
LabOSBench: Benchmarking Computer Use Agents for Scientific Instrument Control
Source: arXiv:2606.16802 · Published 2026-06-15 · By Anqi Zou, Han Deng, Chengyu Zhang, Junquan Hu, Yu Wang, Yuxiang Xing et al.
TL;DR
LabOSBench addresses the challenge of evaluating computer-use AI agents on scientific instrument GUIs, where controlling sophisticated devices involves complex, procedural, feedback-driven workflows. Existing benchmarks focus on general software or web navigation tasks and rely on costly OS virtualization or physical hardware that is expensive, risky, and not reproducible. LabOSBench introduces a lightweight, web-browser based simulation platform covering eight different scientific instruments and 96 realistic subtasks spanning workflows from sample loading, alignment, parameter tuning, data acquisition, to result inspection. This facilitates scalable, safe, and reproducible evaluation of multimodal agents interacting via natural language instructions and visual observations directly through the GUI.
The benchmark evaluates multiple strong general-purpose vision-language models (e.g., GPT-5.5, Claude Sonnet), specialized GUI agents (UI-TARS, GUI-Owl), and agentic frameworks that integrate planning, feedback, and recovery (e.g., GTA1 w/ GPT-5.5). Results reveal that although many structured subtasks can be completed, current agents generally struggle with tasks requiring feedback-driven scientific state interpretation, closed-loop parameter adjustment, and long-horizon workflows, especially for instruments like FIB and LFM. The end-to-end success rates on workflows average only 26.3%, indicating error accumulation and recovery remain major challenges. Detailed subtask-level metrics and scientific-state quality measures (e.g., PSNR for SEM focus) demonstrate gaps in visual grounding and domain-specific reasoning. Overall, LabOSBench provides a critical, reproducible platform exposing key challenges for autonomously controlling complex scientific instruments through GUIs.
Key findings
- LabOSBench includes 96 subtasks distributed across eight scientific instrument simulators with realistic workflows covering sample preparation, alignment, parameter tuning, data acquisition, and post-processing (Fig. 3).
- In subtask-level evaluation, success rates for general-purpose models range from 25% to 82%, with Seed-1.6 achieving the highest average score of 0.763 and GPT-5.5 scoring 0.726 (Table 1).
- Agentic frameworks improve overall performance, with GTA1 w/ GPT-5.5 obtaining the highest average subtask success rate of 0.814, outperforming general models by ~5 percentage points.
- Certain instruments like FIB and LFM are more difficult due to long workflows and feedback-driven visual state interpretation, showing the lowest subtask success rates (e.g., FIB average ~0.275-0.65) and large human-model gaps (Fig. 4).
- Scientific-state understanding is critical: for the SEM focus-adjustment subtask, GPT-5.5 reaches the highest focus success rate and best PSNR (Fig. 6), highlighting LabOSBench's ability to measure intermediate scientific outcomes rather than just discrete action correctness.
- End-to-end workflow completion success rates are drastically lower than subtask-level scores, with GPT-5.5 achieving only 26.3% average success over full instrument workflows, reflecting cumulative error and recovery challenges.
- Specialized GUI models like UI-TARS-1.5-7B show competence in widget localization and structured tasks but underperform on tasks requiring scientific visual reasoning and feedback control (Table 2).
- Agentic frameworks are effective only when their recovery and planning strategies align with instrument operation semantics; others (e.g., VLAA-GUI w/ Opus-4.5) suffer from invalid recovery and wrong actions.
Threat model
The adversary is an autonomous AI agent interacting solely through GUI controls on the web-based scientific instrument simulators, receiving visual and textual inputs without direct API or device-level access. The agent cannot manipulate hardware directly and operates in a non-adversarial, simulated environment designed primarily to test procedural reasoning, visual grounding, feedback-driven control, and error recovery capabilities.
Methodology — deep read
The paper's core is the design and evaluation of LabOSBench, a benchmark for multimodal agents controlling scientific instrument simulators via GUI.
Threat Model and Assumptions: The adversary is an AI agent acting autonomously on scientific instrument GUIs without direct API access; it receives natural-language instructions and screenshots. The agent must operate safely within the simulator constraints, without physical harm risk since simulation is virtual. No adversarial or malicious attacks are studied.
