
MOCHI: Motion Enhancement of Collaborative Human-object Interactions
Source: arXiv:2606.18243 · Published 2026-06-16 · By Jiye Lee, Yonghun Choi, Jungdam Won
TL;DR
This paper addresses the complex challenge of capturing and refining motion data for collaborative multi-human object interactions (MHOI), where both human-human and human-object dynamics coexist. Existing motion capture techniques often produce noisy data with artifacts such as hand-object contact misalignment, jittery motions, incomplete finger articulation, and temporal inconsistencies due to occlusions and complexity in multi-person scenarios. MOCHI is proposed as a two-stage motion enhancement framework aimed at improving the plausibility and quality of MHOI data. The first stage optimizes physically plausible hand grasps from noisy body inputs by constructing bounded search spaces and minimizing combined losses to ensure stable, natural hand-object interactions. The second stage refines full-body motion using a diffusion-based single-person motion prior, enhanced via optimization conditioned on the synthesized hand-object contacts and multi-person interaction semantics to maintain coherence across participants and preserve original interaction intent.
Experimental results on diverse datasets—including captured noisy sequences and generative model outputs—demonstrate MOCHI's ability to significantly reduce common artifacts and generate physically and semantically consistent motions. The method shows robustness to varying participant counts and different interaction types. MOCHI also enables applications such as keyframe-based MHOI creation and data augmentation with varied object geometries, addressing key scalability issues inherent in current MHOI data acquisition techniques.
Key findings
- MOCHI effectively reduces hand-object contact misalignment and temporal jitter in noisy MHOI data captured by markerless systems or synthesized generatively.
- The hand pose optimization uses a bounded cylindrical search space around averaged wrist positions, improving grasp plausibility compared to using single-frame optimization.
- The diffusion-based full-body motion refinement conditioned on synthesized hand-object interactions removes unrealistic full-body artifacts while preserving interaction semantics.
- Contact phase identification uses an 8cm wrist-object distance threshold with sliding window smoothing, successfully segmenting pre-contact, contact, and post-contact phases for multiple hands.
- Random perturbations up to 15 degrees on wrist orientation during hand pose optimization improve exploration and grasp quality in local minima avoidance.
- MOCHI shows robustness across scenarios ranging from two-person cooperative lifts to sequential handover interactions, enabling variable participant numbers.
- Applying MOCHI as a data augmentation tool by varying object geometries while preserving interaction intent is demonstrated, potentially enabling scalable MHOI datasets.
- The approach outperforms baseline noisy inputs on qualitative metrics comparing with CORE4D capture data and synthetic data evaluated in multiple qualitative ablations.
Methodology — deep read
The core methodology consists of a two-stage pipeline for enhancing noisy multi-human object interaction (MHOI) motion sequences.
Threat Model & Assumptions: The adversary scenario is not applicable here since the paper targets enhancement of imperfect MHOI capture data, not adversarial robustness. It assumes noisy input motion sequences with artifacts such as jitter, contact misalignment, incomplete finger motion, and missing finger articulation details. The method aims to restore physically plausible and semantically consistent motions.
Data: The input is an MHOI motion sequence I = {M_i, M_j, O, G_obj}, where M_i,j are per-person full-body pose sequences (including joint positions or rotations), O is the object pose trajectory over time, and G_obj is the object mesh geometry. The sequences are noisy and may have missing finger motion. The output is an enhanced sequence with refined body motions, object poses, and synthesized finger motions represented using SMPL-X hand parameters (wrist translation/rotation + finger joint angles).
Architecture / Algorithm:
Stage 1: Hand-Object Interaction Generation
- Identify contact phases using wrist-to-object distance threshold (8cm), smoothed by sliding window (6 frames at 30 FPS).
- Within contact phases, optimize a single stable grasp hand pose for each hand by batching contact frames and constructing a cylindrical bounded search space around averaged wrist and elbow locations in object space.
- The optimization minimizes a composite loss: force closure stability (L_fc), object interaction losses to keep hand near object and avoid penetration (L_obj), hand pose plausibility loss encouraging natural hand shapes and no self-penetration (L_hp), and a novel regularization L_reg enforcing the hand pose remains within the cylindrical bounding volume.
