
EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
Source: arXiv:2606.18239 · Published 2026-06-16 · By Ning Gao, Jinliang Zheng, Xing Gao, Haoxiang Ma, Hanqing Wang, Yukai Wang et al.
TL;DR
EBench is a comprehensive simulation benchmark designed to diagnose generalist mobile manipulation policies more deeply than traditional single scalar success rates. It includes 26 diverse tasks spanning mobile pick-and-place, long-horizon multi-stage, and dexterous-and-precise manipulation, annotated along five capability dimensions and evaluated across four distribution-shifted generalization axes. The benchmark integrates teleoperated data for dexterous tasks and motion-planned trajectories for mobile and long sequences, enabling evaluation across regimes with a unified action space for a dual-arm mobile robot. Evaluation of four state-of-the-art vision-language-action models (π0, π0.5, XVLA, InternVLA-A1) shows that even with similar overall success rates, models differ drastically in their capability profiles, highlighting strengths and weaknesses that single scalar metrics hide. Notably, π0.5 achieves the highest test success rate and retention, InternVLA-A1 excels on mobile manipulation but fails on dexterous tasks, and XVLA shows complementary atomic skill advantages. Beyond profiling, EBench quantifies generalization challenges from unseen backgrounds, objects, instructions, and their combinations, revealing robustness gaps. Finally, EBench uniquely surfaces the impact of large-scale pretraining across models, distinguishing itself from existing benchmarks where pretrained and from-scratch scores converge.
Key findings
- Four evaluated VLAs achieve similar overall test success rates between 24.4% and 29.5%, yet differ by up to 29 points on specific capability axes (operating mode gap for InternVLA-A1).
- π0.5 obtains the highest test success rate of 29.5% with the best train-test retention ratio (0.92 SR retention), indicating strong generalization.
- InternVLA-A1 leads on mobile manipulation tasks (34.7% test SR) but collapses on dexterous tasks (5.8% SR), showing the largest mobile-to-dexterous gap of 29 points.
- Precision tasks under 1 cm success rates are low (<14%), dominated by π0, while π0.5 leads on low-precision tasks (44.2% SR).
- Long-horizon tasks cause larger performance drops compared to short-horizon: InternVLA-A1 gets 29.1% on long vs XVLA drops to 13.5%.
- Generalization on unseen backgrounds and paraphrased instructions is relatively robust (27–35% SR), but swapping unseen object instances reduces success to 21–29%, and combining perturbations lowers it further to 18–23%.
- Pretraining boosts performance by 9–21 percentage points on EBench (e.g., π0.5 from 8.5% → 29.5%), while LIBERO and RoboTwin 2.0 benchmarks show little or no pretraining advantage.
- Per-atomic skill analysis reveals disjoint model strengths: e.g., XVLA excels at Push (73.8% SR) but scores near zero on Handover, Press, and Flip.
Threat model
The implicit threat model involves distributional shift between training and deployment conditions in generalist robot manipulation, including novel backgrounds, unseen object instances, and paraphrased instructions. No direct adversarial manipulation of the policy is assumed. The adversary's capability is modeled via controlled out-of-distribution scenarios rather than active attacks. Policies must robustly generalize without architectural or training changes to these shifts.
Methodology — deep read
Threat model & assumptions: The benchmark assumes a generalist embodied manipulation policy tested in simulation. The adversary is implicit as distributional shifts in scenes, objects, instructions, and backgrounds, simulating out-of-distribution generalization challenges rather than direct adversarial attacks.
Data: EBench provides a synthesized dataset totaling 91.4 hours, 6,600 episodes across 26 tasks, split into telemetry-based dexterous demonstrations (7 tasks, 400 episodes each) and motion-planned long-horizon and mobile episodes (19 tasks, 200 episodes each). Assets are drawn from GRUtopia, InternScenes, and Objaverse, ensuring scene and object diversity. Train and test splits are disjoint at the asset level.
Architecture/Algorithm: Four pretrained vision-language-action models are evaluated - π0 and π0.5 (flow-matching based multi-robot pretraining), XVLA (modular decoder decoupling perception and action), and InternVLA-A1 (visual representation plus hierarchical planning). Models output unified actions compatible with dual-arm mobile robots in a shared action space (6-DoF arms + gripper + 3D base velocity).
Training Regime: Models are fine-tuned on EBench training data for 200k steps using batch size 128, AdamW optimizer with cosine learning rate scheduling and warm-up, peak LR 1e-5. Evaluation is conducted at 25k, 50k, 100k, and 200k steps to analyze learning dynamics.
Evaluation Protocol: Metrics include binary success rate (SR) and a continuous task Score based on staged progress verified by evaluation primitives derived from simulation state (scene graphs, joint angles, object poses). Evaluation includes in-distribution validation, unseen object validation, and a held-out test set covering four generalization axes: unseen backgrounds, unseen objects, instruction paraphrases, and combined perturbations. Each model is evaluated across all 26 tasks without architectural modification. Each experiment reports mean and standard deviation over three runs.
