
AI-Driven Assessment of Human Tutors: Linking Training Performance to Real-Life Practice
Source: arXiv:2606.18617 · Published 2026-06-17 · By Danielle R. Thomas, Marie Cynthia Abijuru Kamikazi, Clara Brandt, Conrad Borchers, Kenneth R. Koedinger
TL;DR
This paper addresses a critical gap in human tutor training by developing an AI-driven assessment system that links tutor training performance to real-life tutor practice. Unlike conventional tutor training platforms which evaluate tutors only in simulated or training environments, this work leverages generative AI (Gemini-2.5-pro) to analyze authentic tutoring session transcripts to evaluate whether trained pedagogical skills transfer to real tutoring interactions. The system evaluates tutors’ open responses and multiple-choice performance in six scenario-based lessons and predicts their quality of instructional moves in actual remote math tutoring sessions with middle school students (N=86 tutors, 405 tutor-lesson observation pairs).
Key findings include a significant average learning gain of 7.4% across lessons and a positive correlation (0.25 SD effect size) between training performance and real-life tutor move quality, with open-response training performance showing stronger predictive validity than multiple-choice. Analysis of tutoring transcripts revealed tutors became more likely to encounter pedagogical opportunities and improve execution quality post-training, although improvements were gradual over time rather than immediate post intervention. The study also contributes open datasets, detailed AI scoring rubrics, and prompt engineering pipelines to support reproducibility. This work advances the state-of-the-art in workforce training evaluation by combining scenario-based lesson learning assessment with automated real-life transcript analysis through LLMs, addressing the challenging problem of measuring skill transfer in complex, context-dependent tutoring moves.
Key findings
- Tutors demonstrated a significant learning gain of 7.4% (F=27.50, p<.001) across six scenario-based lessons.
- The REACT_ERRORS lesson showed the largest gain at 25.2% (F=30.10, p<.001), while other lessons like AFFIRM_CORRECT had ceiling effects with no significant gain.
- A linear mixed-effects model found one SD increase in training performance correlated with a 0.25 SD increase in real-life transcript tutor move scores (p<.001).
- Open-response training performance was a stronger predictor of real-life tutor performance than multiple-choice performance.
- Model comparison via AIC/BIC favored combining open-response and multiple-choice scores over either alone to predict real-life performance.
- Post-training, tutors encountered pedagogical opportunities more frequently (increasing from 61.1% to 68.9%, p<.001) and executed tutor moves with higher quality (65.5% to 68.1%, p=0.003).
- Interrupted time series analysis showed gradual steady improvement over weeks (β=0.01, p=0.022) but no immediate post-training jump in tutor move quality.
- Human-to-LLM inter-rater reliability scores varied (some κ as low as 0.38), likely due to dataset imbalance and small sample size.
Threat model
N/A — This paper focuses on AI-driven tutor performance assessment and training evaluation rather than adversarial security threats or malicious actors. The system assumes transcripts are authentic and unaltered and that tutors aim to improve pedagogical moves.
Methodology — deep read
Threat Model & Assumptions: The adversary considered is not explicitly detailed, as this work focuses on evaluation of tutor training and behavioral transfer rather than security threats. The key assumption is that the AI system (Gemini-2.5-pro) can reliably identify pedagogical opportunities and evaluate tutor moves from text transcripts, and that training performance on lessons reflects tutors’ skill acquisition. The model does not contend with malicious actors or efforts to spoof assessments.
Data: The study involved 86 undergraduate tutors from a Mid-Atlantic US college providing remote math tutoring to middle school students (~five U.S. states, mostly low-income). Tutors completed six scenario-based lessons covering six tutor moves. Training data consisted of pre- and post-test open response and multiple-choice answers (433 lessons completed). Real-life data included 405 session-to-lesson pairs where tutors had transcript recordings (audio processed via OpenAI Whisper, combined with synchronized Zoom chat). All transcripts were deidentified. Data are publicly accessible via DataShop and GitHub.
Architecture / Algorithm: The core is an AI scoring pipeline using Gemini-2.5-pro (a generative large language model) with a two-stage prompt design: first to detect pedagogical "opportunities" in transcripts where a move could be applied; second, to evaluate the quality of tutor execution (binary 0/1 scoring with supporting evidence). The LLM was prompted with expert-validated human coding rubrics for six tutor moves (e.g., REACT_ERRORS, GIVE_PRAISE) derived from educational theory. Open responses during training were similarly scored by the LLM using prompts linked to scoring rubrics.
Training Regime: Tutors completed six lessons each, covering open response predict and explain items plus multiple-choice questions. Open responses were manually annotated by human coders on a subset for interrater reliability benchmarking. The AI system was not trained but used zero-shot/few-shot scoring with prompt engineering to align with human rubrics. No further ML model training details are provided for Gemini-2.5-pro.
