
Learning the Geometry of Data: A Mathematical Review of Shape Space Analysis
Source: arXiv:2606.17022 · Published 2026-06-15 · By Gary P. T. Choi, Khanh Dao Duc, Shira Faigenbaum-Golovin, Karen Habermann, Emmanuel Hartman, Christoph von Tycowicz et al.
TL;DR
This survey paper addresses the emerging field of shape space analysis, a mathematical and computational framework for studying datasets whose observations have intrinsic geometric structure. Unlike traditional machine learning approaches, which often treat data as vectors in Euclidean spaces, shape space analysis explicitly models complex nonlinear geometric variations and subtleties across collections of shapes. It synthesizes methods from differential geometry, statistics, and machine learning to characterize shape variability, compare shapes, and analyze shape trajectories over populations and time. The paper systematically organizes the literature into stages—shape representation and parameterization, metrics, statistical analysis, and geometry-aware learning techniques—while illustrating the breadth of applications from subcellular morphology to primate tooth evolution. By highlighting common challenges like alignment, subtle geometric differences, and limited labeled data, the review offers a unified language and practical roadmap for researchers transitioning to geometry-aware domains. The results emphasize that leveraging entire shape collections with appropriate geometric tools yields more robust structural insights than traditional single-object analysis or classical ML that neglects geometry.
Key findings
- Shape space analysis explicitly accounts for nonlinear geometric variability often overlooked by traditional ML models.
- Implicit shape representations generalize easily to arbitrary dimensions and topologies but lack explicit geometry and point correspondences.
- Explicit representations (point clouds, meshes, graphs) provide direct geometric indexing and alignment but face complexity in topology changes and scalability.
- Geometric learning frameworks outperform standard ML methods particularly in low-label and local-variation sensitive biological shape datasets.
- Collections of shapes, analyzed as manifolds with robust distance metrics, enable detecting subtle biologically meaningful differences missed by Euclidean approaches.
- Popular shape acquisition techniques span contact (e.g., histology) and non-contact methods (e.g., MRI, LIDAR), producing data in multiple implicit and explicit formats.
- Transforming among shape representations (e.g., voxel to mesh to graph) supports flexible processing pipelines adapted to analysis tasks.
- The paper identifies conceptual fragmentation across disciplines which shape space analysis aims to unify with a common mathematical framework.
Methodology — deep read
Threat model & assumptions: The paper is a survey and does not propose a security threat model. Instead, it assumes researchers are working with data representing collections of shapes exhibiting complex geometric variability. Adversarial concerns are indirect, concerning challenges in shape alignment, data noise, and limited labeled data.
Data: The survey covers diverse shape datasets from biology, medicine, anthropology, and computer vision. Data types include subcellular morphologies, ribosomal structures, primate teeth, anatomical scans, etc. Acquisition methods include contact (histology, electron microscopy) and non-contact (MRI, CT, LIDAR) technologies. Resulting data formats include implicit representations like occupancy maps and signed distance functions, as well as explicit formats like point clouds, meshes, and graphs representing shape boundaries or structures.
Architecture/algorithm: The survey reviews various mathematical and computational frameworks including shape parameterizations, distance metrics (geodesic distances on manifolds), registration and alignment algorithms for correspondence, statistical shape analysis (means, modes of variation), and geometry-aware learning approaches extending classical ML to Riemannian manifolds or graph neural networks. It dissects advantages and disadvantages of implicit vs. explicit representations and discusses the significance of shape-space geometry for meaningful comparison.
Training regime: As a broad survey, specifics of training regimes for particular ML models are cited from literature but not specified in one protocol. The paper emphasizes challenges posed by scarce labeled data and highlights transfer learning and model-based geometric inference as partial solutions.
Evaluation protocol: The review stresses the importance of controlled experiments, case studies, and benchmarks to validate shape analysis pipelines. It discusses inherent difficulties of evaluation due to subtle shape differences, alignment complexity, and lack of ground truth labeling. Datasets with known biological or functional correlations serve as validation, e.g., correlation between ribosome shape and biological function.
Reproducibility: The paper catalogs publicly available datasets and software tools for shape analysis encouraging reproducibility. However, it notes that many biological shape datasets are rare or limited in size. Some shape analysis toolkits are open source, but availability and standardization remain challenges.