Reproducibility: EBench code, datasets, and task splits are publicly released with a distributed evaluation runner using 8 consumer GPUs capable of completing full validation in about 30 minutes. Model checkpoints from evaluated baselines are publicly available.
Concrete example: In one dexterous insertion task requiring sub-centimeter precision, human teleoperation demonstrations produce fine-grained corrective trajectories recorded at 60Hz from multiple viewpoints and proprioceptive sensors. Models trained and evaluated on this task must output per-frame dual-arm 6-DoF poses with gripper actions at 60 Hz. Success is measured by achieving final insertion pose within 1cm tolerance, with intermediate stages gauged by joint angles and object pose constraints. π0 leads on these high-precision tasks with 13.8% SR, whereas others fall below 10%, revealing the difficulty of precise contact-rich manipulation.
Technical innovations
- Integration of diverse mobile, long-horizon, and dexterous manipulation tasks under a single evaluation protocol with unified action space and shared robot embodiment.
- Annotation of tasks along five interpretable capability axes and four controlled generalization axes enabling decomposable capability profiles beyond scalar success rates.
- Two-track data synthesis combining human teleoperation for dexterous tasks with key-frame pose plus motion planning (cuRobo) for mobile and long-horizon tasks to scale dataset while preserving feasibility.
- A composable metric library using scene-graph and joint-angle evaluation primitives assembled into staged progress graphs to produce consistent partial-progress and success scores across heterogeneous tasks.
- Controlled out-of-distribution evaluation with asset-disjoint partitioning at scene, object, and instruction levels precisely diagnosing generalization failures.
Datasets
- EBench Demonstrations: 91.4 hours, 6,600 episodes synthesized via human teleoperation and motion planning — open-sourced alongside benchmark
- GRUtopia and InternScenes scene assets — public research asset collections
- Objaverse object assets — large-scale 3D object dataset
Baselines vs proposed
- π0: Test SR = 24.4% ±0.9, Retention = 0.80 vs π0.5: Test SR = 29.5% ±0.3, Retention = 0.92
- XVLA: Test SR = 24.7% ±1.1 vs InternVLA-A1: Test SR = 27.6% ±1.6 (highest mobile SR but lowest dexterous SR)
- π0.5 pretrained: 29.5% test SR vs from-scratch: 8.5% test SR (+21.0 points)
- π0 pretrained: 24.4% test SR vs from-scratch: 11.2% test SR (+13.2 points)
- XVLA pretrained: 24.7% test SR vs from-scratch: 15.7% test SR (+9.0 points)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18239.

Fig 1: EBench is a simulation benchmark for generalist embodied manipulation that, within a

Fig 2: EBench end-to-end pipeline. Left: 26 tasks span pick-and-place, long-horizon, and

Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).
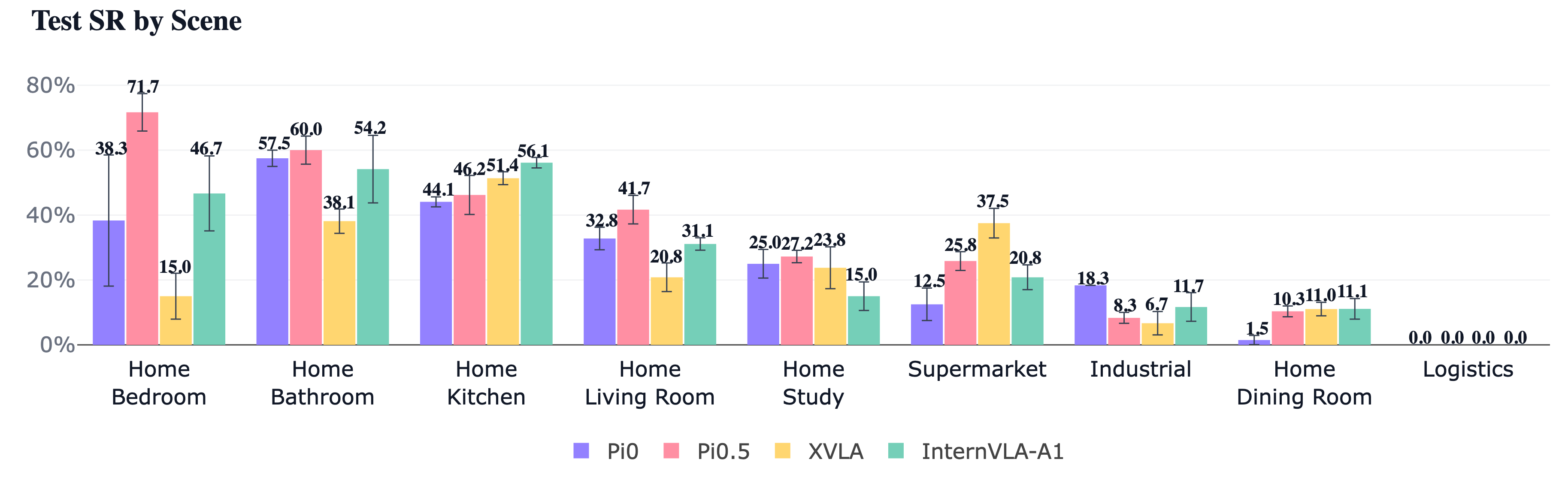
