
RubricsTree: Scalable and Evolving Open-Ended Evaluation of Personal Health Agents across Health Memory and Medical Skills
Source: arXiv:2606.18203 · Published 2026-06-16 · By Weizhi Zhang, Zechen Li, Hamid Palangi, Ben Graef, A. Ali Heydari, Simon A. Lee et al.
TL;DR
This paper addresses the critical challenge of scalable, reliable, and clinically aligned evaluation for personal health agents (PHAs) powered by large language models (LLMs). Existing evaluation methods either rely on costly expert annotations that do not scale to continuous open-ended dialogues or on automated judges that lack clinical rigor and consistency. The authors introduce RubricsTree, an expert-curated, hierarchical taxonomy of over 100 atomic, clinically-verifiable Boolean rubrics. This tree structure breaks down complex health agent outputs into fine-grained, verifiable clinical criteria, enabling automated yet expert-aligned evaluation. A context-aware adaptive routing mechanism activates only relevant rubrics per query, further improving scalability and precision. They validate RubricsTree on over 4,000 real user queries and show it substantially improves expert alignment, robustness to input degradations, stability across model backbones and prompt variations, and utility as a training signal. Downstream optimization using RubricsTree yields up to approximately 66% relative gains on HealthBench for multiple biomedical LLM families. Overall, the paper contributes a scalable, auditable, and evolving evaluation framework essential for deploying safe and effective personal health AI agents.
Key findings
- RubricsTree achieves an overall Intraclass Correlation Coefficient (ICC3) of 0.876 and Cohen's κ of 0.787 against an independent panel of six board-certified physicians, compared to ICC3=0.291 and κ=0.431 for the state-of-the-art principle baseline.
- RubricsTree reliably detects contextually degraded inputs with Detection Rates (DR) above 62.9% and up to 100% across four realistic perturbation scenarios (Missing Instructions, Missing User Data, Inappropriate Instructions, Inaccurate User Data), markedly outperforming the principle baseline which suffers negative mean penalties in 9 of 16 test cells.
- Adaptive routing activates only context-relevant rubric subsets per query, improving evaluation throughput and ensuring clinical relevance while maintaining a deterministic, normalized weighting scheme.
- RubricsTree evaluation scores remain highly stable under stochastic variation in model temperature (T=0.1 to 0.9), judge LLM backbones (Gemini and GPT variants), and instruction prompt roles, with consistently higher ICC3 and lower run-to-run variance than the baseline.
- Using RubricsTree as a structured instruction prompt yields relative gains from +18.6% to +66.4% on the HealthBench-Hard dataset across eight evaluated models (Gemini and GPT families).
- Response optimization with RubricsTree feedback further improves performance beyond prompt injection, particularly on safety-critical dimensions such as Completeness and Context Awareness.
- Reinforcement learning using RubricsTree as a reward signal achieves up to +66.7% relative improvement on Qwen 0.6B and +55.3% on Qwen 1.7B models, demonstrating effective clinical reasoning alignment via structured reward guidance.
- RubricsTree's rubric hierarchy evolves from clinical literature and insights from 4,000 real-world user queries through an iterative human-in-the-loop expert curation process.
Threat model
The adversary is essentially real-world noise and corrupted or incomplete user-provided health data and instructions that degrade the personal health agent’s input context. The evaluation framework aims to detect and penalize these degraded or manipulated inputs. It does not consider adversaries who compromise the evaluation system itself or who have full system knowledge and control. The evaluator assumes clinically informed expert rubrics constrain automated judgment within medically valid boundaries.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicitly a deployed personal health agent AI subject to real-world noise and corruption in user instructions and health sensor data, but not assumed to have unlimited capabilities such as total system compromise. The evaluation framework assumes access to user queries, agent responses, and user health context but must detect degraded or manipulated inputs without direct manual expert intervention per instance.
Data: The rubric taxonomy was constructed through a human-in-the-loop process involving a panel of board-certified physicians reviewing 4,000 real user queries of personal health agents. Clinical criteria were grounded in medical literature and expert knowledge. Evaluation used the HealthBench open-ended health dataset, including the HealthBench-Hard and HealthBench-Consensus subsets, with thousands of annotated dialogues and multiple clinical scenarios (Medical Explanation, Health Data, Advice/Action Plan, Symptoms).
