
UXBench: Measuring the Actionability of LLM-Generated UX Critiques
Source: arXiv:2606.16262 · Published 2026-06-15 · By Wenjie Wang, Yue Huang, Zipeng Ling, Han Bao, Hang hua, Xiaonan Luo et al.
TL;DR
The paper addresses the emerging role of large language models (LLMs) as UX judges that inspect and critique interactive web interfaces. Despite widespread interest in LLMs for usability diagnosis, no controlled benchmark existed for systematically measuring whether their critiques are reliable, actionable, and transferable across diverse product surfaces. To fill this gap, the authors introduce UXBench, a novel benchmark consisting of local-first runnable web fixtures spanning ten product-surface families, equipped with an interaction-driven, coverage-gated exploration protocol that forces the LLMs to collect empirical evidence before generating critiques. Each model produces a structured UX report rated along seven rubric dimensions, and report quality is measured by whether a fixed repair agent can effectively improve the interface based on the critique.
UXBench was used to evaluate eight frontier LLMs via automated repair-lift tests and a blind human validation study. Results show UX judging remains a complex, multi-faceted problem: models vary notably in overall actionability, dimension-level repair signatures, reliability on particular fixtures, and leadership across surface types. The best model improves the UX rubric score by +0.22 points on a 1-5 scale compared to baseline, with other models trailing behind. Human ratings broadly confirm the automated rankings but indicate a top cluster rather than a strict dominance hierarchy. This work concretely demonstrates that LLMs are not yet interchangeable as UX judges and provides a rigorous, reproducible platform for longitudinal evaluation.
Key findings
- LLMs differ significantly in producing actionable UX critiques, with GPT-5.4 achieving a +0.22 repair lift on a 1-5 rubric scale versus Gemini-3.1-Pro's +0.14 (Table 1).
- Models exhibit distinct rubric-level repair signatures: GPT-5.4 leads in error recovery (+0.36), Kimi k2.5 leads feedback and trust transparency (+0.44 and +0.27), Sonnet 4.6 excels at goal-state clarity (+0.15), and Qwen 3.6 is strongest on flow and scanability/accessibility (+0.39) (Table 1).
- Fixture-level reliability varies: GPT-5.4 shows the widest performance spread across different fixtures, indicating uneven report consistency, while some lower-ranked models provide more stable but lower peak gains (Figure 4).
- Surface-conditioned competence differs—docs and pricing pages are easier to improve, while dashboards and chatbot interfaces remain challenging, with top-performing models varying by surface category (Figure 5, Table 2).
- Pairwise win rates reveal no strict global ranking; GPT-5.4, Kimi-K2.5, and GLM-5.1 form a competitive top cluster, with Gemini-3.1-Pro generally underperforming but leading in dashboards (Figure 6).
- Blind human validation aligns broadly with automated repair-lift rankings, showing repaired interfaces from stronger judge reports are perceived as more usable, but human raters place GPT-5.4 and Sonnet 4.6 in a close top tier rather than a strict ordering (Figure 7).
- Synthesized siblings exhibit higher accessibility risks, while real product anchors challenge information architecture breadth, confirming that UXBench covers varied and realistic UX failure modes (Figure 3).
Threat model
The underlying threat model assumes an LLM acting as a UX judge with access to observable interface states and user interactions but no privileged knowledge of the interface backend, user personal data, or adversarial manipulations. The LLM's goal is to identify actionable usability issues based solely on grounded interaction evidence. There are no active adversaries attempting to deceive or mislead the judge, nor is the judge itself adversarial. The focus is purely on evaluating the judge's reliability and actionability under honest conditions.
Methodology — deep read
The authors formulate UX judging as an interaction-grounded, report-conditioned repair evaluation task. The threat model implicitly supposes a UX judge LM who must explore a web interface, collect observable evidence about usability, and produce an evidence-backed critique enabling interface repair. The adversary is the LLM judge needing to be accurate and actionable; no explicit attacker is considered.
UXBench provides 41 local-first static HTML/CSS/JS web fixtures across 10 product-surface families (e.g., landing, pricing, onboarding, dashboard, chatbot). There are 11 real-product anchors and 30 synthetic siblings, the former preserving real-world interaction flows and the latter introducing varied branding, text, and layout. Using local-first fixtures eliminates backend variability and live-site drift, allowing controlled evaluation.
