
A Clinician-Centered Pipeline for Annotation and Evaluation in Ultrasound AI Studies
Source: arXiv:2606.19174 · Published 2026-06-17 · By Fangyijie Wang, Jianjun Yu, Wentao Shi, Haixia Huang, Ran Shi, Guénolé Silvestre et al.
TL;DR
This work addresses a critical gap in medical AI validation by introducing a clinician-centered pipeline designed specifically for ultrasound imaging AI studies. Existing platforms mainly focus on medical image annotation, lacking integrated support for blinded model comparison, multi-rater preference ranking, and reproducible evaluation workflows that closely involve clinicians. The proposed solution enables remote, browser-based clinician participation without direct dataset downloads, preserving data governance and privacy. It integrates annotation, blinded rankings of AI model outputs, centralized aggregation, and automated statistical analysis, facilitating standardized, reproducible human-in-the-loop evaluation.
The pipeline was empirically validated through a fetal ultrasound segmentation study involving six raters with varying expertise levels (experts, generalists, non-experts) and five successive active learning models from a semi-supervised framework. Results showed moderate to strong inter-rater agreement (Kendall's τ ≈ 0.53-0.55; Spearman correlation significant across groups), with stronger preference for later iteration models. This demonstrates the system’s ability to capture meaningful clinician judgments remotely while supporting blinded multi-model comparisons. The pipeline is openly available on GitHub, making it a practical tool for collaborative validation studies in medical imaging AI.
Key findings
- Inter-rater agreement across six clinicians (two experts, two generalists, two non-experts) showed moderate concordance with Kendall's τ mean values of 0.53 for HC18 and 0.55 for ES-TCB datasets.
- Approximately 20.0% (HC18) and 26.7% (ES-TCB) of cases had high inter-rater agreement (τ > 0.7), primarily in images with clearer anatomical boundaries.
- Later active learning models (M3–M5) were significantly preferred in blinded rankings over earlier models (M1), as shown by top-1 selection frequency (Fig. 5).
- Spearman correlation analysis revealed moderate to strong agreement in preference patterns between experts, generalists, and non-experts (significant at p < 0.05 or better).
- Clinicians completed annotation tasks in approximately 45–50 seconds per ultrasound image and blinded ranking tasks in around 30 seconds per case, indicating practical efficiency.
- The pipeline enabled remote, multi-rater evaluation without dataset downloads using a lightweight browser interface and centralized image streaming.
- Automated statistical reporting generated standardized agreement metrics and ranking statistics for reproducible human-AI evaluation studies.
- Blinded randomized presentation of model outputs ensured unbiased clinician preference ranking in the multi-model comparison.
Threat model
The adversary in this scenario is not a traditional attacker but the threat arises from privacy and institutional governance constraints restricting data sharing. Clinicians cannot directly access or download raw patient data to comply with regulations. The system is designed to prevent data leakage by centralizing data hosting and streaming images securely. Adversaries are assumed unable to bypass centralized controls or recover patient data from streamed content; the system does not currently address malicious users or insider threats.
Methodology — deep read
The paper introduces a clinician-centered pipeline for remote annotation and evaluation tailored to ultrasound AI studies, with a demonstration in fetal ultrasound fetal head segmentation.
Threat model & assumptions: The adversary scenario is indirect and concerns privacy and governance constraints limiting data sharing; the pipeline assumes researchers and clinicians have pre-established collaboration but clinicians should not download or directly access raw data, thus requiring centralized data hosting and controlled access. Clinicians are blind to model identity to avoid bias during preference ranking.
Data provenance: Two public fetal ultrasound datasets were used—HC18 (fetal head ultrasound, routine obstetrics) and ES-TCB (trans-cerebellum fetal ultrasound from Spain), with 30 randomly selected cases per dataset (60 total). Each case had 5 anonymized model segmentation outputs (M1–M5) from successive active learning iterations. Data was uploaded to a centralized server.
