
ROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning
Source: arXiv:2606.17011 · Published 2026-06-15 · By Wei Xiao, Weiliang Tang, Yuying Ge, Hui Zhou, Yao Mu, Li Zhang et al.
TL;DR
This paper addresses a major challenge in robotic Vision-Language-Action (VLA) model post-training, specifically for complex humanoid robots with dexterous hands. Human interventions during deployment provide valuable correction signals but are often imperfect due to the difficulty of teleoperating a whole-body humanoid with high-dimensional, contact-rich manipulation. These suboptimal intervention trajectories can mislead learning if treated as expert data. To tackle this, the authors present ROVE, a reinforcement learning framework that integrates a human-in-the-loop data collection system capturing mixed-quality human interventions, an Optimistic Value Estimation (OVE) method to prioritize high-value behaviors despite noisy data, and cross-embodiment human video experiences to enhance value function learning. Evaluations on two real-world humanoid manipulation tasks (putting bread in a toaster and erasing a whiteboard) show that ROVE outperforms supervised fine-tuning, imitation learning baselines, and prior experience-learning algorithms. Furthermore, ROVE demonstrates consistent improvement over multiple rollout-intervention iterations, illustrating its robust closed-loop policy refinement from imperfect human corrections.
Key findings
- ROVE improves success rate on 'Erase the whiteboard' from 45.0% to 80.0% over three rollout-intervention iterations.
- On 'Put the bread into the toaster', success increases from 56.7% to 86.7% across three iterations with ROVE.
- ROVE outperforms supervised fine-tuning (SFT) trained on demonstration-only data on both tasks.
- ROVE achieves higher average success compared to baselines HG-DAgger, Filtered BC, and RECAP in experience-learning settings.
- Optimistic Value Estimation produces sharper, more discriminative value functions than Monte-Carlo estimation, more accurately differentiating failure and recovery states (Fig. 6).
- Incorporating cross-embodiment human experience videos helps the critic to assign lower values to incomplete task states and better reflect progress (Fig. 5).
- Human teleoperation during intervention exhibits transient adaptation behavior causing noisy suboptimal data, which ROVE handles via stage-aware trajectory decomposition.
- HG-DAgger baseline performs worse than demonstration-only policies, due to imitating suboptimal intervention actions.
Threat model
n/a — This is not a security paper. The adversarial challenge addressed is primarily noisy, suboptimal human teleoperation data during intervention, which can mislead learning algorithms if assumed to be expert. The system assumes no malicious actors but deals with imperfect human supervisory signals in a complex embodiment.
Methodology — deep read
The paper tackles improving humanoid robot VLA policies post-training by learning from mixed-quality human interventions. The methodology has several key components:
Threat Model & Assumptions: The adversary is not relevant here, but the central challenge is that human teleoperation interventions are imperfect, noisy, and suboptimal due to robot complexity, teleoperation gap, and lack of tactile feedback. The system assumes access to pre-trained VLA policies, human intervention episodes collected via teleoperation in deployment, and human egocentric videos unrelated to the robot embodiment.
Data Collection: The authors build a human-in-the-loop intervention pipeline for whole-body humanoid teleoperation using a VR headset and motion capture to map operator whole-body and dexterous hand poses to robot control. Each episode starts with autonomous rollout by the VLA policy. On detecting near-failure by supervisor, the robot pauses and the human operator intervenes to recover and complete the task. The intervention episodes are segmented into three stages: (1) Autonomous rollout, (2) Intervention-adaptation phase (initial unstable takeover with hesitant, noisy actions), and (3) Intervention-recovery phase (steady corrective actions until task completion). They collect data from two real-world object manipulation tasks characterized by contact-rich and fine-grained dexterous manipulation. To increase data diversity, task initialization also occurs at intermediate progress stages.
Reward Design: A reward scheme penalizes failure heavily at episode end and at the end of adaptation stage, while intermediate steps have a -1 time penalty. Success receives 0 at terminal step. Discount factor γ=1 is used to encode time-to-completion.
Value Function Training: They first pretrain a state-value critic Vϕ on large-scale heterogeneous robot and human egocentric datasets using a Monte-Carlo regression fitting the discounted return per state. This generalizes knowledge of task progress.
