
A Unified Framework for Efficient Remote Sensing Visual Question Answering: Adapting Dual, Hybrid, and Encoder-Decoder Architectures
Source: arXiv:2606.19277 · Published 2026-06-17 · By Timothy Agboada, Shikha Chandel, Yadav Raj Ghimire, Leila Hashemi-Beni
TL;DR
This paper addresses the challenge of adapting general-domain Vision-Language Models (VLMs) for Visual Question Answering (VQA) in the Remote Sensing (RS) domain, where high-resolution aerial imagery presents unique visual complexities such as multi-scale objects and domain shifts. The authors propose a unified Parameter-Efficient Fine-Tuning (PEFT) framework called RSAdapter, which injects lightweight bottleneck adapter modules into frozen transformer backbones of three representative architectures: Dual-Encoder (CLIP), Encoder-Decoder (BLIP), and Hybrid (FLAVA). This "architectural surgery" allows rapid domain adaptation by training less than 5% of parameters, avoiding costly full fine-tuning.
Experiments on the high-resolution RSVQAx dataset demonstrate that all three architectures with RSAdapter obtained convergence with limited data, but the hybrid FLAVA model achieved the highest accuracy (79.2%) compared to BLIP (76.8%) and CLIP (72.4%). The results show FLAVA's superior multimodal fusion and reasoning capabilities suited for RS VQA. The study establishes a new baseline for resource-efficient, scalable Earth observation VQA applicable to disaster response and urban monitoring scenarios.
Key findings
- Using RSAdapter, less than 5% of each model's parameters were trainable during adaptation.
- On a 30% subset of the RSVQAx dataset, the Hybrid FLAVA model attained 79.2% accuracy, outperforming the Encoder-Decoder BLIP (76.8%) and Dual-Encoder CLIP (72.4%).
- CLIP converged fastest (~Epoch 4) but plateaued at a lower accuracy, struggling especially with counting tasks due to late fusion architecture.
- FLAVA reduced false positives in water detection queries by 12% compared to CLIP, thanks to deeper multimodal fusion.
- All models struggled with counting more than 10 objects, likely due to resolution constraints (224x224).
- Restricting the answer classification vocabulary to the top 21 most frequent answers covered 95% of dataset instances and stabilized training under data scarcity.
- Adapters injected in both attention and MLP layers with a bottleneck rank of 64 provided a good balance of efficiency and capacity.
- Freezing backbone weights and tuning only adapters and classification heads enabled resource-efficient fine-tuning on a single 16GB RTX A4000 GPU.
Threat model
Not a security-focused paper. The primary challenge addressed is domain-shift adaptation from general web-trained vision-language models to the remote sensing domain under resource constraints and limited labeled data. No adversarial or malicious actors are considered.
Methodology — deep read
Threat Model and Assumptions: The work assumes a scenario where a pretrained VLM—originally trained on general internet images and text—is adapted to the RS domain. The adversary or challenge is the domain shift: large differences in visual features, scales, and semantics between RS images and typical web images. They do not consider adversarial attacks or malicious adversaries, but rather focus on efficient retraining under limited labeled data.
Data: The RSVQAx High-Resolution (HR) dataset derived from USGS orthoimagery at 15-30 cm resolution was used. It contains 772 images and 1,000+ QA pairs covering simple presence, complex counting, and land use queries. For experiments, a random 30% subset of training data was used to simulate data scarcity in disaster scenarios. Images were resized to 224x224 for CLIP/FLAVA and 384x384 for BLIP, applying minimal augmentation (random horizontal flips) to maintain spatial fidelity.
Architecture/Algorithm: Three VLM architectures were studied:
- Dual-Encoder CLIP: Image and text separately encoded with ViT and text transformer, final embeddings fused by dot product.
- Encoder-Decoder BLIP: BERT-like multimodal transformer with cross-attention layers linking vision encoder and text decoder.
- Hybrid FLAVA: Separate unimodal image and text encoders plus a shared multimodal fusion encoder allowing deep cross-modal interactions.
The key novelty is the RSAdapter: inserting lightweight bottleneck adapter modules with residual connections in the MHSA and MLP transformer blocks of frozen backbones to enable parameter-efficient domain adaptation. The adapter has a down-projection (D to r=64), a gelu activation, and an up-projection (r to D=768). This "architectural surgery" was applied distinctly per architecture at appropriate attention and fully connected layers.