Data and Environment: LabOSBench uses eight high-fidelity web-based instrument simulators (SEM, TEM, XRD, FIB, SPM, LFM, EDS, APT) designed to emulate real scientific devices' GUI and control logic. The benchmark contains 96 subtasks reflecting realistic, multi-step workflows, decomposed from real lab procedures (e.g., sample loading, vacuum conditioning, parameter tuning). Each subtask has natural language instructions and defined success criteria.
Architecture and Algorithm: Evaluated agents are diverse multimodal computer-use agents, taking textual task prompts and GUI screenshots as input, producing GUI actions (mouse click, drag, type, select, etc). Models include general vision-language models (Qwen3VL-32B, GPT-5.5, Seed-1.6), specialized GUI-focused transformers (UI-TARS-1.5-7B, GUI-Owl-7B), and agentic frameworks integrating planning and recovery loops (GTA1 with GPT-5.5).
Agents operate in a step-by-step interaction loop: observe GUI screenshot + instruction, output an executable GUI action, receive updated GUI state. The unified interaction protocol abstracts common desktop/browser controls. Agentic frameworks incorporate additional reasoning/planning modules controlling multiple agent calls.
Training Regime: The evaluated agents are pretrained foundation models and frameworks; no end-to-end retraining on LabOSBench data is reported. Evaluation runs repeated each model-subtask pair twice for statistical robustness.
Evaluation Protocol: Two modes—subtask-level evaluation initializes the simulator in the pre-subtask state, allowing isolation of individual capability (e.g., widget selection, parameter adjustment). Full-episode evaluation requires completing entire workflows within step limits. Metrics: subtask success rate (binary completion), episode success, task completion within step budgets. Additional metrics are domain-specific, e.g., PSNR for SEM image quality. Aggregation is by averaging over subtasks and runs.
Reproducibility: LabOSBench is implemented as browser-based simulators executable via Playwright, avoiding heavy virtualization, enabling low-cost and reproducible benchmarking. The paper links to a project website containing code, benchmark documentation, task definitions, and evaluation results. Data is synthetic and fully public via web simulations.
Concrete example: For the XRD instrument, subtasks include specimen selection from dropdown, chamber loading, power-up, angle setting, scan running, and saving results (Table 3). An agent receives instructions and GUI screenshots, navigates menus, selects parameters, clicks buttons, and completes the scan. Success is measured by the correct sequence of actions verified by simulator state checks.
This evaluation reveals capabilities and failure modes of state-of-the-art AI agents across structured and feedback-driven scientific GUI control.
Technical innovations
- Development of LabOSBench, a scalable, browser-based benchmark with 96 subtasks simulating eight complex scientific instruments, supporting realistic GUI interactions without heavy virtualization.
- Task decomposition into operational subtasks aligned with real laboratory workflows, enabling interpretable subtask- and full-episode-level evaluation of multimodal agents.
- Integration of scientific-state metrics, such as PSNR for SEM image focus evaluation, allowing assessment beyond binary action completion toward meaningful scientific output quality.
- Comprehensive evaluation of diverse agent families—general vision-language models, specialized GUI transformers, and agentic planning frameworks—highlighting distinct strengths and limitations in scientific instrument control.
Datasets
- LabOSBench simulated instrument tasks — 96 subtasks across 8 scientific instrument simulators — synthetic web-based simulations
Baselines vs proposed
- Seed-1.6: average subtask success rate = 0.763 vs GTA1 w/ GPT-5.5 (agentic) = 0.814
- GPT-5.5: average subtask success rate = 0.726 vs UI-TARS-1.5-7B (specialized GUI) = 0.659
- VLAA-GUI w/ Opus-4.5: average subtask success rate = 0.456 vs Hippo Agent w/ Opus-4.5 = 0.658
- End-to-end GPT-5.5 workflow success rate = 26.3% vs subtask success rate = ~72.6% (Table 1, Fig. 4)
- SEM focus-adjustment PSNR and success highest for GPT-5.5 (Fig. 6)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.16802.
