
A Multi-Center Benchmark for Abdominal Disease Diagnosis and Report Generation from Non-Contrast CT
Source: arXiv:2606.16991 · Published 2026-06-15 · By Mariam Elbakry, Aliaa Sayed Sheha, Salma Hassan Tantawy, Aya Yassin, Concetto Spampinato, Karim Lekadir et al.
TL;DR
This paper addresses the clinical and logistical challenges of multiphasic contrast-enhanced CT (CECT) for abdominal disease diagnosis, including risks of nephropathy, increased workload, and limited availability in resource-constrained settings. The authors propose a novel multi-center benchmark and large-scale paired dataset combining non-contrast CT (NCCT) volumes with corresponding triphasic contrast-enhanced reports. They study whether deep learning can extract latent diagnostic information from single-phase NCCT scans to generate comprehensive radiology reports and multi-organ disease classifications typically relying on multiphasic contrast imaging. Five contemporary 3D deep learning architectures spanning chest-specific, abdomen-specific, and generic 3D multimodal models are benchmarked on internal and external cohorts. Results show that despite lower diagnostic signal in NCCT, models achieve an average multi-organ AUC of 69.1% internally and 63.1% externally, retaining about 90% of contrast-enhanced diagnostic performance. Fine-tuning significantly improves clinical report generation metrics over zero-shot baselines, validating targeted multi-center adaptation. This benchmark and open dataset aim to catalyze safer, more accessible contrast-free abdominal imaging workflows through AI.
Key findings
- NCCT-based models achieve average multi-organ AUCs of 0.6910 (internal) and 0.6312 (external), retaining >90% of multiphasic contrast-enhanced diagnostic power (0.7654 and 0.6861 respectively).
- Merlin model's GREEN clinical report metric improves 459% from 6.254 (zero-shot) to 34.988 (fine-tuned) on internal data, and 435% from 4.967 to 26.597 on external data.
- Report generation metrics prioritize clinical correctness (GREEN, RadGraph-XL) over standard NLG metrics, which can be misleading in medical domain.
- The dataset includes 1,254 patients across two centers with paired NCCT and triphasic CECT scans, enabling multi-organ disease classification across 53 pathologies and 15 organs.
- Domain-specific architectures (Merlin, Pillar) outperform chest CT-trained models when fine-tuned on abdominal data.
- Qualitative analysis confirms models can identify subtle findings on NCCT such as mesenteric panniculitis and small renal cysts that are typically contrast-dependent.
- External validation cohort showed some performance degradation due to institutional differences, necessitating domain adaptation.
- NCCT cannot capture dynamic contrast kinetics critical for certain lesions, limiting full replacement of multiphasic protocols.
Threat model
Not applicable as a security paper; the adversarial context relates to clinical diagnostic replacement challenges rather than security threats. The 'adversary' could be seen as the inherent information loss in NCCT compared to multiphasic contrast CT, with AI models tasked to recover latent diagnostic cues despite this limitation.
Methodology — deep read
Threat Model & Assumptions: The adversary in this context is not explicitly defined as security-focused; the threat is the clinical challenge of replacing contrast-enhanced imaging (considered the gold standard) with non-contrast scans that inherently lack certain dynamic diagnostic signals. The assumption is that deep learning models can extract latent sub-visual morphological features from NCCT scans to approximate diagnostic insights traditionally obtained from multiphasic contrast-enhanced CT.
Data: The dataset is retrospectively curated from two tertiary care centers including 1,254 patients (1,085 internal, 169 external). Each patient has paired single-phase NCCT and triphasic CECT volumes with corresponding radiology reports. Imaging parameters include 512×512 axial matrices, 0.875 mm in-plane spacing, slice thickness approx. 1.07 mm. Diagnostic labels for 53 abdominal pathologies over 15 organs were extracted from contrast-enhanced reports through the RATE framework and audited by board-certified radiologists. The dataset is split internally into train (760), validation (106), and test (219) sets, with the external center reserved for validation (169 cases). Data preprocessing involves label normalization and careful de-identification.
Architecture / Algorithm: Five deep learning models are benchmarked:
- CT2Rep: Chest CT pretrained 3D encoder + causal transformer with relational memory.
- BTB3D: Causal convolutional encoder-decoder producing volumetric tokens, chest CT pretrained.
- M3D: Generic multimodal 3D spatial pooling perceiver + large language model backbone.
- Merlin: Abdominal CT-specific 3D vision-language foundation model pretrained on pancreatic and abdominal scans.