Training Regime: The backbone weights were frozen; only RSAdapters, LayerNorm layers, and final classification head (linear) were trainable. Batch size was 16, learning rate 1e-4, optimizer AdamW, trained for 15 epochs on a single NVIDIA RTX A4000 GPU (16GB VRAM). No random seeds or multiple runs are reported.
Evaluation Protocol: Accuracy on the RSVQAx test set was the main metric. Baselines were the same architectures without adaptation or other PEFT methods (not explicitly described). Performance broken down by question type (presence, area, counting). Ablation on vocabulary pruning was performed limiting the classification head to top 21 frequent answers covering 95% of dataset. Qualitative failure mode analysis examined typical error types.
Reproducibility: Implementation was done in PyTorch Lightning with a unified VQAModel managing training loops. The paper does not mention code release or frozen weights availability. The RSVQAx dataset is public. Some hyperparameter and configuration details are explicitly provided, but full scripts and seeds are not.
Concrete example: To adapt the FLAVA model, the authors injected RSAdapters into all FlavaLayer blocks shared between unimodal and multimodal encoders. During a forward pass, the frozen backbone outputs feature embeddings, while RSAdapters transform these features through bottleneck layers, adjusting them for RS domain semantics. The output went through a linear classification head predicting one of the top 21 answers. Only the RSAdapter and classification head parameters were updated via backpropagation for 15 epochs on 30% of RSVQAx training data, yielding 79.2% accuracy on the test set.
Technical innovations
- Unified architectural surgery pipeline injecting lightweight bottleneck adapter modules directly into attention and MLP layers of frozen VLM backbones for RS domain adaptation.
- Systematic comparative evaluation of parameter-efficient fine-tuning across three distinct VLM paradigms: Dual-Encoder (CLIP), Encoder-Decoder (BLIP), and Hybrid (FLAVA), within a single study.