Architecture/algorithm: The pipeline consists of a centralized researcher server hosting images, AI model outputs, annotations, and study configurations. Clinicians interact via a lightweight browser client that streams images and segmentation overlays. The system supports annotation (segmentation mask creation/editing) and blinded ranking interfaces for multi-model comparison randomized per rater. Results are saved server-side. A Python module handles result aggregation and automated statistical analysis including Spearman correlation, Kendall's τ, top-1 selection, and inter-rater agreement.
Training regime: Not applicable as the paper focuses on evaluation; however, the underlying AI segmentation models (M1–M5) were developed via active learning but training details are limited here.
Evaluation protocol: Six clinicians of varying expertise (2 expert obstetric sonographers, 2 general sonographers, 2 non-experts) participated remotely without local installation or downloads. Each rated 60 cases × 5 models = 300 rankings per rater. Metrics included annotation time per image (~45-50s), ranking time per case (~30s), inter-rater agreement (Kendall's τ), correlation metrics (Spearman), frequency of top-preferred models. Blinded randomization minimized bias. Statistical significance for correlations reported (p < 0.05). No explicit cross-validation.
Reproducibility: The pipeline software is publicly available on GitHub for reproducibility and adoption. The datasets are public (HC18, ES-TCB), facilitating external validation. Code includes annotation, ranking, result aggregation, and statistical reporting.
Concrete example: For one case, clinicians accessed five anonymized segmentation overlays streamed from the server via a browser interface, ranked their quality blindly, and these rankings were saved centrally. Across raters, these were aggregated and compared statistically to identify consensus preferences and inter-rater agreement. Over all cases, this provided a robust human-AI evaluation dataset.
Technical innovations
- Integration of annotation and blinded preference ranking workflows within a lightweight, browser-based pipeline enabling remote, multi-rater clinician participation without dataset downloads.