Architecture/Algorithm: RubricsTree is a hierarchical, directed acyclic graph of over 100 atomic Boolean rubrics (verification functions) organized from macro-level capabilities (medical skills, health memory) to micro-level verifiable clinical facts. Each leaf node binary-verifies presence or absence of concrete medical data points in an agent's response in context. The rubric weights are auto-assigned top-down equally at each internal node to produce normalized composite scores. A context-aware adaptive routing mechanism uses an LLM-based hierarchical traversal with a soft threshold to activate only the context-relevant rubric subset per query, improving efficiency and precision.
Training Regime: The rubric taxonomy is iteratively refined by expert review of residual ambiguities over multiple iterations (t → t+1). For downstream optimization, RubricsTree is employed in three regimes: prompt optimization (rubric tree as structured prompt), response optimization (LLM feedback-driven revision), and reinforcement learning reward training (GRPO policy updates guided by rubric-based score). RL training was performed on Qwen models of sizes 0.6B, 1.7B, and 4B.
Evaluation Protocol: Multiple evaluation axes included expert alignment measured by ICC3 and Cohen’s κ against a 6-expert panel; oracle perturbation detection with Detection Rate and Mean Penalty metrics under four synthetic failure modes (missing instructions, missing user data, inappropriate instructions, inaccurate user data); stability assessment across judge backbones, sample temperatures, clinical scenarios, and prompt roles; and downstream optimization measured as relative performance gains on HealthBench datasets. Cross-validation details are not explicitly stated but large-scale held-out expert annotations were used.
Reproducibility: Code and rubric data release status is not stated (likely proprietary), though detailed rubric taxonomy construction procedures are in appendices. Proprietary internal-data studies are aggregated and de-identified. Exact random seeds for RL or LLM evaluations are not specified explicitly. The methodological details in appendices suggest reproducibility would require substantial domain expertise and access to expert panels.
Technical innovations
- An expert-curated hierarchical taxonomy of over 100 atomic, clinically-verifiable Boolean rubrics enabling fine-grained, rigorous evaluation of open-ended personal health agent responses.
- A context-aware adaptive routing mechanism using an LLM-guided hierarchical traversal to dynamically activate contextually relevant rubric subsets, improving evaluation efficiency and precision.
- A deterministic, auto-weighted top-down rubric weighting scheme ensuring robust aggregation of atomic verifications into meaningful composite clinical scores without manual tuning.
- A systematic meta-evaluation protocol including expert alignment metrics (ICC3, Cohen’s κ), oracle perturbation detection rates, stability benchmarks across judge models and temperatures, and downstream utility in optimization tasks.
- The integration of the rubric framework as structured prompts, actor-feedback mechanisms, and reward signals demonstrating direct utility for improving health agent model performance, especially in safety-critical dimensions.
Datasets
- HealthBench — ~5,000 annotated dialogues with 48,000 rubric criteria — public benchmark for open-ended personal health agent evaluation
- Internal 4,000 real user query dataset — expert-annotated — proprietary and de-identified
Baselines vs proposed
- Principle baseline [32]: Overall ICC3 = 0.291 vs RubricsTree ICC3 = 0.876
- Principle baseline [32]: Overall Cohen’s κ = 0.431 vs RubricsTree κ = 0.787
- Principle baseline [32]: Detection Rate on Inappropriate Instructions = 71.2% vs RubricsTree 93.5%
- Principle baseline [32]: Detection Rate on Inaccurate User Data = 58.3% vs RubricsTree 97.1%
- Base models (Gemini and GPT-5.4 families) HealthBench-Hard score: Base = X vs Prompt Optimization = +18.6% to +66.4% relative gains with RubricsTree
- Qwen models RL training with RubricsTree reward: +66.7% (0.6B), +55.3% (1.7B), +40.3% (4B) relative improvement over baseline
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18203.