- Adaptation of RSAdapter method, originally designed for RS classification, to complex multi-step reasoning VQA tasks in remote sensing with minimal trainable parameters (<5%).
- Top-K vocabulary pruning strategy restricting classification head to the most frequent 21 answers to stabilize training under long-tailed answer distributions in RS VQA.
Datasets
- RSVQAx High-Resolution — 772 images, 1,000+ QA pairs — derived from USGS orthoimagery, public
Baselines vs proposed
- CLIP-ViT-B/32 (Dual Encoder): Accuracy = 72.4% vs FLAVA-Full (Hybrid): 79.2%
- BLIP-Base (Encoder-Decoder): Accuracy = 76.8% vs FLAVA-Full (Hybrid): 79.2%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19277.
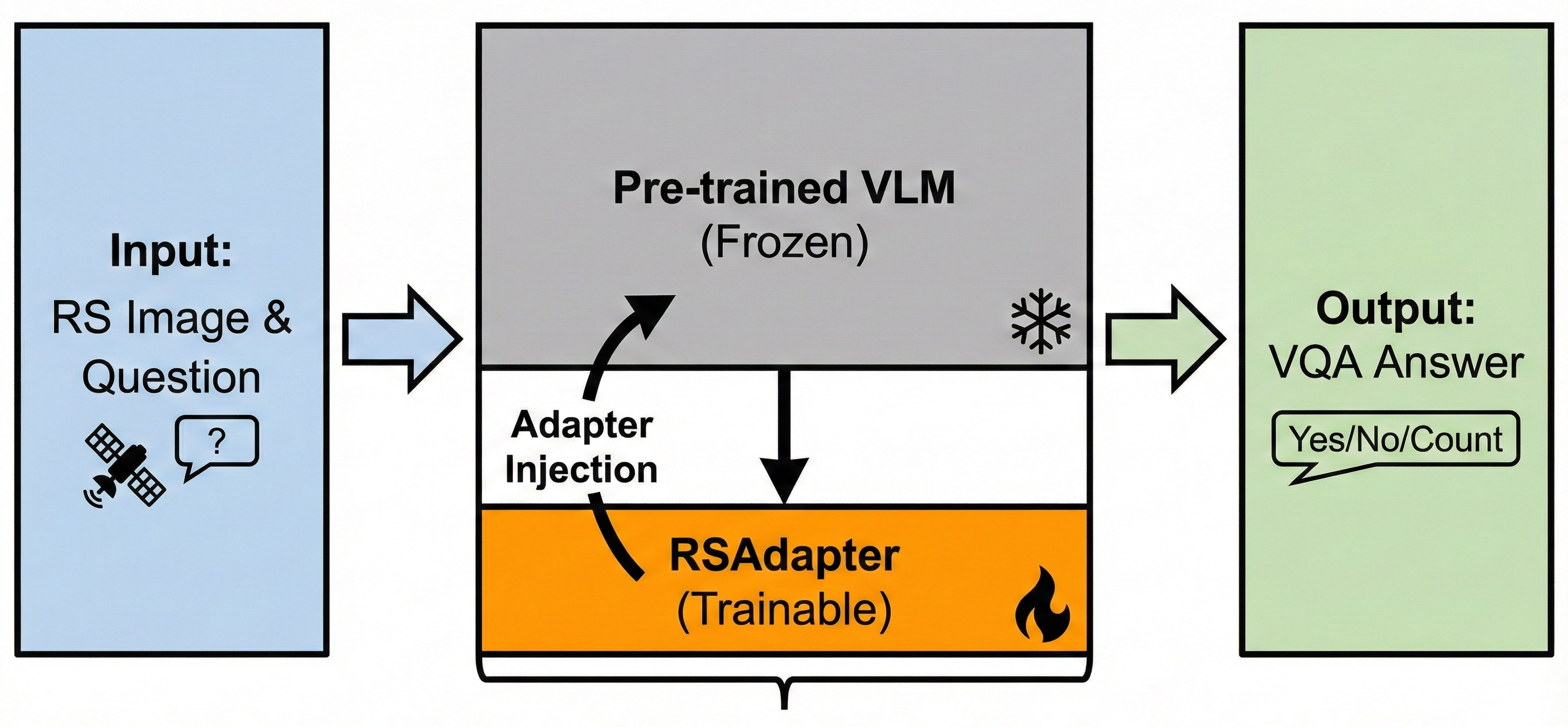
Fig 1: Overview of the RSAdapter Architectural Surgery pipeline.
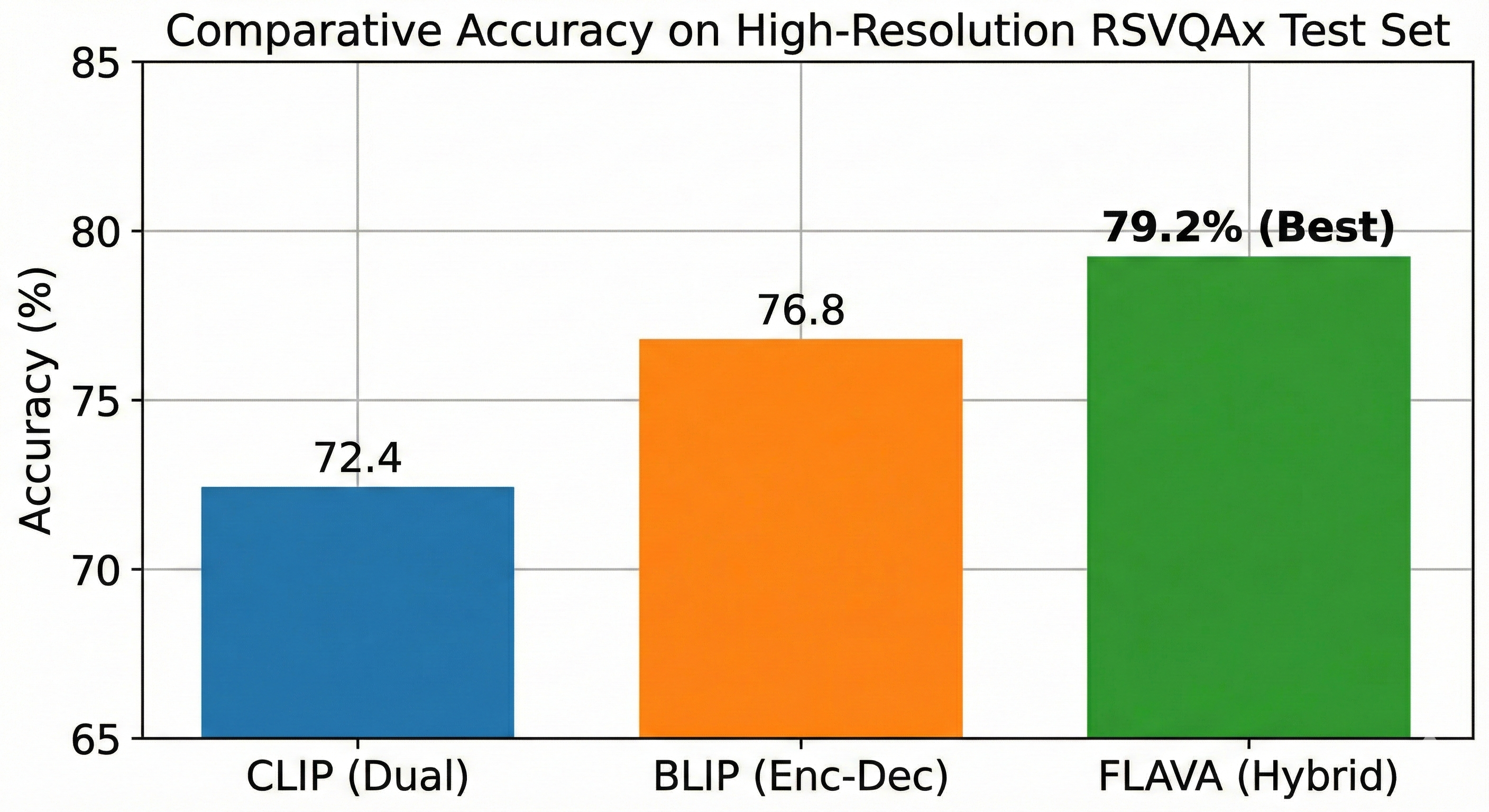
Fig 2: Accuracy breakdown by architecture.
Limitations
- Evaluation limited to a single dataset (RSVQAx) with relatively small size (772 images, 1,000 QA pairs), which may limit generalizability.
- Experiments conducted on a 30% subset to simulate few-shot setting, but impact of full dataset training or cross-dataset evaluations remain unknown.
- No explicit adversarial robustness or attack resilience testing of adapted models.
- Limited analysis of sensitivity to hyperparameters beyond single configuration reported (e.g., bottleneck rank fixed at 64).
- Resolution bottlenecks (224x224 or 384x384) caused failures in dense counting scenarios, indicating scalability challenges for ultra-high resolution imagery.
- No publicly released code or pre-trained adapter weights mentioned, affecting reproducibility.
Open questions / follow-ons
- How well does the RSAdapter framework generalize across other remote sensing tasks beyond VQA, such as image segmentation or change detection?
- What are the impacts of varying bottleneck ranks or adapter insertion strategies on model performance and parameter efficiency?
- Can multi-temporal or multi-spectral remote sensing data be integrated within this adapter-based fusion framework to improve temporal change detection VQA?
