
Architectural Bias in Face Presentation Attack Detection: A Comparative Study of Vision Transformers and Convolutional Neural Networks
Source: arXiv:2606.18510 · Published 2026-06-16 · By Ngela Landon Ntung, Floride Tuyisenge, Jema David Ndibwile
TL;DR
This paper addresses the critical issue of demographic bias in face Presentation Attack Detection (PAD) systems, focusing on whether Vision Transformer (ViT) architectures can reduce such biases compared to traditional convolutional neural networks (CNNs). The authors conduct a rigorous empirical comparison using the CASIA-SURF Cross-Ethnicity Face Anti-Spoofing (CeFA) dataset, which includes African, East Asian, and zero-shot Central Asian demographic groups. They evaluate three model types: a ViT-Tiny trained from scratch, a pretrained ResNet18 CNN, and a pretrained DeiT-S transformer fine-tuned on CeFA.
Key results show that DeiT-S achieves highest overall accuracy (97.27%) and lowest equal error rate (0.86%), outperforming ResNet18 at 90.15% accuracy. Importantly, DeiT-S reduces the inter-ethnic Average Classification Error Rate (ACER) gap between African and East Asian groups to 0.13%, an 83% reduction compared to LBP-based fairness-aware methods. DeiT-S also demonstrates substantially better generalization to unseen Central Asian subjects, yielding a 2.89% Bona Fide Presentation Classification Error Rate (BPCER) versus 10.44% for ResNet18—a 3.6-fold improvement. These findings indicate that pretrained Vision Transformers combined with global self-attention mechanisms provide both higher PAD performance and more equitable demographic fairness, suggesting architectural design influences bias in biometric security systems.
Key findings
- DeiT-S achieves overall accuracy of 97.27% and EER of 0.86% on CeFA, outperforming ResNet18 at 90.15% accuracy and 1.90% EER (Table I, V).
- DeiT-S reduces the inter-ethnic ACER gap between African and East Asian groups to 0.13%, an 83% decrease compared to 0.75% ACER gap from prior LBP-based method [6].
- DeiT-S obtains 2.89% BPCER on zero-shot Central Asian subjects, 3.6× better than ResNet18’s 10.44% BPCER, showing superior generalization to unseen demographics (Table III, IV).
- Scratch-trained ViT-Tiny achieves high overall accuracy (96.48%) but shows large demographic fairness gap (1.35% ACER for African vs 0.41% for East Asian) and training instability (Table II).
- ResNet18 CNN performs well on seen ethnic groups (AF ACER 0.34%, EA ACER 0.24%) but struggles massively on unseen CA group (BPCER 10.44%) (Table IV).
- Fairness gap reductions in DeiT-S are statistically validated using McNemar’s test and bootstrap confidence intervals per the framework in [6].
- Pretraining and architectural choice jointly influence fairness: DeiT-S pretrained on ImageNet outperforms ViT-Tiny trained from scratch, implicating both data diversity and model design (Section V.A).
- DeiT-S’s global self-attention reduces texture bias found in CNNs that depend on local skin texture, improving cross-demographic robustness (Section II.C).
Threat model
Adversaries conduct presentation attacks (print photos, replay video, or 3D masks) to spoof face biometric systems. The defender’s system must detect these attacks across demographic groups including unseen ethnicities. Attackers are not assumed to manipulate input beyond physical spoof presentations; the defender cannot retrain or adapt models dynamically for unseen demographics. The system treats demographic attributes as labels for fairness evaluation but does not incorporate explicit demographic inputs.
Methodology — deep read
The authors focus on face Presentation Attack Detection (PAD) where adversaries try to spoof biometric systems using printed photos, videos, or masks. The threat model involves demographic generalization challenges, where models trained on some ethnicities must detect attacks on unseen ethnic groups. They assume attackers have physical artifacts but the models have no demographic information beyond ethnicity labels.
Dataset: The CASIA-SURF CeFA dataset is used, consisting of 1,607 subjects across African (AF), East Asian (EA), and Central Asian (CA) groups, totaling ~90K RGB facial images. CA samples are treated as zero-shot (unseen) test data to assess generalization. Training/validation splits use 80%/20% of AF and EA plus 3D mask attacks, excluding CA and silicone masks for zero-shot evaluation.