- Initialization is done by aligning wrist orientations to the cylinder axis with random perturbations (±15 degrees) to augment the search.
- After optimization, select the best solution with the lowest loss.
- Generate full hand motion sequences for pre-contact and post-contact transitions using a conditional diffusion model trained on hand-object interaction priors, conditioned on wrist-object proximity features and the optimized grasp pose.
Stage 2: Full-Body Motion Refinement
- Use a diffusion-based single-person motion prior pretrained on large-scale single-person motion datasets.
- Formulate motion refinement as a diffusion noise optimization problem that updates the latent noise such that the denoised motion aligns with the synthesized hand grasps and interaction semantics.
- Introduce interaction-aware objectives to encode human-object and human-human interaction information within the single-person prior framework.
- Employ DDIM sampling with gradient normalization and small noise perturbations during optimization for stability and exploration.
- Training Regime:
- The hand pose optimization is iterative and performed per batch of contact frames for each hand, augmented multiple times for robustness.
- The diffusion models (both for hand motion and full-body motion) are pretrained separately on single-person datasets or interaction datasets, but details such as exact epochs, batch sizes, seeds, or hardware are not exhaustively specified in the truncated text.
- Evaluation Protocol:
- Qualitative evaluation on MHOI datasets including CORE4D, synthetic data from generative models, and manipulated noisy inputs.
- Ablation studies on loss components, contact phase determination, and diffusion-based refinement.
- Robustness analysis across scenarios with varying number of participants and diverse interaction types.
- No specific standard quantitative metric values or statistical evaluations clearly reported in the excerpt.
- Reproducibility:
- Source code and project page URL are provided (https://jiyewise.github.io/projects/MOCHI/), though the dataset and pretrained models availability is not explicitly stated.
Example End-to-End: For a captured MHOI sequence involving two people lifting a table, the system:
- Preprocesses the object trajectory to smooth abrupt motions.
- Identifies contact phases via wrist-object distances.
- Constructs cylindrical bounds around average wrist-elbow positions for each hand.
- Optimizes stable grasp poses minimizing combined force closure, proximity, hand plausibility and boundedness losses across batch of contact frames.
- Uses the optimized grasp pose as target for a diffusion model to generate smooth finger motion transitions.
- Runs diffusion noise optimization refining each person's full body motion to be consistent with hand-object contacts and maintain interaction semantics.
- Outputs enhanced motion with natural finger articulation, stable contact, and coherent multi-person body poses.
Technical innovations
- Decomposition of MHOI motion enhancement into two stages: stable hand-object interaction optimization followed by full-body motion refinement via diffusion noise optimization.
- Introduction of a cylindrical bounded search space around averaged wrist-elbow positions to constrain hand pose optimization from noisy inputs, preventing overfitting to single-frame noise.
- Encoding multi-person interaction semantics within a single-person diffusion-based motion prior via novel interaction-aware optimization objectives.
- Use of conditional diffusion models trained on hand-object interaction priors to generate natural finger motion transitions bridging pre-contact and post-contact phases.
Datasets
- CORE4D — unspecified size — captured multi-human object interaction dataset using hybrid inertial-optical system
- Additional synthetic multi-human interaction data generated by existing motion generative models (unnamed) used for evaluation
Baselines vs proposed
- Noisy CORE4D input: visually observable artifacts including contact misalignment and temporal jitter; MOCHI produces physically plausible interaction sequences with natural finger articulation (qualitative comparison, Figures 6-8).
- CORE4D-HMR (parametric model reconstruction): exhibits severe finger and contact artifacts; MOCHI improves grasp stability and body motion coherence (qualitative evaluation).
- MOCHI hand grasp optimization reduces average force closure loss compared to single-frame optimization baselines (numbers not explicitly provided).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18243.