For fine-tuning on deployment data, they introduce Optimistic Value Estimation (OVE), combining H-step temporal-difference bootstrapping with expectile regression loss controlled by parameter τ. Expectile loss emphasizes fitting to higher-value outcomes in mixed-quality data rather than averaging, thus learning optimistic value estimates of recoverable behaviors from noisy suboptimal intervention and rollout data. The critic also incorporates cross-embodiment human experience videos to improve estimation on difficult state regions with sparse robot experience.
Policy Improvement: The VLA actor is trained with advantage conditioning using advantage labels derived from the learned critic. The policy is fine-tuned iteratively, alternating between data collection, critic update, advantage computation, and actor update. They add state dropout and perturbation during training to make actor more robust to brittle proprioceptive inputs.
Implementation: Experiments use the IRON-R01-1.11 humanoid robot with a 50-dimensional proprioceptive state and action space covering joints and fingers. Training occurs offline with multiple iterations of rollout-intervention data.
Evaluation Protocol: Success rate on real-world tasks is the primary metric. Baselines include supervised fine-tuning on demonstrations, imitation learning (Filtered BC, HG-DAgger), and reinforcement learning baselines (RECAP). Ablations compare value estimators (MC vs OVE), effect of human experience videos, and multiple rollout-intervention iterations for closed-loop improvement.
Reproducibility: Paper references open-source datasets for egocentric human videos, but robot intervention datasets and codebase status are not clearly stated. Hyperparameters are described in appendices but not fully detailed in main text.
Technical innovations
- Design of a human-in-the-loop teleoperation pipeline enabling whole-body and dexterous hand interventions on real-world humanoid robots.
- Introduction of Optimistic Value Estimation (OVE), combining multi-step temporal difference learning with expectile regression to selectively prioritize high-value recoverable behaviors from mixed-quality human-robot data.
- Cross-embodiment learning by integrating human egocentric experience videos as supervision to enrich value function estimation on rare failure and recovery states.
