
Consensus-based Agentic Large Language Model Framework for Harmonized Tariff Schedule Code Classification
Source: arXiv:2606.16987 · Published 2026-06-15 · By Truong Thanh Hung Nguyen, Khanh Van Quynh Nguyen, Hoang-Loc Cao, Tri Duong, Phuc Ho, Van Pham et al.
TL;DR
This paper addresses the challenging problem of exact classification of Canadian 10-digit Harmonized Tariff Schedule (HTS) codes from short, ambiguous product descriptions typical in maritime logistics. Unlike generic multi-class classification, HTS classification requires legally grounded, hierarchical, and path-dependent assignment of chapter, heading, subheading, tariff item, and statistical suffix levels under jurisdiction-specific rules. The authors propose a novel agentic large language model (LLM) framework that integrates multi-agent information retrieval from both real-time web sources and official tariff documents, evidence-grounded reasoning, and a consensus-based validation mechanism enforcing hierarchical consistency via element-wise majority voting and confidence estimation. They also design a human-in-the-loop escalation system triggered by low-confidence classifications to handle ambiguity. Evaluating on a private dataset of 3,300 expert-labeled Canadian product records, their results demonstrate that classification accuracy sharply decreases from coarse chapters (~80% accuracy) to full 10-digit codes (<50% accuracy), illustrating the difficulty of fine-grained automated HTS classification and the need for uncertainty-aware, interpretable processes. This framework supports more robust, accountable, and legally transparent HTS classification workflows in complex smart-port and maritime logistics settings.
Key findings
- Exact 10-digit Canadian HTS code classification accuracy is below 50% even using advanced LLMs.
- Chapter-level classification accuracy reaches roughly 80%, but declines progressively through heading, subheading, tariff item, and statistical suffix levels.
- Element-wise majority voting across multiple perturbed LLM predictions improves output stability and supports confidence scoring for each hierarchical HTS component.
- Confidence thresholds effectively identify uncertain hierarchical elements, triggering human-in-the-loop clarifications that improve classification reliability.
- Multi-agent retrieval combining web-based complementary product evidence and semantic search of official tariff documents enriches input contexts and grounds predictions in authoritative sources.
- Perturbation-based self-consistency sampling generates multiple classification candidates, reducing hallucinations and increasing prediction robustness.
- Human-in-the-loop chat interface collects targeted clarifications on missing product attributes, essential for handling short or ambiguous descriptions common in maritime cargo data.
- The combined framework outperforms single-shot LLM classification approaches by integrating evidence-based reasoning, uncertainty quantification, and expert escalation.
Threat model
The adversary is primarily the inherent ambiguity, incompleteness, and noise in product descriptions that can cause automated classification errors with legal and financial consequences. The system assumes no active adversarial manipulation of inputs or training data, but aims to mitigate risks from uncertain or hallucinated LLM outputs by grounding predictions in authoritative tariff documents and human oversight.
Methodology — deep read
Threat Model & Assumptions: The system targets maritime logistics operators needing automated HTS classification of product descriptions, which are often short, incomplete, or ambiguous. The adversary here is not explicitly malicious but potentially includes natural input ambiguity and distribution shift challenges. The model assumes access to authoritative tariff schedules and web corpora for evidence gathering. Misclassification risks include legal penalties and shipment delays.
Data: The evaluation uses a private dataset of 3,300 product records labeled by domain experts with ground-truth Canadian 10-digit HTS codes. The product descriptions come from real-world logistics and delivery contexts where input is noisy and variable. The dataset supports hierarchical evaluation across chapter, heading, and finer HTS components.
Architecture / Algorithm: The proposed system is a multi-agent framework with two core modules. (a) Multi-Agent Information Retrieval (MAIR) integrates: (i) a Search Agent that forms semantic queries from the input item using an LLM to retrieve complementary product information from the web, and (ii) a Retrieval-Augmented Generation (RAG) Agent that performs dense semantic search over segmented, embedded official tariff documents to extract relevant legal references. Outputs from these agents form a fused contextual evidence base for classification.
