
DRFLOW: A Deep Research Benchmark for Personalized Workflow Prediction
Source: arXiv:2606.18191 · Published 2026-06-16 · By Md Tawkat Islam Khondaker, Raymond Li, Muhammad Abdul-Mageed, Laks V. S. Lakshmanan, Issam H. Laradji
TL;DR
This paper addresses a significant gap in deep research (DR) systems: focusing not just on generating reports or summaries, but on predicting personalized workflows—concrete sequences of actionable steps—from heterogeneous, scattered enterprise data sources. The authors introduce DRFLOW, the first benchmark specifically designed for personalized workflow prediction in deep research contexts. It contains 100 tasks across five domains, grounding 1,246 workflow steps in over 3,900 diverse company and user artifacts. The benchmark emphasizes retrieving relevant evidence, resolving conditionals, and producing structured, personalized workflow outputs rather than free-form text.
Along with the benchmark and an extensible task data generation pipeline, they propose seven detailed metrics—covering factual grounding, step recall and precision, structural ordering, condition resolution, and personalization quality—to evaluate workflow predictions. They also present DRFLOW-Agent (DRFA), a newly designed workflow-oriented LLM agent which plans research and action steps, performs adaptive retrieval, and outputs the personalized workflow. Experiments on multiple backbone language models show DRFA improves average F1 scores by up to 10% over baselines, especially on Condition Resolution and personalization metrics, but overall scores remain modest (F1 ~44–58%), highlighting this as a challenging and underexplored problem space.
Key findings
- DRFLOW comprises 100 tasks with 1,246 reference workflow steps grounded in more than 3,900 heterogeneous sources spanning company and personal contexts.
- DRFA outperforms a strong planning baseline DRBA by +10.02% absolute in average F1 score (57.93 vs 47.91) on the original task split using GPT-5.2 backbone.
- DRFA improves substantially on Condition Resolution metric (38.21 vs 20.19) and Personalized Comprehensiveness (56.54 vs 37.69) over DRBA baseline, showing better handling of conditional branches and personalization.
- Task difficulty increases in the mixed split with confounding evidence; DRFA's average F1 falls from 57.93 to 43.91, showing robustness challenges.
- Ablation studies reveal both gap finding and conditional action planning components of DRFA contribute significantly to performance, especially Condition Resolution.
- Evaluated backbones include GPT-5.2, Claude-Opus-4.5, Gemini-3.1-pro, and DeepSeek-v3.2, with consistent DRFA improvements over baselines.
- Factuality scores are relatively high but still limited (~85–95%), complicated by heterogeneous and distributed evidence.
- The benchmark provides a fine-grained breakdown of metrics useful for diagnosing workflow prediction quality including step correctness, ordering, and evidence grounding.
Threat model
n/a - The paper does not consider an active adversary or security threat model but focuses on evaluating AI agents’ ability to predict personalized workflows from noisy, heterogeneous enterprise data sources.
Methodology — deep read
The work focuses on agents predicting personalized workflows from enterprise heterogeneous data across a combination of company-level and user-specific evidence.
Threat model and assumptions: The adversary model is not explicitly discussed as this is not a security paper, but rather a challenge for AI agents interpreting complex scattered data, extracting relevant evidence, and resolving conditional branches to produce correct personalized sequences of action steps.
Data generation involves a 6-stage pipeline starting from domain and task seed generation (including synthetic deep research questions, company and user personas), followed by generic workflow composition encoding prerequisite and conditional relations, and then generating company-side supporting insights plus distractors embedded naturally into heterogeneous artifacts (PDFs, emails, DOCX files, chat logs). Next the generic workflow is personalized using user context, yielding personalized workflow steps and user-side supporting and distracting evidence similarly realized as artifacts. Finally, a more challenging mixed split is created by injecting additional confounding deep research questions and evidence into the evidence pool, simulating real-world complexity.
The structured workflows contain 100 tasks spanning 5 domains (B2B, B2C, Education, Healthcare, Legal) with 1,246 workflow steps total. Artifacts total 3,900+, mixing relevant insights and distractors posing needle-in-the-haystack retrieval challenges.
