
A Multi-Domain Benchmark for Detecting AI-Generated Text-Rich Images from GPT-Image-2
Source: arXiv:2606.19259 · Published 2026-06-17 · By Yijin Wang, Shuyi Wang, Wenhan Zhang, Yuqi Ouyang
TL;DR
This paper addresses the emerging challenge of detecting AI-generated text-rich images synthesized by state-of-the-art multimodal models, specifically OpenAI's GPT-Image-2. Unlike previous work that largely focuses on object-centric images, this study concentrates on a diverse set of text-rich domains where textual semantics, layout structure, and visual organization jointly shape authenticity assessment. The authors introduce a new multi-domain benchmark dataset comprising 8,602 images across six categories—commercial posters, infographics, academic posters, receipts, tables, and UI screenshots—combining both real and generated samples. They evaluate five representative AI-generated image detectors in a zero-shot manner, revealing that detector performance is highly category-dependent and sensitive to post-processing operations like JPEG compression. Furthermore, they conduct a preliminary evaluation of a powerful multimodal vision-language model, GPT-5.5, which shows superior performance overall but still struggles with highly structured formats such as tables and UI screenshots.
Key findings
- The dataset contains 8,602 images: 5,616 generated and 2,986 real across six categories (Table 1).
- NPR detector achieves highest overall F1 score of 82.66% and accuracy of 80.45% on the benchmark (Table 3).
- Detectors show strong domain dependence, e.g., NPR F1 ranges from 13.58% on tables to 99.24% on commercial posters (Table 4).
- JPEG compression drastically reduces detector performance; NPR F1 drops from 82.66% to 33.98% even with mild compression (Fig. 7).
- Category-wise, detectors perform reliably on commercial posters (average F1 ~70%) but poorly on tables and receipts (F1 ~40-50%) (Fig. 5).
- GPT-5.5 vision-language model achieves 85.72% accuracy overall, outperforming baselines but falls to 55.63% accuracy on tables (Fig. 8).
- GPT-5.5 relies on semantic and structural inconsistencies (e.g., arithmetic errors in receipts) for detection but struggles when such cues are subtle.
- Existing detectors trained on conventional images do not generalize well to highly structured text-rich images generated by GPT-Image-2.
Threat model
The adversary is a content generator using advanced multimodal image generation systems (GPT-Image-2) capable of producing fully synthesized, visually realistic text-rich images across multiple domains. The adversary cannot modify existing detection models but aims to produce images that evade detector identification while maintaining plausible textual and layout authenticity.
Methodology — deep read
The authors first define the threat model as detecting fully AI-generated text-rich images across multiple domains where generated text and layout coherence pose detection challenges. The adversary is assumed to have access to powerful multimodal image generation models (GPT-Image-2) capable of realistic text and structured layouts, though not to directly compromise detection forms or retrain detectors.
They curate real samples from multiple public datasets spanning six categories: commercial posters (MARIO-LAION), infographics (InfographicVQA), academic posters (PosterSum), receipts (SROIE), tables (PubTabNet), and UI screenshots (Enrico). This combination ensures domain diversity and real-world relevance.
Synthetic images are generated by converting real samples into abstracted prompt representations capturing structural, semantic, and stylistic cues without reusing literal text, thus preserving privacy and avoiding replication. Prompts guide GPT-Image-2 to produce full images with text and layout patterns resembling originals but with fictionalized content.
Five detector baselines are selected covering diverse detection strategies: CNNSpot (CNN artifact-based), NPR (neighboring pixel relationship feature), HPAI-BSC/SuSy (patch-level ResNet-18), dima806 (ViT-based), and prithivMLmods (SigLIP vision-language). All are used off-the-shelf in a zero-shot setting without fine-tuning.
The detectors classify each image once, with outputs binarized at 0.5 threshold. No dataset-specific adaptations, augmentations, or ensemble methods are applied. Input resizing and normalization follow official pipelines.
Evaluation metrics include accuracy, precision, recall, and F1, with a focus on AI-generated images as positive class. Category-wise analysis and post-processing robustness are studied. Post-processing tests include JPEG compression at varying quality, resizing with compression, and PNG re-encoding.