Fig 1: Our method enhances noisy multi-human object interaction (MHOI) data (soft pink and skyblue) into clean MHOI data (pink and blue), automatically
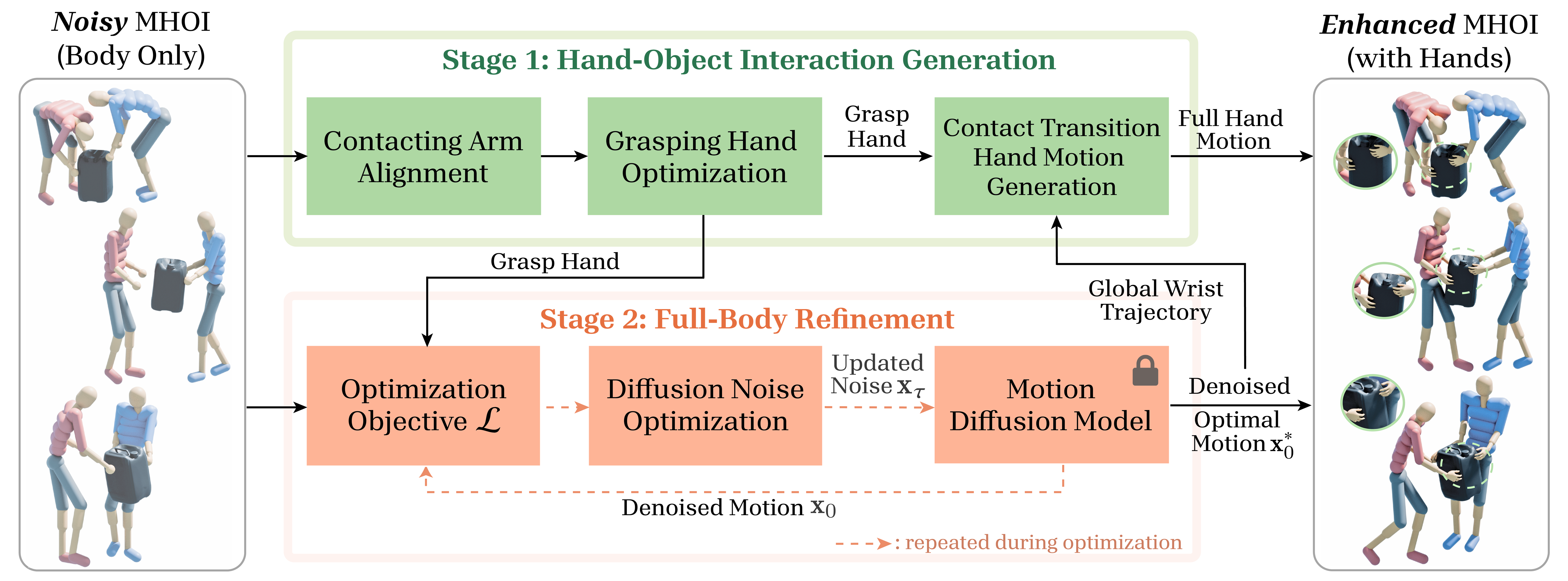
Fig 2: System Overview.