The DRFLOW-Agent (DRFA) architecture consists of four key components: (1) Research Planning decomposes the DR question into investigation areas for collecting generic company-level and personalized user-level evidence; (2) Action Planning translates investigation areas into concrete retrieval or analytic actions corresponding to tools like enterprise search, file browsing, internet search, chat logs; (3) Adaptive Action Planning analyzes evidence collected after each iteration to identify evidence gaps and unresolved conditional branches requiring further personalized evidence; (4) Workflow Generation integrates collected evidence to predict first a generic workflow then specializes it to a personalized workflow resolving conditional branches.
DRFA agents were instantiated with multiple backbone LLMs: GPT-5.2, Claude-Opus-4.5, Gemini-3.1-pro-preview, and DeepSeek-v3.2. Baseline comparison agents include a Basic agent without planning (ingesting all documents and predicting workflows end-to-end) and DRBench Agent (DRBA), a planning-based baseline from prior work.
Evaluation metrics cover seven facets: (1) Factuality verifies predicted step claims are supported by cited evidence; (2) Recall measures coverage of golden steps recovered; (3) Precision measures correctness of predicted steps; (4) F1 harmonic mean of recall/precision; (5) Condition Resolution evaluates correctness of resolving branching conditions from personalized evidence; (6) Topology measures ordering and structural consistency; (7) Personalized Comprehensiveness measures if operational and personalized details like names, dates, thresholds are preserved.
Experiments run on original 50-task split and more challenging mixed split with confounding evidence. Ablations study DRFA's planning components effect. All code and data generation pipeline are publicly released. Evaluation proceeded in containerized environments simulating enterprise systems.
A concrete example: Given a complex clinical workflow question and patient/user persona, DRFA plans investigations into company consent policies and patient language needs, retrieves evidence from multiple heterogeneous artifacts, iteratively plans actions to find missing condition resolving evidence (e.g., interpreter tiers), then generates a personalized step-by-step workflow grounded in multiple documents, such as "Assess language needs", "Use video remote interpreter", "Obtain consent signature" with conditional branches resolved based on patient context.
Technical innovations
- A novel benchmark (DRFLOW) for personalized deep research workflow prediction combining generic company procedures with user-specific context from heterogeneous, distributed data sources.
- A multi-stage synthetic data generation pipeline producing scalable, realistic tasks with grounded personalized workflows and embedded insights plus distractors in structured artifacts.
- Seven fine-grained metrics explicitly designed to evaluate workflow prediction beyond text generation: factual grounding, step recovery, condition resolution, structural order, and personalization.
- DRFLOW-Agent (DRFA), a workflow-oriented agent architecture integrating research planning, action planning, adaptive gap finding, conditional branch resolution, and workflow generation.
Datasets
- DRFLOW Benchmark — 100 tasks with 1,246 reference workflow steps over 3,900 heterogeneous artifacts — synthetic enterprise and user data (publicly released)
Baselines vs proposed
- Basic agent on original split: average F1 = 9.84 vs DRFA: 57.93 (GPT-5.2 backbone)
- DRBA baseline on original split: average F1 = 47.91 vs DRFA: 57.93 (GPT-5.2 backbone)
- DRFA improves Condition Resolution from 20.19 (DRBA) to 38.21 (original split average)
- On the mixed split, DRFA average F1 falls from 57.93 (original) to 43.91 but still outperforms DRBA (38.27)
- Ablation removing gap finding reduces DRFA average F1 from 56.12 to 50.35; removing conditional action planning reduces it to 51.77
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18191.