An exploratory evaluation with GPT-5.5 vision-language model assesses the promise and limitations of integrated multimodal reasoning for this task.
Code and dataset details are not explicitly provided, but the dataset release is mentioned. Baseline weights are publicly available from original sources.
Technical innovations
- A new multi-domain benchmark dataset of 8,602 text-rich images across six diverse categories generated by GPT-Image-2, combining real and synthetically generated samples with privacy-preserving prompt synthesis.
- A two-dimensional conceptual framework for text-rich image generation defined by text-layout regularity and functional context, guiding dataset curation and prompt design.
- Systematic zero-shot evaluation of diverse representative AI-generated image detectors on challenging text-rich image categories, exposing severe domain-dependent performance gaps.
- Demonstration of catastrophic degradation of artifact-based detectors under standard lossy JPEG compression in text-rich scenarios.
- Exploratory use of GPT-5.5 multimodal vision-language model showing improved detection ability via semantic, textual, and structural consistency reasoning, though limited on highly structured visual-textual formats.
Datasets
- Proposed multi-domain GPT-Image-2 benchmark — 8,602 images (5,616 generated, 2,986 real) — collected from multiple public sources (MARIO-LAION, InfographicVQA, PosterSum, SROIE, PubTabNet, Enrico) with synthetic images generated via abstraction-based prompts
Baselines vs proposed
- NPR: accuracy = 80.45%, F1 = 82.66% vs best baseline
- HPAI-BSC/SuSy: accuracy = 65.32%, F1 = 78.39%
- dima806 (ViT): accuracy = 59.57%, F1 = 71.03%
- prithivMLmods (SigLIP): accuracy = 48.51%, F1 = 55.45%
- CNNSpot: accuracy = 36.42%, F1 = 5.63%
- GPT-5.5 vision-language: accuracy = 85.72%, category max 90%+ except 55.63% on tables
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19259.

Fig 1: Representative AI-generated samples across six text-rich image categories.
Fig 2: Comparison of representative text-rich datasets and our benchmark.
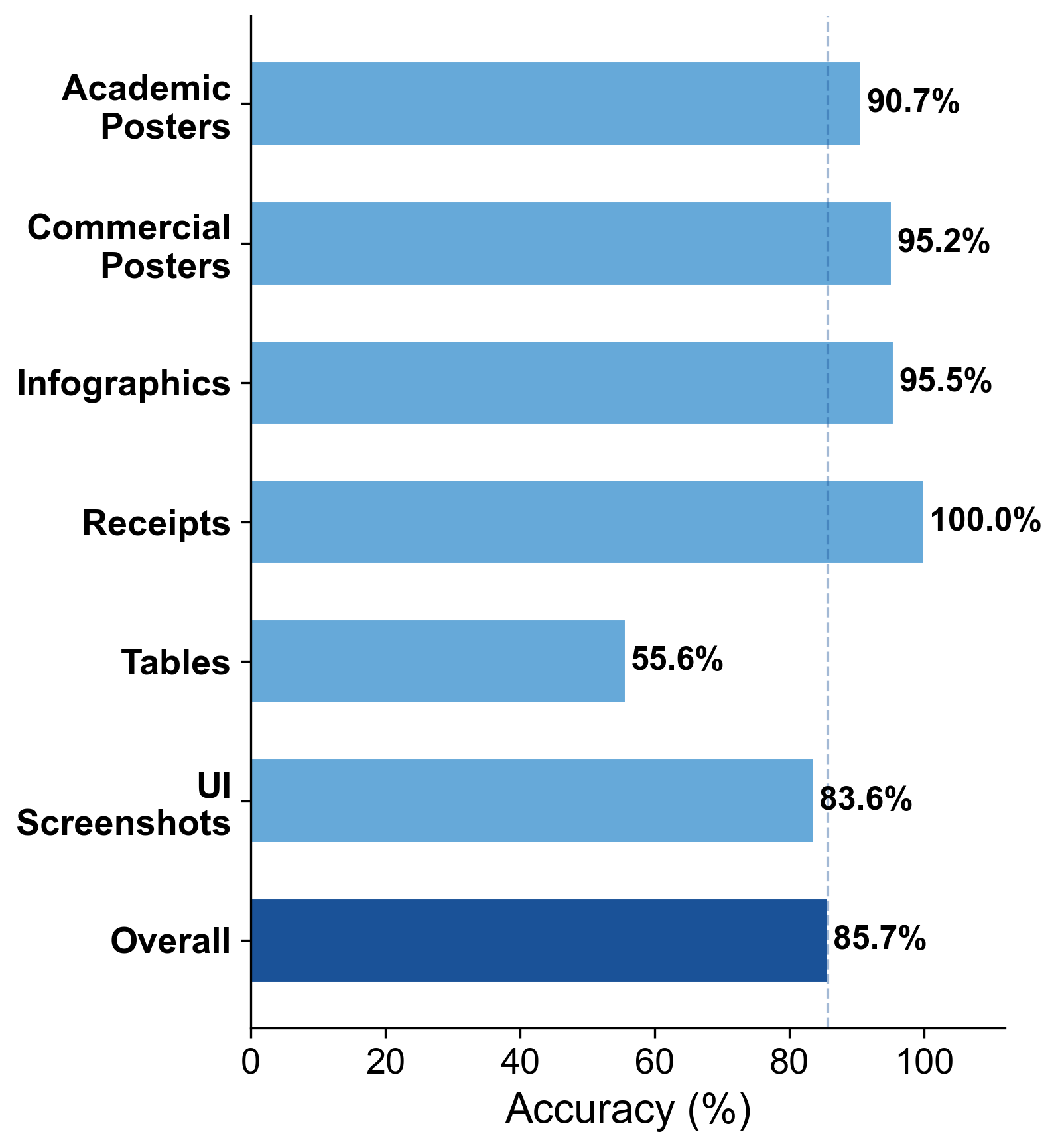
Fig 8: Category-wise Accuracy of
Fig 9: Representative anomalies observed in GPT-Image-2-generated text-rich images across six

Fig 5 (page 11).

Fig 6 (page 11).

Fig 7 (page 11).
Limitations
- Detectors evaluated only in zero-shot conditions without domain-specific fine-tuning or adaptation.