- Centralized hosting of medical imaging data with secure streaming to clinician clients, preserving privacy while supporting collaborative evaluation across institutions.
- Automated statistical analysis module producing standardized agreement metrics (Spearman, Kendall's τ) and ranking statistics for reproducible clinician-centered AI evaluation.
- Randomized model output ordering uniquely per clinician to ensure blinded, unbiased multi-model comparisons in medical AI validation studies.
Datasets
- HC18 — 30 fetal ultrasound head cases for annotation and evaluation — public, routine obstetric exams
- ES-TCB — 30 trans-cerebellum fetal ultrasound cases — public dataset from Spain
Baselines vs proposed
- N/A — No external baseline comparison reported; evaluation focuses on clinician preference ranking across different active learning model iterations (M1–M5).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.19174.
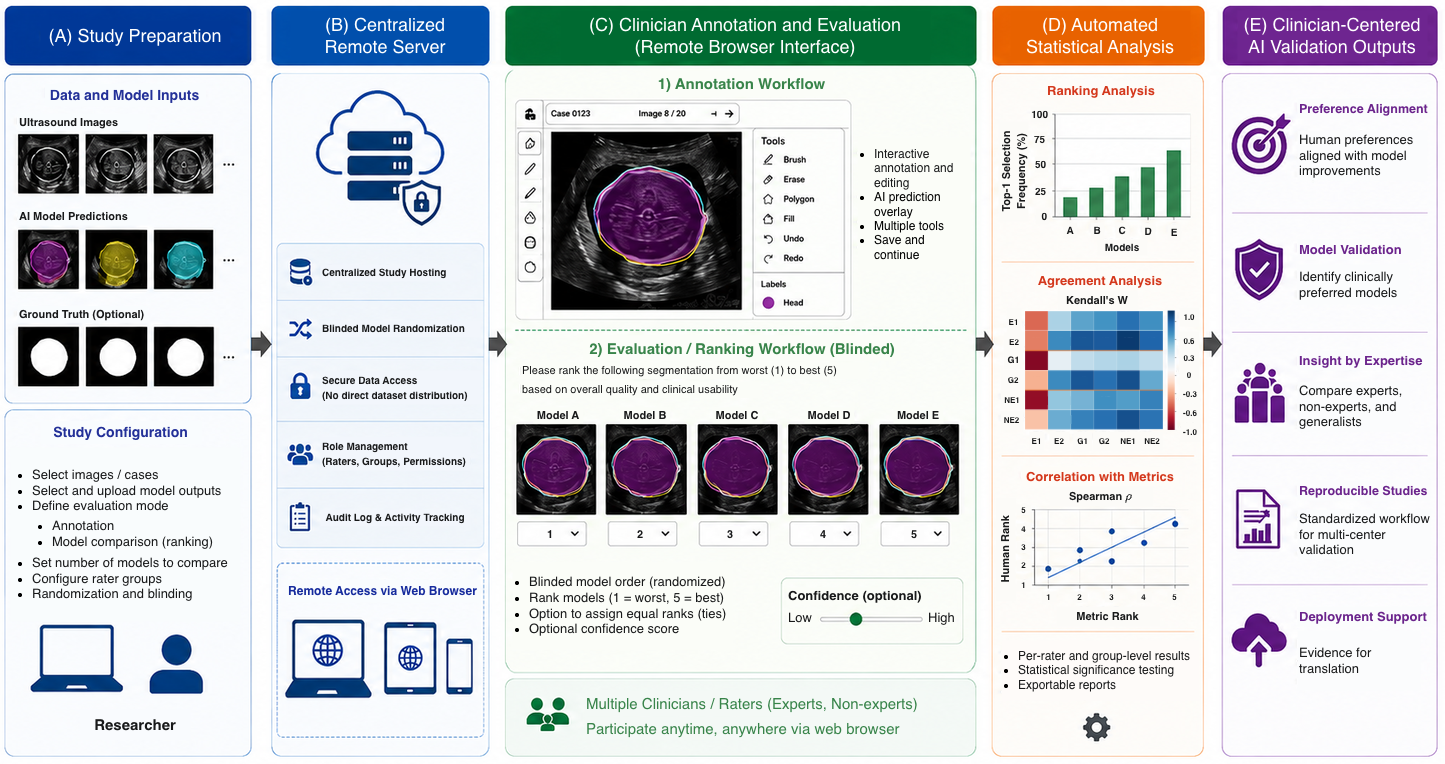
Fig 1: Overview of the proposed clinician-centered pipeline for remote anno-
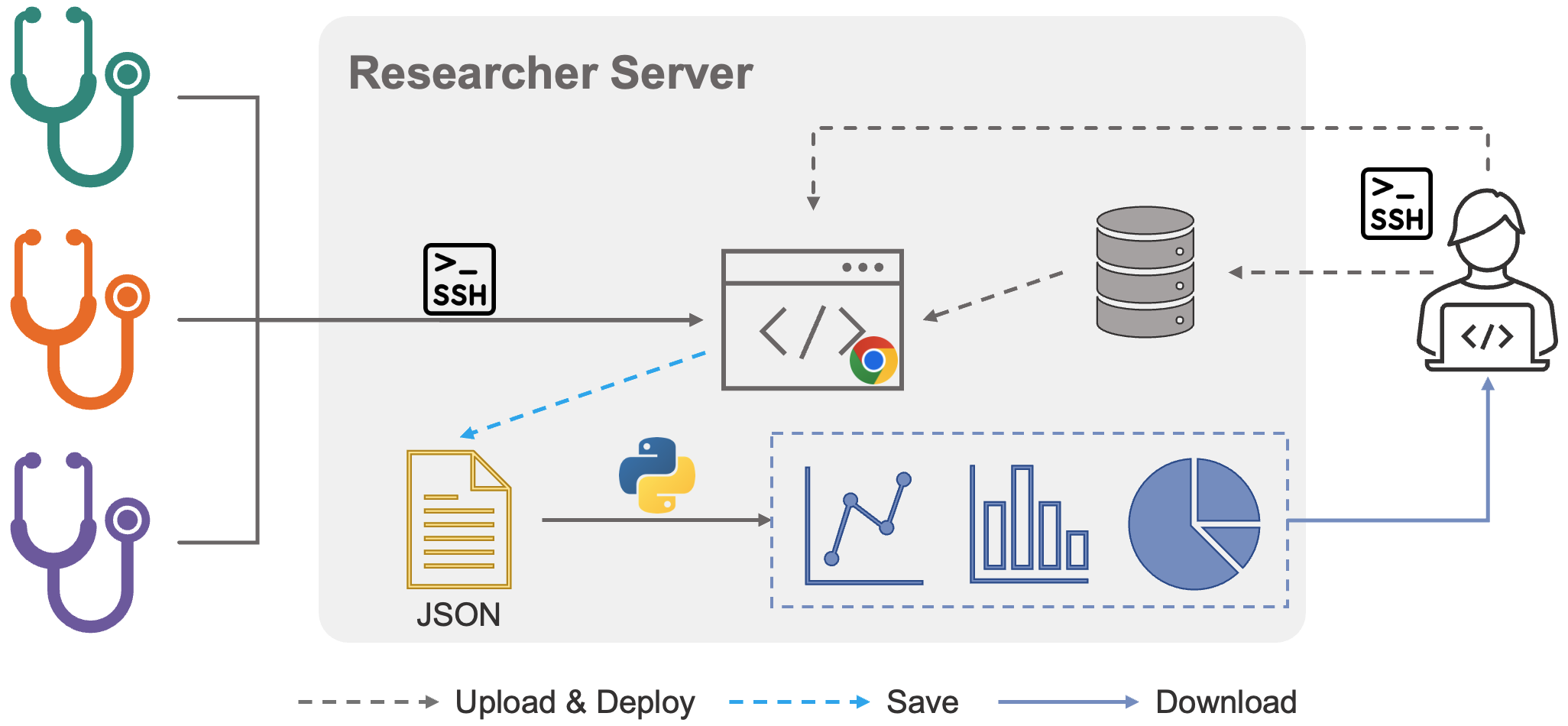