Fig 1: Comparison of deep research questions be-

Fig 2: Overview of the DRFLOW task and evaluation pipeline. Given a task context and heterogeneous task data,
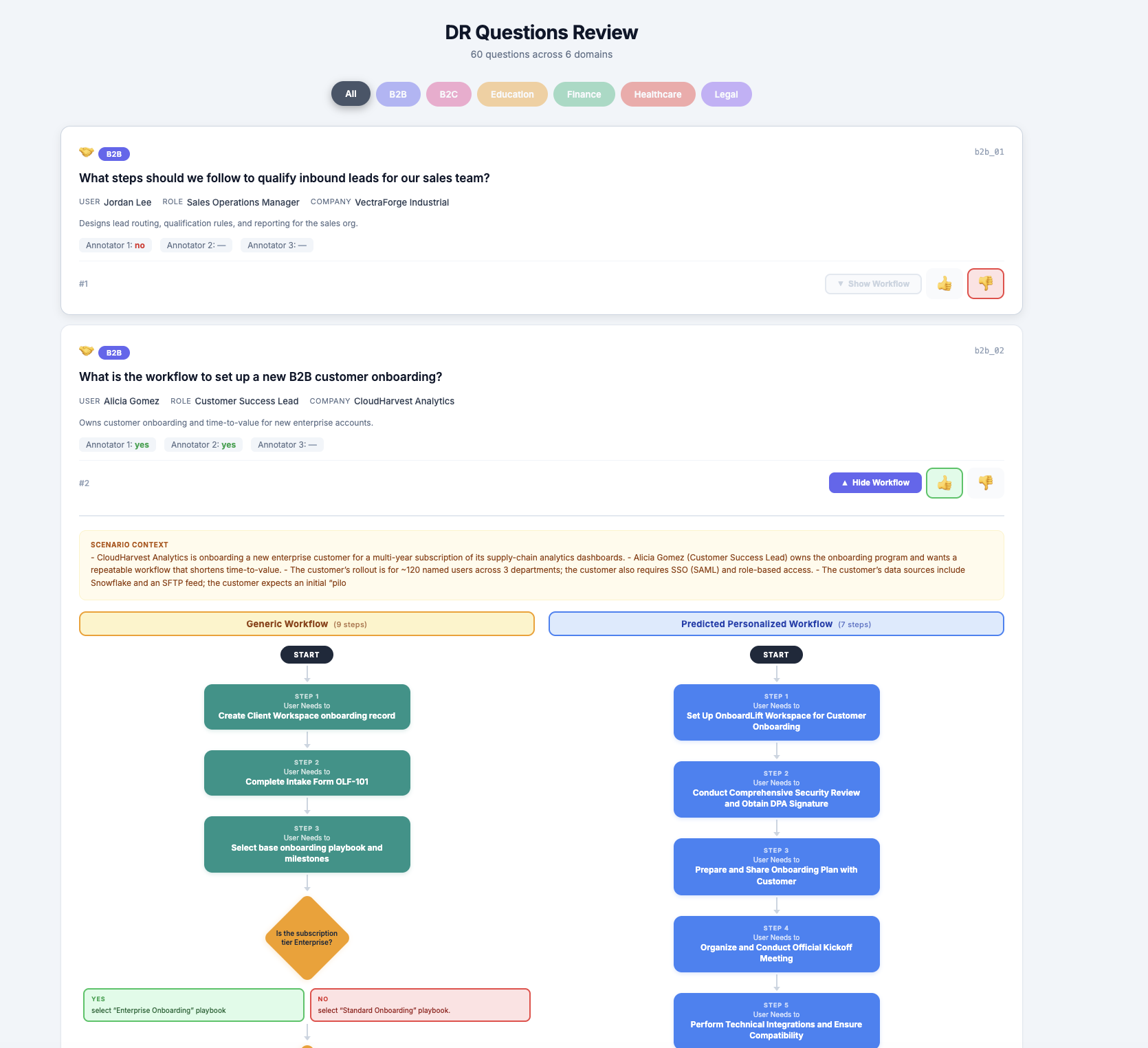
Fig 3 (page 59).