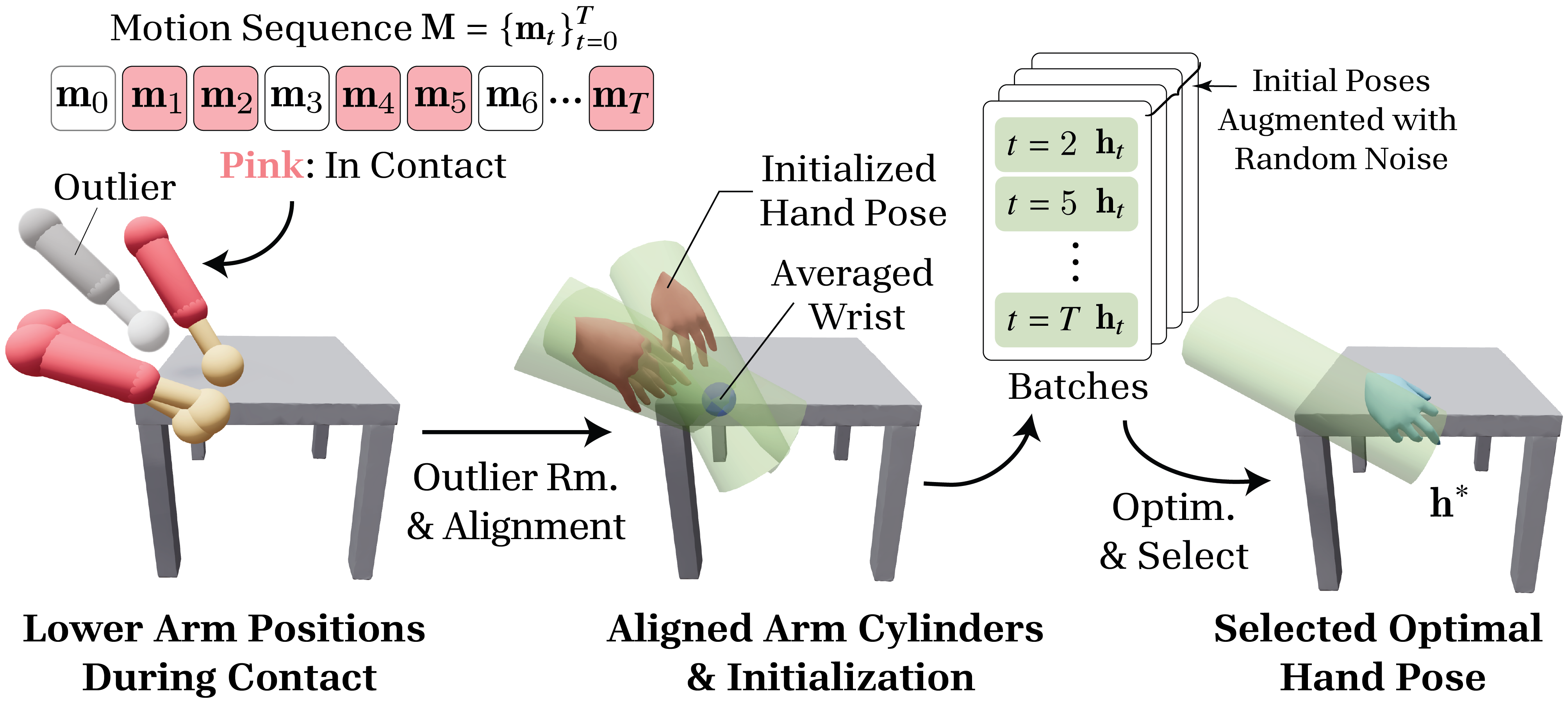
Fig 3: An overview of grasping hand pose generation. (Left) Lower arms in
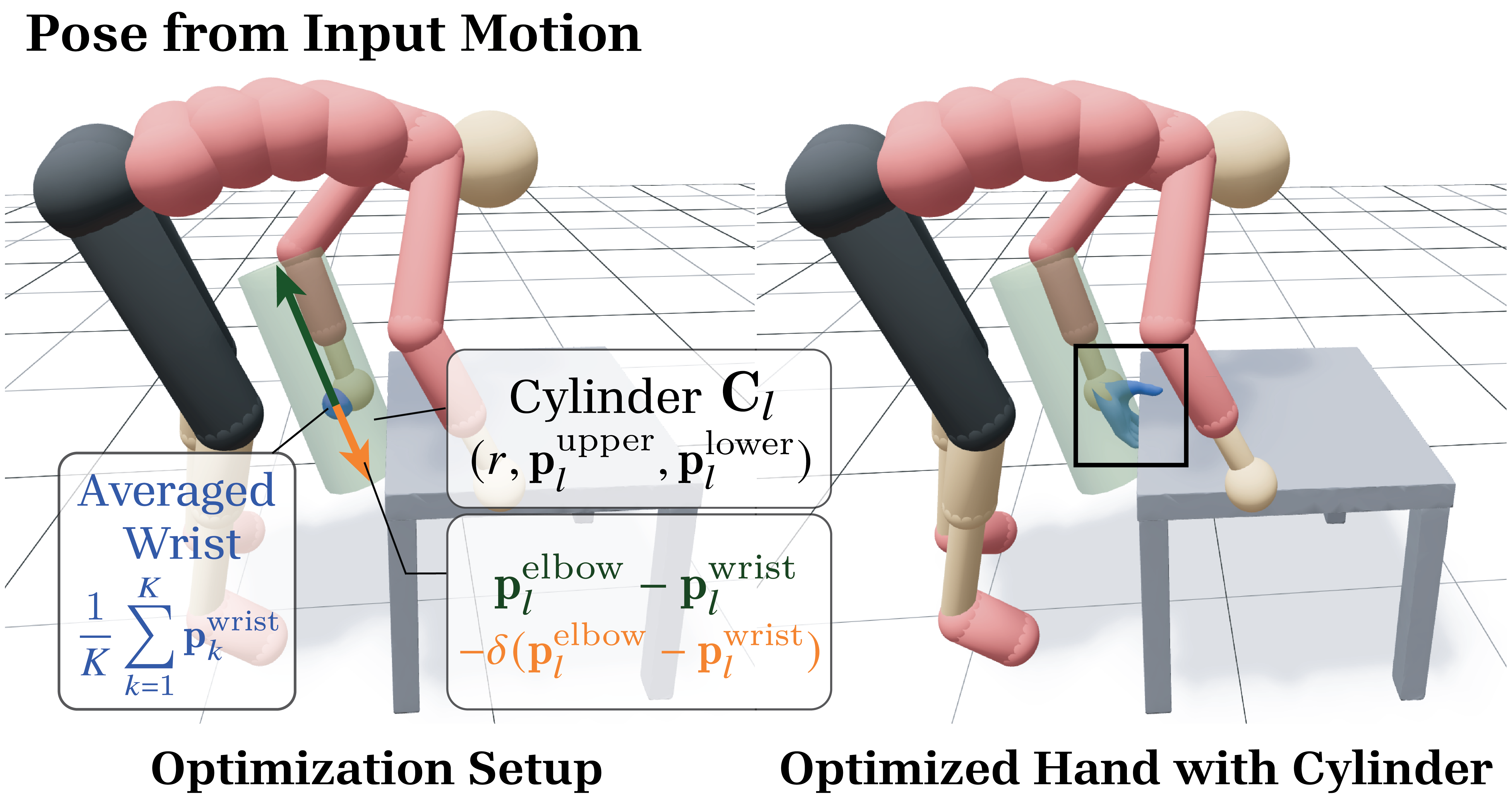
Fig 4: An example of a cylindrical bound for grabbing a table. (Left) The
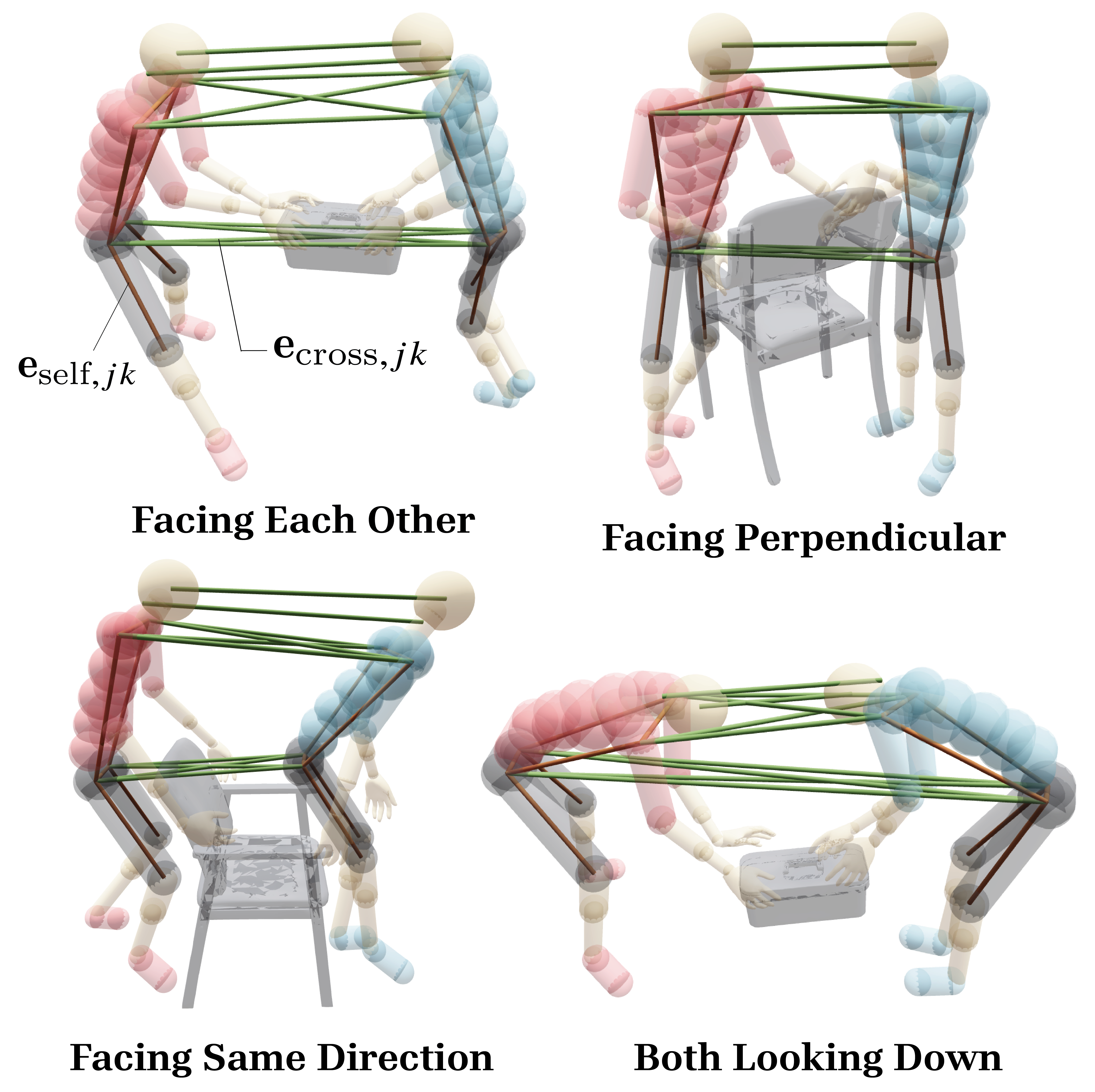
Fig 5: Visualization of the interaction graph showing self-edges eself,𝑗𝑘
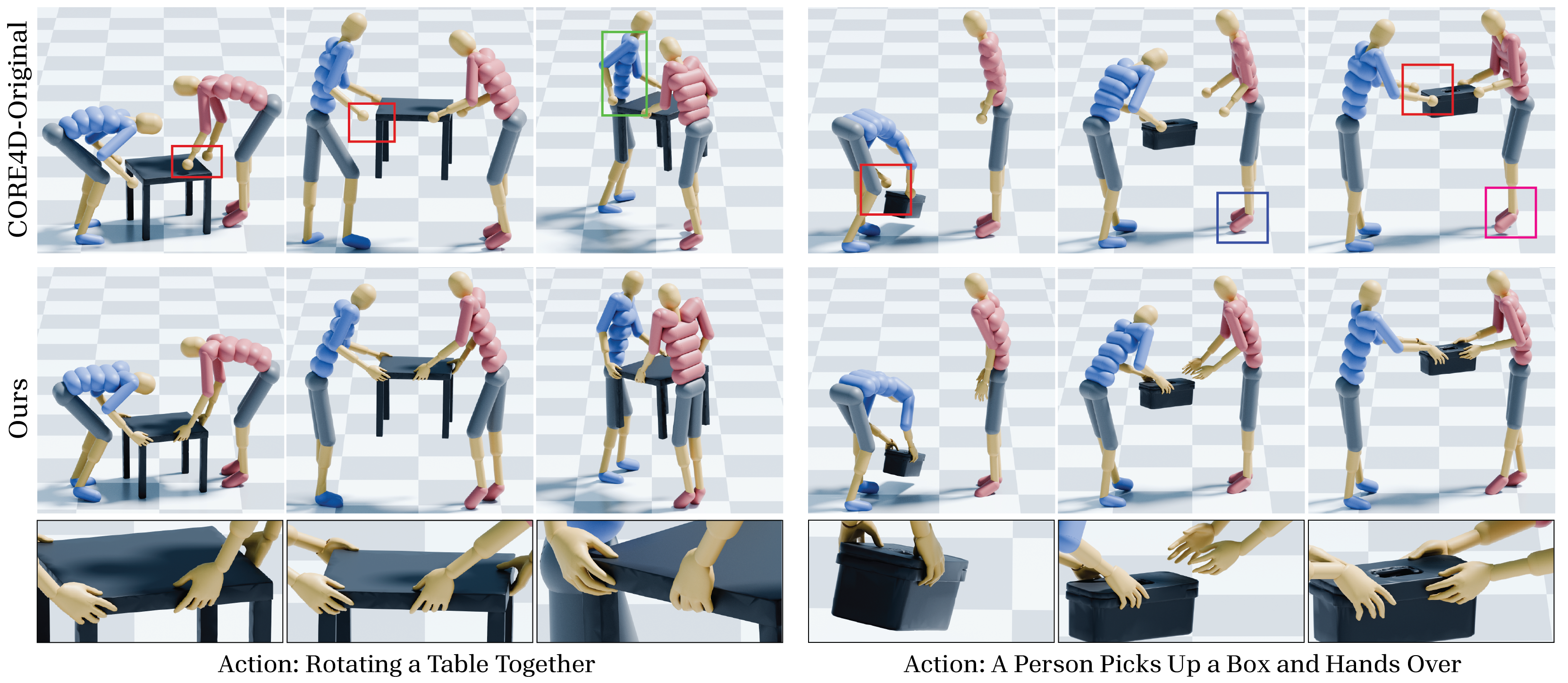
Fig 6: Qualitative comparison: CORE4D-Original and Ours.
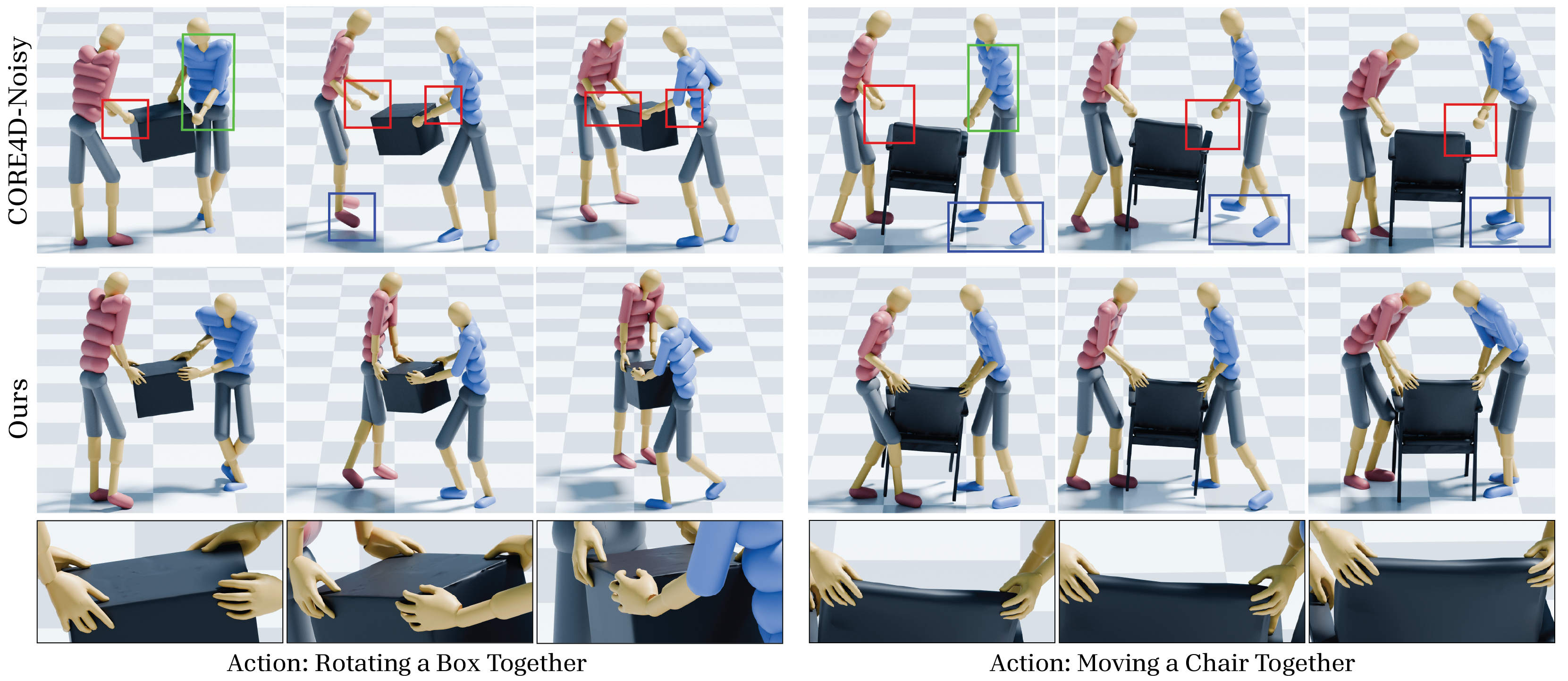
Fig 7: Qualitative comparison: CORE4D-Noisy and Ours.

Fig 8: Qualitative comparison among CORE4D-HMR and Ours. The first
Limitations
- No comprehensive quantitative metrics or standard benchmarks reported for objective evaluation; most results are qualitative.
