
Human Universal Grasping
Source: arXiv:2606.17054 · Published 2026-06-15 · By Kevin Yuanbo Wu, Tianxing Zhou, Isaac Tu, Billy Yan, Irmak Guzey, David Fouhey et al.
TL;DR
This paper addresses the gap between human dexterous grasping capabilities and multi-fingered robot grasping generality by directly learning from large-scale, in-the-wild human grasp data. The authors present HUG, a flow-matching model that predicts natural human grasp poses given a single RGB-D stereo image and a user-specified object point. Key innovation is training exclusively on a new egocentric dataset called 1M-HUGS, which has 1 million annotated human grasp frames over 6,707 object instances collected from 41 varied indoor environments using Aria Gen 2 smart glasses. The model outputs grasp parameters as wrist translation, rotation, and MANO hand articulation that can then be retargeted zero-shot to multiple robot hands. To evaluate, the authors introduce HUG-BENCH, a challenging benchmark of 90 unseen objects spanning diverse shapes and sizes, with metric-scale 3D meshes for simulation and real robot testing.
Experiments demonstrate HUG substantially outperforms prior state-of-the-art multi-finger grasping approaches (Dex1B, CAP) by large margins of +23% to +34% success on a 30-object held-out test set both on tabletop and in-the-wild robotic platforms. Ablations show the importance of fusing RGB and point cloud inputs and explicit 3D fingertip supervision. Extensive real-world trials with multiple robot embodiments confirm the framework’s strong generalization to novel environments, objects, and camera viewpoints without per-hand or per-scene retraining. Overall, this work showcases the effectiveness of leveraging large-scale natural human grasp data and novel flow-matching architectures to close the dexterous grasping gap for robots.
Key findings
- HUG achieves 66.7% success in real-world tabletop grasping on 30 unseen test objects, outperforming Dex1B (43.7%) and CAP (32.7%) by +23% and +34%, respectively.
- In-the-wild tests across multiple rooms and a different robot hand achieve 62.0% grasp success, only 4.7 points below controlled tabletop settings.
- Simulation success rates reach 73.0% on 30 test objects with the full RGB+PC model, within ~20 points of a human grasp oracle (94.0%).
- Removing the 3D geometric fingertip loss reduces test success from 73.0% to 32.7% and more than doubles fingertip contact error (14.6 mm to 35.7 mm), highlighting its critical role.
- Ablations show cropping the point cloud around the query point and using DINOv2 point painting contribute ~10-15% success rate gains each.
- RGB-only input yields only 29.7% test success and 108.6 mm fingertip error; PC-only gets 70.7% success and 22.1 mm error, showing complementary modalities.
- Scaling dataset size from 25K to 1M frames improves test success rate from 33% to 73%, indicating the model is data-bound at current scale.
- HUG successfully grasps large prismatic objects (storage bin 10/10) where baselines fail (0/10), and shows robustness across 5 geometric categories and 3 size bins.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly modeled as this is a robotic grasping learning paper rather than security-focused. The goal is generalization to unseen objects, environments, and robot hands with no per-embodiment training. Adversarial manipulation of sensors or objects is not considered.
Data: The core dataset 1M-HUGS is collected using Aria Gen 2 smart glasses capturing synchronized RGB, stereo grayscale, and calibrated depth alongside 3D hand landmarks. Data spans 6,707 recordings (>1.5K unique objects) across 41 buildings representing diverse indoor scenes. Each recording captures a user grasping an object, collecting both hands-visible and no-hand frames. Grasp pose is propagated to no-hand frames to generate many training pairs. Dataset size is 1 million RGB and 1 million grayscale frames after strict filtering for depth confidence, object masks, and hand visibility. Labels are MANO hand model fits to 21 hand landmarks, providing wrist translation, rotation, and detailed finger articulation.
Architecture/Algorithm: The model takes single RGB-D images and a 2D user-specified pixel query on the object. Depth is back-projected to a point cloud cropped to 0.3m radius around this query point. RGB features are extracted by frozen DINOv2 ViT; point cloud features by a trainable PointNeXt U-Net. These two streams are fused with point painting (projecting 3D points onto 2D image features and concatenating) and encoded by a 4-layer transformer. This produces conditioning tokens for a flow-matching transformer to predict a 99-dimensional grasp state (3D wrist translation, 6D wrist rotation in continuous rotation rep, and 15 MANO finger joints encoded as 6D rotations each). The MANO shape parameter is fixed canonical size; only articulation and wrist position are predicted. The flow-matching transformer uses AdaLN-Zero conditioning on diffusion timestep to generate the grasp in normalized coordinates.
Training Regime: The loss combines MSE velocity prediction of the flow-matching velocity field with a fingertip 3D landmark L1 supervision weighted to near-clean denoised samples. AdamW optimizer with lr=1e-4 is used, batch size 128 on two RTX 5090 GPUs with distributed training. Training uses 100K steps (~10 hours) including MuJoCo validation every 5K steps. Only PointNeXt, RGB-PC fusion, and flow transformer are trained; DINOv2 is frozen.
Evaluation Protocol: Metrics include success rate (fraction of grasps maintaining object hold after open-loop pregrasp→grasp→lift rollout in simulation and real robot) and fingertip contact error measuring average signed distance of thumb and supporting fingers to object surface. Model checkpoints chosen by highest validation success rate. Ablations test RGB-only, PC-only, crop/no crop, point painting, and 3D supervision removal. Real-world testing uses 30 unseen objects from HUG-BENCH held out from training with no tuning. Baselines Dex1B and CAP deployed on different robot and camera setups provide comparison. Real-to-sim evaluation uses paired 3D meshes derived from metric scans of actual physical objects.
Reproducibility: Authors release code, data, benchmark, trained checkpoints, and interactive demo at https://grasping.io. The full pipeline from Aria recordings to MANO fitting (aria2mano) and mesh asset creation (aria2mesh) is open-source. Some components such as Aria glasses hardware and environment scans are proprietary or limited access, but overall protocol and benchmarks are detailed for replication.
Concrete example: For a given single RGB-D frame and a user click on an object point, the model crops metric point cloud around this point, extracts RGB and PC features, fuses them, and predicts a grasp pose in MANO parameters. This predicted grasp is converted to robot hand pose via retargeting, then executed open-loop on a 6-DoF robotic hand in simulation and real world. Success is measured by whether the object remains securely grasped after lift.
Technical innovations
- Collecting and releasing 1M-HUGS, a large-scale egocentric dataset of 1 million natural human grasps with RGB-D, hand tracking, and MANO pose annotations.
- Designing HUG, a flow-matching transformer architecture that fuses RGB image and local point cloud features conditioned on a user-selected point to predict diverse and naturalistic 99D human hand grasps.
- Introducing a novel point painting technique that injects 2D RGB patch features into 3D point cloud tokens to improve spatial and semantic feature fusion for grasp prediction.
- Building HUG-BENCH, a benchmark of 90 unseen metric-scale object meshes spanning diverse geometric categories for rigorous sim and real-world dexterous grasping evaluation.
- Demonstrating zero-shot retargeting of human grasp predictions to diverse robotic hand embodiments with no per-hand re-training.
Datasets
- 1M-HUGS — 1 million RGB-D frames with human grasp poses — collected via Aria Gen 2 smart glasses across 6,707 recordings and 41 buildings, covering ~1.5K unique objects
- HUG-BENCH — 90 unseen real objects with metric-scale 3D meshes — scanned and reconstructed from egocentric recordings for sim and real evaluation
Baselines vs proposed
- Dex1B: real-world test success rate = 43.7% vs proposed HUG: 66.7% (+23% absolute gain)
- CAP: real-world test success rate = 32.7% vs HUG: 66.7% (+34% absolute gain)
- Human grasp oracle (simulation): success rate = 94.0% vs HUG full RGB+PC: 73.0%
- HUG full RGB+PC model: 73.0% sim success vs RGB-only 29.7% and PC-only 70.7%
- Removing 3D fingertip loss from HUG cuts sim test success from 73.0% to 32.7%
- No point cloud cropping reduces test success from 73.0% to 58.0%
- No point painting reduces test success from 73.0% to 58.3%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.17054.
Fig 1: HUG learns dexterous grasping without any robot data. Trained solely on egocentric