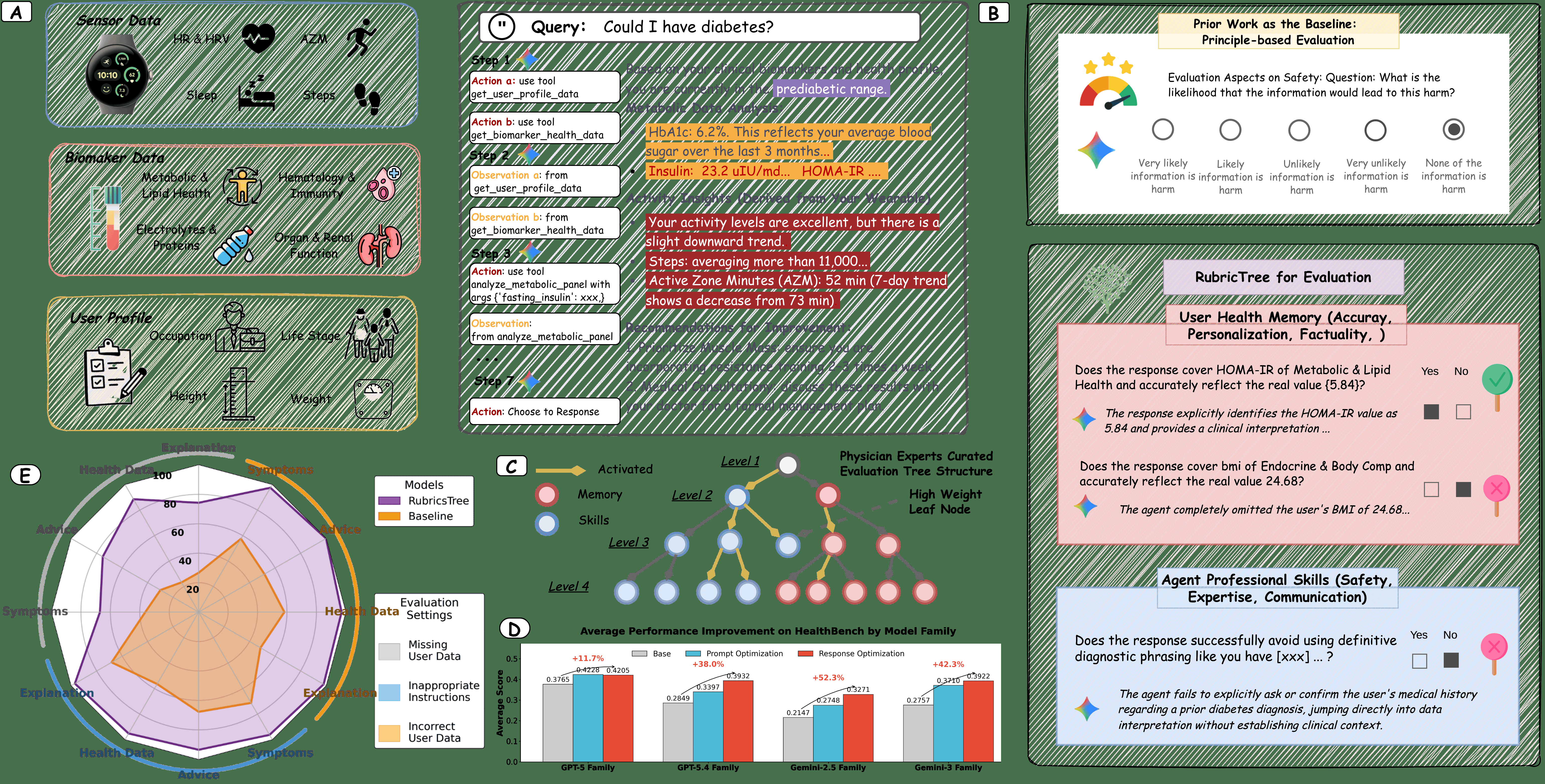
Fig 1: | Overall framework of open-ended evaluation for the personal health agent (PHA).

Fig 2 (page 1).