Concrete example end-to-end: For instance, in the study of ribosome shape evolution, volumetric acquisition via electron microscopy yields segmented 3D shapes represented as meshes. Registration and alignment establish correspondences. Geodesic distance metrics capture shape differences invariant to translation, rotation, and scaling. Statistical analysis of shape distributions reveals evolutionary trajectories associated with functional complexity. Geometry-aware machine learning models classify shapes with higher accuracy than vanilla methods ignoring shape manifold structure.
Technical innovations
- A unified analytical pipeline synthesizing differential geometry, statistics, and machine learning tailored to shape space analysis.
- Comprehensive taxonomy and critical comparison of implicit and explicit shape representations for diverse applications.
- Geometry-aware machine learning frameworks extending classical models to Riemannian manifolds and graph-based shape representations.
- Practical guidelines and protocols for preprocessing, alignment, parameterization, metric selection, and statistical inference on shape collections.
Datasets
- Ribosome structures — size variable — public protein structural databases
- Primate dental morphology — mid-size collections — specialized evolutionary biology repositories
- Medical imaging shape datasets (brain scans, mycobacteria, cancer cells) — variable size — public and proprietary sources
- Fruit fly wings and archaeological artifacts (bones, flints) — small to medium size — domain-specific collections
Baselines vs proposed
- Classical Euclidean ML models: classification accuracy significantly lower versus geometry-aware learning frameworks particularly on low-label biological shape data (quantitative deltas not explicitly detailed).
- Implicit representations: scalable to high dimension and arbitrary topology but demonstrate weak direct geometric interpretability compared to explicit mesh/graph methods in shape comparison tasks.
- Explicit representations: enable intuitive shape similarity interpolation and meaningful correspondence, outperforming implicit methods in detailed shape alignment benchmarks.
- Geometry-aware statistical models achieve better sensitivity to subtle shape variations than classical morphometrics, validated in biological case studies.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.17022.
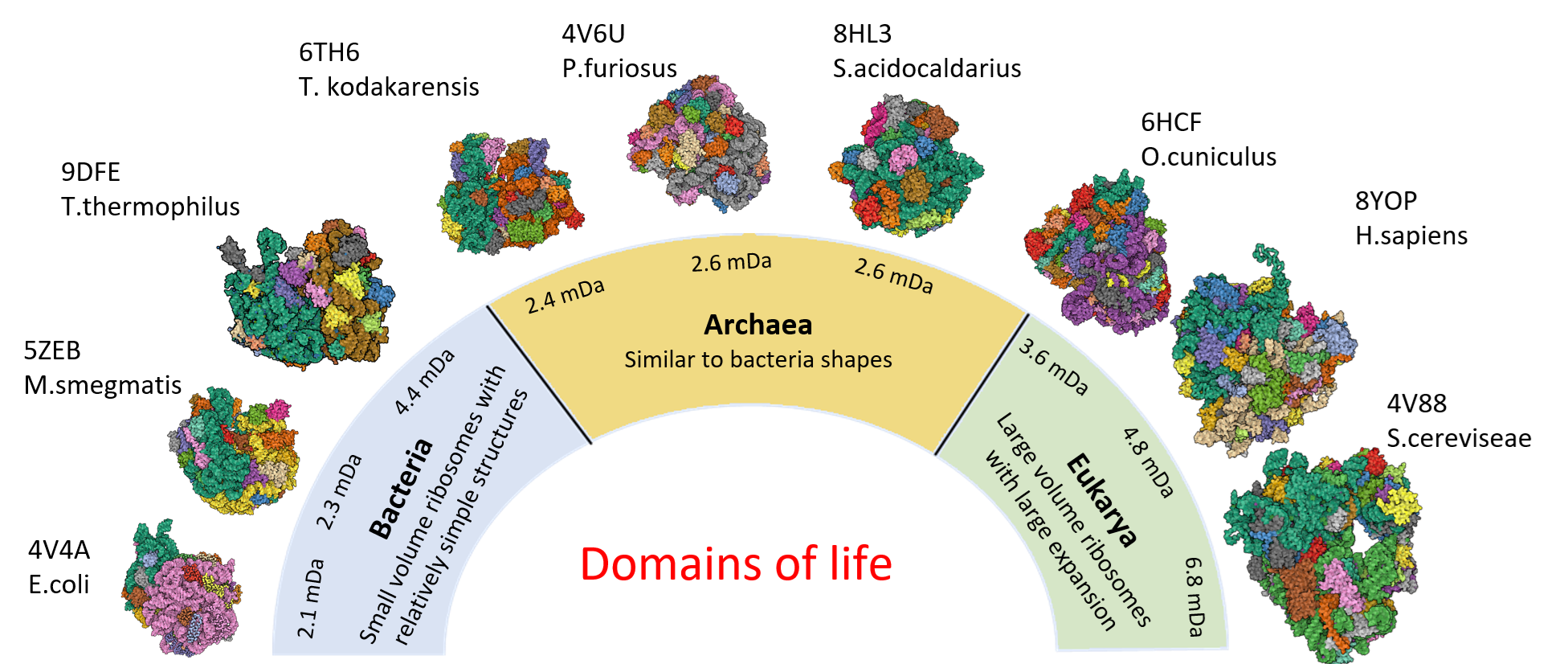
Fig 1: Form is function – the ribosome shape space. Inspired by the concept of Kendall’s shape space [246],
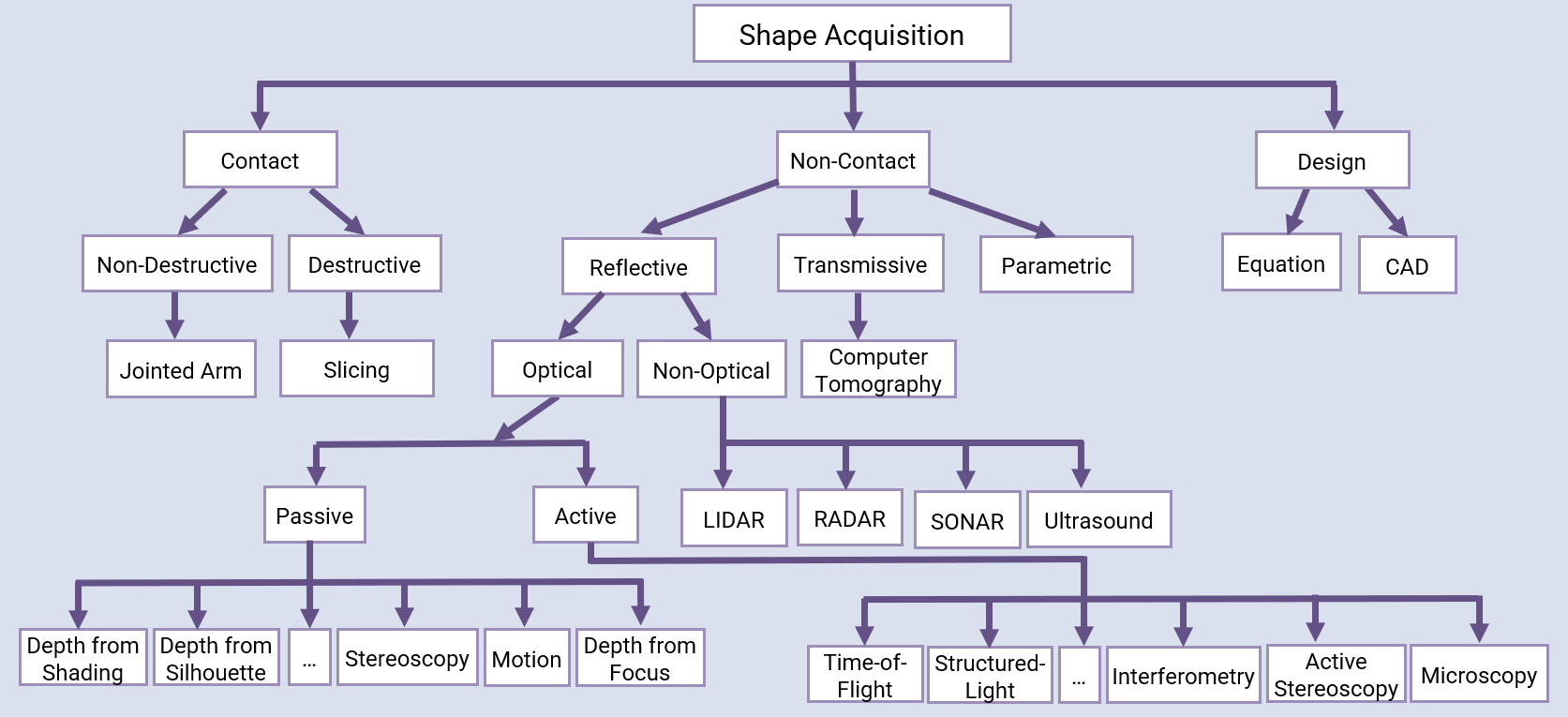
Fig 2: Taxonomy of shape acquisition technologies adapted from [163].
