
VaultxGPU: GPU-Accelerated Blockchain Consensus
Source: arXiv:2606.14007 · Published 2026-06-12 · By Samuel Taiwo Fatunmbi, Om Amit Gandhi, Luke Logan
TL;DR
This paper addresses the high computational and energy cost of Proof-of-Work (PoW) blockchain consensus by focusing on accelerating Proof-of-Space (PoSp) plot generation, a more energy-efficient alternative where storage replaces repeated hashing. While prior CPU-based plotters like VaultX used multithreaded Blake3 hashing to improve plotting speed dramatically over the Chia reference plotter, the authors identify that CPU parallelism eventually plateaus under hardware limits. VaultxGPU extends this by offloading the entire Blake3 hashing pipeline and subsequent sorting and matching stages to GPU architectures, supporting NVIDIA via CUDA and AMD/Intel via SYCL. This design exploits massive GPU parallelism, eliminating CPU bottlenecks and minimizing costly data transfers through clever memory management and kernel fusion techniques.
Evaluation across K-values 27 through 31 demonstrates that VaultxGPU achieves speedups of up to 59.2× over a naive single-threaded CPU baseline and outperforms even highly parallel CPU configurations (up to 384 cores). The SYCL implementation slightly outperforms CUDA at larger problem sizes, showing near-ideal linear scaling as the workload doubles. The main remaining bottleneck is sequential disk I/O during plot file writes. The results firmly establish GPU acceleration as the scalable solution for Proof-of-Space plotting beyond CPU threading limits.
Key findings
- SYCL GPU implementation achieves a 59.2× speedup over single-threaded CPU baseline at K=31, completing plotting in 45.4 seconds versus 2688 seconds.
- CUDA GPU implementation achieves 50.0× speedup (53.8 seconds) at K=31, slightly slower than SYCL but still highly performant.
- Best 384-thread CPU configuration achieves 51.5× speedup but at much higher hardware cost compared to GPU solutions.
- Disk write stage accounts for 59–82% of total runtime across K-values, representing the primary performance bottleneck.
- Insertion sort in fused Sort+Match kernel creates an O(n^2) bottleneck rising from 11% of pipeline time at K=27 to 34% at K=31.
- SYCL GPU maintains near-ideal linear scaling with runtime ratios of 1.95× to 2.03× across K=27 to K=31; CUDA kernel management degrades at larger K, reaching 2.40× ratio at K=31.
- CPU parallel efficiency drops sharply beyond 16 threads, reaching only 14% efficiency at 384 threads, limiting performance gains from additional cores.
- VaultxGPU produces plot files fully byte-compatible with prior VaultX CPU prover, enabling seamless integration.
Threat model
The adversary is a blockchain participant who aims to efficiently generate Proof-of-Space plots to compete in consensus mining. They have access to commodity CPUs and GPUs but cannot bypass cryptographic guarantees or tamper with kernel execution. The system does not consider adversarial GPU attacks or attempts to falsify proof data.
Methodology — deep read
Threat Model & Assumptions: The adversary is a blockchain miner aiming to generate Proof-of-Space plots as rapidly as possible to participate efficiently in the consensus protocol. The attackers are assumed honest but resource-constrained. The system assumes access to GPUs across vendors but does not address adversarial attempts to tamper with GPU kernel execution or break cryptographic hashing.
Data: Plot generation involves hashing a full space of 2^k nonces (with k ranging 27 to 31), resulting in very large datasets stored as Table-1 and Table-2 structures holding nonce-hash pairs in buckets. Data is stored temporarily in GPU VRAM for maximal parallel processing, with final plot files written sequentially to disk. No external datasets are used—this is computation-centric benchmarking.
Architecture/Algorithm: VaultxGPU re-architects the VaultX CPU pipeline by implementing a custom Blake3 keyed hashing kernel for GPUs, assigning one GPU thread per nonce to compute hashes independently within thread registers, eliminating inter-thread synchronization. The hashing output is stored into 2^24 buckets using atomic insertions in GPU VRAM. Sort and matching stages are fused into a single GPU kernel operating entirely in shared (CUDA) or local (SYCL) memory per bucket, performing insertion sort and pairwise matching without global memory round-trips.