Fig 2: 1M-HUGS dataset. Our training data comprises 1M egocentric frames of human grasps,
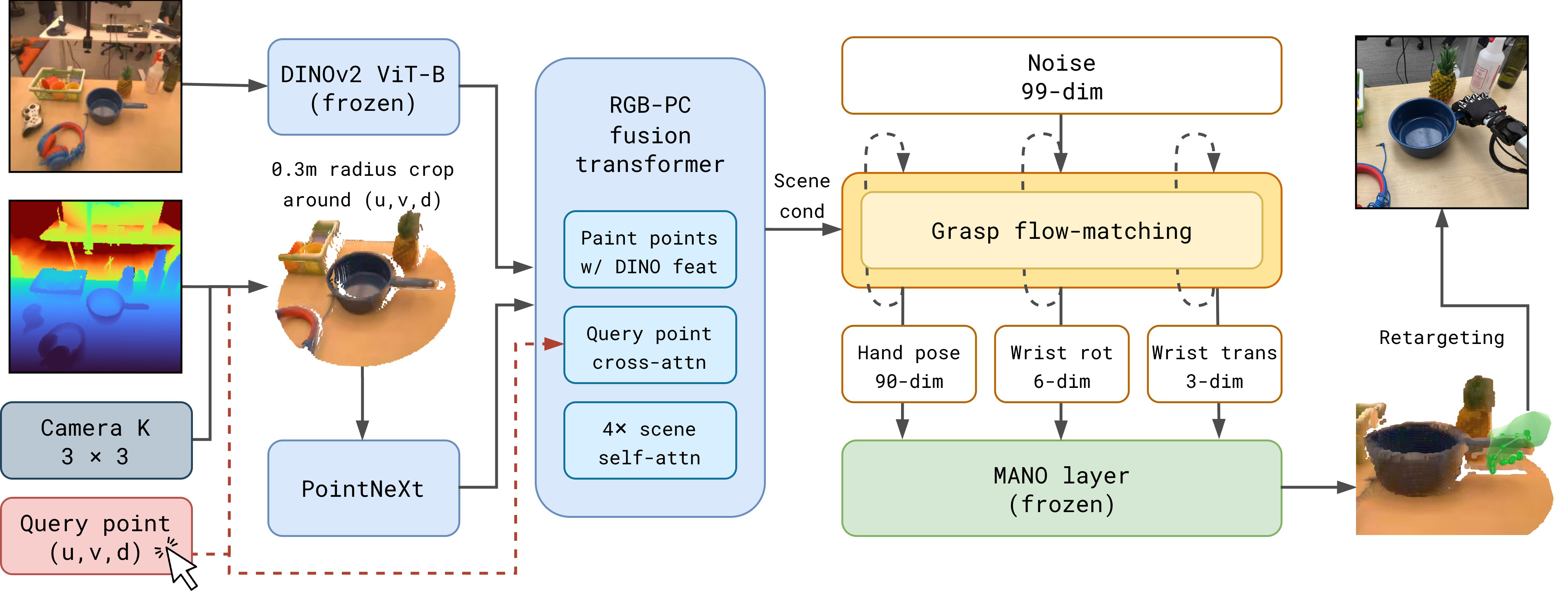
Fig 3: HUG architecture. Conditioned on an RGB-D image and a query point on the target