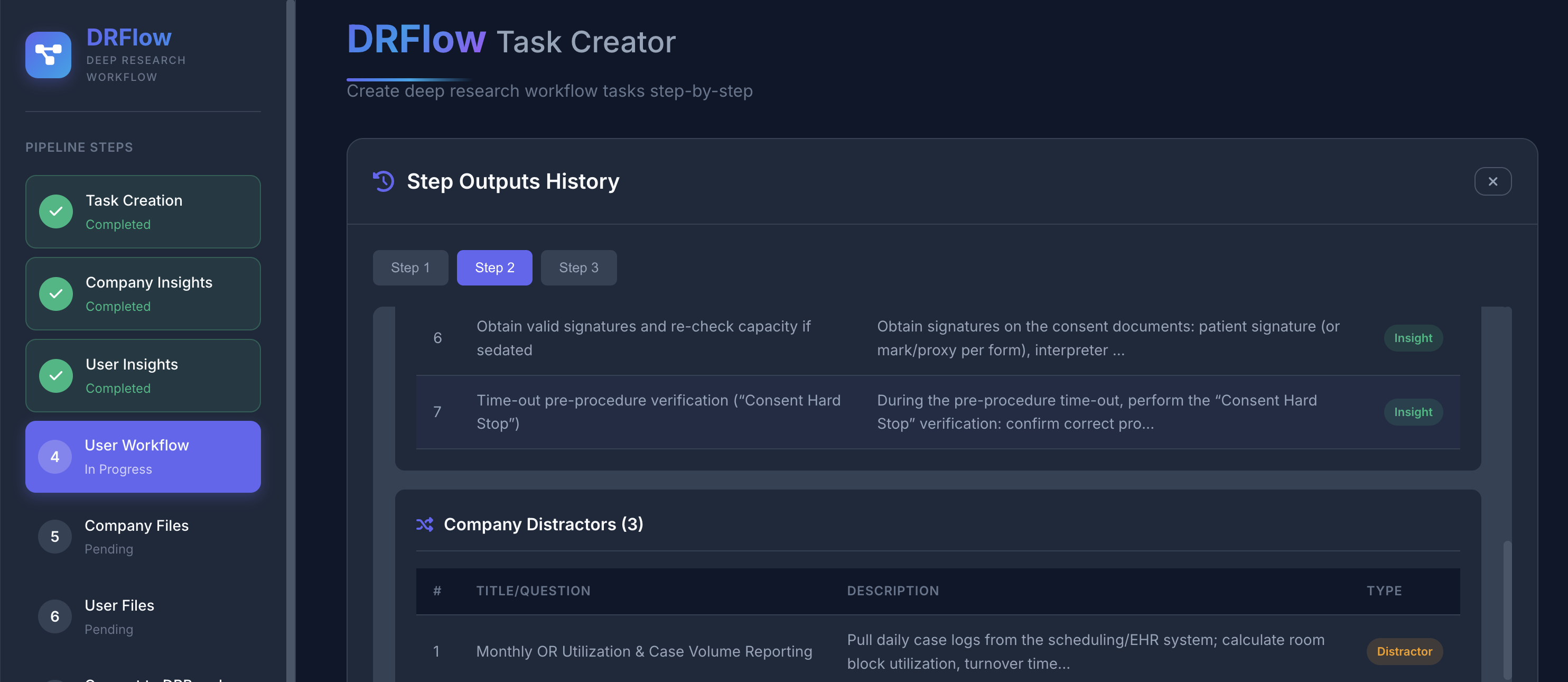
Fig 4 (page 59).
Fig 5 (page 60).
Fig 6 (page 60).