- Pillar-0: Multimodal 3D radiology foundation model pretrained on chest, abdomen, and head volumes. Inputs are NCCT volumetric images; outputs are multi-label disease classification and free-text radiology reports capturing multiphasic contrast-equivalent findings.
Training Regime: Models are fine-tuned on the internal training split to adapt pretrained weights (from chest or other abdominal data) to the Egyptian abdominal NCCT data. Specific hyperparameters (epochs, batch size, optimizer choices) are not fully detailed but training used GPU hardware. Zero-shot baselines were tested without finetuning.
Evaluation Protocol: Diagnostic classification is measured using AUROC and macro F1 across 53 pathologies to assess clinical performance. Report generation is evaluated primarily using clinical metrics GREEN and RadGraph-XL which capture structured entity extraction and relation correctness, addressing the limitations of generic text-overlap metrics like BLEU or ROUGE. Evaluation is performed separately on internal hold-out test set and external validation cohort to assess generalizability. Ablations include zero-shot vs finetuned results. Qualitative case studies confirm clinical relevance of findings.
Reproducibility: The dataset and benchmark are publicly released with code at https://github.com/xmed-lab/TriALS-Report to facilitate future research. However, the dataset itself is derived from medical centers and may have access restrictions. Frozen weights for baselines are not explicitly mentioned.
Example end-to-end: A non-contrast CT from the internal cohort is input into the fine-tuned Merlin model, which processes the 3D volume through its vision-language encoder-decoder pipeline to produce a multi-organ disease classification and a detailed free-text radiology report. This report captures sub-visual signs such as fatty liver infiltration and mesenteric inflammation consistent with triphasic CECT findings, as validated against the ground-truth contrast report by radiologists. Performance is quantified with a GREEN score of ~35, showing a large improvement over zero-shot inference.
Technical innovations
- Introduction of the first large-scale multi-center paired NCCT-CECT dataset with comprehensive triphasic radiology reports enabling multi-organ abdominal disease classification and report generation from contrast-free scans.
- Benchmarking and fine-tuning of multiple contemporary 3D vision-language and multimodal transformer architectures on NCCT for synthesizing contrast-enhanced diagnostic findings.
- Adoption of clinical-focused report generation metrics (GREEN and RadGraph-XL) over traditional text-overlap scores to accurately assess medical report fidelity and clinical correctness.
- Demonstration that fine-tuning foundational abdominal CT models (e.g., Merlin) on NCCT substantially boosts clinical report generation, surpassing zero-shot and chest CT-trained model baselines.
Datasets
- Multi-center NCCT-CECT paired abdominal CT dataset — 1,254 patients — collected from two tertiary centers in Egypt, including internal (1,085) and external (169) cohorts
Baselines vs proposed
- Merlin zero-shot GREEN (internal): 6.254 vs fine-tuned GREEN: 34.988
- Merlin zero-shot GREEN (external): 4.967 vs fine-tuned GREEN: 26.597
- Average multi-organ AUC Merlin NCCT (internal): 0.6910 vs multiphasic: 0.7654
- Average multi-organ AUC Merlin NCCT (external): 0.6312 vs multiphasic: 0.6861
- Pillar NCCT pancreatic lesion AUC: 0.8032 vs multiphasic: 0.8419
- M3D zero-shot report generation GREEN (internal): 1.695 vs fine-tuned: 35.626
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.16991.