Fig 1: Overview of LabOSBench. The benchmark evaluates computer use agents on eight types of scientific

Fig 2: Evaluation infrastructure of LabOSBench. Each run is specified by command-line arguments, environment

Fig 3: Overview of scientific-instrument workflows and GUI task taxonomy in LabOSBench. The left panel
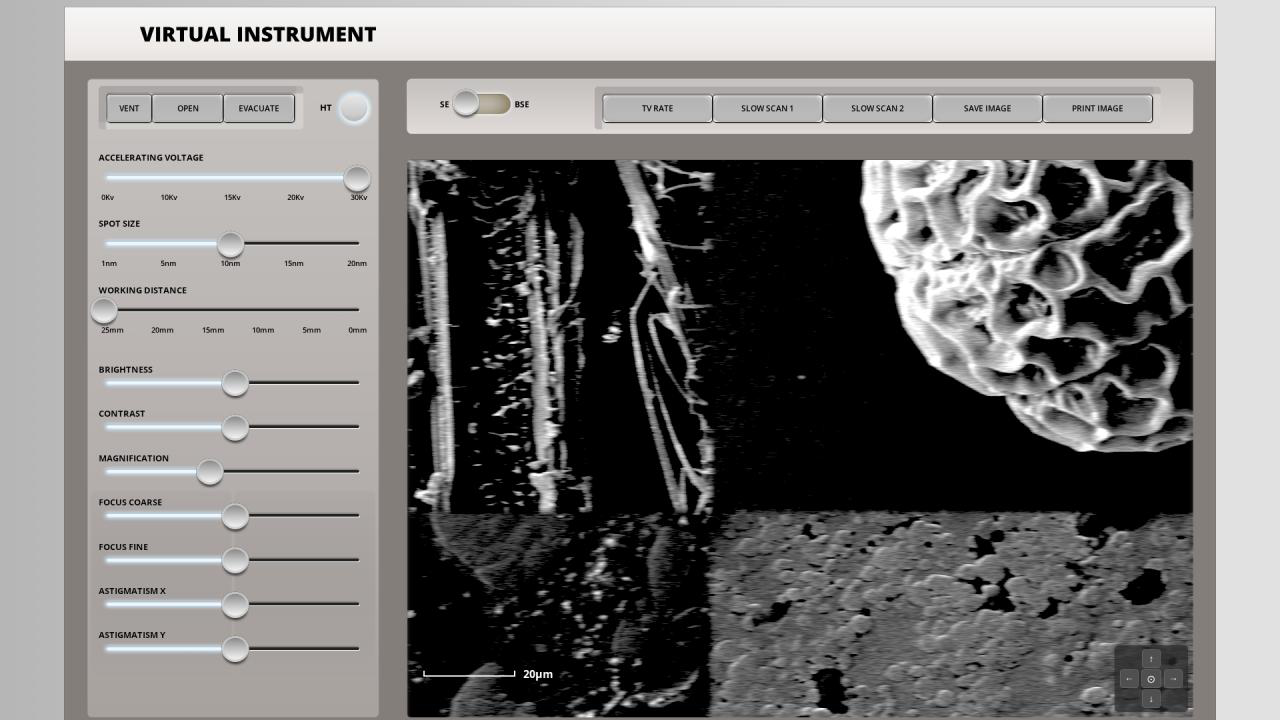
Fig 4 (page 4).
