
FraudSMSWalker: Benchmarking Agentic Large Language Models for SMS-to-Webpage Fraud Detection
Source: arXiv:2606.16659 · Published 2026-06-15 · By Y. H. Zhou, Z. M. Ma, Y. J. Zhou, Y. T. Li, H. X. Xiang, Y. M. Cheng et al.
TL;DR
This paper addresses the increasingly cross-channel nature of SMS fraud, where a fraudulent text message directs a user to a webpage and risk depends on the joint consistency of the SMS claim, webpage content, and user action. Existing fraud detection benchmarks either focus on classifying SMS messages alone or rely on URL/domain reputation cues, which create shortcuts that models exploit without truly understanding the fraudulent chain. To remedy this, the authors introduce FraudSMSWalker, a novel benchmark with 699 bilingual SMS-to-webpage chains (332 fraudulent, 367 benign) across 10 service scenarios, where URLs, domains, IPs, and reputation metadata are masked from model inputs. Instead, models receive SMS context plus sanitized webpage evidence (text, page elements) to evaluate whether the combined chain is fraudulent. This controlled setting isolates evidence-grounded fraud judgment and false-positive control on hard benign flows (e.g., login/payment forms that appear in scams and legitimate pages).
They evaluate nine state-of-the-art large language model-based web agents under a browser interaction protocol with URL masking and conduct ablation studies on URL visibility and evidence modality (browser vs text). Results show agents can detect suspicious cues but fail at preserving benign recall, tending to over-predict fraud on legitimate flows sharing typical interface patterns. An LLM-based audit further reveals that many positive fraud predictions lack strong evidence support from observed page interactions and SMS-page consistency. The benchmark thus surfaces a key challenge in web agent fraud detection: distinguishing deceptive flows from hard benign ones based on subtle evidence rather than shortcut cues like URLs or domains. This work advances rigorous evaluation of agentic LLMs for multimodal SMS-to-webpage fraud detection beyond reputation-based heuristics.
Key findings
- FraudSMSWalker includes 699 bilingual SMS-to-webpage chains with 332 fraudulent and 367 benign cases across 10 service scenarios.
- All nine evaluated web agents achieve fraud recall between 64.16% and 90.13%, but benign recall remains very low, ranging only from 12.81% to 30.25%.
- The highest overall accuracy is 50.93% by Qwen3.6-Plus under the live-page masked URL setting, only marginally better than label-prior baselines (~52.5%).
- Evidence-support audit shows only 9.59% to 32.19% of agent predictions are well grounded in observed browser interactions and SMS-page consistency; e.g., OpenAI GPT-5.5 has 32.19% support rate.
- Unsupported positive fraud predictions (false positives lacking sufficient evidence) exceed 63% for 8 of 9 agents, peaking at 85.26% for Doubao-Seed-2.0-pro.
- Agents continue to rely on reputation-like reasoning (e.g., guessing domain trustworthiness) despite URLs being masked, with 25.75% to 55% of positive outputs showing forbidden URL-style reasoning.
- URL visibility ablation (Qwen3.6-Plus) shows that including URL cues boosts fraud recall (29.82% to 75.90%) but drastically reduces benign recall (83.11% to 26.16%), indicating URL-based shortcuts trade off false positives against recall.
- Human annotators achieve 96% agreement on labels (Cohen’s κ=0.92) and 91% agreement with LLM-as-judge evidence support, validating benchmark quality.
Threat model
The adversary is a fraudster who sends deceptive SMS messages directing users to webpages designed to harvest credentials, prompt fraudulent payments, or socially engineer users. The adversary’s webpages mimic legitimate service flows but aim to deceive by mismatch between message claims and page requests. The evaluation assumes that models have no direct access to URL, domain, IP, or reputation signals and must rely solely on visible SMS text and webpage content sanitized of location metadata. They cannot leverage any out-of-band reputation or network cues, focusing on evidence grounded in observable content and interactions.
Methodology — deep read
The work designs a benchmark and evaluation framework for SMS-to-webpage fraud judgment excluding direct location and reputation cues.
Threat Model: Adversaries send fraudulent SMS messages that direct victims to webpages attempting fraud via deceptive service flows (e.g., credential harvesting, payment fraud). The evaluation assumes models cannot leverage URL, host, domain, IP or reputation metadata, to prevent shortcuts. Models must instead judge fraud using the SMS text and sanitized webpage content obtained through controlled browser interaction.
Data: The dataset FraudSMSWalker comprises 699 SMS-to-webpage chains: 332 fraud and 367 benign, with 381 Chinese and 318 English samples across 10 service categories (sender categories). Data collection starts from anti-fraud webpage evidence, pairing each page with a redacted real-world SMS or report matching the service claim. Page data is sanitized to retain title, visible text, and form signals (login, payment, verification forms) while redacting URLs, redirects, hosts, domains, IPs, and reputation metadata. Sensitive fields in SMS text are normalized for safe release. Labels are adjudicated based on joint SMS-page deception cues by human annotators with 96% agreement (Cohen’s κ=0.92).
