
SurroundNEXO: Ego-Centric Metric Bridging for Spatially Consistent Geometry in Autonomous Driving
Source: arXiv:2606.16960 · Published 2026-06-15 · By Shuai Yuan, Runxi Tang, Yuzhou Ji, Fudong Ge, Hanshi Wang, Yifei Wang et al.
TL;DR
SurroundNEXO addresses a critical problem in autonomous driving: metric-depth estimation from surround-view multi-camera rigs with extremely low overlapping fields of view (FoV). Traditional multi-view depth and geometry reconstruction methods assume substantial cross-view visual overlap to establish dense correspondences, which is not the case in typical vehicle surround cameras where views face outward with minimal visual overlap. This severely limits the effectiveness of existing global attention or cross-view fusion techniques, which either degrade single-view accuracy or fail to maintain cross-view spatial consistency. SurroundNEXO departs from reliance on dense visual correspondences by grounding feature tokens into a shared ego-centric geometric frame through a novel Ego-Ray Positional Encoding (ERPE), which encodes image patches by their ego-centric viewing directions. It then injects absolute metric scale cues via Sparse Metric Anchoring (SMA) using sparse LiDAR points as anchors, and progressively expands feature interaction from local per-view modeling to decomposed spatio-temporal and global fusion through a Progressive Geometry Transformer (PGT). This architecture enables both high-fidelity single-view metric depth estimation and improved multi-view spatial consistency for downstream 3D reconstruction in low-overlap surround drive scenes. On multiple autonomous driving benchmarks including NuScenes, Waymo, DDAD, KITTI, and Argoverse (zero-shot), SurroundNEXO reduces single-view absolute relative error by 33.2%, improves cross-view consistency metrics by 10.5%, and boosts 3D reconstruction accuracy by 25.6% compared to state-of-the-art methods. Its robust performance under extremely sparse depth prompt conditions and good generalization to unseen camera layouts highlight its practical applicability for surround-view depth perception in autonomous vehicles.
Key findings
- SurroundNEXO reduces single-view absolute relative depth error by 33.2% compared to SOTA methods across low-overlap datasets including NuScenes, Waymo, KITTI, DDAD, and OpenScene.
- Cross-view consistency metrics (Abs Rel, Sq Rel, RMSE, δ<1.25) improve by an average 10.5% on NuScenes and DDAD compared to prior methods like DA3-G and DVGT.
- 3D reconstruction accuracy (measured by ICP alignment accuracy and completeness) improves by 25.6% over existing feed-forward geometry models such as MapAnything and DA3-G.
- Ego-Ray Positional Encoding (ERPE) enables global comparison of image tokens across views by encoding patch directions in a unified ego-centric spherical coordinate system.
- Sparse Metric Anchoring (SMA) effectively propagates sparse LiDAR measurements as absolute metric scale cues into dense depth predictions, boosting metric-scale accuracy especially under sparse depth supervision.
- Progressive Geometry Transformer (PGT) stages feature interaction from view-local intra-attention to decomposed spatio-temporal cross-view attention and finally global integration, avoiding early noisy global fusion.
- Robustness tests show SurroundNEXO maintains high performance with extremely sparse depth prompts (down to 0.1% sampling) without requiring post-alignment scaling.
- In zero-shot evaluations on Argoverse, SurroundNEXO outperforms other feed-forward methods in both metric depth accuracy (Abs Rel 0.081 vs next-best >0.1) and 3D reconstruction quality.
Threat model
The threat model is typical of autonomous driving scenarios where the sensor setup includes multiple calibrated surround cameras with limited visual overlap and sparse LiDAR depth is available but can be extremely sparse or missing. The system must accurately estimate metric depth under these physical constraints without assumptions of dense visual correspondences or large overlapping FoVs. It assumes no adversarial manipulation of sensors or environmental conditions beyond what is normal for autonomous vehicle perception tasks.
Methodology — deep read
Threat Model & Assumptions: The adversary or environment is typical autonomous driving scenarios with surround-view camera rigs producing low or near-zero overlap (~10%-25%) between adjacent cameras. The method assumes availability of sparse LiDAR observations as anchors for metric scale but must perform well even under extreme sparsity or absence of such sparse points. Cameras are calibrated with known intrinsics and extrinsics. There is no adversarial attacker explicitly considered — the focus is on improving multi-view depth estimation under challenging sensor setups.
Data: Training data are curated from multiple large-scale autonomous driving datasets inclusive of NuScenes, Waymo, KITTI, DDAD, and OpenScene, combined with weighted sampling (waymo weighted highest) to balance scale and quality. Sparse depth points from LiDAR are used as inputs for metric anchoring, and full dense pseudo-depth from multi-modal data serves as supervision. Evaluation includes held-out validation splits and zero-shot tests on Argoverse with unseen camera layouts. Preprocessing includes random multi-view and temporal frame sampling with variable aspect ratios, normalization, and sparse depth input augmentation to simulate various sparsity levels.