CUDA and SYCL implementations share a common Blake3 hashing kernel but differ in memory model: CUDA utilizes constant memory for the plot key and implicit atomics, SYCL uses malloc_device for key storage and explicit atomic_ref objects with declared memory order and scope.
Training Regime: N/A - empirical performance benchmarking was done on physical hardware. CUDA tests ran on Tesla V100 NVIDIA GPUs with a 192-core or 64-core CPU servers; SYCL tests ran on AMD Vega 20 and Intel DG2 Arc A770 GPUs paired with a 6-core CPU. CPU baselines used a 64-core server with thread counts from 1 to 384. Multiple runs recorded, best times reported.
Evaluation Protocol: Evaluated total plot generation time for k=27 to k=31, comparing single-thread CPU baseline, multi-threaded CPU up to 384 threads, CUDA GPU, and SYCL GPU. Measured per-stage pipeline timing (Table-1 hashing, Sort+Match, disk write), parallel efficiency and scaling (runtime ratios T(k+1)/T(k)), speedup relative to naive CPU baseline, and cross-implementation runtime comparisons.
Observed pipeline stage bottlenecks and scalability. No adversarial or robustness tests. No cross-validation as this is pure system performance measurement.
- Reproducibility: Authors released VaultxGPU integrated into VaultX, fully compatible plot files, and detailed implementation differences for CUDA and SYCL. The Blake3 kernel source is shared. Dataset (plot files) generated on-demand as per k-value, not externally sourced or closed. Hardware specifics and software dependencies are described, enabling reproduction assuming access to similar GPUs. No mention of open-sourced codebase but methods described in depth.
Example end-to-end iteration: For K=31 plotting, the GPU launches 2^31 threads each hashing a unique nonce via per-thread Blake3 keyed hashing, atomically inserting outputs into bucket arrays in GPU VRAM. Fused sort+match kernel runs with one GPU block per bucket, loading bucket data into shared memory, performing insertion sort by hash, then pairwise matching to produce Table-2 records entirely on-device. Table-2 is then copied via PCIe to host CPU memory for sequential disk write in optimized 4MB chunks, completing in 45.4 seconds on SYCL GPU vs 2688 seconds baseline.
Technical innovations
- Custom GPU kernel fully parallelizing Blake3 keyed hashing by assigning one thread per nonce and performing complete hash computation within thread registers, eliminating cross-thread dependencies.
- Dual backend implementation using CUDA for NVIDIA GPUs and SYCL for AMD/Intel GPUs with a shared Blake3 kernel but adapted memory and atomic operations respecting vendor-specific constraints.
- Fusion of sort and match stages into a single GPU kernel executing entirely within shared/local memory per bucket, removing intermediate global memory transfers and reducing overhead.
- Integration of GPU-accelerated plotter producing byte-compatible outputs with existing CPU-based VaultX prover, maintaining interoperability.
Baselines vs proposed
- Single-threaded CPU baseline at K=31: 2688 seconds vs SYCL GPU: 45.4 seconds (59.2× speedup)
- 384-thread CPU at K=31: 52.2 seconds vs CUDA GPU: 53.8 seconds (CYUDA slightly slower) vs SYCL GPU: 45.4 seconds (SYCL best)
- SYCL CPU fallback at K=31: 99.2 seconds vs SYCL GPU: 45.4 seconds (2.18× faster)
- Disk write stage accounts for 59-82% of total time regardless of compute backend
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.14007.
