agency/setting.
Threat model
n/a — This work is an empirical analysis of narrative content in pretraining data and does not directly involve adversarial threat models or security scenarios.
Methodology — deep read
The authors begin by defining a threat model focused on understanding the distribution and structure of narrative features embedded within large-scale open pretraining corpora, specifically DOLMA, a 3-trillion-token dataset comprising 12 different subcorpora. The adversary model is not adversarial in a security sense but conceptualizes the challenge of measuring a subtle, multidimensional property (narrativity) within highly heterogeneous, noisy, and partially unstructured web-derived text.
They develop an annotation framework grounded in established narrative theory, breaking narrative into three core elements: agency, setting, and events, operationalized as 11 fine-grained dimensions including focalization, emotion, cognition, change of state, conflict (agency), concreteness, temporal grounding, spatial grounding, sensory detail (setting), and event density, temporal sequencing, and causal relation (events). This design enables a scalar measurement rather than binary narrative detection.
Data sampling involves extracting ~17 million three-sentence passages from about 5 million documents in DOLMA, applying a DEBERTA-based narrative binary classifier to score narrative coherence, and using a topic classifier (WEBORGANIZER) to assign topic labels for stratification. They then sample a gold annotation set of 400 passages biased toward narrative content and balanced by source and topic for human annotation.
Human annotation involved multiple annotators with inter-annotator agreements assessed using Krippendorff's alpha and F1 scores for event relations, yielding reasonable but variable agreement (e.g., mean alpha ~0.76 for agency, ~0.70 setting, kappa=0.68 event relations). The annotated passages provide the labeled data for supervised learning.
The authors evaluate three large LLMs (CLAUDE SONNET 4.6, QWEN3-235B, GEMMA4-31B) as zero-shot annotators on the gold set and select GEMMA for cost-effective large-scale labeling, generating labels for 5K passages.
They distill GEMMA labels by training NarraBERT, consisting of two RoBERTa-base encoders: one shared encoder predicting nine regression heads for agency and setting features, one dedicated encoder for binary event relations classification. Training frames Likert scores as regression and event relations as classification with hyperparameters detailed in appendix.
Validation against held-out human annotations shows NarraBERT matches LLM-level agreements on agency and setting but underperforms on event relations (F1 drop from 0.78 to 0.63). This is attributed to class imbalance, particularly temporal ordering and causal relations averages.
NarraBERT is applied at scale to 3 million passages spanning 785K documents, producing continuous multidimensional narrative feature vectors, which are aggregated at document level by averaging. PCA and clustering analysis reveal coherent narrative structure dimensions.
For example, a passage about an interview room scored 4/5 for focalization, 4/5 emotion, but low on spatial grounding and temporal grounding, illustrating how the model quantifies narrative aspects at fine granularity. Clustering analysis (Fig. 5) shows narrative dimension profiles by category, highlighting heterogeneous distributions and subcorpus differences.
All code, models (NarraBERT), and labeled corpus (NarraDolma) are publicly released to encourage reproducibility and further study.
Overall, the methodology carefully links theoretical narrative constructs to scalable annotation and modeling, validating stepwise from human labels through LLM distillation to lightweight models for large corpus annotation and statistical analysis.
Technical innovations
- Development of an 11-dimensional narrative annotation framework grounded in narrative theory covering agency, setting, and event relations as continuous Likert-scale features.
- Creation of NarraBERT, a RoBERTa-based model trained via knowledge distillation from LLM labels to efficiently predict fine-grained narrative features at scale.
- Stratified sampling pipeline combining a DEBERTA-based binary narrative classifier and topic classifier to curate a representative dataset balancing narrative content and topical diversity within a 3-trillion-token web corpus.
- Discovery that narrative content in LLM pretraining data exists as a continuous, multidimensional structure rather than a binary attribute with three principal axes (interiority, grounded eventfulness, storyworld texture).
Datasets
- DOLMA — 3 trillion tokens — open web-scale multilingual pretraining corpus
- Gold annotated narrative dataset — 400 passages — human annotated from DOLMA samples
- LLM-labeled narrative dataset — 5,000 passages — produced by GEMMA4-31B
- NarraDolma — ~3 million passages from ~785,000 documents — labeled with 11 narrative dimensions using NarraBERT
Baselines vs proposed
- Human annotation agreement: mean Krippendorff's alpha ~0.76 (agency), 0.70 (setting), Cohen's kappa 0.68 (event relations)
- LLM annotators (CLAUDE SONNET 4.6, QWEN3-235B, GEMMA4-31B): mean alpha 0.71 agency/setting, F1 0.78 event relations, chosen GEMMA for cost-effectiveness
- NarraBERT vs human: mean alpha 0.66 agency/setting (vs 0.76/0.70 human), mean F1 0.63 event relations (vs 0.78 GEMMA LLM)
- PCA components explain ~72% variance of 10 validated narrative features
- Narrative concentration: >50% Reddit/Gutenberg docs in top quartile interiority PC vs <5% for Wikipedia/Politics
- Event detector achieves F1=0.85 on event trigger detection (Sims et al., 2019 validation)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19468.
Fig 5: Mean z-scored narrative features by category,
Fig 2 (page 18).
Fig 3 (page 18).