Fig 3: Capability breakdown on the five axes. The top row reports overall success rate and three
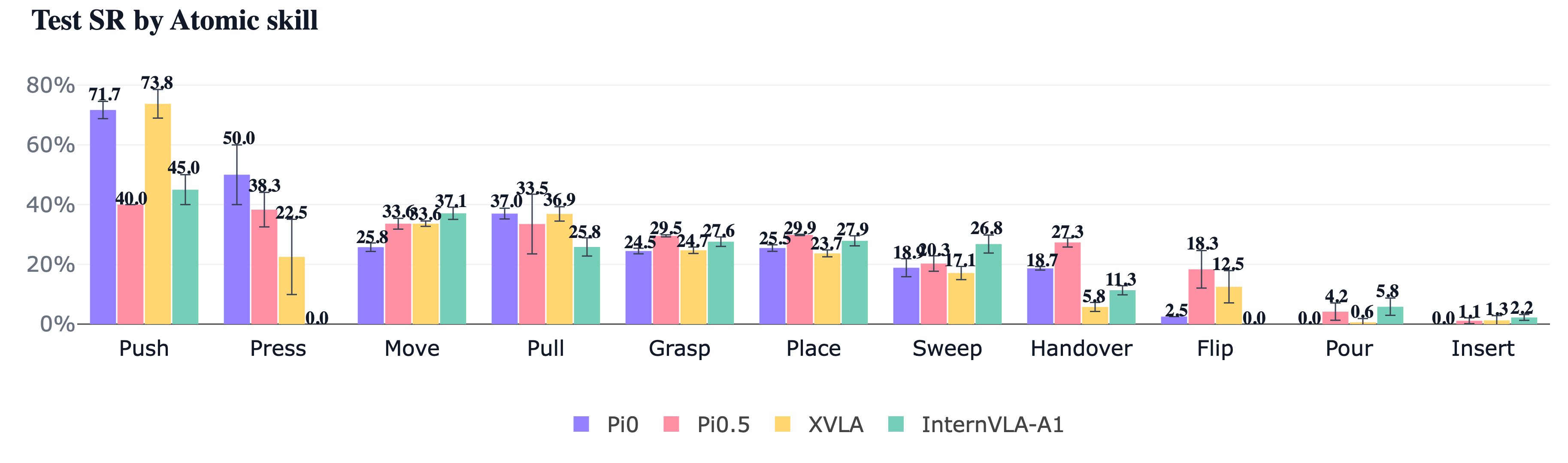
Fig 4: SR of baselines on Validation-Train and
Limitations
- Benchmark operates fully in simulation; no claim that simulation success maps directly to real-robot performance.
- Relatively small number of tasks (26) and sparse coverage of nine scene categories limits statistical power of scene-level analysis.
- Focuses on evaluation of pretrained models fine-tuned on EBench; lacks extensive testing of adversarial robustness or unexpected environmental perturbations.
- Does not include physical robot hardware tests; real-world sim-to-real transfer challenges remain unaddressed.
- Generalization tests control a limited set of distribution shifts (background, object, instruction paraphrase, mix) but may not capture compositional or adversarial OOD conditions.
Open questions / follow-ons
- How well do EBench simulation-based evaluations correlate with real-robot performance across the diverse task families?
- Can learned policies be improved to reduce the large mobile-to-dexterous performance gap demonstrated by InternVLA-A1?
- What architectural or training modifications enable more uniform capability coverage rather than disjoint skill dominance?
- How does EBench performance evolve with additional adversarial or more complex distributional shift scenarios beyond current axes?
Why it matters for bot defense
While EBench focuses on embodied mobile manipulation rather than bot detection or traditional CAPTCHA tasks, its detailed capability profiling and structured generalization diagnostics hold lessons for bot-defense systems. Bots interacting with complex environments or simulators may benefit from multi-axis behavioral diagnostics rather than single scalar success measures. EBench’s approach to decomposing performance by atomic skills and testing robustness to distinct distributional factors parallels challenges in detecting evasive, adaptive bots under diverse conditions. Practitioners designing CAPTCHA or bot-detection systems targeting embodied agents can use EBench’s framework to better understand failure modes caused by environmental and input perturbations, guiding development of defenses that recognize fine-grained behavioral cues instead of only aggregated metrics.
Cite
@article{arxiv2606_18239,
title={ EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies },
author={ Ning Gao and Jinliang Zheng and Xing Gao and Haoxiang Ma and Hanqing Wang and Yukai Wang and Jiantong Chen and Zanxin Chen and Shujie Zhang and Mingda Jia and Xuekun Jiang and Zihou Zhu and Xinyu Li and Shuai Wang and Hao Li and Wenzhe Cai and Yuqiang Yang and Xudong Xu and Zhaoyang Lyu and Yao Mu and Tai Wang and Jiangmiao Pang and Jia Zeng and Weinan Zhang and Chunhua Shen },
journal={arXiv preprint arXiv:2606.18239},
year={ 2026 },
url={https://arxiv.org/abs/2606.18239}
}