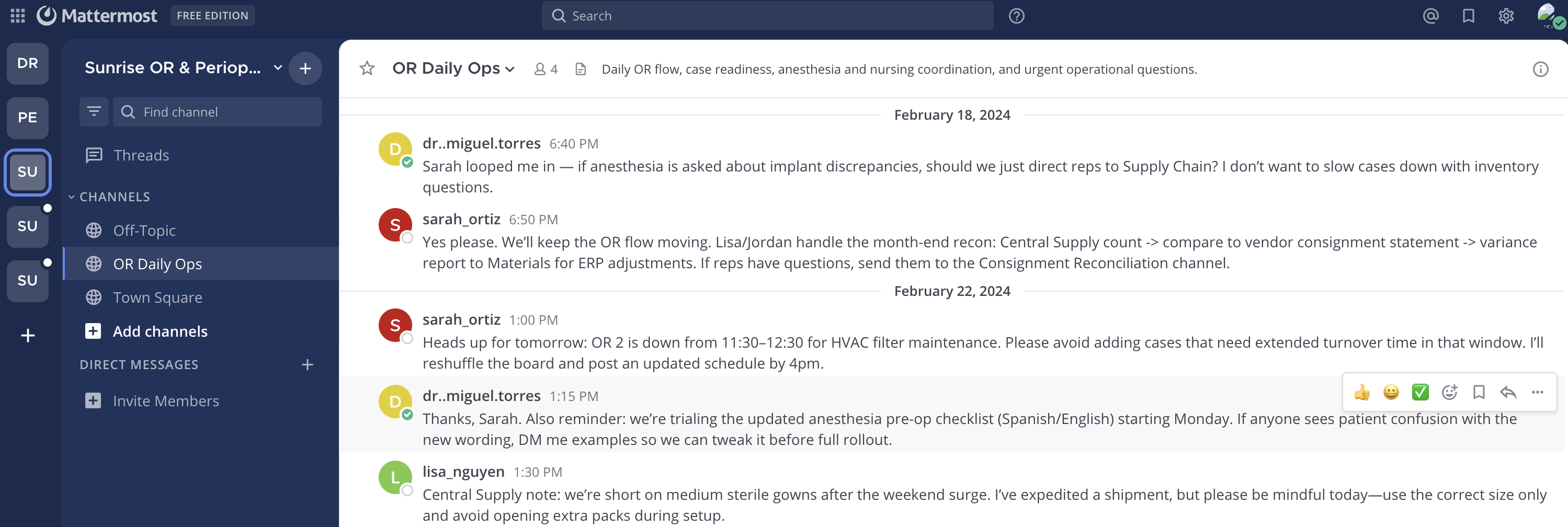
Fig 7 (page 60).
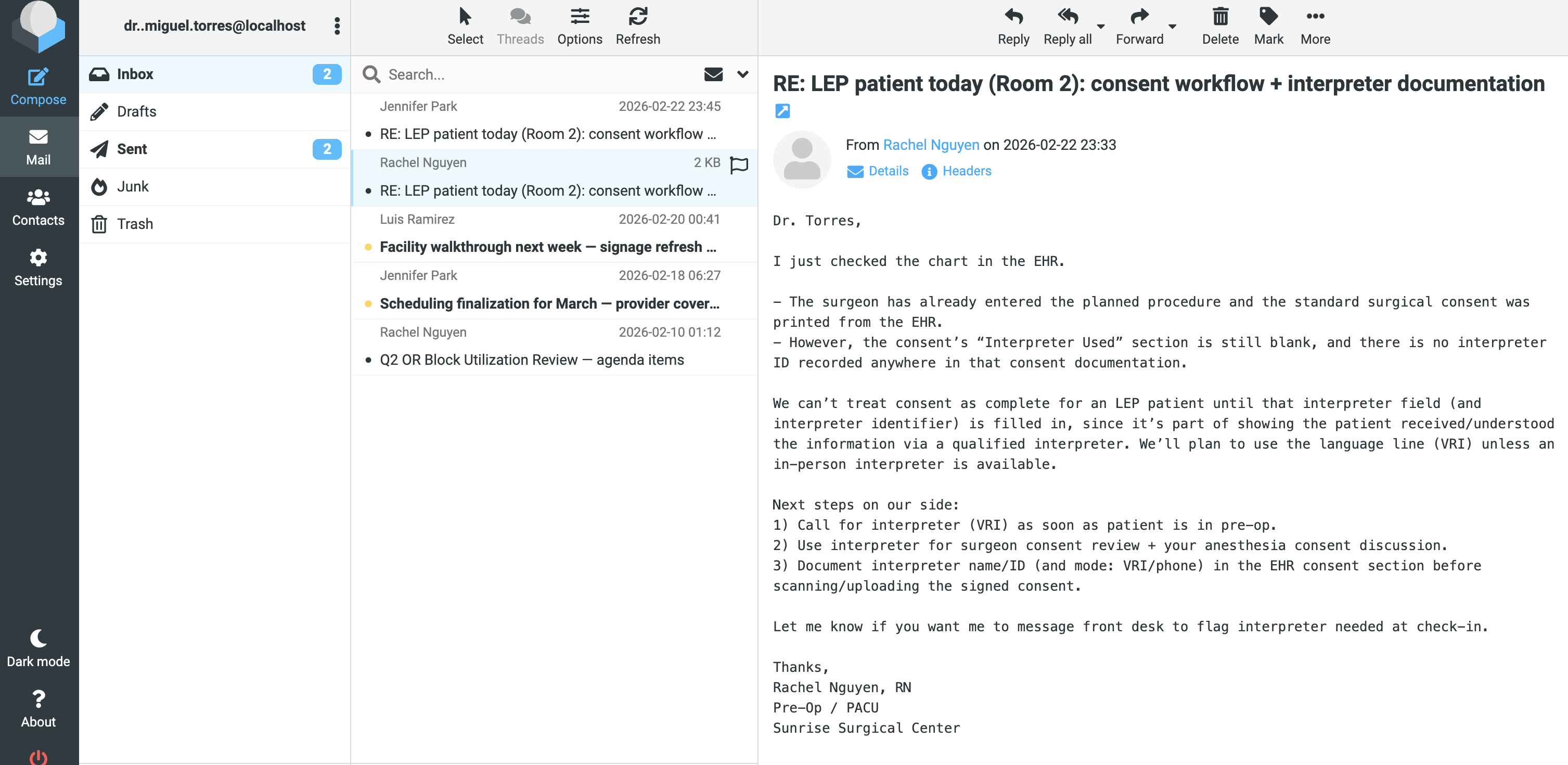
Fig 8 (page 61).
Limitations
- Benchmark tasks and data are synthetically generated with human verification, but may lack some real-world noise or adversarial complexity.
- While the DRFLOW benchmark covers diverse domains, 100 tasks remain a moderate sample size relative to enterprise diversity.
- Evaluation does not yet include adversarial attacks or robust testing against intentional workflow obfuscation.
- Performance remains modest even for state-of-the-art LLM backbones, indicating scaling to larger or more complex workflows remains challenging.
- Factuality assessments are complicated by distributed heterogeneous evidence, occasionally impacting metric reliability.
- The mixed split exposes fragility when faced with confounding evidence; generalization to open-world unseen cases needs further study.
Open questions / follow-ons
- How to improve robustness and generalization of workflow prediction agents under large-scale confounding or adversarial evidence?
- Can retrieval and reasoning components be better integrated to more accurately resolve conditional branches and personalization constraints?
- How to scale personalized workflow prediction to more dynamic, real-time enterprise environments with frequent policy/process changes?