- Stage-aware intervention trajectory decomposition into rollout, adaptation, and recovery phases to properly assign value labels and mitigate noisy early intervention data during teleoperation takeover.
- Advantage-conditioned policy training that leverages critic-derived advantage signals to guide the VLA actor towards high-value actions instead of uniform imitation.
Datasets
- Robot teleoperation and rollout data — size not explicitly stated — collected on real-world humanoid robot tasks (Bread in toaster, Whiteboard erase).
- Large-scale robot and egocentric human demonstration dataset — from EgoDex [10] — size not specified.
- Cross-embodiment human experience videos — from publicly available egocentric human datasets — detailed source not explicitly stated.
Baselines vs proposed
- Supervised Fine-Tuning (SFT) on demos: Success rate on Erase 40-50% vs ROVE 80% after 3 iterations.
- SFT (more demos): lower than ROVE with rollout-intervention data.
- HG-DAgger imitation learning: below base demo-only policy on one task; exhibits hesitant behavior.
- Filtered Behavior Cloning (BC): performance worse than ROVE, indicating RL-style advantage conditioning adds gains.
- RECAP experience-learning: performance gap remains vs ROVE, attributed to critic quality and advantage assignment.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.17011.
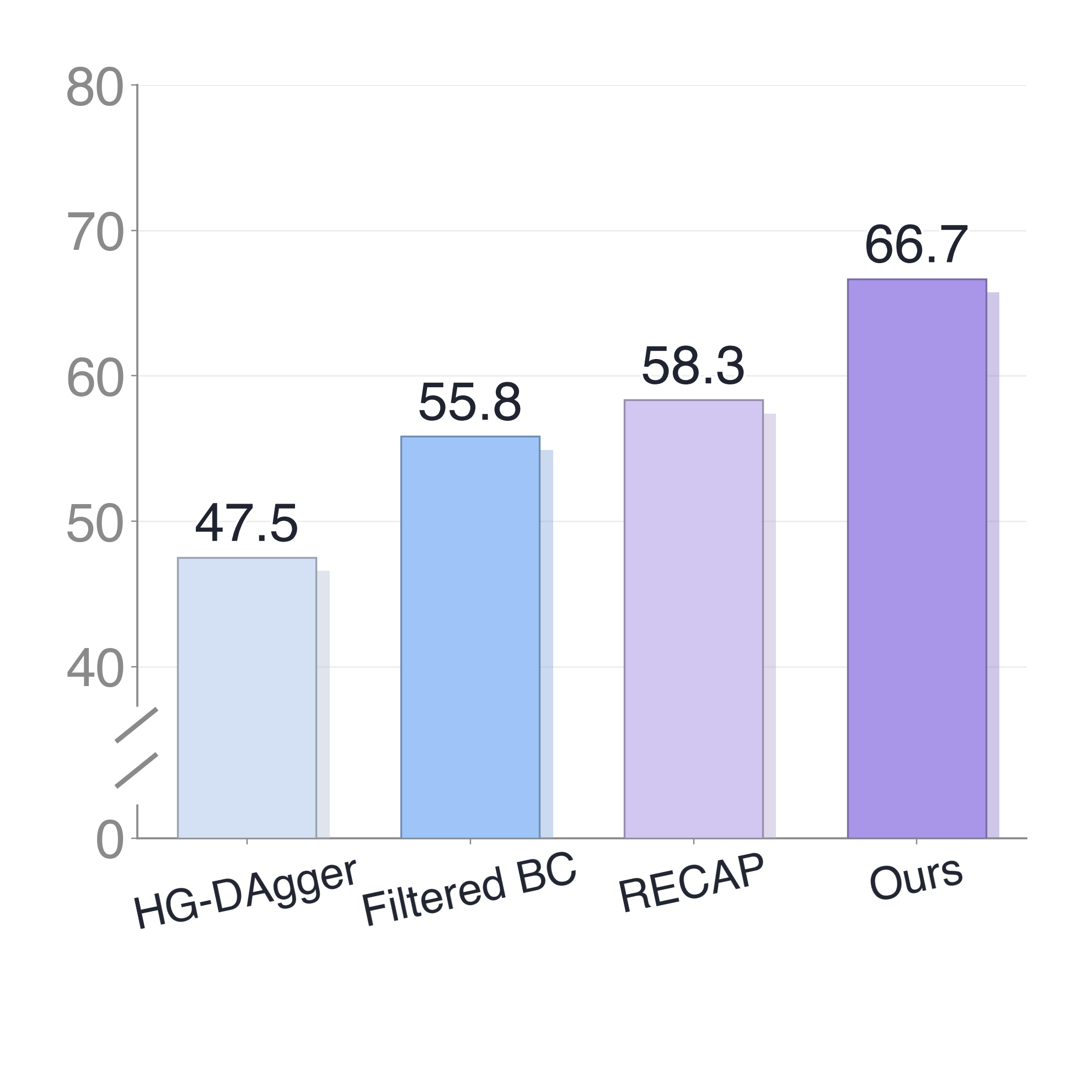
Fig 1: ROVE learns from imperfect humanoid interventions. (Left) Our method recovers
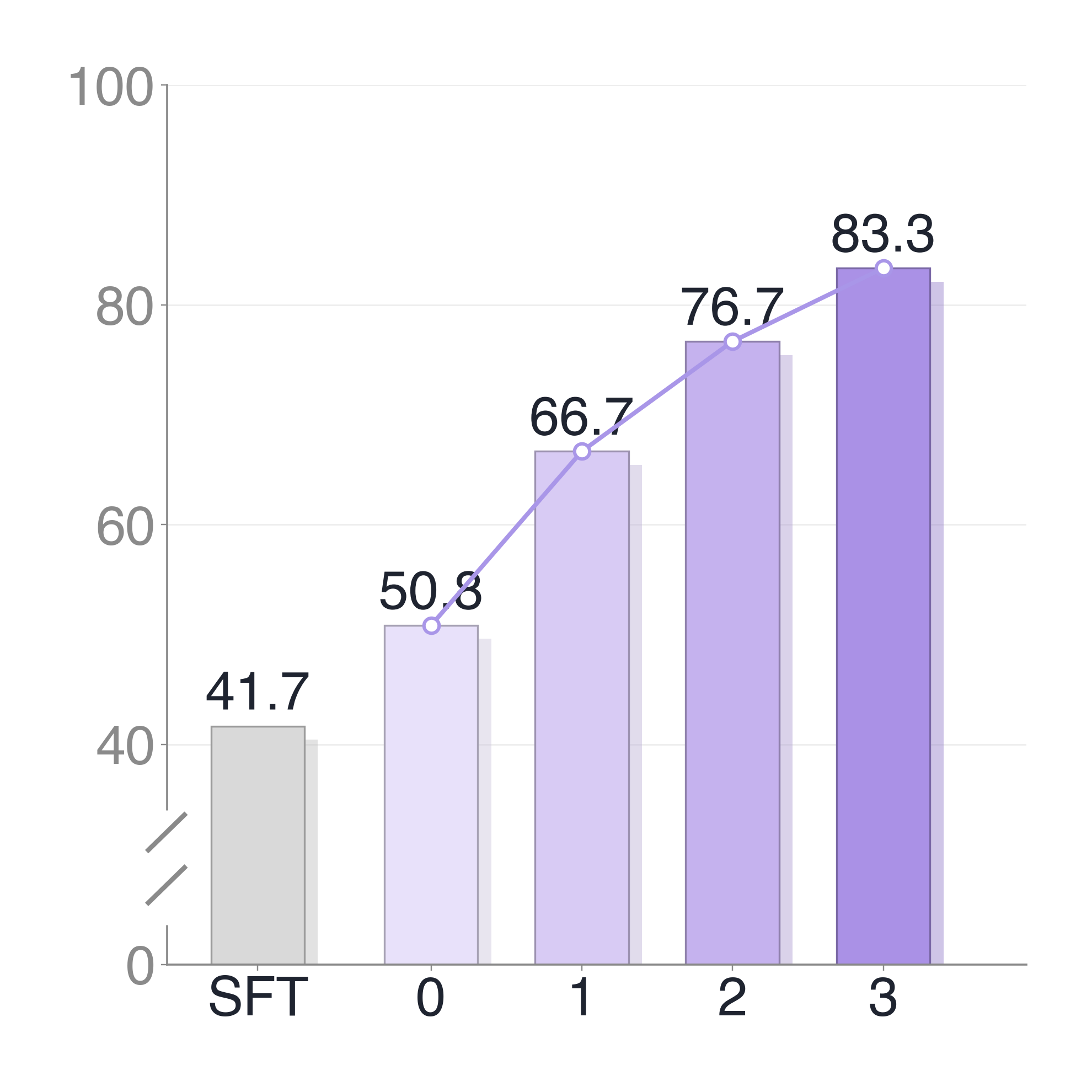
Fig 2: Task procedures for Put the bread into the toaster (top) and Erase the whiteboard (bottom).

Fig 3: summarizes the overall ROVE framework. The method first collects mixed-quality real-world

Fig 4 (page 1).

Fig 5 (page 1).

Fig 6 (page 1).

Fig 7 (page 1).

Fig 8 (page 1).
Limitations
- Human experience videos are only used for critic training, not for direct policy learning or representation-level supervision.
- No end-effector sensing (e.g., wrist cameras, tactile feedback) limits precision manipulation and may affect generalization.
- Current approach is offline or iterative offline RL; not yet extended to online RL requiring stable and efficient deployment-time updates.
