
ReAge3D: Re-Aging 3D Faces with View Consistency
Source: arXiv:2606.18156 · Published 2026-06-16 · By Libing Zeng, Li Ma, Mingming He, Ning Yu, Paul Debevec, Nima Khademi Kalantari
TL;DR
This paper addresses the challenging problem of realistic and controllable 3D face re-aging, which modifies the apparent age of a 3D face model while preserving identity and multi-view consistency. Existing 3D editing techniques produce noticeable inconsistencies across views leading to over-smoothed and unnatural age-related details. To overcome this, the authors introduce DiffReaging, a 2D diffusion-based face re-aging model trained on synthetically generated image pairs to produce high-fidelity, identity-preserving age transformations. To extend this 2D model to 3D, they propose a center-out editing propagation strategy: starting from a frontal re-aged pivot view, they warp this view to neighboring views and apply a novel Masked-DiffReaging process to inpaint missing regions while injecting known pixel content at every denoising step, ensuring cohesive multi-view consistency. The resulting consistent 2D views supervise the optimization of a 3D face representation (implemented with 3D Gaussian Splatting).
Key findings
- DiffReaging reduces age prediction error to as low as 2.3 years on target ages from 10 to 80, outperforming FRAN (as low as 3.9) and FADING (down to 7.0) on FFHQ-derived test sets (Table 1).
- Identity similarity scores (measured via face recognition embeddings) improved to 0.684±0.184 with DiffReaging versus 0.675 for FRAN and 0.555 for FADING, indicating stronger identity preservation.
- Center-out multi-view propagation significantly improves view consistency; ablation shows independent multi-view editing increases detail blurring due to inconsistent age features (Fig. 11).
- Masked-DiffReaging, injecting warped known pixels at each diffusion step, enables coherent inpainting of occluded regions, reducing artifacts compared to naive approaches (Fig. 3).
- The iterative optimization of 3D Gaussian Splatting model with multi-view consistent supervision improves both 3D model age detail fidelity and optical flow quality (Fig. 12).
- DiffReaging fine-tuning on 16,000 synthetic image pairs from 2,000 FFHQ identities across 8 ages yields strong age control and identity preservation.
- Compared to state-of-the-art 2D methods (FADING, FRAN, InstructPix2Pix), the diffusion-based DiffReaging model produces smoother, more accurate age progression and regression effects.
- The pipeline generalizes across multiple facial expressions and identities with smooth, continuous age transitions from 20 to 80 years (Fig. 1).
Threat model
The adversary is assumed to want to manipulate or generate 3D facial models with realistic age appearances while preserving identity. The attacker's capability is limited to image or 3D model input modification; they cannot access or corrupt the internal weights or training data of the DiffReaging diffusion model, nor the ground truth multi-view images. The method assumes the adversary cannot produce perfectly consistent multi-view aged faces without the proposed propagation strategy, making manual or naive edits detectable by inconsistency artifacts.
Methodology — deep read
The threat model assumes the adversary attempts to generate or tamper with 3D facial models with plausible age appearance. The method focuses on preserving identity and subtle age-related details (e.g., wrinkles) consistently across views, preventing over-smoothing due to multi-view inconsistencies. The adversary cannot manipulate internal latent states of the diffusion model or exploit ground truth multi-view images.
Data was synthetically created by applying the SAM GAN-based age-conditioned face image generator to 2,000 identities from FFHQ, producing 8 re-aged images per identity spanning ages 10 to 80. Training pairs are formed by randomly selecting two age variants per identity, using one as source and the other blended in the face region (via BiSeNetV2 masks) as target. This yields roughly 16,000 training pairs. No direct use of original FFHQ images occurs during training.
Architecture builds upon InstructPix2Pix, a latent diffusion model pre-trained for general image editing. The model is fine-tuned to output a denoised latent corresponding to the target age image, conditioning on the input image and the text prompt 'Photo of a {target age} years old person.' Loss is the standard diffusion L2 noise prediction loss. This forms the DiffReaging 2D re-aging module.
For 3D multi-view consistency, a center-out progressive strategy is used. First, the frontal pivot view is re-aged with DiffReaging. Then, optical flow is computed between views based on the current 3D estimate. The re-aged pivot is backward warped to neighbors, generating incomplete warped views with confidence masks from forward-backward flow consistency. Masked-DiffReaging injects these warped pixels at each diffusion step using a mask, reconstructing missing regions coherently. This process propagates outward layer by layer to all views, blending information from multiple neighbors to avoid overlapping inconsistent reconstructions.