- What advances in multimodal or structured data grounding could further reduce factuality errors and improve step sequencing accuracy?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, DRFLOW illustrates the complexity of naturalistic workflow prediction tasks that go beyond simple question-answering or free-form text generation. The modular and multi-step approach of DRFA to evidence retrieval, conditional resolution, and structured output generation can inspire defenses that require bots to comprehend, aggregate, and act upon fragmented evidence from heterogeneous sources before producing a valid sequence of steps—far harder than generating plausible text.
Moreover, the diagnostic workflow metrics (e.g., condition resolution, personalization) highlight dimensions of behavioral consistency and grounding that advanced bot detectors might use to distinguish authentic, human-like reasoning from shallow or generic automated outputs. DRFLOW’s open benchmark and evaluation protocols provide a rigorous testbed for evaluating workflow-oriented multi-turn agent reasoning, which could be adapted to test the robustness and comprehensiveness of bot defenses in related scenarios where attackers try to bypass multi-step, conditionally branching challenge-response protocols.
Cite
@article{arxiv2606_18191,
title={ DRFLOW: A Deep Research Benchmark for Personalized Workflow Prediction },
author={ Md Tawkat Islam Khondaker and Raymond Li and Muhammad Abdul-Mageed and Laks V. S. Lakshmanan and Issam H. Laradji },
journal={arXiv preprint arXiv:2606.18191},
year={ 2026 },
url={https://arxiv.org/abs/2606.18191}
}