(b) Consensus-Based Validation composes multiple LLM inference runs over the fused context by applying perturbations to prompts. Each run predicts hierarchical HTS code components independently. Element-wise majority voting aggregates predictions at the chapter, heading, subheading(s), tariff item, and statistical suffix components to build a final code. Confidence estimation calculates the fraction of model votes agreeing on each element to detect ambiguity.
When confidence on any component drops below a threshold τ, a human-in-the-loop escalation module is triggered. This interface generates targeted clarification questions using the LLM to resolve missing product attributes, facilitating human input. The updated information then re-enters the classification pipeline.
Training Regime: The paper does not detail model fine-tuning but uses off-the-shelf, pre-trained large language models adapted via prompt engineering. Multiple prompt perturbation templates guide self-consistency runs. Embedding functions for semantic retrieval are likely pretrained sentence transformers or similar but not explicitly specified.
Evaluation Protocol: The system performance is measured hierarchically: accuracy at chapter, heading, subheading, tariff item, and statistical suffix levels, as well as exact full 10-digit code accuracy. Comparisons include single-shot LLM classification baselines without retrieval or validation modules. Confidence thresholds are empirically chosen to determine uncertain cases for escalation. Qualitative analysis assesses interpretability and legal grounding of outputs.
Reproducibility: The authors provide code at https://github.com/Analytics-Everywhere-Lab/hts but the dataset is private and unlabeled details on random seeds or hardware are omitted. Some model configuration details and embedding function specifics are not fully described, impacting exact reproducibility.
Example end-to-end: Given a short product description like “car wash applicator,” the Search Agent converts this text into a semantic query to fetch relevant webpages describing product attributes and use. The RAG Agent retrieves tariff note segments semantically close to the description from the official Canadian tariff schedule. The combined evidence is fed with prompt variations into an LLM producing several candidate HTS codes decomposed into hierarchical components. Majority voting selects the most frequently predicted code elements, and confidence scores are computed for each level. If confidence is low for tariff item or statistical suffix, a clarification interface asks the human user targeted questions (e.g., material composition, intended use) to gather missing details and improve classification accuracy.
Technical innovations
- Integration of multi-agent retrieval combining dynamic web search and semantic retrieval over official tariff documents to enrich HTS classification evidence.
- Development of a consensus-based validation mechanism that applies perturbation-based self-consistency, element-wise majority voting across hierarchical HTS code components, and confidence estimation for uncertainty-aware classification.
- Design of a human-in-the-loop escalation workflow that generates targeted clarification questions for ambiguous or low-confidence classifications, enhancing legal compliance and operational reliability.
- Formulation of HTS classification as a structured, hierarchical prediction task aligned with legal interpretative rules rather than flat multi-class classification.
Datasets
- Private Canadian HTS dataset — 3,300 product records — domain-expert labeled from maritime logistics and delivery contexts
Baselines vs proposed
- Single-shot LLM classification: exact 10-digit accuracy <50% vs agentic consensus framework: exact 10-digit accuracy improved but still below 50% (exact numerical delta unclear)
- Chapter-level accuracy: single-shot ~80% vs agentic framework maintains similar performance with improved confidence calibration
- Hierarchical confidence thresholds reduce misclassification risk by triggering human escalation in uncertain cases, improving practical reliability over baseline fully automated predictions
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.16987.