Preprocessing: Identical ethnicity-aware image preprocessing (resizing to 224x224, CLAHE contrast enhancement, and adaptive gamma correction) was applied uniformly across all models to isolate architectural effects from input biases.
Models: Four models were evaluated:
- LBP + SGD Baseline: Classical fairness-aware Local Binary Patterns method with group-specific thresholds from prior work [6].
- ResNet18 CNN baseline: ImageNet-pretrained ResNet18 fine-tuned on CeFA for 50 epochs with cross-entropy and cosine annealing.
- DeiT-S: Pretrained Data-efficient Image Transformer Small, 12 transformer layers, 6-head self-attention, embedding dimension 384, fine-tuned under same training regime as ResNet18 with AdamW optimizer and standard augmentations.
- Multimodal ViT-Tiny: A smaller ViT trained from scratch on CeFA without pretraining, initialized randomly.
Training: All models trained for 50 epochs with consistent batch size (not specified), balanced class weights, and standard data augmentations (random flips, crop, color jitter). Weights were saved at epoch of best validation loss.
Evaluation: Models evaluated on held-out validation and test splits disaggregated by ethnicity and attack type. Metrics computed: overall accuracy, APCER, BPCER, ACER, EER, AUC. Statistical fairness assessed by maximum accuracy gap between ethnic groups (Δfairness), McNemar’s test for significance, and 1000-sample bootstrap for 95% confidence intervals.
Reproducibility: Exact random seeds were not reported. Code and pretrained weights were not publicly released, so full reproduction requires dataset access and replication of training details from text.
Concrete example: DeiT-S fine-tuned on CeFA achieved 97.27% overall accuracy and 0.13% ACER gap between African and East Asian groups, a reduction from 0.75% for LBP baseline. DeiT-S maintained 2.89% BPCER on zero-shot Central Asian subjects, versus 10.44% BPCER for ResNet18 CNN baseline, demonstrating superior cross-demographic generalization.
Overall, the study uses a rigorously controlled setup, consistent preprocessing and data splits, comparable training regimes, and permits attribution of improved demographic fairness to architectural differences supported by statistical tests.
Technical innovations
- Demonstration that pretrained Vision Transformer architecture (DeiT-S) achieves both higher PAD accuracy and substantially reduced demographic bias compared to CNN baseline (ResNet18).
- Use of large-scale ImageNet pretrained DeiT-S fine-tuned on multi-ethnic CeFA dataset to establish ViT’s improved demographic generalization over CNNs for PAD.
- Application of rigorous fairness evaluation using inter-ethnic ACER gap, McNemar’s test, and bootstrap confidence intervals for demographic bias assessment in PAD models.
- Empirical linkage of ViT’s reduced texture bias via global self-attention to improved cross-demographic fairness in biometric security tasks.
Datasets
- CASIA-SURF Cross-Ethnicity Face Anti-Spoofing (CeFA) — 1,607 subjects, ~90K RGB images — publicly available via CASIA
Baselines vs proposed
- ResNet18 CNN baseline: overall accuracy = 90.15%, ACER = 5.22%, BPCER on zero-shot CA = 10.44%
- LBP + SGD classical baseline [6]: reported inter-ethnic ACER gap = 0.75%
- Multimodal ViT-Tiny (scratch): overall accuracy = 96.48%, ACER = 1.05%, inter-ethnic ACER gap = 0.94%
- DeiT-S: overall accuracy = 97.27%, ACER = 1.45%, EER = 0.86%, inter-ethnic ACER gap = 0.13%, BPCER on zero-shot CA = 2.89%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.18510.
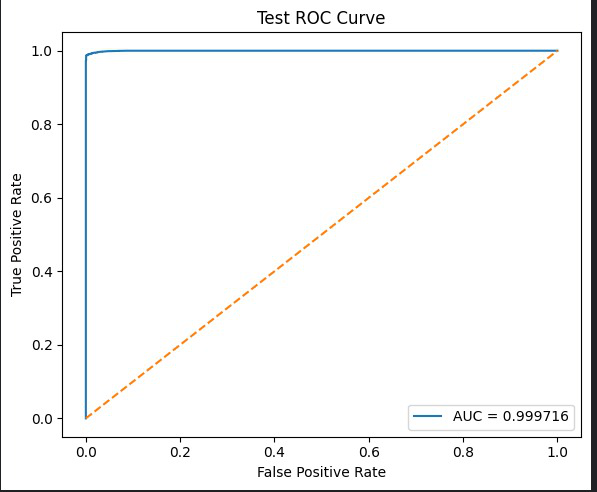
Fig 1: ROC Curve for DeiT-S on CASIA-SURF CeFA Dataset.