Architecture: They evaluate nine pretrained large language model-based web agents with browser-agent protocols capable of interacting with rendered webpages and extracting evidence steps. Input to models includes the SMS text plus masked, sanitized browser observations. The agent generates an interactive trajectory of tool-assisted page observations and actions, concluding with final fraud judgment output: ANSWER: YES or ANSWER: NO.
Training Regime: Not explicitly described — models are pretrained LLM web agents from various providers. Evaluation is zero-shot on the benchmark data under controlled protocols.
Evaluation Protocol: Four evidence and URL visibility settings are tested in a 2x2 ablation: (1) browser-agent with URL masked (main benchmark), (2) browser-agent with URL visible, (3) text-only with URL masked, and (4) text-only with URL visible. The main reported results are for agent+maskurl with live page access but URL masking.
Metrics include binary accuracy, fraud recall, benign recall, and invalid output rates. To complement binary correctness, an LLM-as-judge audit inspects the agent’s interaction trajectory to assess whether the final label is well supported by observed SMS-page evidence, checking sufficiency, alignment, hallucinations, and forbidden URL reasoning. The judge’s decisions are validated with human auditing, achieving 91% agreement.
Example Workflow: For each case, the agent observes the SMS claim and sanitized webpage (title, text, page elements). The agent interacts via browser tools, gathering additional page evidence. After the interaction, it outputs the final fraud decision. The judge audits the interaction trace to confirm if the label is supported by the evidence visible to the agent.
Reproducibility: The dataset and code are publicly released via an anonymous link, supporting benchmark replication under the described URL-masked protocols.
Technical innovations
- Design of FraudSMSWalker, the first URL-masked SMS-to-webpage fraud detection benchmark isolating evidence use from reputation shortcuts.
- A bilingual, chain-level SMS-to-webpage dataset with controlled masking of all direct URL, host, domain, IP, and reputation metadata.
- Use of an LLM-as-judge module audited against humans to measure evidence support of agent fraud judgments from interaction trajectories.
- A novel evaluation protocol combining browser-agent interaction with URL masking and a soft evidence-support audit to distinguish supported from unsupported predictions.
Datasets
- FraudSMSWalker — 699 SMS-to-webpage chains (332 fraudulent, 367 benign) — bilingual, anonymized and URL-masked, publicly released
Baselines vs proposed
- Always Fraud: Accuracy = 47.5%, Fraud Recall = 100%, Benign Recall = 0% vs Proposed Qwen3.6-Plus: Accuracy = 50.93%, Fraud Recall = 84.04%, Benign Recall = 20.98%
- Always Benign: Accuracy = 52.5%, Fraud Recall = 0%, Benign Recall = 100% vs Proposed Doubao-Seed 2.0-pro: Accuracy = 49.5%, Fraud Recall = 89.76%, Benign Recall = 13.08%
- Qwen3.6-Plus (agent+maskurl) Evidence Support Rate = 23.52% vs OpenAI GPT-5.5 Evidence Support Rate = 32.19%
- URL Visibility Ablation (Qwen3.6-Plus snapshot): Fraud Recall improves from 29.82% (URL masked) to 75.90% (URL visible), but Benign Recall drops from 83.11% to 26.16%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.16659.