- How do these adapter-based adapted models perform under distribution shifts caused by sensor types, seasonal changes, or geographic variation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper's detailed exploration of parameter-efficient fine-tuning via adapters in vision-language transformers is valuable for scenarios where lightweight model adaptation to new domains is required under limited data and compute budgets. The unified architectural surgery approach provides practical insight on injecting minimal trainable modules to repurpose foundation models without full retraining—a principle applicable to designing efficient CAPTCHA solvers or visual challenge systems. Moreover, understanding the trade-offs across different VLM architectures (dual-encoder, encoder-decoder, hybrid) helps inform model selection strategies when deploying vision-language tasks embedded with security checks.
The findings on vocabulary pruning to stabilize classification under long-tail label distributions and the importance of multimodal fusion highlight considerations when designing robust, explainable AI defenses against automated or adversarial image+text input attacks. This work also underscores the limits of late-fusion models for spatially detailed reasoning—critical for defending against bots that exploit coarse semantics. While this study focuses on remote sensing imagery, the methodological insights into adapter placement, lightweight parameter learning, and architectural choice have direct relevance to improving the efficiency and robustness of visual language models used in CAPTCHAs or multimodal authentication.
Cite
@article{arxiv2606_19277,
title={ A Unified Framework for Efficient Remote Sensing Visual Question Answering: Adapting Dual, Hybrid, and Encoder-Decoder Architectures },
author={ Timothy Agboada and Shikha Chandel and Yadav Raj Ghimire and Leila Hashemi-Beni },
journal={arXiv preprint arXiv:2606.19277},
year={ 2026 },
url={https://arxiv.org/abs/2606.19277}
}