- Only two manipulation tasks studied; broader task diversity and locomotion integration remain future work.
- Teleoperation suboptimality is mitigated but not eliminated, potentially limiting ultimate policy performance.
- Details on code and datasets release for full reproducibility are unclear.
Open questions / follow-ons
- How can human experience videos be integrated more directly into policy learning, for example via representation learning or imitation?
- Can ROVE be extended to online RL with stable, real-time policy updates during deployment?
- How does the framework scale to tasks involving locomotion combined with manipulation requiring safe, whole-body interventions?
- What are the effects of adding richer sensing modalities like tactile or vision on intervention quality and policy learning?
Why it matters for bot defense
While this work focuses on humanoid robot manipulation, the core challenges of learning from imperfect, noisy human interventions and mixed-quality data are highly relevant to bot-defense and CAPTCHA systems that receive human signals or demonstrations under uncertain quality. The optimistic value estimation approach may inspire new methods to robustly learn from human-in-the-loop inputs where data quality varies or is partially erroneous. Additionally, the use of cross-embodiment supervision suggests leveraging heterogeneous human behavioral data to improve robustness in learning or recognition models. Engineering a seamless human-in-the-loop data pipeline with careful definition of intervention phases can help marketing CAPTCHA systems better filter and refine human responses for improved bot detection or challenge adaptation. However, the complex teleoperation gap and proprioception-specific challenges highlight that human signal quality must be critically accounted for rather than naively treated as ground truth. Practitioners should consider stage-aware labeling and value-driven filtering of human corrections or answers to avoid absorbing subtle human errors into their defense models.
Cite
@article{arxiv2606_17011,
title={ ROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning },
author={ Wei Xiao and Weiliang Tang and Yuying Ge and Hui Zhou and Yao Mu and Li Zhang and Yixiao Ge },
journal={arXiv preprint arXiv:2606.17011},
year={ 2026 },
url={https://arxiv.org/abs/2606.17011}
}