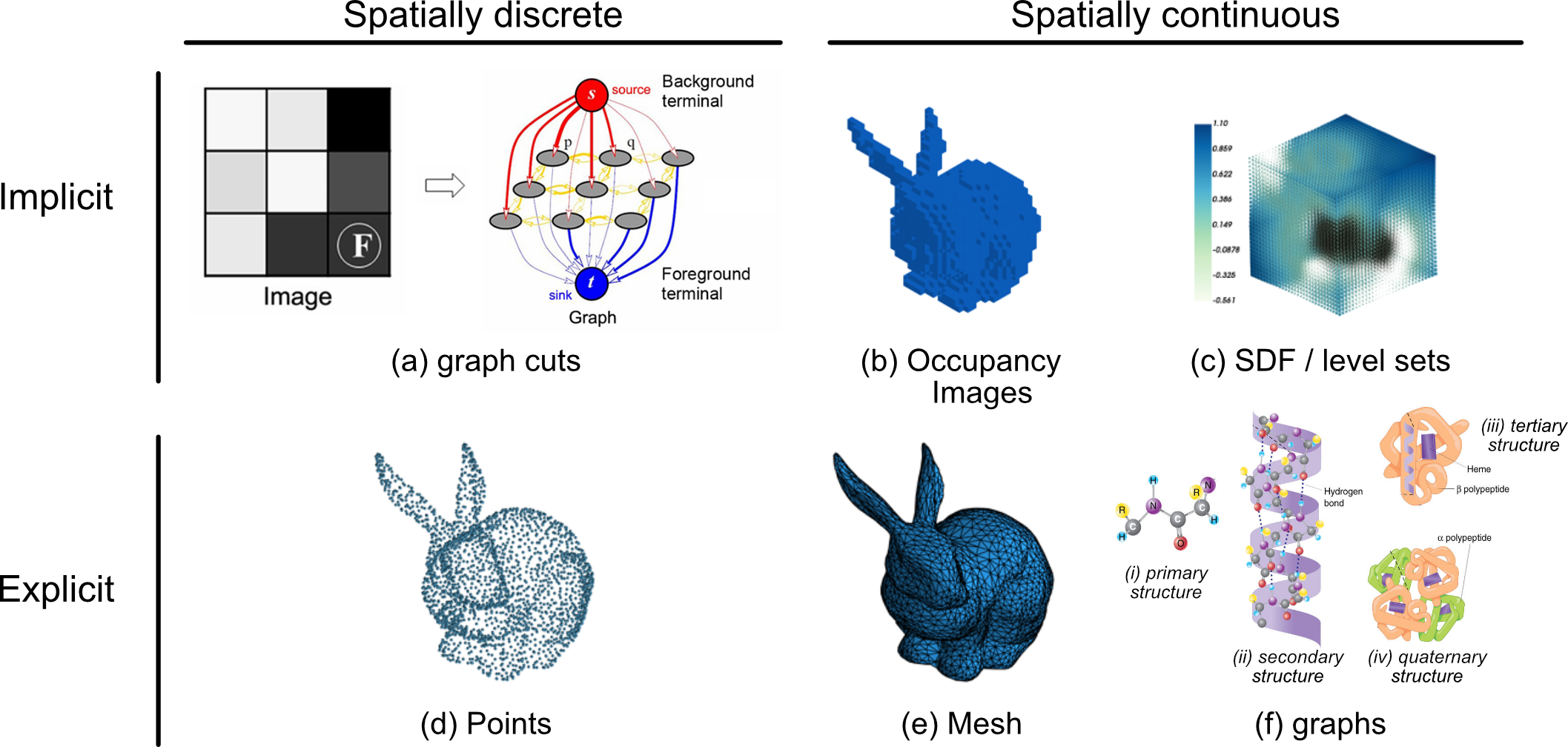
Fig 3: Commonly occurring digital formats representing 3D shape implicitly (by interior) or explicitly (by
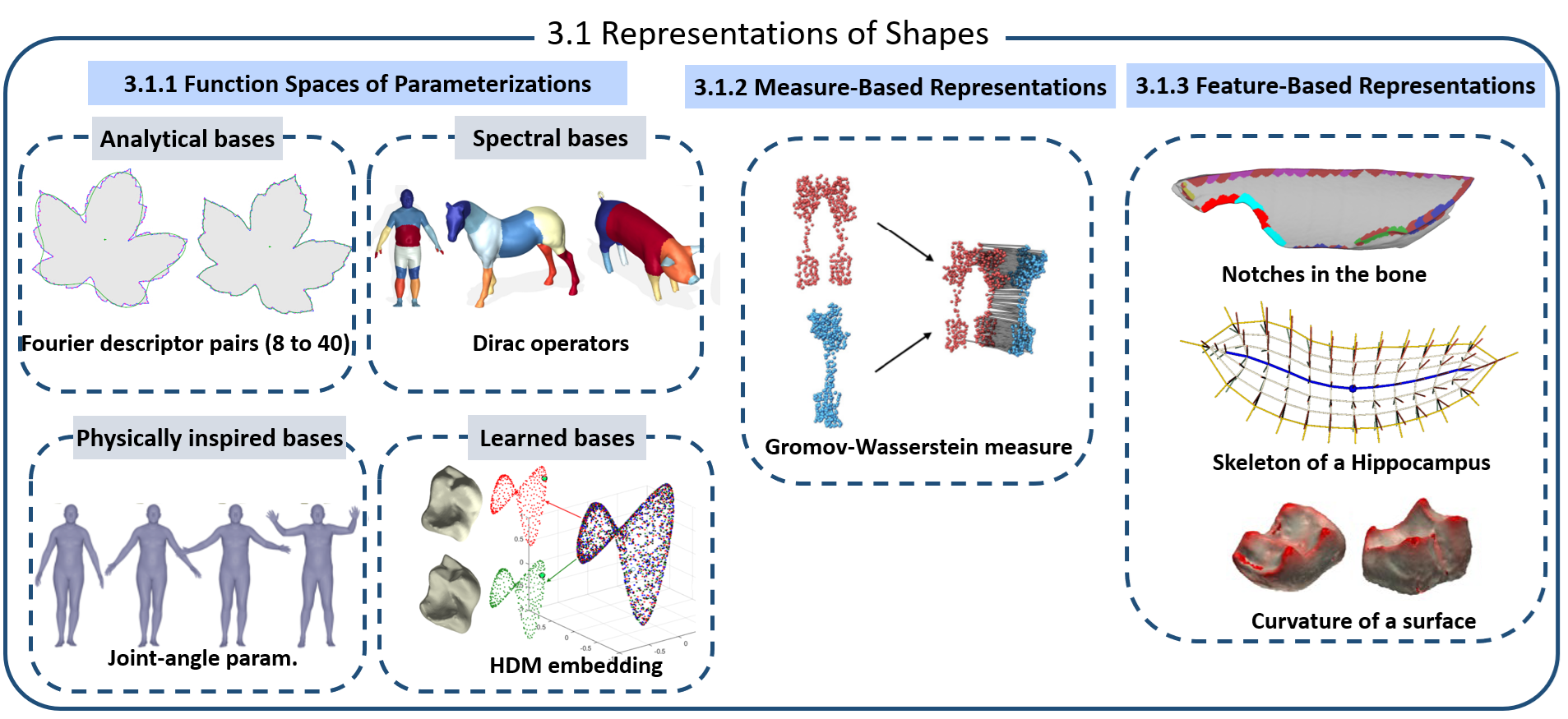
Fig 4: Key ideas in Representations of Shapes as discussed in Section 3.1. Specifically, we discuss the Function
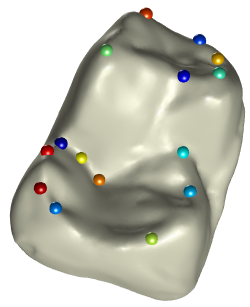
Fig 5: Landmarking in different applications and different data representations (3D surfaces and images).