Fig 2: Overview of the remote deployment workflow for clinician and researcher
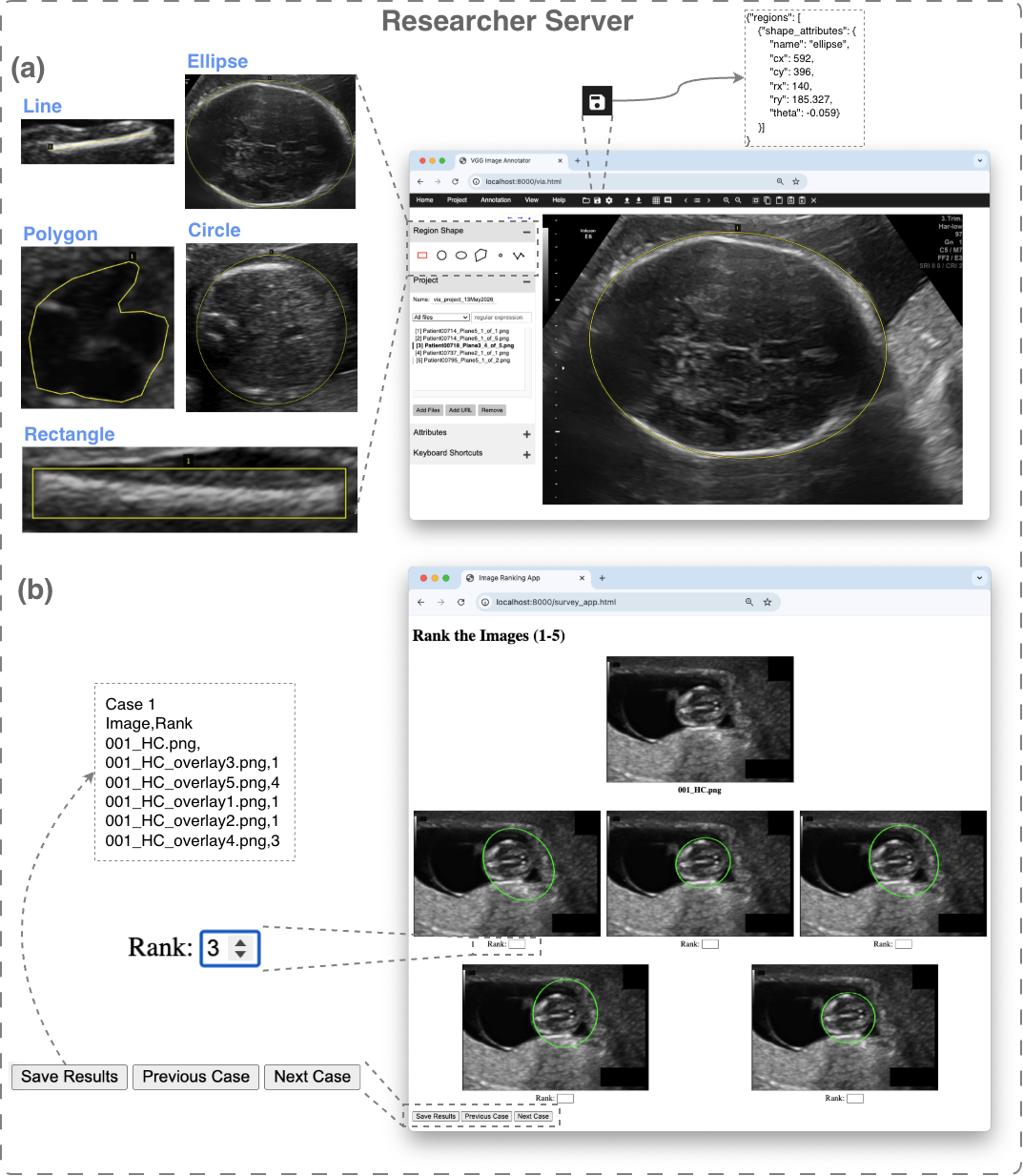
Fig 3: The lightweight interface for clinician annotation and evaluation via
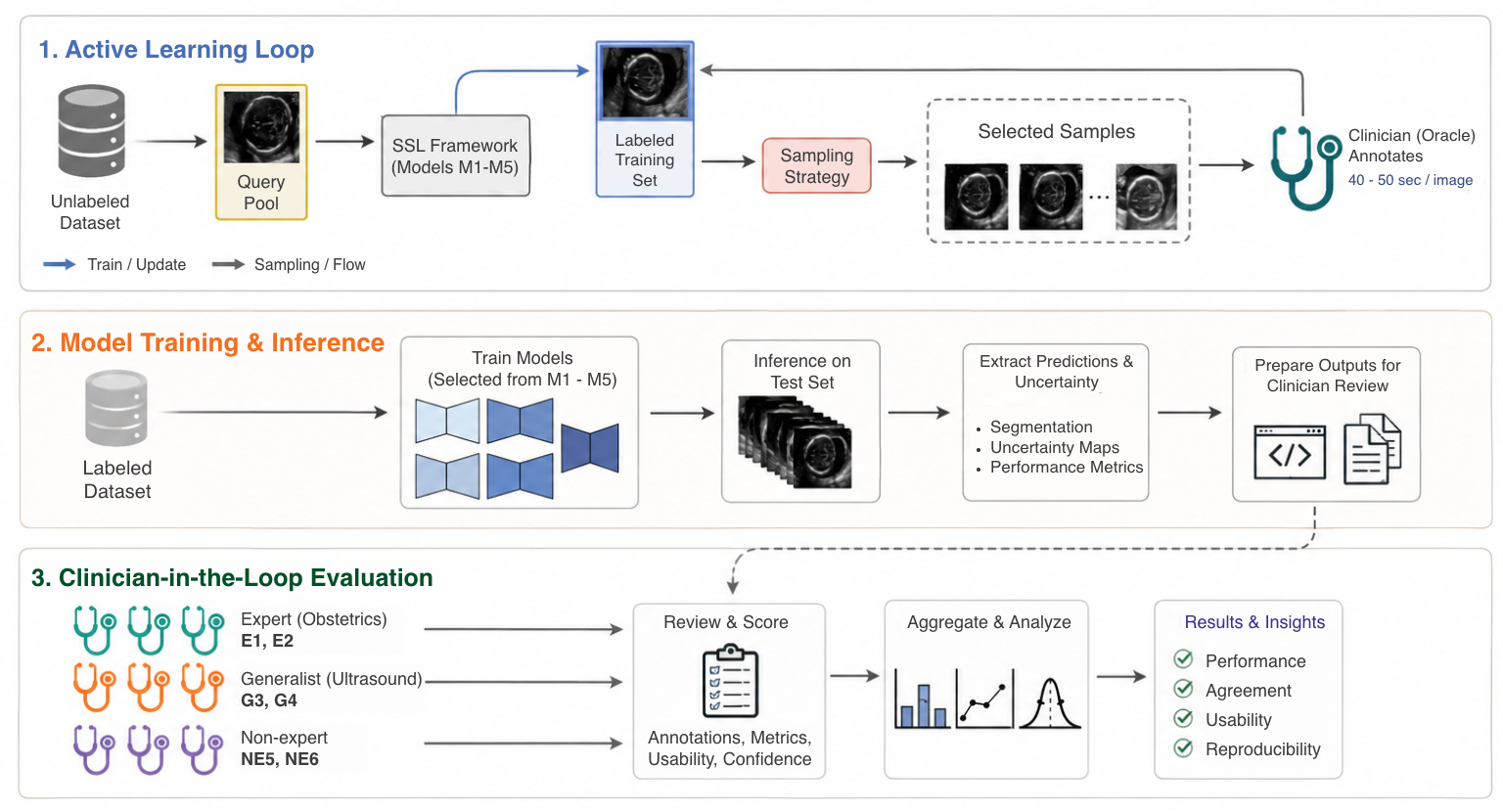
Fig 4: Overview of the clinician-centered pipeline for our ultrasound AI studies.
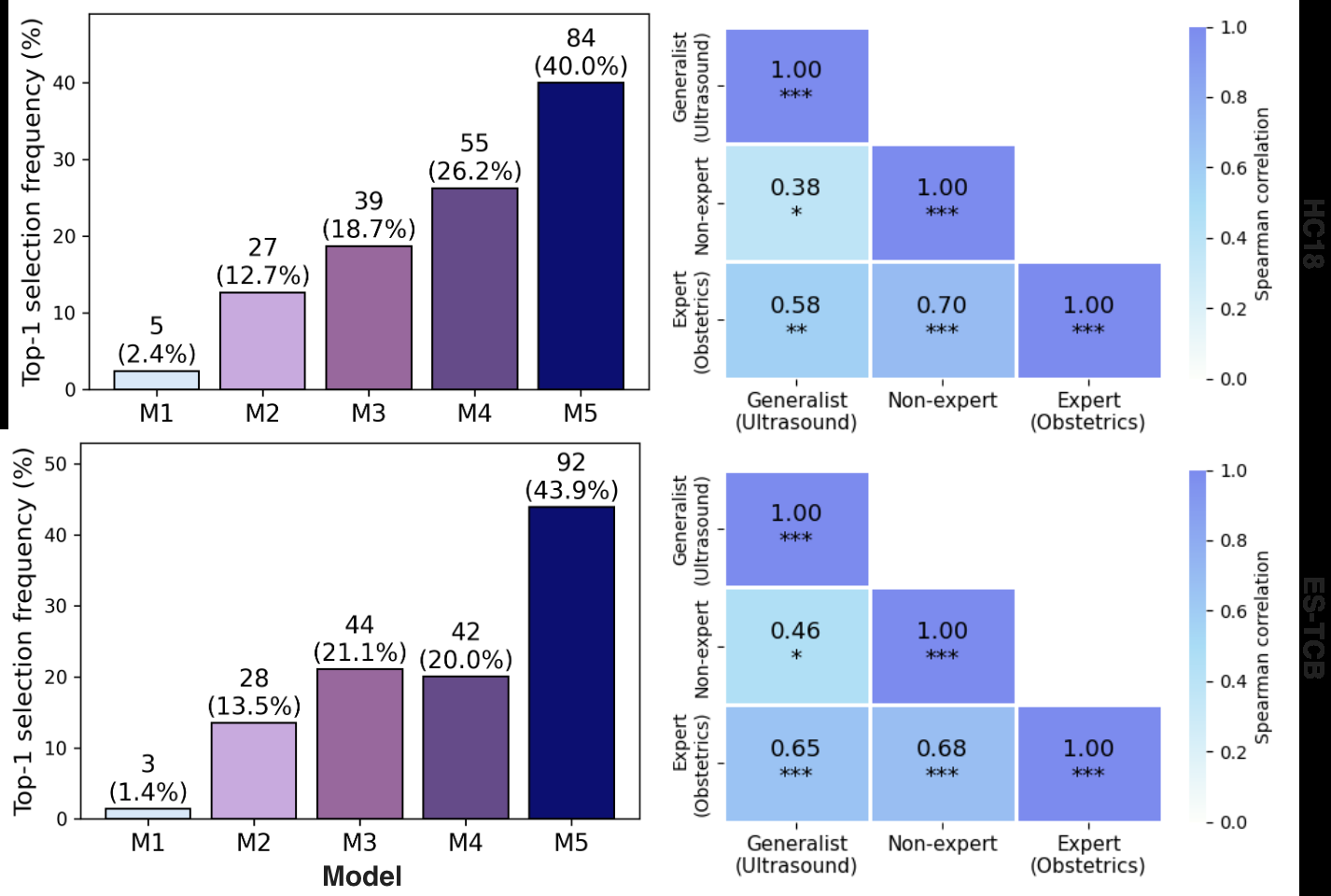
Fig 5: Top-1 selection frequency across models (M1–M5) and inter-group agree-
Limitations
- Current system assumes existing collaboration and does not implement enterprise-grade authentication, role-based access control, or audit logging.
- Usability measures such as clinician satisfaction, cognitive workload, and user experience were not formally assessed.
- Pipeline currently optimized and tested only on ultrasound imaging; generalization to other modalities remains untested.
- Small sample size of clinicians (6 raters) and limited dataset (60 cases) may constrain generalizability.
- No adversarial testing or distribution shift scenarios examined; system robustness under real-world data variability is unknown.
Open questions / follow-ons