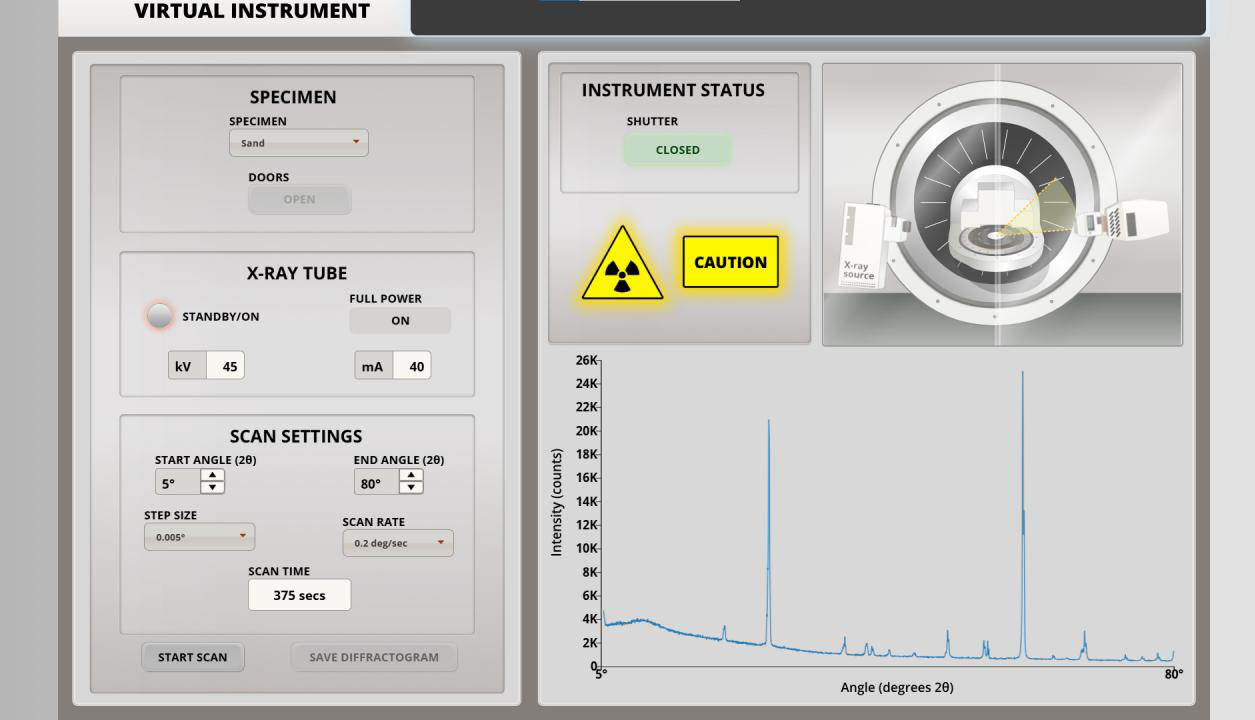
Fig 5 (page 4).
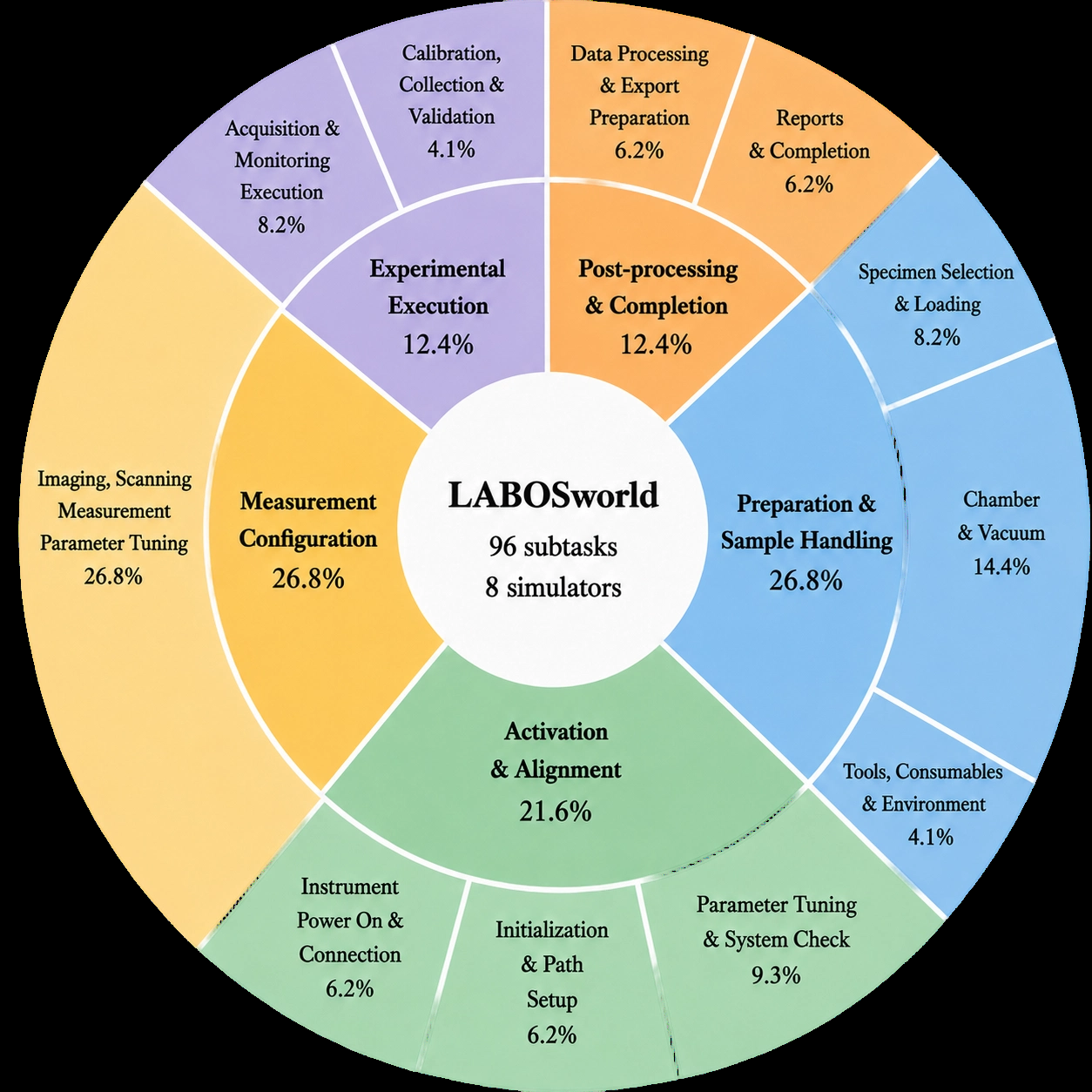
Fig 4: Instrument difficulty map of the eight scientific-instrument simulators in LabOSBench. The x-axis shows the
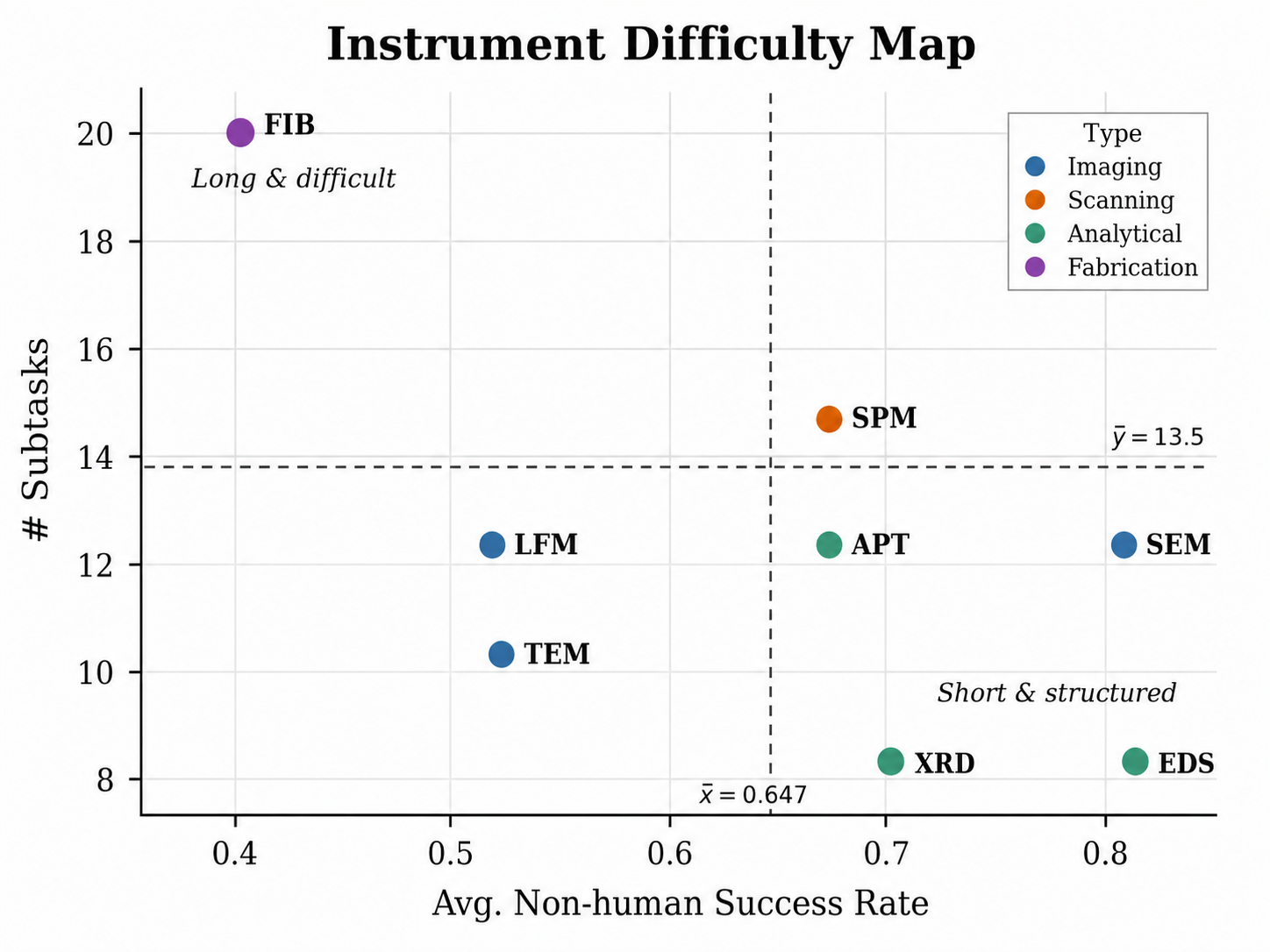
Fig 5: Qualitative comparison of final outputs on the SEM focus-adjustment task under the same task setting.
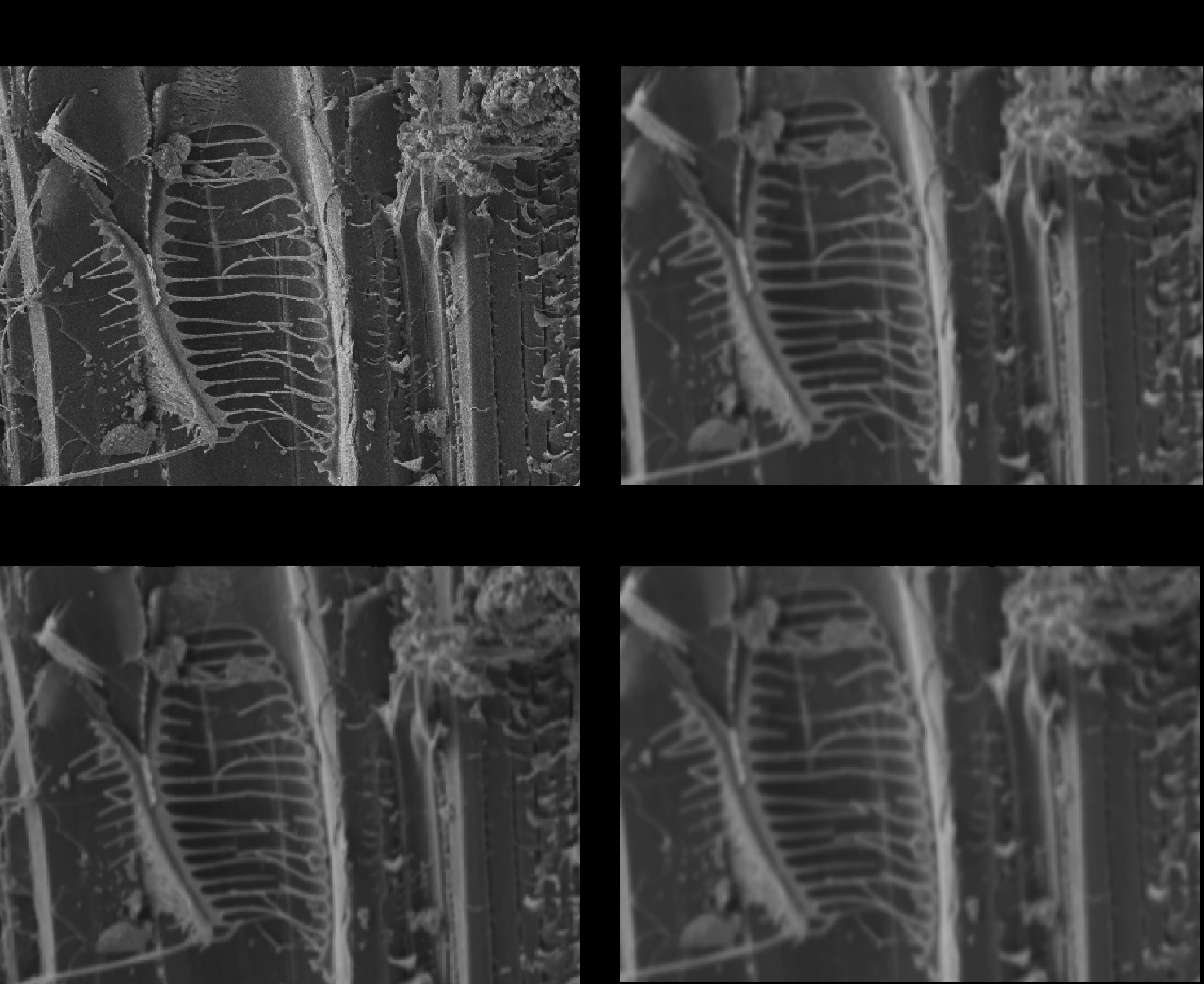
Fig 6: Scientific-state quality on the SEM focus-adjustment task. The two lines show best PSNR and focus success
Limitations
- LabOSBench relies on web-based simulators, lacking physical instrument nuances like hardware latency, calibration uncertainty, or safety-critical constraints.
- The benchmark covers only selected scientific instruments and workflows, omitting wet-lab protocols, robotic manipulation, chemical synthesis, and multi-instrument planning.