- Robustness evaluation limited primarily to JPEG compression and resizing; other real-world manipulations (e.g., cropping, noise) not tested.
- Multimodal model evaluation (GPT-5.5) exploratory and interpretability of reasoning remains unclear; reliance on generated explanations may not reflect internal decision process.
- Dataset generation uses abstracted prompts without verifying generation diversity or fidelity beyond visual quality, potential for domain bias.
- Real images collected from multiple datasets with variable sample sizes and distributions, which may affect representativeness of category-level analyses.
Open questions / follow-ons
- How can detectors be designed or trained to robustly handle the diversity and complexity of text-layout semantics across multiple domains?
- What strategies can improve detection robustness against lossy image post-processing common in online distribution?
- Can multimodal vision-language models be reliably interpreted to understand their detection reasoning and improve trustworthiness?
- How to effectively incorporate textual, semantic, and structural cues in automated detection pipelines beyond pixel-based artifacts?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights crucial challenges in reliably identifying AI-generated images that contain realistic text and structured layouts, increasingly used in phishing, fraud, or misinformation campaigns. Traditional detectors optimized for natural image artifacts may fail on document-like or interface-rich content, especially under lossy compression in transmission. Integrating text- and layout-aware detection strategies, possibly leveraging multimodal vision-language models, is important to ensure the authenticity of visual content featuring textual information. This benchmark provides a valuable resource to assess and develop detection tools that better reflect real-world complexities encountered in text-rich bot-generated images, which are becoming more common attack vectors in automated abuse scenarios.
Cite
@article{arxiv2606_19259,
title={ A Multi-Domain Benchmark for Detecting AI-Generated Text-Rich Images from GPT-Image-2 },
author={ Yijin Wang and Shuyi Wang and Wenhan Zhang and Yuqi Ouyang },
journal={arXiv preprint arXiv:2606.19259},
year={ 2026 },
url={https://arxiv.org/abs/2606.19259}
}