Evaluation Protocol: Learning gains were computed from pre- to post-test lesson scores. Predictive validity was assessed by correlating training scores with real-life transcript scoring using Pearson correlations and linear mixed-effects models with tutor random effects. Model comparisons using Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) compared predictors based on open-response, multiple-choice, and combinations thereof. Interrupted time series (ITS) analysis modeled tutor quality trends longitudinally pre- and post-training. Human inter-rater reliability (IRR) was measured by Cohen’s kappa comparing expert human coders and AI scoring on subsets of transcripts and training items.
Reproducibility: All datasets, human annotation rubrics, and LLM scoring prompts are released openly through GitHub and DataShop. However, full details about Gemini-2.5-pro configuration are not disclosed, and the model is not open-source. Some IRR metrics indicate small sample sizes limit reliability evaluation robustness. Overall, the system is designed to be reproducible given access to the underlying LLM and prompt templates.
Concrete Example: For a tutor session transcript, Gemini-2.5-pro is prompted first to identify if an opportunity existed for REACT_ERRORS (e.g., student makes a math error). If opportunity=1, a second prompt asks the AI to score the quality of the tutor’s response on a 0/1 scale and return textual evidence from the transcript supporting the rating. This process is repeated for all six tutor moves, enabling scoring of real-life application skills. These outcomes are statistically analyzed against the tutors’ training test scores to validate predictive relationships.
Technical innovations
- Development of a two-stage LLM prompting pipeline to first identify pedagogical opportunities in authentic tutoring transcripts, followed by assessment of tutor move execution quality.
- Application of generative AI (Gemini-2.5-pro) to score open responses in tutor scenario-based training and real-life tutoring interactions with alignment to expert human rubrics.
- Integration of training performance data from multiple formats (open response and MCQs) with real-life application metrics using mixed-effects statistical models to establish predictive validity.
- Open sourcing of the AI prompts, scoring rubrics, and tutor training datasets to promote transparency and reproducibility in AI-driven tutor assessment.
Datasets
- Tutor training lesson dataset — 433 lesson completions, open-source (DataShop)
- Real-life tutor transcript dataset — 405 session-to-lesson transcript pairs, de-identified, open-source (DataShop, GitHub)
Baselines vs proposed
- Multiple-choice only model: AIC = 1150.0, BIC = 1166.0 vs. combined MCQ + open-response model: AIC = 1129.7, BIC = 1145.8
- Open-response only model: AIC = 1130.0, BIC = 1146.1 vs combined model: AIC = 1129.7, BIC = 1145.8
- Overall training performance model (both MCQ + open response): correlation with real-life transcript score = 0.25 SD (p < .001)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18617.
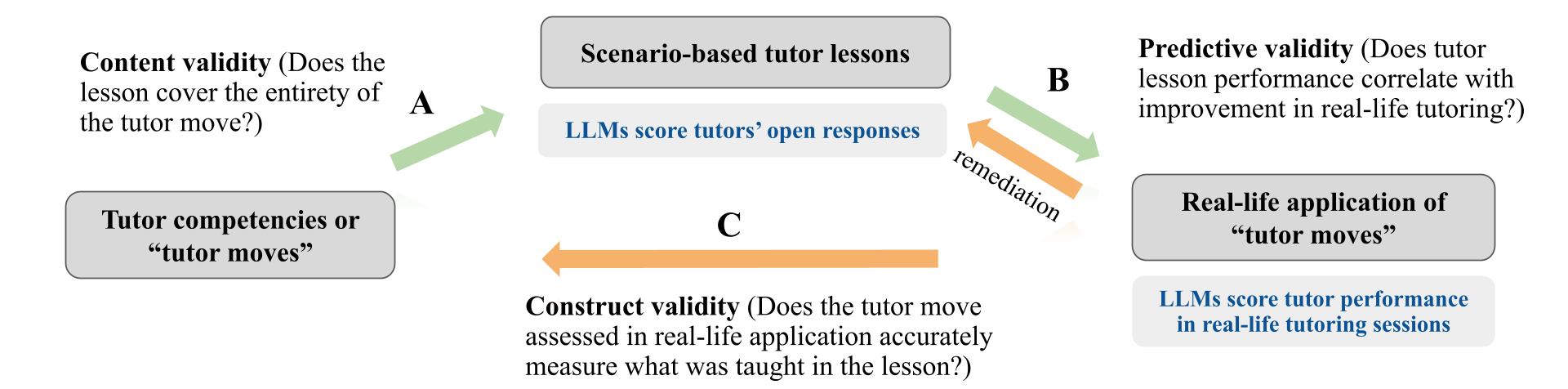
Fig 1: AI-driven tutor training and real-life assessment system.

Fig 2: Interrupted-time series research design.

Fig 3: Pretest-posttest instructional design.