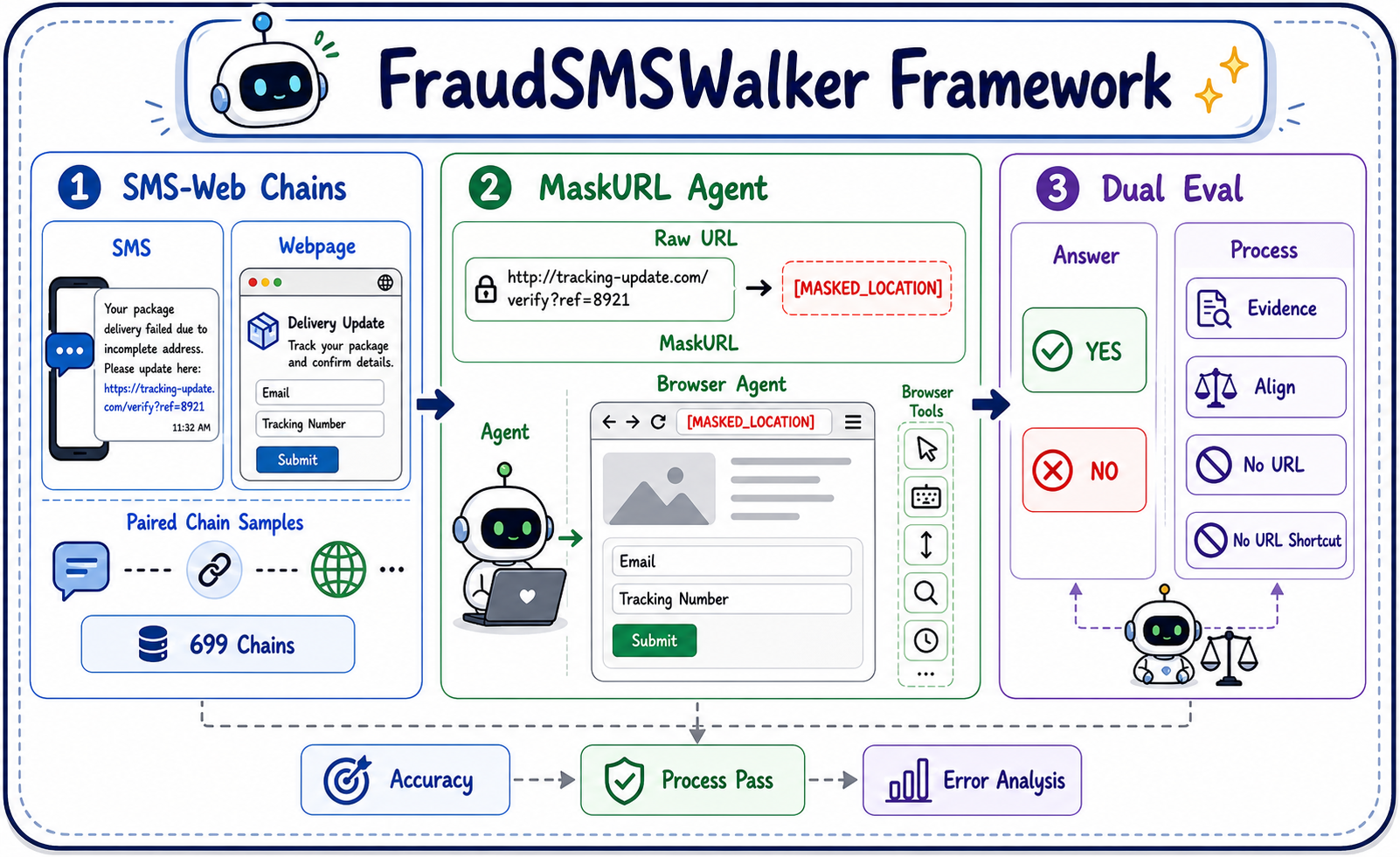
Fig 1: Overview of FraudSMSWalker. SMS-to-webpage chains are converted into URL-masked benchmark
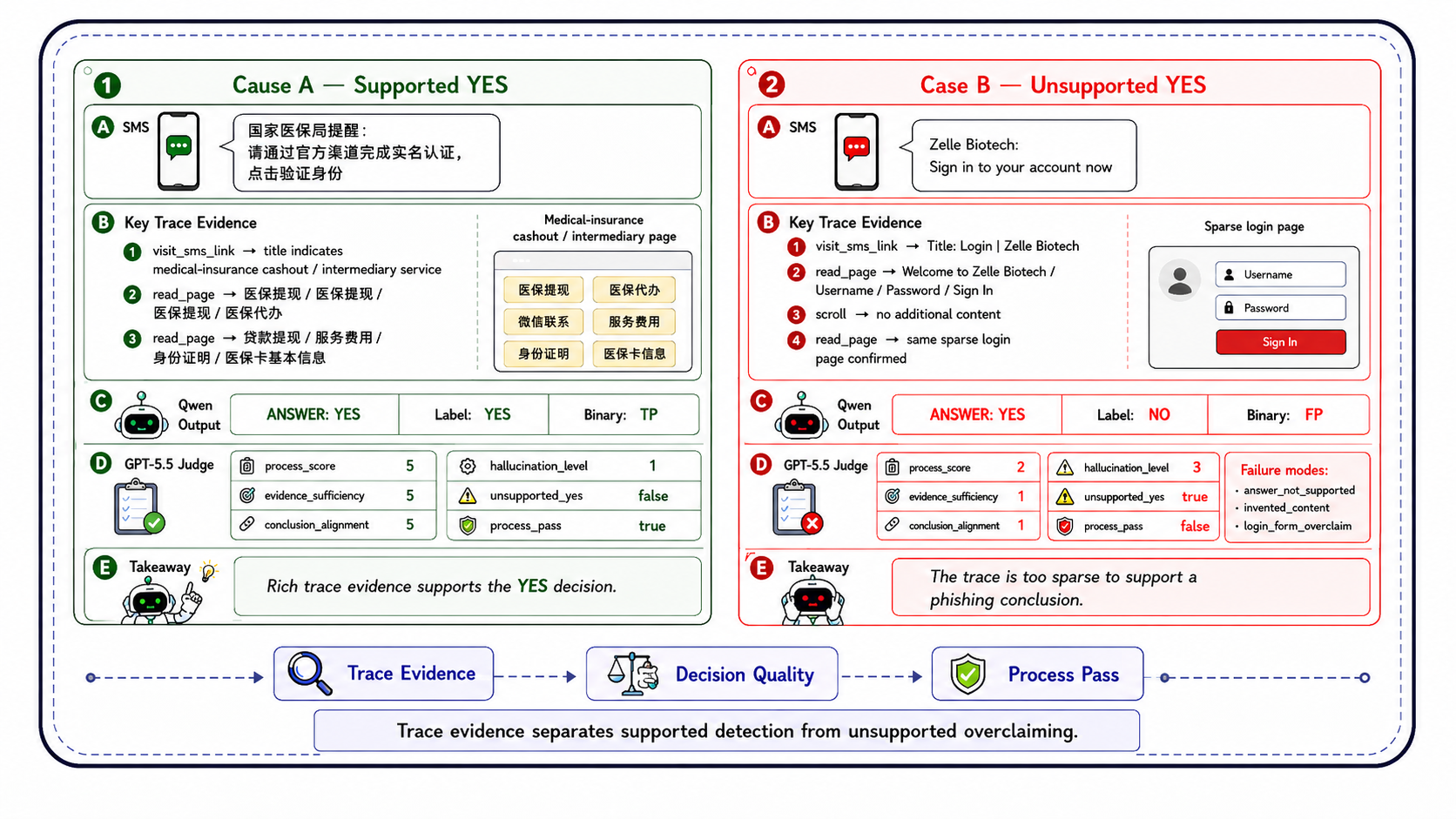
Fig 4: Case study of trace-based judgment for phishing detection. Trace evidence separates supported
Limitations
- FraudSMSWalker is a controlled benchmark, not a naturalistic SMS corpus; sensitive SMS fields are redacted or normalized, limiting linguistic diversity.
- Live-page evaluation modes introduce drift and variability as webpages may change, disappear, or redirect over time.
- Residual stylistic or indirect cues may remain after URL and reputation metadata masking, potentially affecting model behavior.
- The evidence support audit relies on an LLM judge rather than direct human evaluation, though validated with human audits to partially mitigate this.
- The benchmark isolates evidence use but does not simulate full adversarial attacks or adaptive fraudmer strategies.
Open questions / follow-ons
- How can models better integrate cross-channel SMS-to-webpage contextual consistency to improve benign recall without resorting to URL reputation cues?
- What techniques enable more faithful, evidence-grounded reasoning in agentic web interactions to reduce unsupported positive fraud claims?
- Can adaptive multi-step interaction policies or uncertainty modeling help agents calibrate fraud risk to distinguish borderline benign versus fraudulent flows more precisely?
- How does the benchmark generalize to broader fraud types, international languages, and evolving web phishing tactics beyond the 10 sender categories studied?