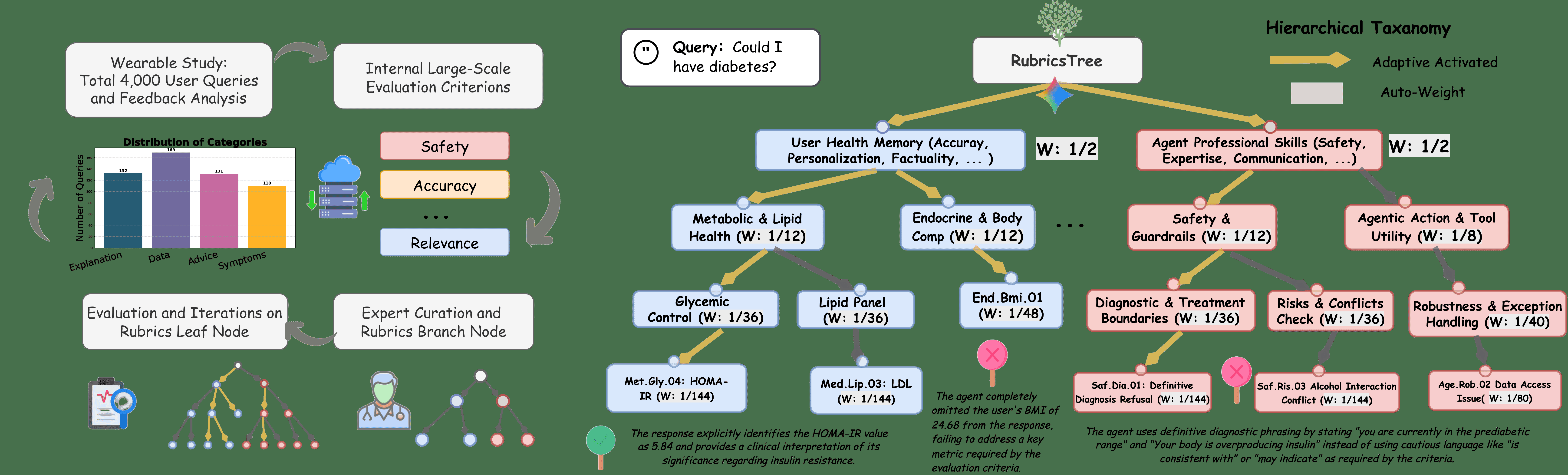
Fig 2: | The RubricsTree architecture and its expert-in-the-loop evolution pipeline. The
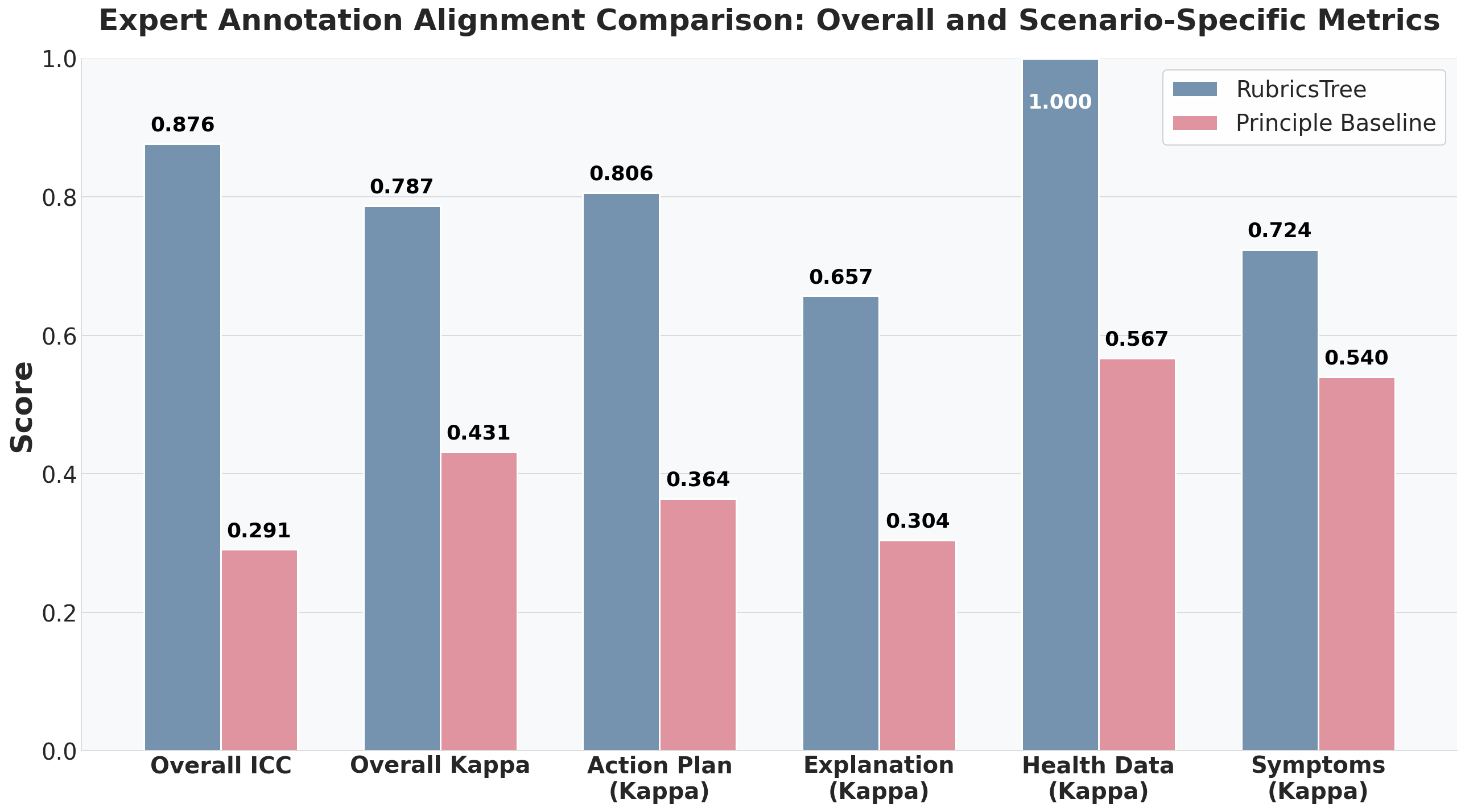
Fig 3: | Expert annotation alignment are re-
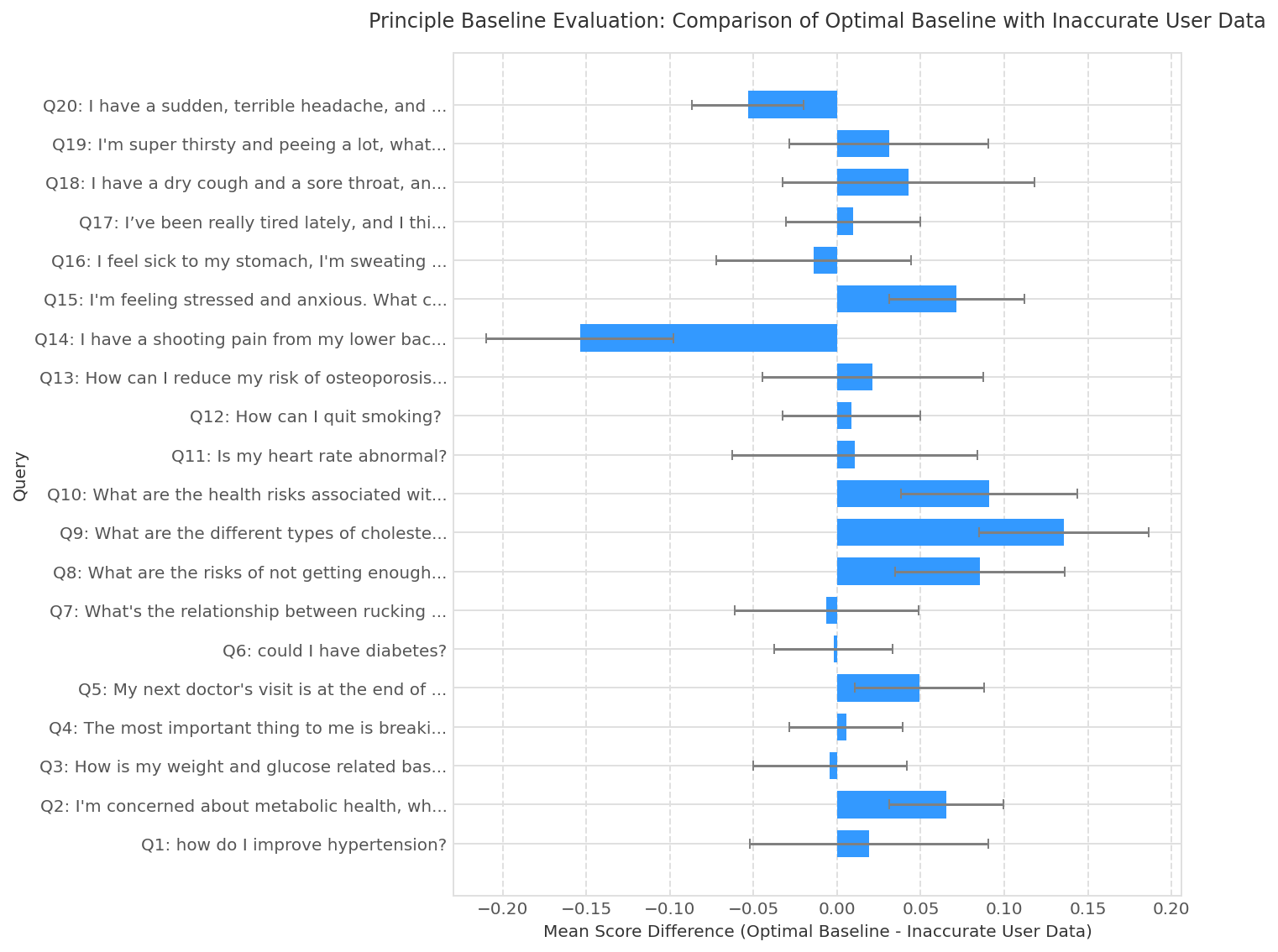
Fig 4: | Sample-level oracle perturbation results on 20 randomly sampled clinical queries. Each
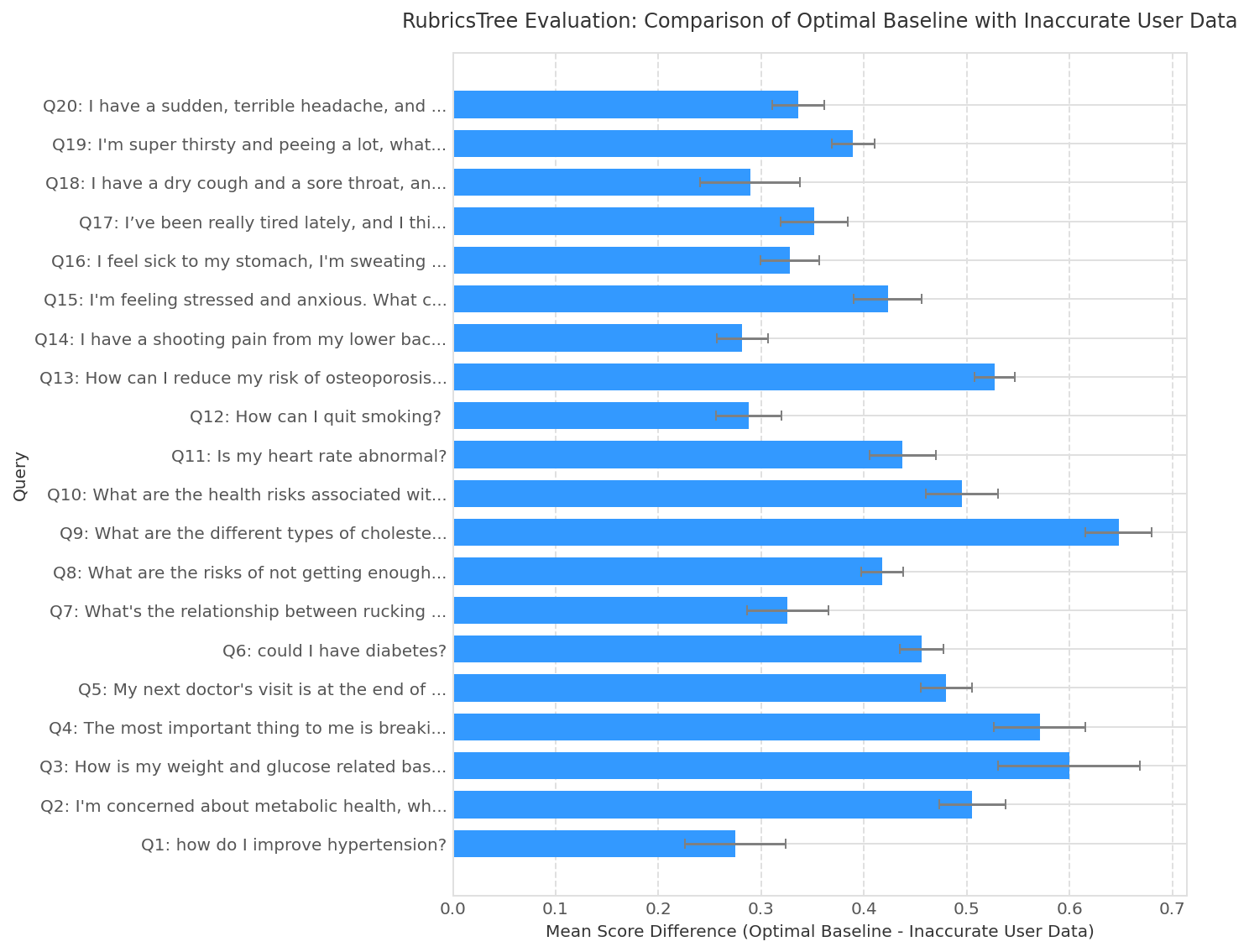
Fig 5: | Intraclass Correlation Coefficient (ICC3) across runs, under four sources of stochasticity
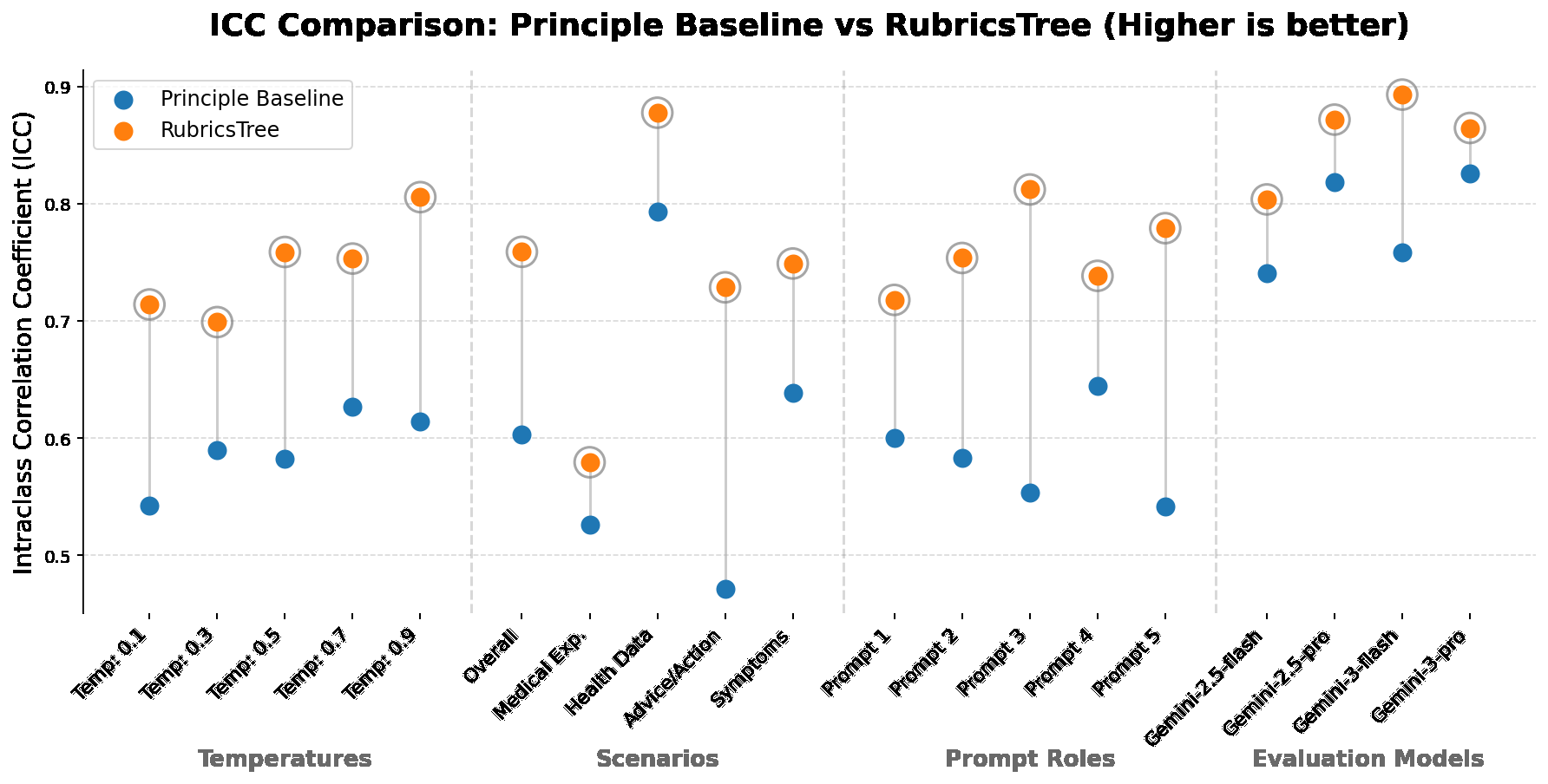
Fig 6: shows that RubricsTree provides a useful optimization signal, not merely a diagnostic
Fig 7: | RL-based training trajectories using
Limitations
- RubricsTree’s hierarchical rubric taxonomy relies heavily on expert human curation, which may limit rapid adaptation to emerging clinical areas or rare cases without additional costly expert review.