- Assumes availability of object geometry mesh and roughly accurate body pose inputs; accuracy may degrade if these are compromised.
- Diffusion model for full-body refinement relies on single-person motion priors and may not fully capture complex multi-person interaction dynamics.
- Current framework demonstrated mostly on two-person scenarios; although claimed extensible, scalability to many participants not empirically validated.
- Computational cost and runtime performance details are not disclosed, limiting practical applicability understanding.
- No adversarial robustness or adversarial noise evaluation despite typical noise and tracking errors in capture data.
Open questions / follow-ons
- How well does MOCHI generalize to highly dynamic MHOI scenarios with rapid object manipulations or large numbers of participants?
- Can dedicated multi-person MHOI motion priors improve full-body motion refinement beyond the current single-person prior approach?
- What are the quantitative impacts of different noisy input characteristics (e.g., markerless capture vs monocular RGB) on MOCHI performance?
- How might incorporating physics-based constraints or reinforcement learning improve physical plausibility and interaction realism further?
Why it matters for bot defense
Although this paper focuses on enhancing multi-human object interaction capture data, bot-defense and CAPTCHA practitioners can draw useful insights regarding complex temporal interaction modeling and noise refinement in multi-agent scenarios. MOCHI's approach to decomposing noisy interaction data into physically plausible hand grasps and then refining full-body motions with diffusion priors could inspire advanced behavioral anomaly detection algorithms that must handle noisy or partial multi-agent input data. Furthermore, the use of interaction-aware diffusion models suggests promising directions for synthesizing or verifying realistic collaborative human motions, which might be used in authentication challenges relying on human-like multi-agent interaction dynamics. However, direct application to CAPTCHA generation or bot detection would require adaptation, since MOCHI targets motion capture data enhancement rather than adversarial robustness or bot behavior analysis per se. Still, the underlying principles of refining noisy multi-participant input sequences while preserving interaction semantics can inform bot-defense techniques that analyze human motion and coordination in virtual or physical environments.
Cite
@article{arxiv2606_18243,
title={ MOCHI: Motion Enhancement of Collaborative Human-object Interactions },
author={ Jiye Lee and Yonghun Choi and Jungdam Won },
journal={arXiv preprint arXiv:2606.18243},
year={ 2026 },
url={https://arxiv.org/abs/2606.18243}
}