The consistent multi-view re-aged images supervise the update of the 3D face representation, implemented as 3D Gaussian Splatting (3DGS). The 3D model is optimized using a combined L1 and SSIM loss between rendered images of the representation and the corresponding multi-view re-aged images. The center-out re-aging is repeated every 400 iterations of the 2000-step 3D optimization, progressively refining the 3D model and the flow estimates.
Training DiffReaging requires about 3 days on four NVIDIA A100 GPUs at 1024x1024 resolution with batch size 4. 3D optimization runs on a single NVIDIA A5000. Evaluation uses standard face recognition and age estimation models on unseen FFHQ images, with extensive visual comparisons and ablations (e.g., independent view edits versus center-out). The authors provide latent diffusion weights fine-tuned from InstructPix2Pix but the complete 3D optimization framework and data are not publicly released.
An example end-to-end: from a 3D face model rendered at multiple poses, the frontal view is re-aged by DiffReaging; this re-aged image is warped via optical flow to a neighboring view, generating holes for occluded pixels; Masked-DiffReaging inpaints the missing regions by injecting known warped pixels each denoising step; the newly generated neighboring view is used along with the pivot to update the 3D Gaussian splatting parameters; the process repeats expanding to more views and refining the model iteratively until a fully consistent 3D re-aged mesh is obtained.
Technical innovations
- DiffReaging: a diffusion-based 2D face re-aging model fine-tuned on synthetic paired data enabling precise age control and strong identity preservation.
- Masked-DiffReaging: a novel inpainting method integrating warped partial views as hard constraints injected at every diffusion step to ensure pixel-level multi-view consistency.
- Center-out re-aging propagation strategy: progressively re-ages neighboring views from a pivot, blending multiple warped images to avoid inconsistent overlapping edits.
- Joint iterative optimization of a 3D Gaussian Splatting face model supervised by multi-view consistent re-aged images, improving both flow quality and age detail fidelity.
Datasets
- Synthetic Re-Aged Faces Dataset — ~16,000 image pairs — generated from 2,000 FFHQ identities using SAM GAN-based re-aging with age targets 10-80 years
Baselines vs proposed
- FADING: age error = 7.0 to 17.6 across ages vs DiffReaging: 2.3 to 6.6 (lower better) (Table 1)
- FRAN: age error = 3.9 to 13.3 across ages vs DiffReaging: 2.3 to 6.6 (Table 1)
- FADING: identity similarity = 0.555 ± 0.232 vs DiffReaging: 0.684 ± 0.184 (higher better)
- InstructPix2Pix: identity similarity = 0.604 ± 0.248 vs DiffReaging: 0.684 ± 0.184
- Multi-view independent editing: visually causes blurred age details vs Center-out re-aging: sharper, consistent age features (Fig. 11)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18156.

Fig 1: Given a 3D face model, represented here using 3D Gaussian splatting, our proposed method enables precise age manipulation with
Fig 2: Overview of Our 3D Face Re-Aging Framework. We first train a diffusion-based re-aging model, DiffReaging, on a synthetic dataset.
