
IsabeLLM: Automated Theorem Proving Applied to Formally Verifying Consensus
Source: arXiv:2606.18098 · Published 2026-06-16 · By Elliot Jones, William Knottenbelt
TL;DR
This paper addresses the challenge of formally verifying blockchain consensus protocols, specifically Bitcoin's Proof-of-Work, using automated theorem proving augmented by large language models (LLMs). Formal verification traditionally requires expert effort and is limited outside safety-critical domains, but blockchain's exposure to adversarial attacks causing substantial financial losses motivates automation to lower this barrier. The authors improve upon their prior tool, IsabeLLM, which integrates the Isabelle proof assistant with LLMs, by introducing Retrieval-Augmented Generation (RAG) that injects domain-specific proof context, error tracing of iterative proof attempts, and counterexample generation to flag logical falsehoods. Compatibility updates to Isabelle 2025 and Sledgehammer improve efficiency, while the underlying LLM model is upgraded to DeepSeek R1T2 Chimera to balance reasoning capability and speed.
The enhanced IsabeLLM-RAG system demonstrates significantly improved automated proof success rates over its predecessor. On 16 complex Bitcoin consensus lemmas, the Chimera model variant achieves a 94.4% success rate with fewer iterations needed per lemma, removing prior manual interventions such as direct Sledgehammer calls. Alternative models like NVIDIA Nemotron also outperform the baseline DeepSeek R1, showing that architectural choices impact efficiency. The verification effort itself is non-trivial: the move from binary to n-ary tree models in consensus formalization more than doubles the logical proof complexity, necessitating robust tooling. Overall, the work advances LLM-assisted formal verification towards practical, automated proof generation for security-critical blockchain protocols, a domain with sparse prior AI-for-verification research.
Key findings
- IsabeLLM-RAG with DeepSeek R1T2 Chimera achieves a 94.4% average success rate proving 16 non-trivial Bitcoin consensus lemmas, improving over original IsabeLLM's results.
- The Chimera model reduces average LLM iterations per successful proof to 1.06 from 1.31 in DeepSeek R1, speeding convergence.
- NVIDIA Nemotron 3 Super attained 87.5% success rate despite a smaller model size (120B params total vs 671B for DeepSeek R1).
- The GPT-OSS-120B model performed worst, with 67.5% success and requiring maximum iteration limits frequently.
- Incorporating a RAG database of 22 prior proofs improves domain-specific context and proof accuracy for the LLM.
- Nitpick counterexample integration identifies logically false proof steps, preventing wasteful exploration by LLM.
- Error trace functionality preserves context between LLM proof attempts, preventing reversion of prior corrections and reducing infinite loops.
- Upgrading to Isabelle 2025 and Sledgehammer speeds proof automation and eliminates need for manual intervention documented in prior work.
Threat model
The threat model assumes an adversarial environment within the blockchain consensus context where the majority of compute power is honest, excluding majority attacks and network partitions beyond the model's assumptions. The adversary targets blockchain consensus correctness but does not compromise the verification process itself; i.e., no adversarial manipulation or poisoning of the automated theorem proving pipeline or LLM inputs is considered.
Methodology — deep read
Threat Model & Assumptions: The adversary is modeled indirectly as part of the consensus theorem assumptions—majority honesty in computing power and synchronisation of views across nodes, excluding majority attacks or network partitions beyond the model. The goal is to certify the consensus protocol correctness under these assumptions rather than resist active attacks on the verification process itself.
Data: The system operates over formally specified Isabelle theory files encapsulating definitions, lemmas, and proofs of an n-ary tree generalisation of the Bitcoin Proof-of-Work consensus. The RAG database consists of 22 prior proofs from a simpler binary tree consensus model formalised in Isabelle. These prior proofs are extracted, vectorised into embeddings via SentenceTransformers all-MiniLM-L6-v2, and stored in a ChromaDB instance for similarity retrieval.
Architecture / Algorithm: IsabeLLM acts as an interface orchestrating between Isabelle, Sledgehammer, and an LLM API. It extracts lemmas to prove, sends contexts plus similar prior proof snippets retrieved by RAG to the LLM (DeepSeek R1T2 Chimera or others), obtains candidate proof code, reinserts into Isabelle, and retries builds. Failed proofs trigger automated calls to Sledgehammer for subgoals, and the system maintains an error trace to contextualize iterative interactions with the LLM. Nitpick’s counterexample generator is leveraged to detect invalid intermediate claims, providing corrective feedback to the LLM as negative examples. Prompt templates encode theory context, lemmas, proof state, errors, and retrieved similar lemmas.