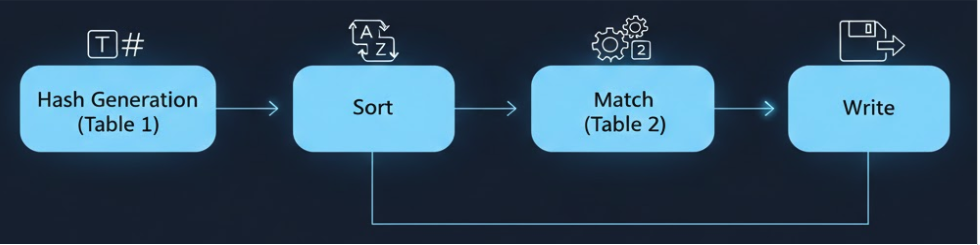
Fig 1: hash generation produces Table-1 by hashing all 2k
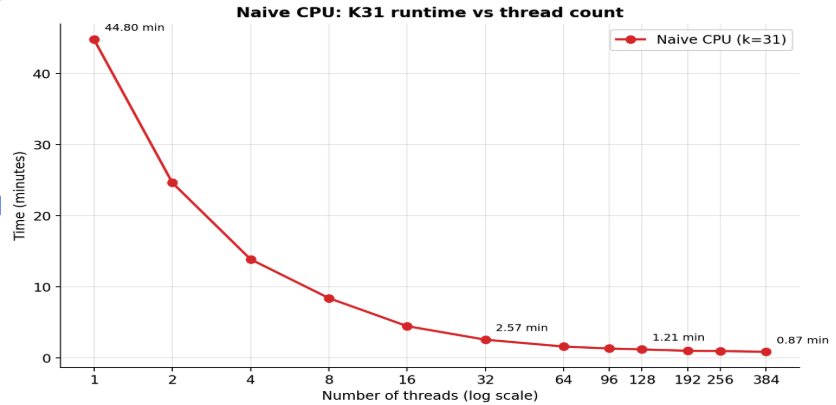
Fig 2: VaultX CPU K=31 runtime vs. thread count across server-grade
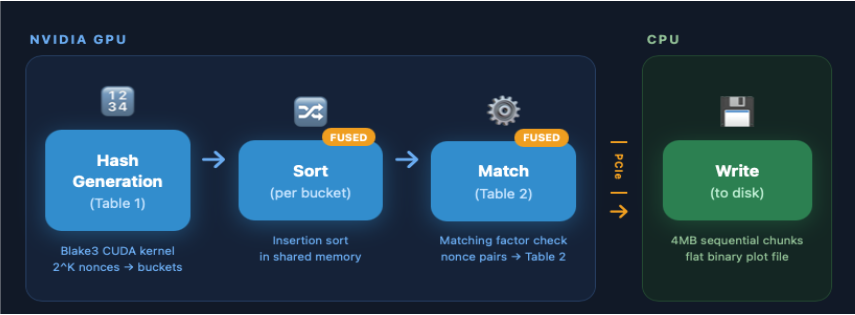
Fig 3: VaultxGPU pipeline: Hash Generation and fused Sort+Match stages
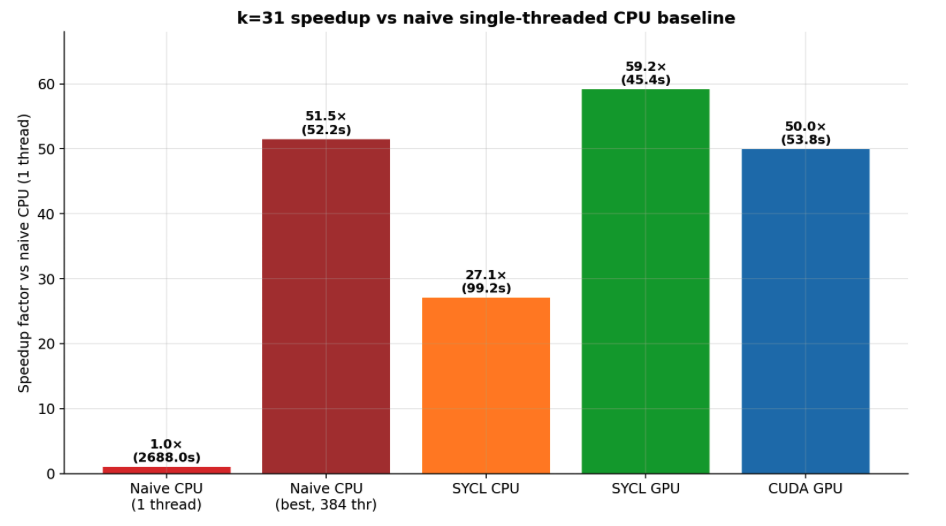
Fig 4: Speedup at K = 31 relative to naive single-threaded CPU baseline
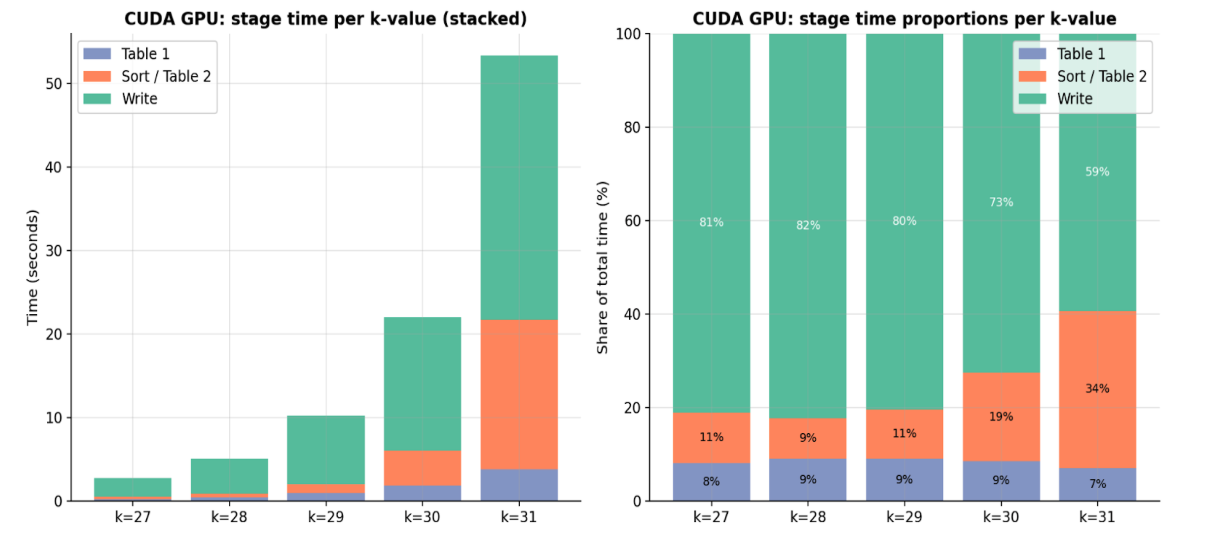
Fig 5: CUDA GPU per-stage time breakdown across K-values 27–31,
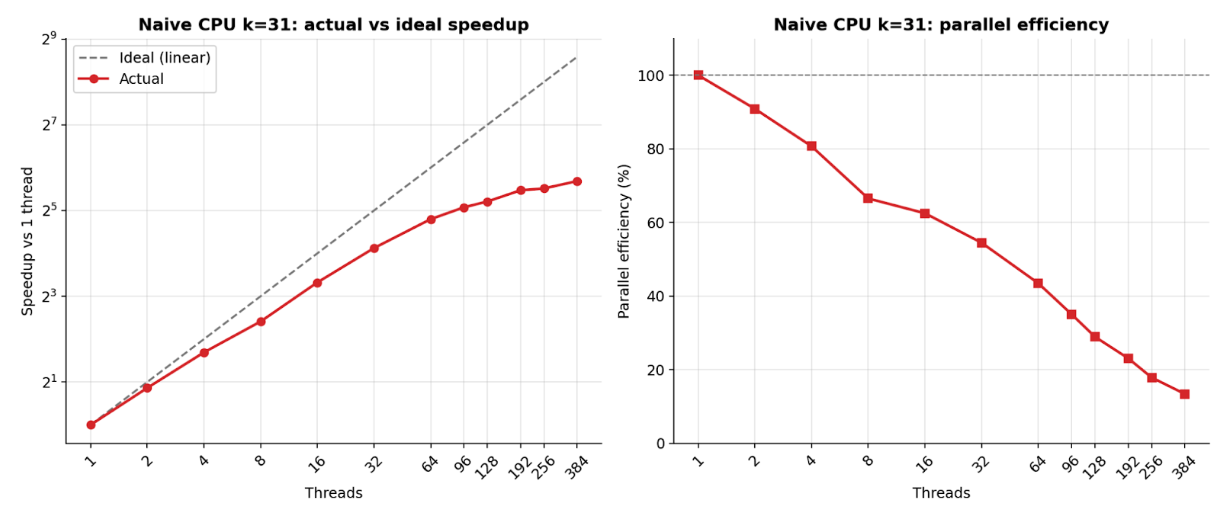
Fig 6: shows the actual versus ideal speedup and parallel
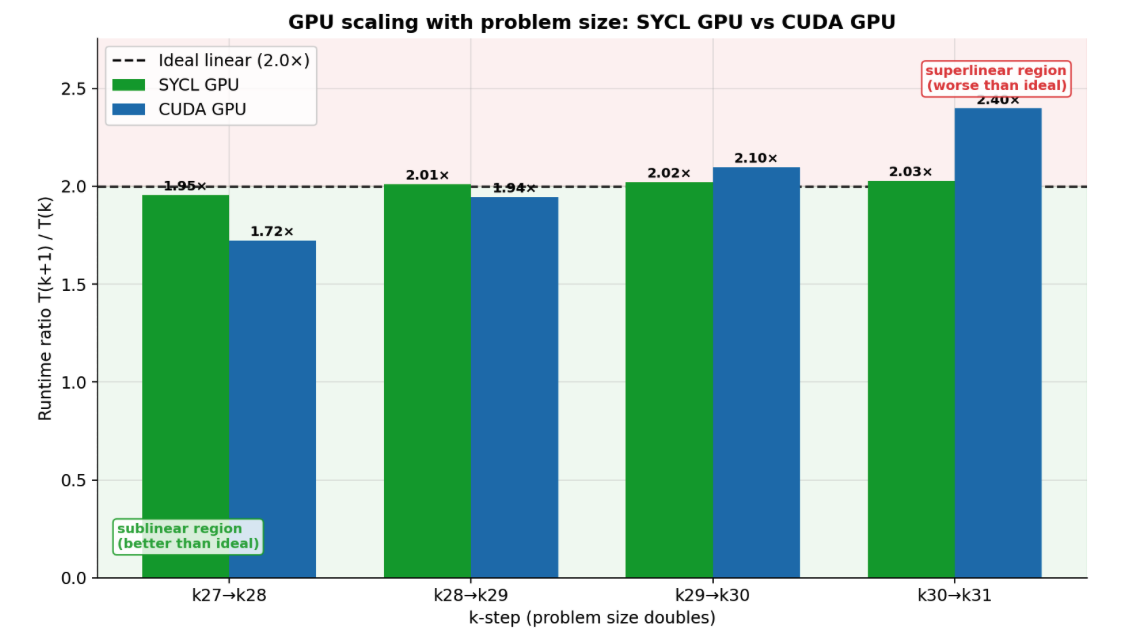
Fig 7: GPU scaling with problem size: runtime ratio T(k + 1)/T(k) for
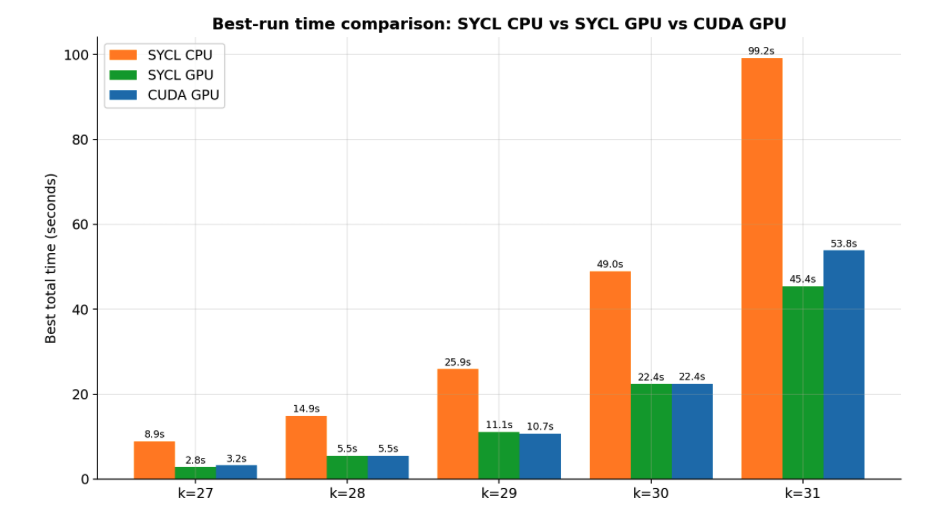
Fig 8: Best-run time comparison across all K-values for SYCL CPU, SYCL
Limitations