Architecture/Algorithm:
- Ego-Ray Positional Encoding (ERPE): converts patch centers from local image coordinates to ego-frame spherical angles using camera intrinsics and rotation matrices, then Fourier encodes these angles and embeds them with an MLP. These embeddings are additively combined with visual tokens after patch embedding, enabling tokens across views to share a unified directional prior.
- Sparse Metric Anchoring (SMA): encodes sparse LiDAR points into anchor embeddings combining Fourier positional encoding, depth encoding, and local features sampled from visual embeddings via bilinear interpolation. SMA applies asymmetric cross-attention from RGB tokens querying sparse anchors with spatial decay bias towards local anchors. SMA updates tokens before the main transformer attention layer to propagate metric scale signals early.
- Progressive Geometry Transformer (PGT): a multi-stage transformer whose early layers apply intra-view attention preserving local per-view features, intermediate layers expand cross-view and cross-frame decomposed attention separately to avoid noisy fusion, and late layers perform global attention integrating all temporal and spatial tokens. SMA modules are inserted at regular intervals to recalibrate tokens with metric anchors progressively throughout the network.
Training Regime: Model initialized from pretrained DA3-G weights. Trained for 30,000 steps on 16 NVIDIA H20 GPUs with AdamW optimizer, using a double learning rate setup (higher for new modules). Batch size constrained by hardware to 16 images per iteration with dynamic multi-view and temporal sampling. Sparse depth inputs undergo probabilistic random sparsification or removal per iteration to improve robustness.
Evaluation Protocol: Evaluation metrics include Absolute Relative Error (Abs Rel), Root Mean Squared Error (RMSE), squared relative error (Sq Rel), and accuracy thresholds (δ < 1.25) for single-view and cross-view consistency. Cross-view consistency assessed by bidirectional reprojection errors in overlapping FoVs. 3D reconstruction metrics use ICP alignment to measure accuracy and completeness of reconstructed point clouds. Comparisons made against monocular metric depth baselines, prompt-based metric depth methods, and feed-forward multi-view 3D geometry foundation models. Zero-shot evaluation conducted on Argoverse for generalization.
Reproducibility: The paper states usage of publicly available datasets and initialization from DA3-G pretrained model. Code and project page publicly available (link in paper). Training details including data splits, augmentations, hyperparameters, and exact architectural components are described to aid reproducibility. Some training data filtering needed, but no closed-source data reported.
Technical innovations
- Ego-Ray Positional Encoding (ERPE): uniquely encodes image patches by ego-centric spherical directions to enable cross-view geometric linking without dense visual correspondences.
- Sparse Metric Anchoring (SMA): a novel asymmetric cross-attention module that injects absolute scale information from sparse LiDAR points into dense image tokens prior to main feature interactions.
- Progressive Geometry Transformer (PGT): a coarse-to-fine multi-stage transformer architecture that gradually expands feature interaction from intra-view to cross-view and temporal to global, avoiding premature noisy fusion in low-overlap views.
- Randomized sparse depth prompt augmentation during training to robustify performance under widely varying sparse input conditions without relying on dense supervision.
- Integration of sparse metric anchors as early calibration cues repeatedly across transformer layers rather than a single late correction step.
Datasets
- NuScenes — ~40k frames combined, multi-camera surround-view with sparse LiDAR — public autonomous driving dataset
- Waymo Open Dataset — large scale multi-view surround camera + sparse LiDAR — public autonomous driving dataset
- DDAD — multi-camera surround depth dataset with sparse depth and diverse scenes — public autonomous driving dataset
- KITTI — stereo and LiDAR based depth + RGB images — public autonomous driving dataset
- OpenScene — driving scenes multimodal dataset with surround view cameras and LiDAR — public autonomous driving dataset
- Argoverse — unseen camera layouts for zero-shot generalization testing — public autonomous driving dataset
Baselines vs proposed
- MoGe-2: single-view Abs Rel on Waymo = 0.177 vs SurroundNEXO = 0.048 (73% reduction)
- DA3-G: multi-view Abs Rel on NuScenes = 0.147 vs SurroundNEXO = 0.079 (46% reduction)
- DVGT: multi-view cross-view Abs Rel on NuScenes = 0.229 vs SurroundNEXO = 0.139 (39% reduction)
- MapAnything: 3D reconstruction Accuracy on NuScenes = 0.330 vs SurroundNEXO = 0.281 (15% improvement)
- DA3-G: 3D reconstruction time = ~31.79s vs SurroundNEXO = ~25.12s on 24×8 images (21% faster)
- Zero-shot on Argoverse: MapAny. Abs Rel = 0.113 vs SurroundNEXO = 0.081 (28% better)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.16960.

Fig 1: SurroundNEXO addresses metric depth estimation in low-overlap surround-view driving scenes. Instead of

Fig 2: Overview of SurroundNEXO. Given surround-view images, camera rigs, and sparse LiDAR, SurroundNEXO grounds

Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).