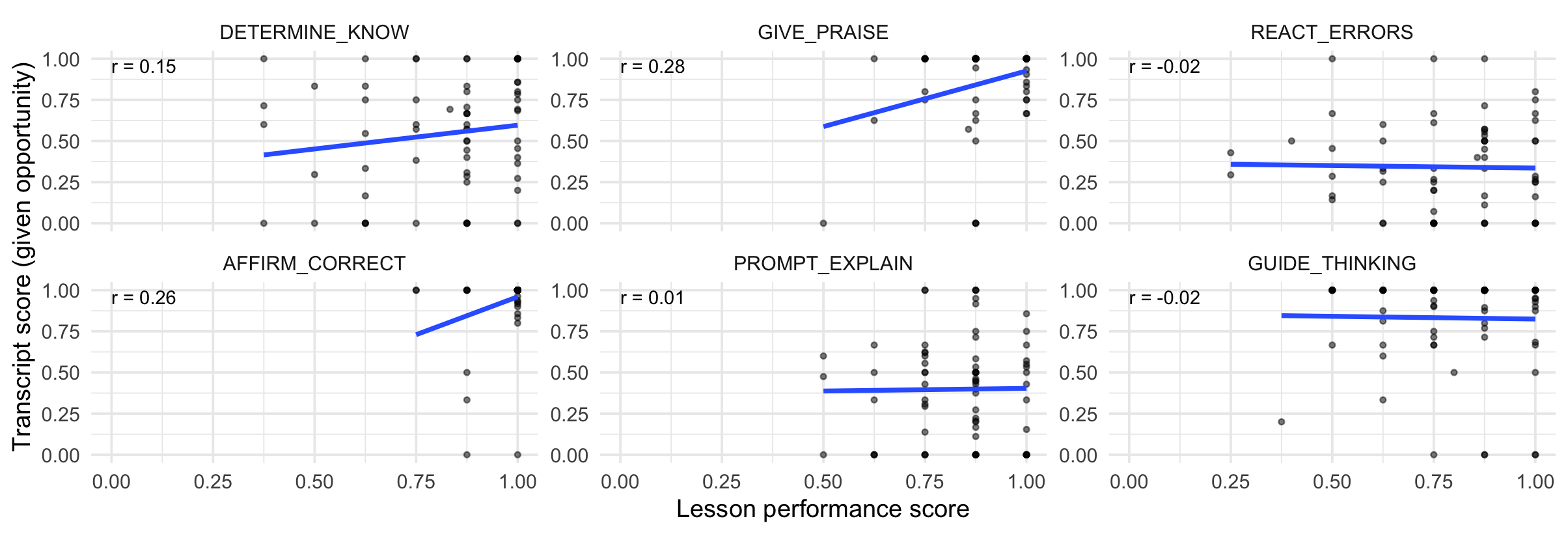
Fig 4: Linear relationship between lesson performance and assessment of real-life
Limitations
- Human-to-LLM inter-rater agreement was moderate to low (κ as low as 0.38), likely due to small transcription sample (10 transcripts) and skewed data distributions rather than poor model performance.
- Ceiling effects in some tutor moves (e.g., AFFIRM_CORRECT) limit observable learning gains and predictive validity for those skills.
- Interrupted time series analysis showed skill improvements were gradual rather than immediate post-training, suggesting one-off scenario-based lessons may be insufficient for rapid behavioral change.
- The system does not train or evaluate tutors’ ability to identify pedagogical opportunities, only their execution after opportunities arise.
- The tutor sample was limited to 86 undergraduates from a single geographic region, potentially limiting generalizability.
- No direct student outcome data was linked to tutor move performance to establish downstream educational impact.
Open questions / follow-ons
- How can active feedback loops leveraging AI-assessed real-life performance improve tutor skill acquisition longitudinally?
- Can models be developed to assist tutors in recognizing pedagogical opportunities, in addition to improving execution quality?
- What is the downstream impact of improved tutor moves on student learning outcomes and engagement?
- How robust are AI assessments of tutoring moves across other subject domains, tutoring modalities, and more diverse tutor populations?
Why it matters for bot defense
This work is relevant to bot-defense and CAPTCHA practitioners focusing on designing AI systems that assess nuanced human behaviors in real-world interactions. The study demonstrates a novel pipeline where large language models analyze conversational transcripts to detect context-dependent opportunities and evaluate the quality of human responses. This approach may inspire new CAPTCHAs or bot-detection mechanisms that assess behavioral competencies beyond binary challenge responses, such as conversational moves or decision-making quality.
Additionally, the use of combined multiple-choice and open-response formats alongside transcript analysis highlights the need for multiple data modalities to robustly predict real-world human intent or competence. The challenges with inter-rater reliability and data imbalance also underscore the difficulties in reliably automating subjective evaluation tasks, an important consideration for bot-detection systems relying on AI interpretation of human behavior. Overall, this paper contributes methods and insights into bridging training assessment with authentic interactions, which can inform the design of behavioral analysis CAPTCHAs or bot defenses requiring complex understanding of human dialog.
Cite
@article{arxiv2606_18617,
title={ AI-Driven Assessment of Human Tutors: Linking Training Performance to Real-Life Practice },
author={ Danielle R. Thomas and Marie Cynthia Abijuru Kamikazi and Clara Brandt and Conrad Borchers and Kenneth R. Koedinger },
journal={arXiv preprint arXiv:2606.18617},
year={ 2026 },
url={https://arxiv.org/abs/2606.18617}
}