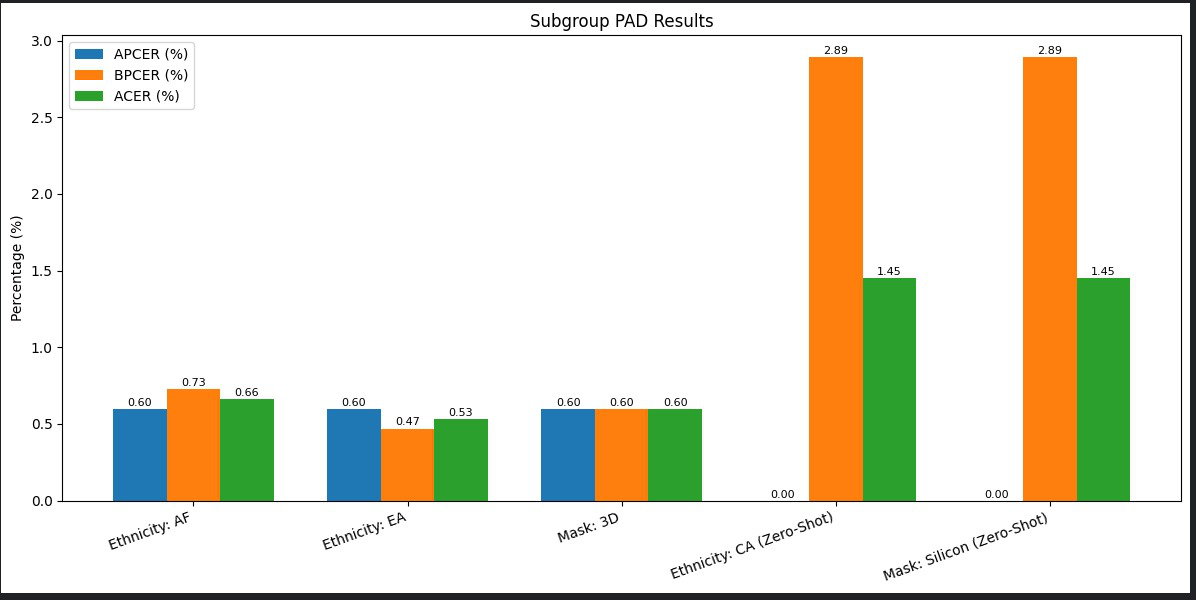
Fig 2: Fairness Improvement in ACER Across Ethnic Groups: ViT-Tiny vs
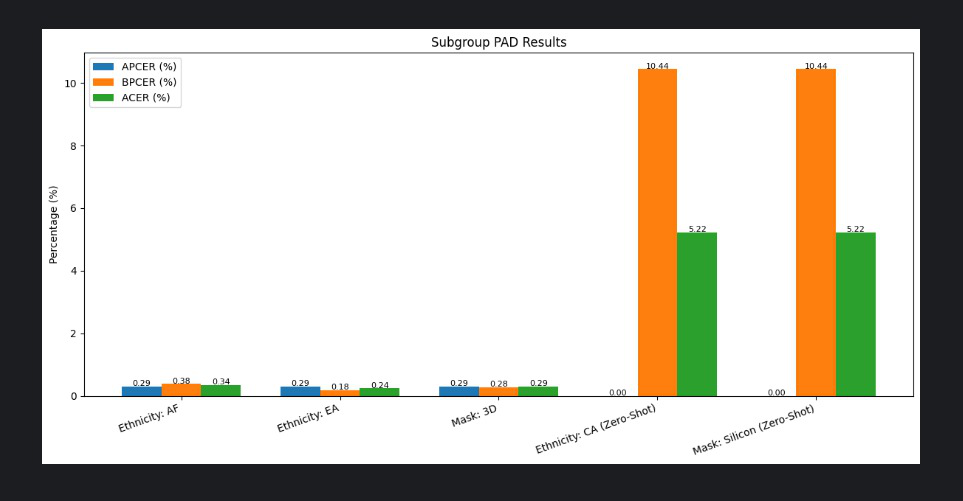
Fig 3: ResNet18 CNN Performance Across Seen and Zero-Shot Groups.