- Evaluation is based on screenshots and internal simulator states; richer multimodal signals or domain knowledge integration is not modeled.
- Social and safety risks of deploying autonomous agents on real scientific equipment are not addressed; LabOSBench is not designed for direct real-world control.
- End-to-end evaluation results are preliminary with limited runs and could benefit from larger-scale experiments or adversarial robustness testing.
Open questions / follow-ons
- How can agentic frameworks be improved to better interpret scientific-state feedback and recover from compounding errors in long workflows?
- What methods can enhance visual grounding and parameter tuning in dense, domain-specific GUI controls for scientific instruments?
- How could multimodal sensor fusion or richer domain knowledge be integrated to support more reliable autonomous scientific instrument operation?
- Can LabOSBench be extended to cover broader laboratory automation tasks like robotic manipulation and multi-instrument experimental planning?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on GUI or multimodal agent security, LabOSBench highlights the complexity that domain-specific scientific GUIs present to autonomous agents. Unlike general web navigation, scientific instrument GUIs require precise widget grounding, long-horizon procedural reasoning, and closed-loop feedback interpretation, illustrating the limits of current AI interaction capabilities.
This benchmark suggests that agents can often be reliably challenged in settings where tasks require stateful monitoring, continuous parameter adjustment, and scientific understanding beyond surface-level GUI manipulation. CAPTCHA or bot-defense systems designed to simulate similar complexities—e.g., procedural multi-step workflows with domain-specific controls and feedback—could more effectively resist general AI-driven automation. Therefore, LabOSBench serves as a case study in constructing richly interactive, feedback-dependent tasks that push the boundaries of autonomous GUI control.
Cite
@article{arxiv2606_16802,
title={ LabOSBench: Benchmarking Computer Use Agents for Scientific Instrument Control },
author={ Anqi Zou and Han Deng and Chengyu Zhang and Junquan Hu and Yu Wang and Yuxiang Xing and Aokai Zhang and Hanling Zhang and Zhaoyang Liu and Ben Fei and Zhihui Wang and Wanli Ouyang },
journal={arXiv preprint arXiv:2606.16802},
year={ 2026 },
url={https://arxiv.org/abs/2606.16802}
}