Each model-driven judge executes a 4-stage protocol: (1) prescan produces a structural summary and adaptive exploration plan; (2) a coverage-gated browser exploration performs repeated observe-act-inspect cycles, with LLM selecting user-like actions (click, type, scroll) conditioned on prior states; exploration is constrained by a coverage gate requiring sufficient evidence to terminate; (3) the model generates an evidence-grounded UX report along seven rubric dimensions (goal clarity, navigation scent, action feedback, flow efficiency, error recovery, trust transparency, scanability/accessibility), with each finding trace-linked to observed interactions; (4) a fixed repair agent (Claude Code) attempts localized interface repair constrained to preserve intent and style based on the report, yielding a repaired interface.
The repaired interface is scored by a fixed automated judge (GPT-5.4-Mini) using the same rubric. The delta improvement over baseline interface measures the judge report's actionability. This pipeline is repeated for all judge models and fixtures under a uniform exploration budget.
Two evaluation protocols are used: an automated sweep across eight frontier LLM judge models producing repair lifts, plus a blind human study where six UX experts blindly compare repaired interfaces across models along the same rubrics.
Data preprocessing includes prescanning fixture structures and extracting salient controls for coverage monitoring. The exploration agent adaptively reroutes upon ambiguous feedback and tests error/recovery paths. Reports require concrete interaction evidence for validity, ensuring critique grounding beyond static impressions.
Evaluation metrics involve mean rubrics scores (1-5, 5 = no issues), per-dimension deltas, pairwise win rates, fixture-level repair lifts, and human rating correlations. Site-level variance and confidence intervals are computed to assess robustness. Some significance testing and effect size analyses were performed (Appendix G), though detailed p-values or CI ranges are not fully reported in the excerpt.
Reproducibility is supported via local-first fixtures and a stable benchmark infrastructure. Code availability and fixture hosting URLs are referenced but not fully detailed here. Exact model prompt engineering details and hyperparameters for the judge or repair agents are not fully enumerated but presumably standardized per run. The fixed repair agent enforces consistent post-report interface editing to isolate report quality.
An example end-to-end: GPT-5.4 begins with a prescan of a checkout page, plans to verify payment form validity and feedback messaging, interacts with disabled buttons and invalid inputs to collect latent error states, then generates a UX report citing missing inline validation and hidden receipts. The repair agent edits the form code to add validation and surface success messages visibly. The scoring judge rates the revised interface with +0.22 rubric improvement over baseline, demonstrating actionable critique.
Overall, methodology tightly couples interactive evidence collection, grounded multi-criteria UX reporting, constrained code repair, and quantitative plus human evaluations to produce a rigorous, reproducible LLM UX-judge benchmark.
Technical innovations
- Introduction of a coverage-gated browser exploration protocol that forces LLM judges to collect sufficient interaction evidence before critique generation.
- A novel local-first runnable web fixture suite spanning ten heterogeneous product-surface families paired with real anchors and synthetic siblings to test both realism and non-memorization.
- Formulation of LLM-based UX judging as a report-conditioned repair evaluation problem, measuring critique actionability via whether a fixed repair agent improves an interface.
- Detailed multi-dimensional rubric scoring grounded in interaction trace evidence rather than static impressions.
- Integration of paired automated repair-lift evaluation with blind expert human validation to calibrate and verify model rankings.
Datasets
- UXBench — 41 web fixtures (11 real anchors + 30 synthetic siblings) — constructed local-first static HTML/CSS/JS bundles
Baselines vs proposed
- GPT-5.4: mean rubric score improvement ∆ = +0.22 versus Gemini-3.1-Pro: +0.14 (Table 1)
- Kimi k2.5: ∆ = +0.21; Sonnet 4.6: ∆ = +0.19; GPT Mini: ∆ = +0.19; GLM 5.1: +0.17; GPT Nano: +0.17; Qwen 3.6: +0.15; Gemini 3.1: +0.14 (Table 1)
- Human expert mean scores cluster GPT-5.4 and Sonnet 4.6 at the top around 3.98–3.99 out of 5, with other models trailing (Figure 7)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.16262.
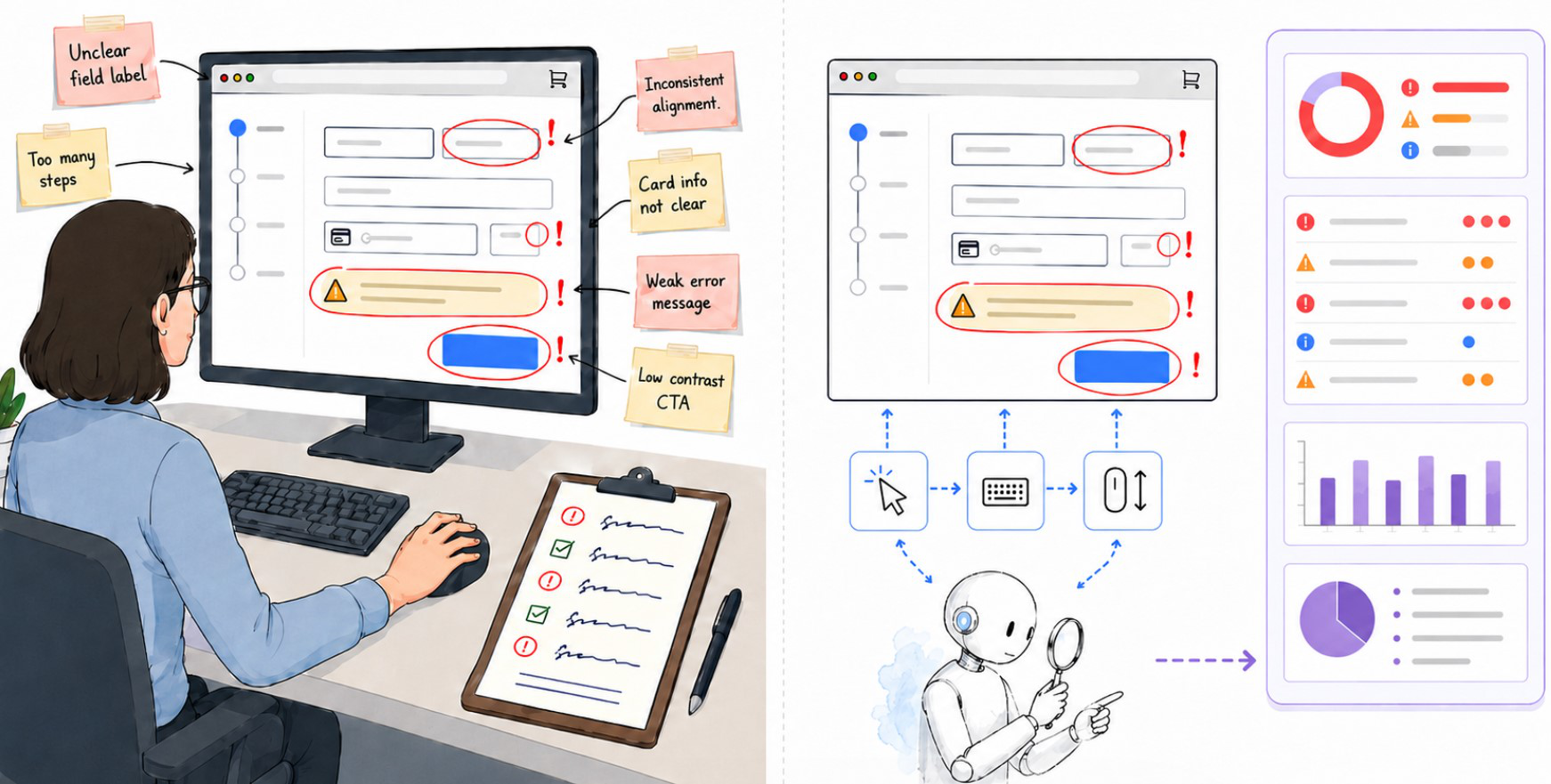
Fig 1: Interaction-grounded UX judging: like hu-