Fig 4 (page 18).
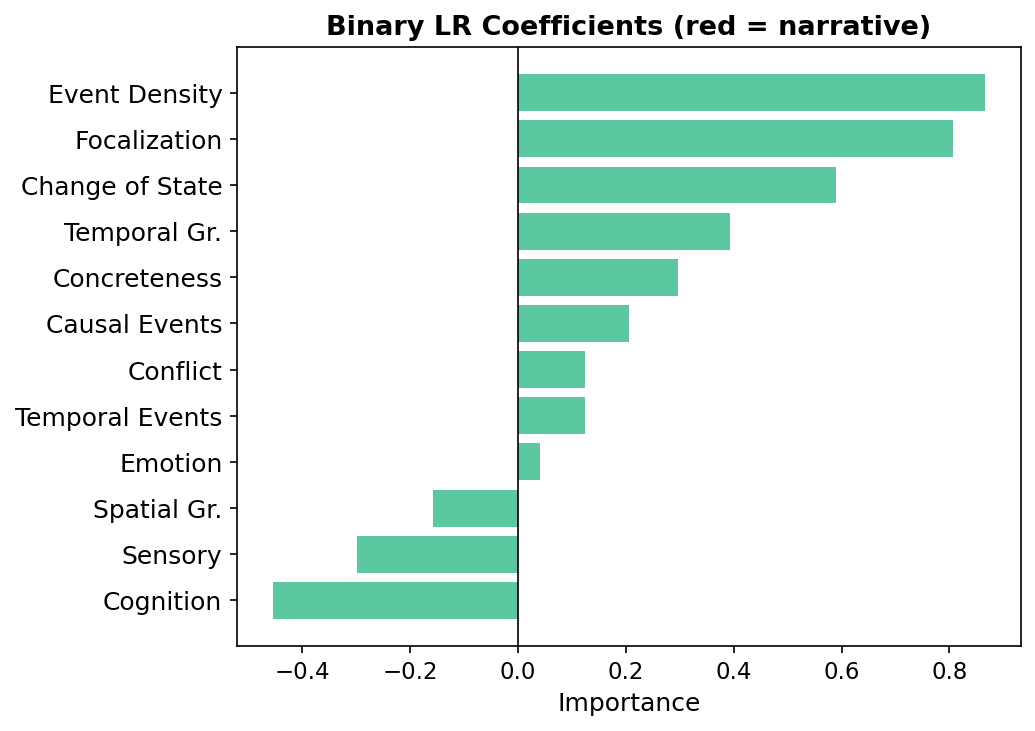
Fig 5 (page 21).
Fig 6 (page 23).
Fig 7 (page 23).
Fig 8 (page 24).
Limitations
- NarraDolma oversamples narrative content (~3M passages) from a >3-trillion-token corpus, so absolute prevalence figures do not extrapolate directly to raw DOLMA.
- Human annotation limited to 400 passages, a small sample relative to the corpus size and diversity, potentially limiting representativeness.
- Primary annotation done by a single author, potentially introducing bias; some moderate inter-annotator agreement on complex narrative dimensions, especially temporal ordering (kappa=0.60).
- Event relation classification suffers from severe class imbalance, which likely reduces NarraBERT performance compared to LLM teacher.
- No direct evaluation or causal analysis of how narrative composition affects downstream LLM narrative reasoning or generation capabilities.
- Analysis focused on English web texts and 3-sentence passages; longer discourse-level narratives or other languages remain to be explored.
Open questions / follow-ons
- How does varying the narrative composition of pretraining mixtures causally affect downstream LLM performance on narrative understanding or generation tasks?
- What is the temporal dynamics of narrative competency acquisition during LLM pretraining and can narrative features predict emergent abilities?
- Can narrative dimension embeddings be integrated into data curation pipelines (e.g. RegMix) to optimize for narrative quality alongside topic and toxicity?
- How generalizable is this annotation framework and NarraBERT to longer narrative texts, other languages, or multimodal pretraining data?
Why it matters for bot defense
From a bot-defense and narrative understanding perspective, this work provides a novel lens to characterize how narrative cognitive complexity is distributed across massive pretraining data, which may influence an LLM's ability to reason over story-like sequences common in human communication. Narrative understanding is central to advanced reasoning and context tracking, which underpins detecting sophisticated bots mimicking human conversational patterns.
By operationalizing and measuring multi-dimensional narrative features at scale, the dataset and model provide new tools to profile pretraining data composition, potentially diagnosing narrative deficits in models that could be exploited by adversaries using story-driven social engineering or misinformation bots. Data curators and researchers focused on improving LLM reliability in recognizing and generating coherent narratives can leverage these insights to adjust training mixes or build more narrative-aware detection systems. The fine-grained annotations and multidimensional narrative profiles may also help design CAPTCHAs or bot-detection challenges focusing on narrative reasoning abilities that are harder for bots to emulate convincingly.
Cite
@article{arxiv2606_19468,
title={ Characterizing Narrative Content in Web-scale LLM Pretraining Data },
author={ Teagan Johnson and Elliott Ash and Andrew Piper and Maria Antoniak },
journal={arXiv preprint arXiv:2606.19468},
year={ 2026 },
url={https://arxiv.org/abs/2606.19468}
}