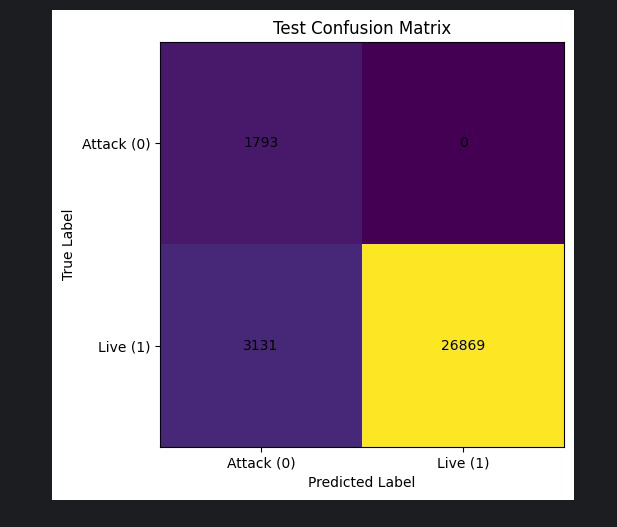
Fig 4: ResNet18 CNN Confusion Matrix by Ethnic Group Showing Zero-
Limitations
- Evaluation conducted only on a single PAD dataset (CASIA-SURF CeFA); results may not fully generalize to other datasets or biometric modalities.
- Fairness improvements may derive from interaction of pretraining data diversity with architecture—controlled ablation of pretraining effects was not performed.
- Only RGB modality evaluated; multi-modal sensors (depth, infrared) common in biometric systems were excluded to mimic typical smartphone cameras.
- Training batch sizes, random seeds, and hardware details not fully specified; exact reproducibility may be difficult.
- The zero-shot demographic group (Central Asian) is treated as unseen, but the inherent demographic variation within other groups is not deeply analyzed.
- Potential overfitting to CeFA dataset’s specific attack types or demographic distributions despite zero-shot testing on silicone masks.
Open questions / follow-ons
- What is the relative contribution of architectural design versus pretraining data diversity to fairness improvements in Vision Transformers?
- Do these architectural fairness advantages generalize to other PAD datasets, biometric modalities (depth, IR), or real-world deployment scenarios?
- Can fairness-aware training or adaptation methods further enhance ViT demographic equity beyond what is achieved by architecture and pretraining alone?
- How do transformer architectures perform under adversarial or more sophisticated attack scenarios beyond those tested here?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on biometric anti-spoofing, this study highlights that selecting or developing PAD models should carefully consider both architectural bias and pretraining impacts. Vision Transformers pretrained on large diverse datasets may offer superior security by reducing false rejections of legitimate users from underrepresented demographic groups, thereby improving equitable system usability. Additionally, the demonstrated generalization to unseen demographic groups signals that ViTs could maintain robustness when deployed in heterogeneous user populations encountered by globally distributed anti-bot systems.
Practitioners should note that CNN-based PAD models, while performant on known demographics, risk high false rejection rates on unseen populations, creating unfair user experiences and potential security blind spots. Incorporating fairness evaluation methods such as inter-ethnic ACER gaps and significance testing into model validation pipelines can help detect demographic biases early. Finally, the benefits appear to hinge not on architecture alone but the synergy between transformer inductive biases and large-scale pretraining, implying future anti-spoofing defenses should consider hybrid approaches and pretraining data diversity to maximize fairness and security.
Cite
@article{arxiv2606_18510,
title={ Architectural Bias in Face Presentation Attack Detection: A Comparative Study of Vision Transformers and Convolutional Neural Networks },
author={ Ngela Landon Ntung and Floride Tuyisenge and Jema David Ndibwile },
journal={arXiv preprint arXiv:2606.18510},
year={ 2026 },
url={https://arxiv.org/abs/2606.18510}
}