- How can enterprise-level access controls, authentication, and audit logging be integrated to support scalable multi-center clinical studies?
- What is the impact of pipeline usability and clinician experience on annotation and evaluation reliability? Formal user studies are needed.
- Can the pipeline be generalized and validated on other medical imaging modalities beyond ultrasound (e.g., MRI, CT)?
- How robust is the evaluation framework under distribution shifts, adversarial attempts, or variability in image quality and clinical settings?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper is a reminder of the critical importance of human-centered evaluation in high-stakes AI deployments, especially in domains where automated quantitative metrics fail to capture true usability or trustworthiness. The pipeline’s design of centralized data hosting combined with lightweight browser-based remote access highlights best practices for privacy-preserving human-in-the-loop evaluation workflows. Although targeted at medical imaging, analogous principles could inform the design of systems requiring blinded multi-rater human judgments without exposing raw data — for example, in CAPTCHA or bot challenge generation where human preferences and subjective judgments are needed.
The demonstration of automated batch statistical analysis to measure inter-rater agreement and preference consistency can serve as a useful methodological framework for assessing human consensus and fidelity in challenges dependent on subjective human annotations or rankings. The pipeline’s architecture also highlights how maintaining data governance, minimizing local data exposure, and supporting remote collaborative evaluation can be balanced—lessons that could be adapted to CAPTCHA evaluation platforms where privacy and data security are priorities.
Cite
@article{arxiv2606_19174,
title={ A Clinician-Centered Pipeline for Annotation and Evaluation in Ultrasound AI Studies },
author={ Fangyijie Wang and Jianjun Yu and Wentao Shi and Haixia Huang and Ran Shi and Guénolé Silvestre and Kathleen M. Curran },
journal={arXiv preprint arXiv:2606.19174},
year={ 2026 },
url={https://arxiv.org/abs/2606.19174}
}