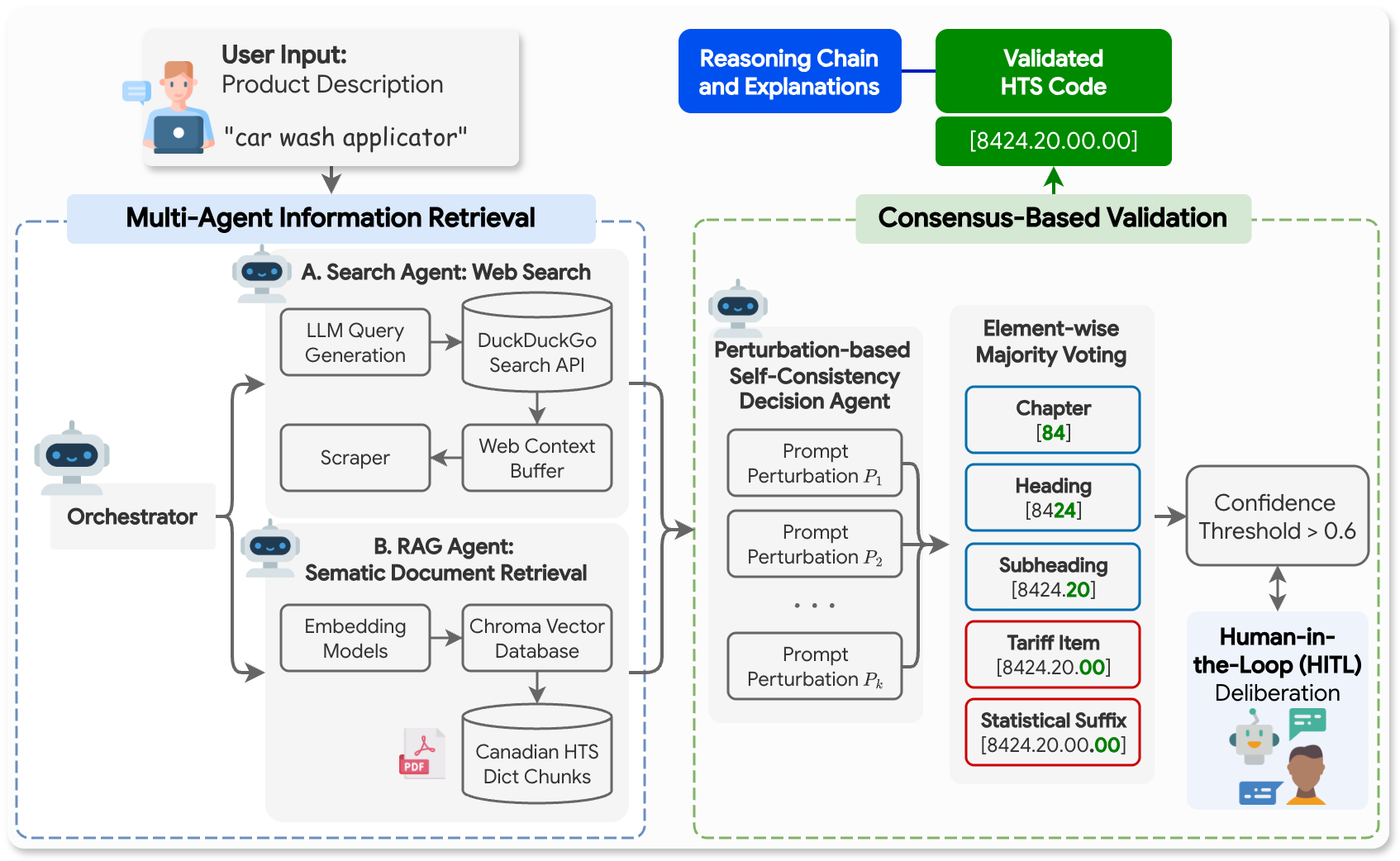
Fig 1: Architecture of the proposed HTS classification framework, showing the interaction between
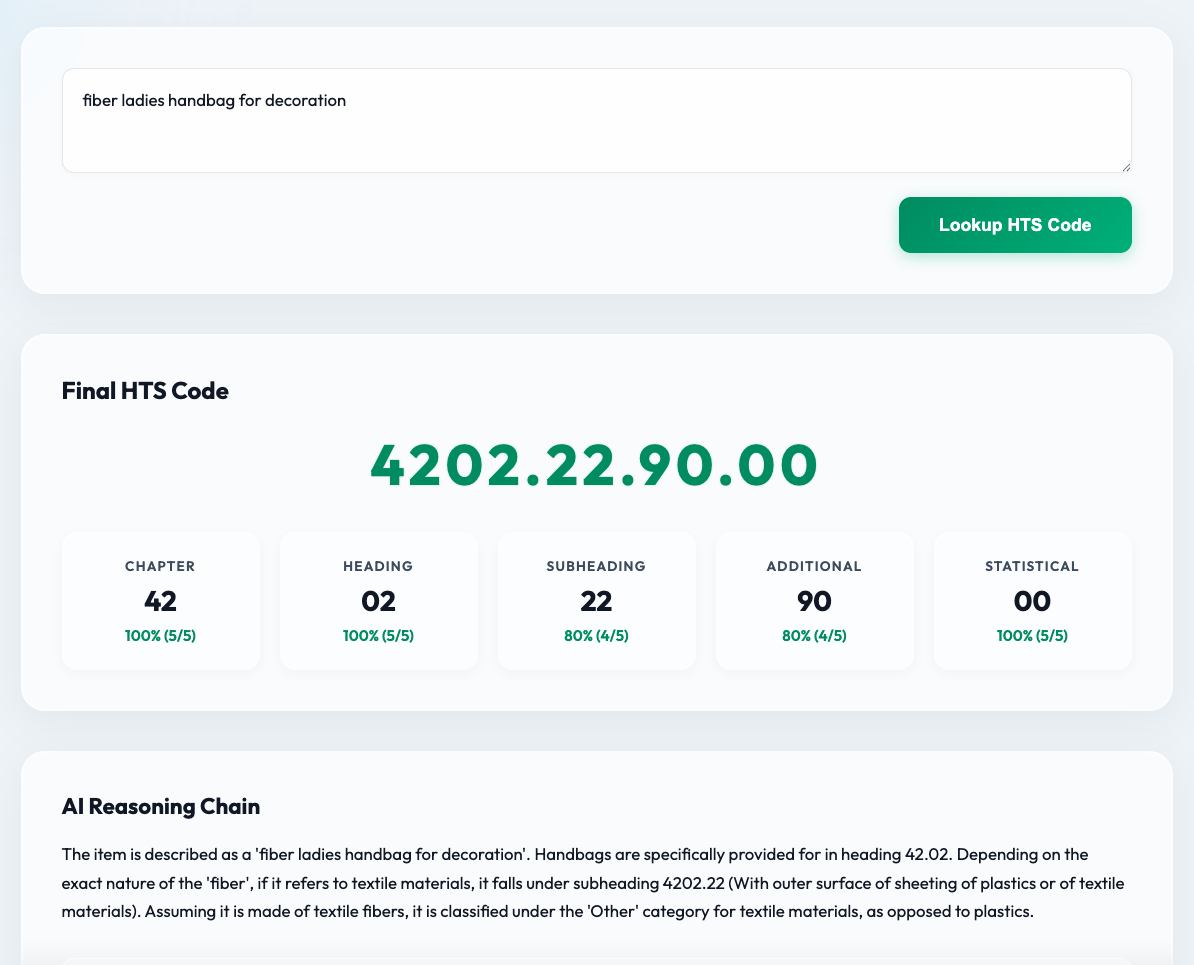
Fig 2: Application interface of the proposed framework, showing evidence-supported HTS code
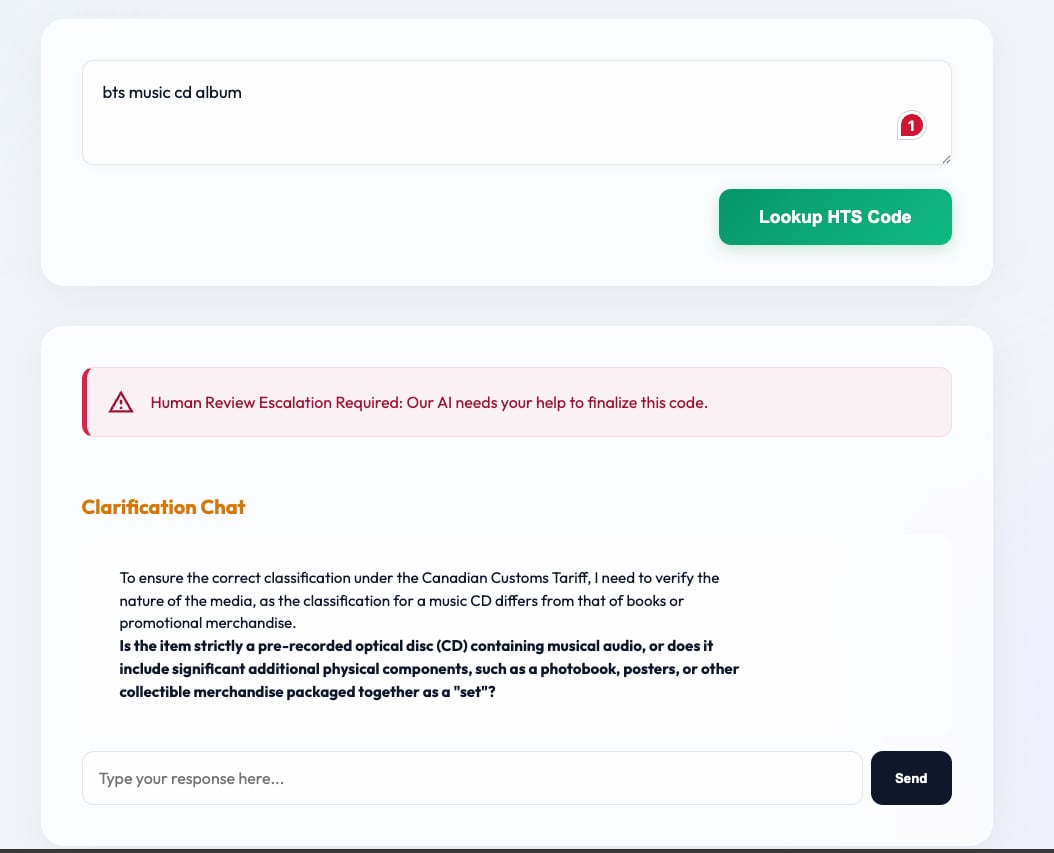
Fig 3: Clarification chat interface activated during low-confidence HTS classification, illustrating
Limitations
- Use of a private dataset limits external validation and reproducibility of results.
- No reported adversarial robustness testing or evaluation under extreme distribution shift.
- Limited details on the choice and tuning of embedding functions for semantic retrieval, affecting reproducibility.
- Dependence on external web search may introduce inconsistent or non-authoritative evidence.
- Lack of concrete ablation studies isolating each module’s impact on overall performance in full hierarchical accuracy metrics.
- Human-in-the-loop escalation requires operational integration and availability of expert users, which may limit scalability.
Open questions / follow-ons