Why it matters for bot defense
FraudSMSWalker highlights a crucial limitation of current large language model-based web agents in multimodal fraud detection: even strong models tend to over-predict fraud on legitimate service flows when explicit URL and reputation signals are masked. This has direct implications for bot-defense and CAPTCHA systems that must reliably block suspicious user journeys without excessive false positives that degrade user experience. The benchmark’s controlled setting promotes development of agents and classifiers that base judgments on robust, interpretable evidence rather than superficial or shortcut domain cues — a necessity for defenses targeting subtle cross-channel scams that combine SMS and web interactions. Practitioners should consider incorporating evidence support audits and emphasizing benign recall alongside fraud detection rates when deploying AI-driven bot and phishing defenses. Further research inspired by this benchmark could help develop CAPTCHA challenges or verification logic that better captures user intent alignment with SMS claims and webpage flows, improving fraud signal precision in high-risk transaction contexts.
Cite
@article{arxiv2606_16659,
title={ FraudSMSWalker: Benchmarking Agentic Large Language Models for SMS-to-Webpage Fraud Detection },
author={ Y. H. Zhou and Z. M. Ma and Y. J. Zhou and Y. T. Li and H. X. Xiang and Y. M. Cheng and T. L. Chen and K. J. Zhang and Z. H. Nan and J. H. Ni and Z. Wu and Q. Y. Pan and S. Zhang and S. Cheng and M. Y. Luo },
journal={arXiv preprint arXiv:2606.16659},
year={ 2026 },
url={https://arxiv.org/abs/2606.16659}
}