Training Regime: While the LLMs used are pretrained and not trained by the authors, model selection involved evaluation of Chimera, Nemotron, and GPT-OSS with varied architectures, parameter counts, and context windows. The Chimera model was selected for its better inference throughput and stability despite being slightly less optimized for pure reasoning compared to the original R1 model.
Evaluation Protocol: Each lemma (16 of varying complexity) was attempted 10 times with up to 3 LLM iterations per attempt, counting empty API failures separately. Metrics included success rate per lemma, average LLM iterations per success, and whether manual interventions were needed. The proof complexity of lemmas was quantified by Lines of Proof (LoP). The evaluation system ran on commodity hardware (AMD Ryzen 7 with 16GB RAM). Cross-model comparisons and ablations of retrieval, error tracing, and counterexample features were conducted implicitly by comparing IsabeLLM to IsabeLLM-RAG.
Reproducibility: The authors provide source code, Isabelle theory files, and use public LLM APIs (DeepSeek). However, the ChromaDB RAG database depends on internal extraction of prior formal proofs from literature. The dataset and pretrained LLMs are publicly accessible but are proprietary models. Exact randomness seeds or full evaluation artifacts are not explicitly stated.
Example End-to-End: For the lemma subtree_height, IsabeLLM-RAG sends the lemma with context and the top 3 similar proofs retrieved from RAG to the Chimera model via API. The model generates a candidate inductive proof by cases. The proof file is injected and built in Isabelle 2025. Failed proof steps trigger Sledgehammer for intermediate goals, and any remaining errors are returned to the LLM with the error trace and counterexamples (if applicable). The cycle repeats until the lemma is verified or iteration limit reached. This example highlights the collaborative, iterative LLM plus ATP (Automated Theorem Prover) workflow enabled by IsabeLLM-RAG.
Technical innovations
- Integration of Retrieval-Augmented Generation (RAG) uniquely applied to formal verification in Isabelle, providing domain-specific proof context to the LLM.
- Implementation of Nitpick counterexample generation to detect and communicate logically false proof attempts to the LLM, improving correctness.
- An error trace mechanism capturing all modifications between LLM calls to preserve context and avoid overwriting prior successful proof edits.
- Consolidation and upgrade of Isabelle tooling including compatibility with Isabelle 2025 and enhanced Sledgehammer integration for faster automated proof solving.
- Empirical evaluation comparing large MoE and AoE transformer LLM architectures (DeepSeek R1 vs Chimera) under a formal verification workflow.
Datasets
- 22 prior formal proofs from the binary tree consensus model [36] — curated extraction from Isabelle theory files — used as RAG corpus.
Baselines vs proposed
- IsabeLLM (DeepSeek R1): average lemma success rate not explicitly quantified, but lower than 94.4% of IsabeLLM-RAG Chimera; needed manual Sledgehammer interventions.