- Disk I/O for final plot file writes dominates overall runtime (59–82%), limiting end-to-end speedup despite GPU acceleration.
- The insertion sort algorithm used in the fused sort+match stage is O(n^2) and becomes a critical bottleneck at larger K-values (rising to 34% of runtime at K=31).
- CUDA kernel management overhead increases at larger bucket sizes, degrading scaling and causing superlinear runtime increase from K=30 to K=31.
- SYCL implementation incurs extra memory fetches for plot key due to lack of constant memory abstraction, slightly reducing performance compared to CUDA.
- No adversarial testing or robustness evaluation against malicious GPU hardware or attacks on hashing correctness.
- Evaluation limited to k-values up to 31 and hardware tested; extension to larger k requires further VRAM tiling strategies.
Open questions / follow-ons
- How to implement GPU-parallel sorting algorithms (e.g., radix or merge sort) to replace the insertion sort and remove the O(n^2) bottleneck during the sort+match stage?
- How to optimize the disk write pipeline by overlapping PCIe transfers with GPU compute using asynchronous streams or exploring direct NVMe write paths to reduce I/O overhead?
- What strategies enable support for K-values beyond 31 via chunked VRAM tiling or multi-GPU coordination without reverting to CPU fallbacks?
- Can the designs be extended to heterogeneous or distributed GPU environments while maintaining deterministic byte-compatible plot output?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, VaultxGPU illustrates a high-impact application of GPU acceleration to a cryptographic hashing-heavy workload that was previously CPU-bound. The paper highlights effective patterns for offloading hash computations to GPUs by assigning fine-grained work units per thread and managing memory layout to minimize costly transfers—a strategy applicable to defending or detecting bots based on GPU-accelerated hashing or puzzle-solving capabilities.
Moreover, the cross-vendor SYCL implementation approach indicates a practical path toward portable GPU security primitives beyond proprietary CUDA stacks, important for diverse security infrastructure. Understanding how bottlenecks shift from compute to I/O phases informs CAPTCHA designers about expansion limits and the critical value of kernel fusion and atomic operations when porting crypto workloads to accelerators under adversarial resource constraints.
Cite
@article{arxiv2606_14007,
title={ VaultxGPU: GPU-Accelerated Blockchain Consensus },
author={ Samuel Taiwo Fatunmbi and Om Amit Gandhi and Luke Logan },
journal={arXiv preprint arXiv:2606.14007},
year={ 2026 },
url={https://arxiv.org/abs/2606.14007}
}