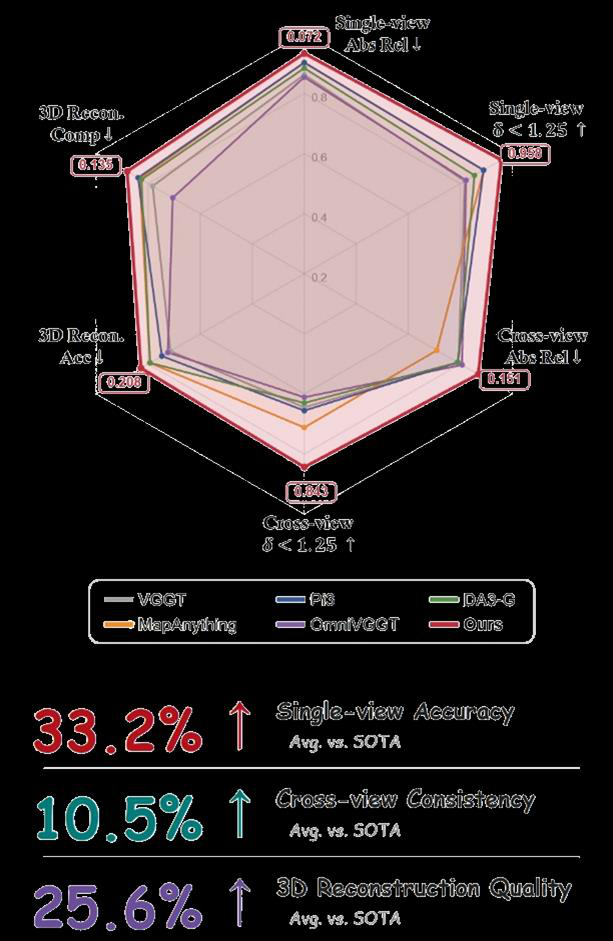
Fig 7 (page 2).

Fig 8 (page 2).
Limitations
- Performance gap persists on KITTI dataset attributed to near 100% camera overlap, favoring conventional correspondence methods.
- Method relies on quality of calibration parameters and availability of sparse depth points; extremely poor calibration or misaligned sparse depth may degrade performance.
- Sparse Metric Anchoring may require tuning of spatial decay and attention parameters per dataset for optimal scale propagation.
- Evaluation lacks explicit adversarial robustness or extreme weather condition tests detrimental to sensors in autonomous driving.
- Training requires large GPU memory and compute, limiting accessibility for rapid experimentation or smaller-scale deployment.
- Some finer details of failure cases under no sparse depth conditions or certain rare camera layouts are not fully analyzed.
Open questions / follow-ons
- Can SurroundNEXO's ego-centric geometric linking and sparse metric anchoring be extended to handle dynamic calibration errors or sensor misalignments?
- How does the method perform in challenging weather, nighttime, or adverse environmental conditions that degrade camera and LiDAR data?
- Could progressive interaction schemes be further optimized or made adaptive based on real-time overlap estimates or scene context?
- What strategies could integrate denser temporal fusion or motion cues beyond current decomposed cross-frame attention for better geometry completion?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, SurroundNEXO exemplifies the importance of grounding multi-view perception in a common, spatially consistent coordinate frame rather than relying on dense pixel-level matching. This parallels challenges in detecting coordinated bot actions or synthetic artifacts across distributed views where weak overlap or sparse shared signals exist. The Ego-Ray Positional Encoding approach could inspire representing cross-view or cross-session data streams via shared geometric or abstract embeddings aiding consistency checks. The Sparse Metric Anchoring mechanism highlights how sparse trusted signals can be propagated effectively to reinforce global scale or integrity in noisy data, akin to using trusted metadata or strong authenticators to anchor bot-detection features. Lastly, the Progressive Geometry Transformer demonstrates a robust architectural principle by gradually integrating multiple views avoiding early noisy fusions, which might analogously improve multi-modal or multi-source bot detection by staged reasoning. While the direct application domain differs, the conceptual approaches to fusing spatially limited and metric-anchored data may offer useful analogies or building blocks for CAPTCHA and bot-defense systems that must operate on low-overlap or partial signals across distributed observations.
Cite
@article{arxiv2606_16960,
title={ SurroundNEXO: Ego-Centric Metric Bridging for Spatially Consistent Geometry in Autonomous Driving },
author={ Shuai Yuan and Runxi Tang and Yuzhou Ji and Fudong Ge and Hanshi Wang and Yifei Wang and Xianming Zeng and Jianyun Xu and Xingliang Liu and Yanfeng Wang and Zhipeng Zhang },
journal={arXiv preprint arXiv:2606.16960},
year={ 2026 },
url={https://arxiv.org/abs/2606.16960}
}