- IsabeLLM-RAG (DeepSeek R1T2 Chimera): success rate = 94.4%, average LLM iterations per success = 1.06.
- IsabeLLM-RAG (NVIDIA Nemotron 3 Super): success rate = 87.5%, average iterations not specified but better than baseline.
- IsabeLLM-RAG (OpenAI GPT-OSS-120B): success rate = 67.5%, with frequent iteration/timeouts.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18098.
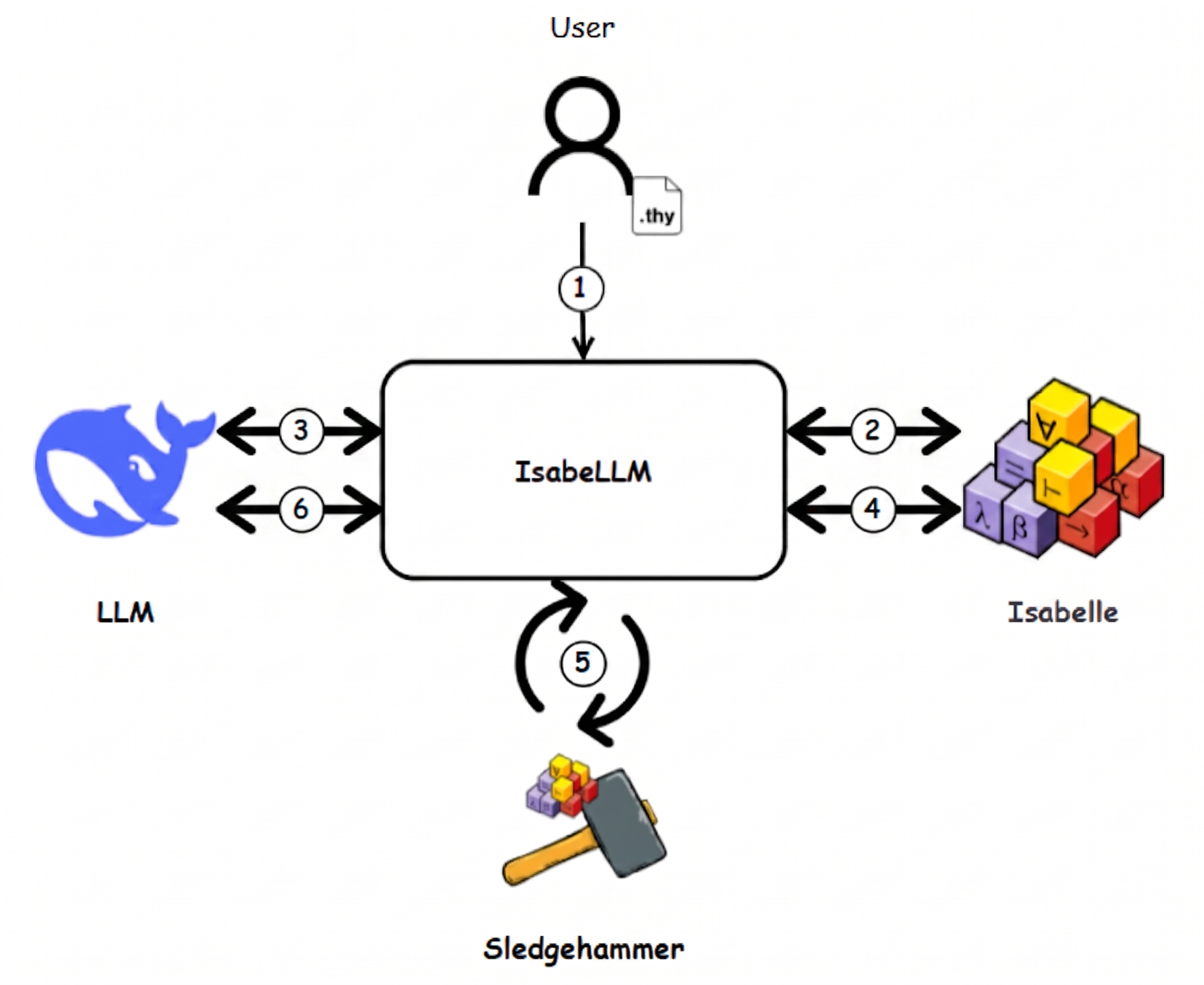
Fig 1: IsabeLLM Architecture.

Fig 2: IsabeLLM example workflow.
Fig 3: Nitpick Example

Fig 4 (page 10).

Fig 5 (page 10).
Fig 6 (page 10).

Fig 7 (page 11).
Limitations
- Evaluation limited to a single consensus protocol (Bitcoin PoW) formalised at moderate complexity; generalization to more complex protocols is untested.
- Adversarial robustness of the automated prover itself is not analyzed; e.g., resilience to LLM hallucination in adversarial settings is unknown.
- External dependence on pretrained LLMs and their API latency could hinder real-time or large-scale verification runs.
- The underlying assumption of majority honest miners and constant difficulty simplifies real-world blockchain dynamics.
- RAG database size is relatively small (22 proofs), potentially limiting diversity and scope of retrieved contexts.
- Limited reporting on exact randomness, reproducibility seeds, and scalability to larger formal verification projects.
Open questions / follow-ons
- Can the IsabeLLM-RAG approach generalize effectively to other consensus protocols or smart contract formal verification requiring richer domain adaptation?
- What are the limits of LLM scalability in formal verification for far more complex blockchain systems or layered protocols?
- How can adversarial robustness be incorporated to detect and mitigate malicious LLM hallucination in security-critical proofs?
- Can joint training or fine-tuning of LLMs on larger formal proof corpora improve performance beyond retrieval-augmented prompting?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, this research demonstrates the potential of coupling large language models with classical logic engines (theorem provers) to automate high-assurance reasoning tasks in adversarial contexts such as blockchain systems. It highlights benefits of retrieval-augmented prompting and iterative feedback loops to improve correctness and stability, techniques that could inspire more robust bot detection decision-making or automated vulnerability analysis. However, the work is focused on formal verification, not human interaction verification, so direct application to CAPTCHA design may be limited. That said, the approach to integrate domain-specific context retrieval and error feedback to improve LLM reliability is a transferable concept relevant for secure bot-defense pipelines relying on language understanding or automated reasoning.
Cite
@article{arxiv2606_18098,
title={ IsabeLLM: Automated Theorem Proving Applied to Formally Verifying Consensus },
author={ Elliot Jones and William Knottenbelt },
journal={arXiv preprint arXiv:2606.18098},
year={ 2026 },
url={https://arxiv.org/abs/2606.18098}
}