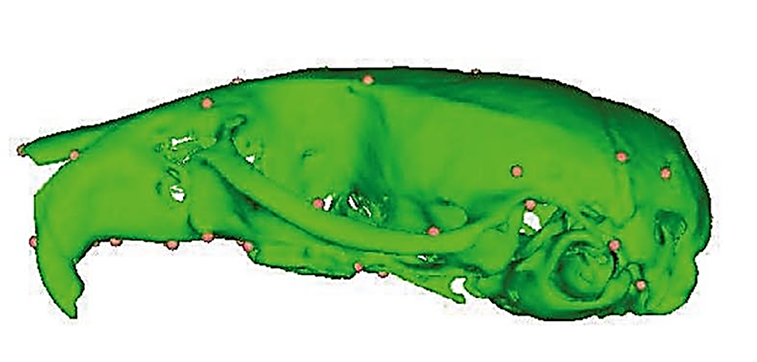
Fig 6 (page 15).
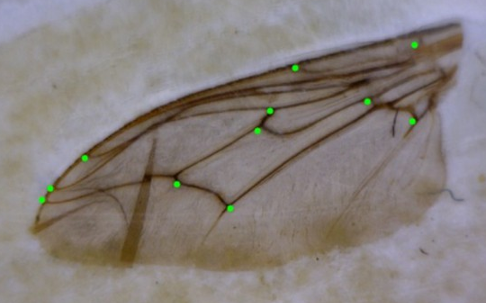
Fig 7 (page 15).
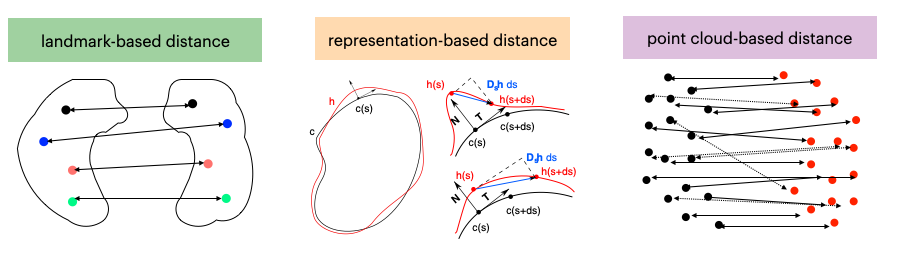
Fig 6: Illustration of distances between shapes depending on the data type. The distances can typically be
Limitations
- The field faces limited availability of large-scale labeled shape datasets, restricting supervised learning methods.
- Evaluation protocols are challenged by lack of ground truth correspondence and subtle, domain-specific shape variations.
- Conversion between shape representations can introduce errors or lose information, complicating pipeline design.
- Current geometry-aware machine learning is limited by computational complexity and scalability to very large shape collections.
- The survey acknowledges potential omissions given the rapid growth and disciplinary fragmentation of shape space research.
Open questions / follow-ons
- How to design robust, invariant metrics that are sensitive enough to detect functionally relevant subtle shape differences?
- What are scalable machine learning architectures that best leverage manifold and graph structures inherent in shape spaces?
- How to standardize benchmarking datasets and evaluation metrics across diverse domains of shape analysis?
- How to effectively integrate multi-scale shape representations from atomic to organism-level for comprehensive analysis?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this survey is valuable in understanding how data with rich geometric structure can be more powerfully modeled by shape space analysis methods than by classical ML alone. Automated attacks may exploit subtle forms or structural patterns in graphical CAPTCHAs or behavioral biometrics with geometric constraints. Incorporating geometry-aware representations—such as manifold embeddings or graph-based models capturing shape relationships—can enhance robustness against adversarial mimicry and synthetic forgeries that alter superficial pixel values but not deep geometric form. However, given the high computational and methodological sophistication required, integrating shape space analysis demands interdisciplinary expertise and careful engineering. The survey’s emphasis on alignment, invariant metrics, and subtle structural variability offers insights for designing CAPTCHAs and bot defenses that resist automation by capitalizing on complex shape properties beyond raw image data. Finally, the identified challenges around limited labeled data and evaluation are relevant for bot-defense researchers pursuing security guarantees in evolving threat landscapes involving shape-based biometrics or puzzle-solving.
Cite
@article{arxiv2606_17022,
title={ Learning the Geometry of Data: A Mathematical Review of Shape Space Analysis },
author={ Gary P. T. Choi and Khanh Dao Duc and Shira Faigenbaum-Golovin and Karen Habermann and Emmanuel Hartman and Christoph von Tycowicz and Chi Zhang and Wenjun Zhao and Felix Zhou },
journal={arXiv preprint arXiv:2606.17022},
year={ 2026 },
url={https://arxiv.org/abs/2606.17022}
}