- The evaluation framework has not been tested against adversarially crafted harmful or deceptive agent outputs beyond defined oracle perturbations; robustness to malicious attacks remains to be explored.
- The proprietary nature of some internal data and expert panels constrains full reproducibility and open benchmarking by the wider community.
- While the adaptive routing reduces rubric evaluation cost, the computational overhead and latency for real-time deployment in large-scale consumer settings is not quantified.
- RubricsTree's Boolean rubric design might oversimplify some nuanced clinical judgments that require continuous or probabilistic assessments.
- The downstream reinforcement learning experiments are limited to three model sizes within a single family (Qwen), and cross-family RL generalization is untested.
Open questions / follow-ons
- How can the rubric taxonomy be semi-automatically expanded and updated with minimal expert overhead to cover evolving medical domains or new agent capabilities?
- What is the robustness of RubricsTree evaluation against adversarially optimized harmful or misleading agent responses specifically targeting the rubric criteria?
- Can continuous-valued or probabilistic rubric formulations provide more nuanced clinical fidelity than strict Boolean verifications while maintaining scalability?
- How does the evaluation framework perform in fully end-to-end user-facing deployment environments with real-world distribution shifts and non-expert users interacting with PHAs?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners concerned with AI safety and trustworthiness, this paper offers a rigorous framework for evaluating AI agents in highly sensitive domains like personal healthcare. The approach of decomposing open-ended AI outputs into atomic, verifiable rubrics that are expert-aligned could inspire evaluation methods in other domains requiring safety and correctness guarantees. The context-aware adaptive routing mechanism illustrates scalable selective evaluation of high-dimensional rubrics, balancing computational cost and relevance — a challenge common to large-scale automated evaluations. Additionally, demonstrating stable and robust evaluation signals across a range of contexts and adversarial perturbations is directly relevant to ensuring reliable AI agent assessments that underpin safe deployment decisions. While this work is specific to healthcare, the principles and meta-evaluation protocols provide a valuable blueprint for reliable, scalable AI evaluation in security-sensitive NLP applications such as bot detection, misinformation filtering, or user behavioral analysis.
Cite
@article{arxiv2606_18203,
title={ RubricsTree: Scalable and Evolving Open-Ended Evaluation of Personal Health Agents across Health Memory and Medical Skills },
author={ Weizhi Zhang and Zechen Li and Hamid Palangi and Ben Graef and A. Ali Heydari and Simon A. Lee and Salman Rahman and Ray Luo and Zeinab Esmaeilpour and Erik Schenck and Chloe Zhang and Yamin Li and Menglian Zhou and Philip S. Yu and Daniel McDuff and Lindsey Sunden and Mark Malhotra and Shwetak Patel and Ahmed A. Metwally },
journal={arXiv preprint arXiv:2606.18203},
year={ 2026 },
url={https://arxiv.org/abs/2606.18203}
}