Fig 4: Predicted grasps on HUG-BENCH. HUG’s predicted grasps for 30 unseen objects

Fig 5: Real world grasping with HUG. Grasp executions on unseen objects from HUG-BENCH

Fig 6: HUG-BENCH test split.

Fig 7: Dataset scaling.

Fig 9: Single-modality failures.
Limitations
- Model trained only on right-hand grasps with fixed canonical MANO shape; no support for left-handed or bimanual grasping or hand shape variation.
- Human-to-robot retargeting can fail when robot hand morphology cannot replicate predicted grasp poses, limiting some object or hand combinations.
- Open-loop execution without closed-loop visual or force feedback causes many grasp failures due to collisions or slipping during lift.
- Hand tracking quality degrades under occlusions, causing label noise in grasp poses that may lead to training inaccuracies.
- Low input RGB-D resolution (224x224) limits accuracy on very small objects; large or far objects are rare in egocentric data causing distribution imbalance.
- Single predicted grasp per trial without candidate selection or ranking may miss better grasp options.
- Evaluation is limited to indoor settings; outdoors or more diverse environmental conditions remain untested.
Open questions / follow-ons
- How to extend the model to bimanual grasping and incorporate left-hand or diverse hand morphologies?
- Can closed-loop reactive controllers or force sensing integrated with HUG improve grasp robustness and reduce open-loop failures?
- How would HUG perform in more diverse environments beyond indoor homes, including outdoor or cluttered scenes?
- What are effective strategies for candidate grasp generation and ranking beyond predicting a single grasp to improve success?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper offers insight into leveraging large-scale in-the-wild human behavioral data to learn models that generalize robustly and naturally across varied real-world scenarios, even when trained on data from a different morphology (human hands) and deployed on robotic embodiments. The approach of conditioning on minimal user-specified input (point clicks) and fusing multiple input modalities to predict complex poses is an example of generalizable AI that can handle diverse inputs without task-specific retraining. The demonstrated zero-shot transfer and dataset scale effects emphasize the importance of rich, semantically meaningful, and well-labeled human data for training real-world systems. While focused on robotics, lessons from multi-modal fusion, data scaling, and zero-shot retargeting may inform advances in CAPTCHA generation or bot-behavior detection that need to generalize from human-like interaction data. Additionally, understanding failure modes in open-loop control and limitations due to occlusions and sensing resolution can shed light on challenges in deploying learned models robustly in the wild.
Cite
@article{arxiv2606_17054,
title={ Human Universal Grasping },
author={ Kevin Yuanbo Wu and Tianxing Zhou and Isaac Tu and Billy Yan and Irmak Guzey and David Fouhey and Dandan Shan and Lerrel Pinto },
journal={arXiv preprint arXiv:2606.17054},
year={ 2026 },
url={https://arxiv.org/abs/2606.17054}
}