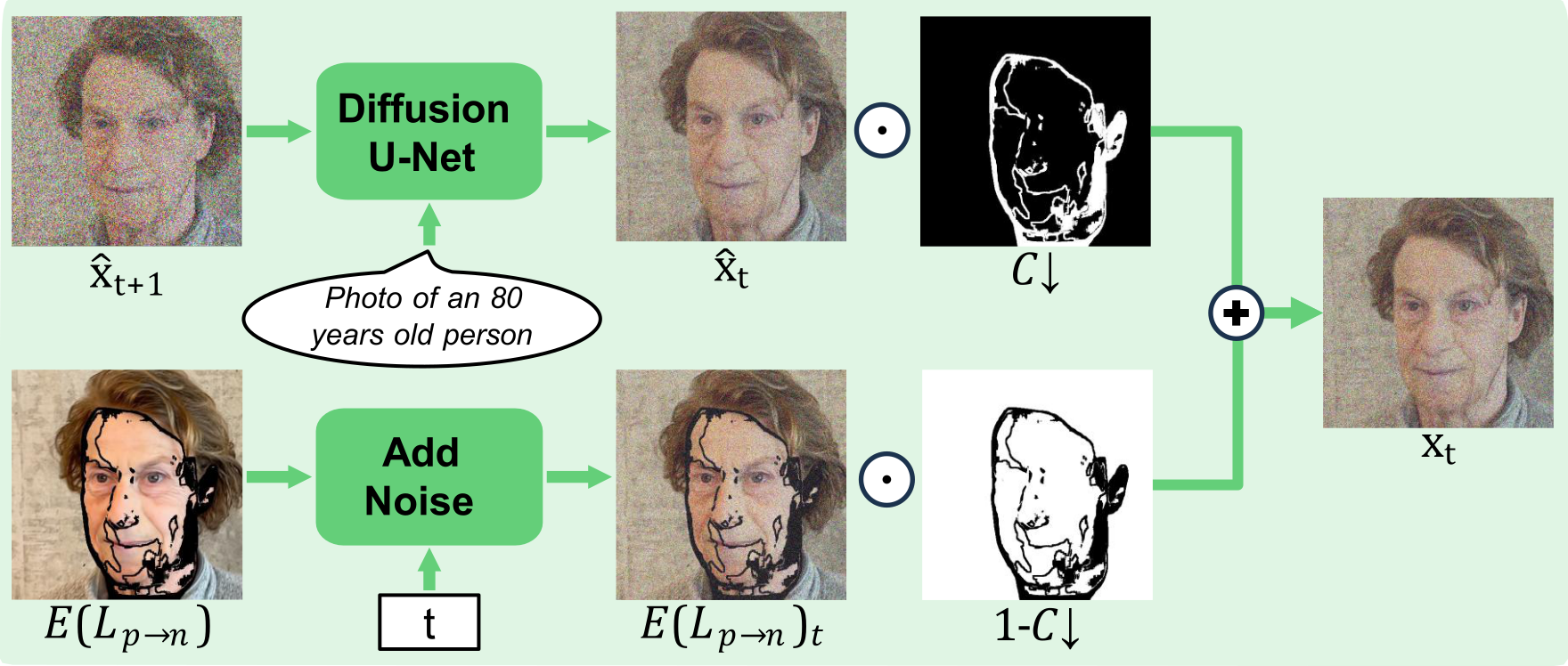
Fig 3: Masked-DiffReaging. Given a warped re-aged image with
Fig 4: Center-Out Re-Aging. Progressive reconstruction of multi-
Fig 5: Here, we show comparisons against FRAN. FRAN exhibits

Fig 6: Compared to FADING, our re-aging diffusion model consistently produces realistic age transformations while preserving the

Fig 7: We show comparisons against several methods. The baselines IGS2GS [VH24], GE [CCZ∗24], and DGE [CLV24], all based

Fig 8: We present a comparison with 2D re-aging of Age-
Limitations
- Synthetic training data derived from GAN-based SAM model which imperfectly preserves identity, potentially limiting real-world generalization.
- No public code or full dataset released yet, hindering reproducibility and wider adoption verification.
- Evaluations focus on FFHQ-derived data; performance on in-the-wild noisy or low-resolution images untested.
- Optical flow estimation depends on intermediate 3D model quality, introducing possible errors especially in occlusions.
- The method re-ages only face region; other age-related features (hair, clothing) are out of scope and left for practical effects.
- Computationally expensive due to diffusion-based inference and iterative 3D optimization; real-time applications unlikely.
Open questions / follow-ons
- Can the approach be extended to handle full head attributes beyond the face, such as hair aging or accessory changes?
- How robust is the method to noisy, low-resolution, or uncalibrated input 3D scans or meshes encountered in the wild?
- Can similar multi-view consistent editing strategies be adapted for other subtle non-age facial attributes like emotions or skin conditions?
- What are the limits of age interpolation and extrapolation beyond the training age range, and can domain adaptation improve these?
Why it matters for bot defense
Bot-defense practitioners focused on CAPTCHA can draw insights from this work's approach to enforcing fine-grained, multi-view consistency in subtle appearance transformations. For CAPTCHA systems employing 3D face or avatar verification, methods like Masked-DiffReaging offer techniques to simultaneously preserve identity and apply controlled attribute changes without introducing detectable inconsistencies. Detecting bot-generated facial age manipulations may require sensitive evaluation of subtle, view-consistent texture details, which naive 2D GAN or diffusion edits often fail to achieve. This paper highlights the importance of propagation strategies and per-step confidence masking to reduce artifact and maintain coherence, principles potentially extendable to robust bot or deepfake detection pipelines that monitor multi-view or video consistency rather than single-frame artifact cues. However, practical integration would need addressing computational cost and responsiveness.
Cite
@article{arxiv2606_18156,
title={ ReAge3D: Re-Aging 3D Faces with View Consistency },
author={ Libing Zeng and Li Ma and Mingming He and Ning Yu and Paul Debevec and Nima Khademi Kalantari },
journal={arXiv preprint arXiv:2606.18156},
year={ 2026 },
url={https://arxiv.org/abs/2606.18156}
}