Fig 2: Overview of UXBench. Local-first real anchors and synthetic siblings are evaluated through

Fig 3: Structural characterization of real anchors

Fig 4 (page 5).

Fig 5 (page 5).
Fig 6 (page 5).
Fig 7 (page 5).

Fig 8 (page 5).
Limitations
- Use of local-first static fixtures limits modeling of dynamic live-site phenomena such as personalization, backend failures, or long-term user behavior.
- Report actionability is tied to a single fixed repair agent and scoring judge, limiting generalization to other repair workflows or human developer interpretations.
- Human evaluation was conducted with a small number of expert reviewers (six) and limited scale, restricting broader validation across diverse users and contexts.
- Exploration budgets and coverage criteria are fixed, possibly affecting model behaviors under different constraints.
- No explicit adversarial evaluations or robustness tests under malicious or deceptive interface manipulations.
- Specifics of the LLM judge prompting and hyperparameters are not fully detailed, limiting replication fidelity.
Open questions / follow-ons
- How do LLM judges perform under dynamic or personalized interfaces where live backend state affects usability?
- Can the repair agent framework generalize to more diverse or manual developer workflows, capturing broader report actionability?
- How robust are LLM UX judges against adversarially crafted UI anti-patterns or deceptive affordances?
- What are the effects of varying exploration budgets and coverage criteria on judge reliability and report completeness?
Why it matters for bot defense
For practitioners in bot defense and CAPTCHA design, UXBench highlights the complexity and multi-dimensionality of reliable automated interface evaluation by LLMs. While CAPTCHAs often represent narrowly scoped interactive challenges, this study shows that assessing UX in varied, complex interactive flows requires evidence-grounded, structured exploration and critique mechanisms rather than superficial static snapshots. When integrating LLMs into bot detection or challenge generation tools, it's crucial to account for the LLM's ability to interactively test interfaces and produce actionable feedback grounded in observed state transitions.
Moreover, the finding that LLM judge models vary significantly across interface families and rubric dimensions warns against assuming uniform LLM performance. Bot defense engineers should carefully evaluate candidate models on relevant interface types (e.g., transaction flows, data entry forms) and consider multi-dimensional rubrics such as feedback visibility, error recovery, and trust transparency. The UXBench methodology could inspire development of nuanced evaluation benchmarks for CAPTCHA UX, helping to identify which LLMs or agents reliably detect or improve challenge usability, ultimately reducing false positives and friction.
Cite
@article{arxiv2606_16262,
title={ UXBench: Measuring the Actionability of LLM-Generated UX Critiques },
author={ Wenjie Wang and Yue Huang and Zipeng Ling and Han Bao and Hang hua and Xiaonan Luo and Yu Jiang and Shiyi Du and Yuexing Hao and Xiaomin Li and Yuchen Ma and Dianzhuo Wang and Yanfang Ye and Xiangliang Zhang },
journal={arXiv preprint arXiv:2606.16262},
year={ 2026 },
url={https://arxiv.org/abs/2606.16262}
}