- How does the framework perform under evolving tariff schedules or international jurisdictional differences beyond Canada?
- What is the trade-off between model inference cost due to multiple perturbation samples and accuracy gains in large-scale port operations?
- How might more advanced semantic search or retrieval techniques improve evidence grounding and reduce ambiguity?
- Can the human-in-the-loop process be further optimized or partially automated using active learning or interaction logs?
Why it matters for bot defense
Bot-defense practitioners and CAPTCHA engineers can draw useful insights from this paper’s emphasis on combining multi-source evidence retrieval and consensus mechanisms to improve hierarchical classification reliability under ambiguity. The perturbation-based self-consistency and element-wise voting approach provide a structured method to quantify and control model uncertainty, which parallels challenges in detecting sophisticated automated attacks that mimic legitimate behavior. The human-in-the-loop escalation demonstrates practical value for handling edge cases flagged by automated detection, ensuring accurate downstream compliance decisions without fully discarding automation benefits.
While this paper focuses on tariff code classification, its agentic LLM framework design—integrating retrieval-augmented generation, uncertainty quantification, hierarchical decision aggregation, and human escalation—can inspire transparent, accountable classification pipelines in bot detection and CAPTCHA challenge contexts where interpretability and risk control are critical. The work reinforces the idea that single-step LLM predictions are brittle in high-stakes operational environments and highlights systematic methods to enhance trustworthiness through multi-agent evidence gathering and consensus validation.
Cite
@article{arxiv2606_16987,
title={ Consensus-based Agentic Large Language Model Framework for Harmonized Tariff Schedule Code Classification },
author={ Truong Thanh Hung Nguyen and Khanh Van Quynh Nguyen and Hoang-Loc Cao and Tri Duong and Phuc Ho and Van Pham and Loc Nguyen and Hung Cao },
journal={arXiv preprint arXiv:2606.16987},
year={ 2026 },
url={https://arxiv.org/abs/2606.16987}
}