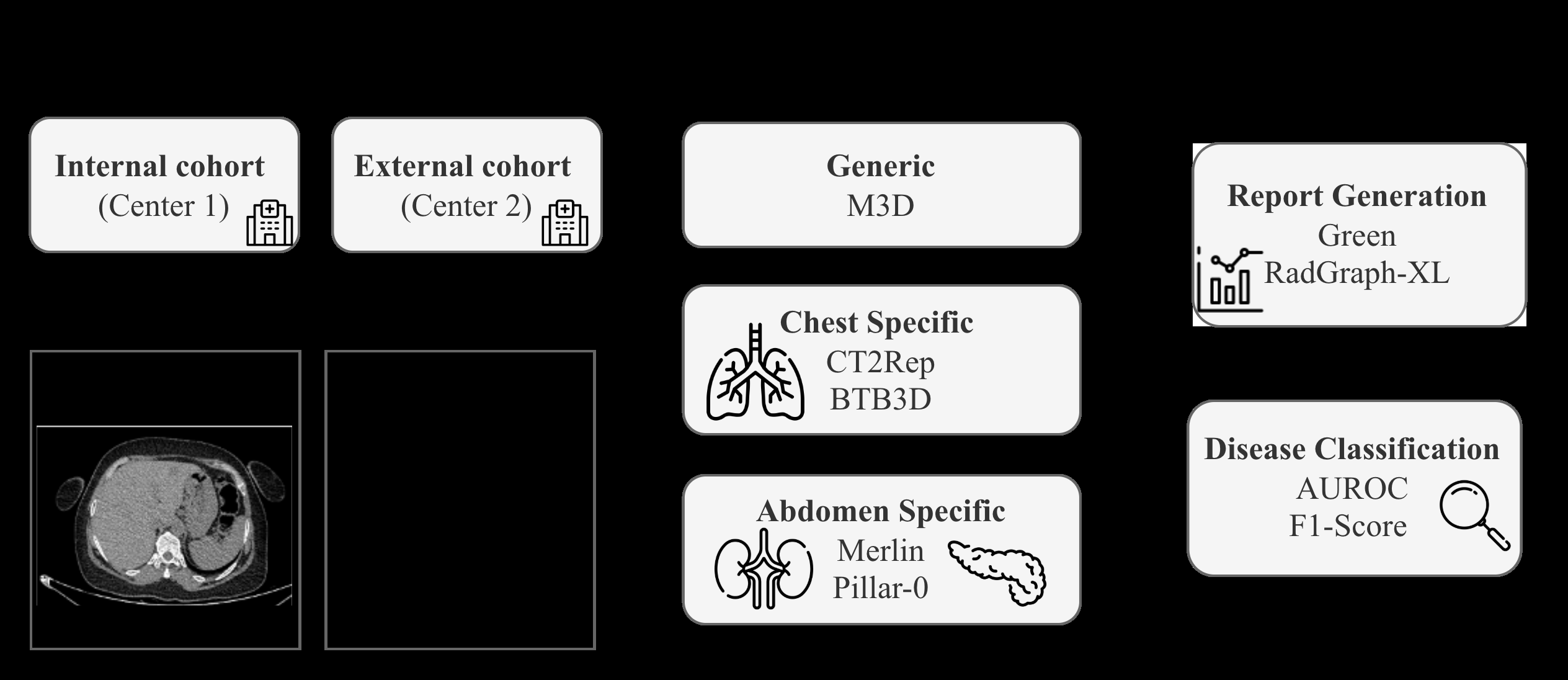
Fig 1: Overview of the benchmark workflow.

Fig 2: A comparison between AI-generated findings and expert ground truth (GT)
Limitations
- NCCT fundamentally cannot capture dynamic contrast kinetics necessary for some lesion characterizations, placing a ceiling on achievable diagnostic accuracy.
- External validation cohort exhibits performance degradation due to scanner and population heterogeneity, indicating need for domain adaptation.
- Report evaluation does not include pixel-level lesion grounding, relying on text and clinical label extraction which may introduce noise despite audits.
- Dataset population is regionally specific (Egyptian centers), which may limit immediate generalizability globally.
- Study lacks prospective clinical trial validation and does not assess impacts on actual radiologist workflow or patient outcomes.
Open questions / follow-ons
- How can domain adaptation techniques further improve external validation performance across diverse scanner types and patient populations?
- Can pixel-level lesion localization or segmentation integrated with report generation improve clinical transparency and trustworthiness?
- What is the clinical impact of deploying NCCT-based AI reporting workflows in resource-limited or high-risk patient settings?
- How might temporal or multi-phase modeling innovations compensate for missing contrast kinetic information in NCCT?
Why it matters for bot defense
This work is relevant to bot-defense and CAPTCHA practitioners primarily in demonstrating large-scale multimodal dataset curation and benchmark design under multi-institutional heterogeneity, illustrating the challenges of domain adaptation and robust generalization across medical imaging centers. The approach to evaluating not only raw performance metrics but clinically meaningful metrics (GREEN, RadGraph-XL) parallel efforts in bot detection where domain-specific metrics must be prioritized. Furthermore, the use of vision-language models and layered benchmarking highlights methodologies for developing robust AI systems that can extract subtle latent signals from limited or noisy inputs — an insight potentially transferable to bot-detection signal design when obscured or indirect features are present. Lastly, the transparent release of data and reproducible pipeline sets an example for community benchmarking standards important for security research.
Cite
@article{arxiv2606_16991,
title={ A Multi-Center Benchmark for Abdominal Disease Diagnosis and Report Generation from Non-Contrast CT },
author={ Mariam Elbakry and Aliaa Sayed Sheha and Salma Hassan Tantawy and Aya Yassin and Concetto Spampinato and Karim Lekadir and Xiaomeng Li and Marawan Elbatel },
journal={arXiv preprint arXiv:2606.16991},
year={ 2026 },
url={https://arxiv.org/abs/2606.16991}
}