
Typical Healthcare Pathways as a Basis for Admixture Modeling of Patient Trajectories
Source: arXiv:2606.14587 · Published 2026-06-12 · By Maryam Farhadizadeh, Carola S. Heinzel, August Sigle, Harald Binder, Frederik Wenz, Jan Hasenauer et al.
TL;DR
This paper addresses the challenge of representing heterogeneous patient care trajectories in routine healthcare data where patients differ in diagnostic, treatment sequences, timing, and event documentation. The authors propose a novel framework that separates cohort-level pathway identification from patient-level inference. At the cohort level, a rule-based algorithm constructs a compact and interpretable pathway graph summarizing typical healthcare pathways by collapsing and pruning raw prefix trees built from temporally ordered event blocks across patients. These pathways are modeled as pathway-specific Markov chains. At the patient level, an admixture model represents each patient trajectory as a probabilistic combination of these typical pathways rather than forcing a single cluster assignment. The patient-specific admixture weights provide a low-dimensional and clinically meaningful embedding of patient care sequences useful for subgroup discovery.
Applied to routine inpatient care data from 995 prostate cancer patients undergoing radical prostatectomy, the framework revealed stable and interpretable pathway structures across multiple train-test splits. Admixture patterns consistently captured patient heterogeneity in typical treatment patterns. The approach supports robust subgroup identification based on shared pathway mixtures and offers a scalable method to summarize complex, branching healthcare trajectories while maintaining clinical interpretability. The paper also includes a simulation study to validate recovery of latent pathways and admixture proportions.
Overall, the contribution is an interpretable, stable, and modular method to disentangle cohort-level pathway structure from patient-level heterogeneity, enabling improved characterization of real-world clinical practice variation.
Key findings
- Dataset of 995 prostate cancer patients with 6904 inpatient events and 167 distinct event states.
- Rule-based cohort-level typical pathway algorithm reduces raw prefix trees to compact graphs by vertical/horizontal collapsing, pruning, and backward merging.
- Node importance scoring prioritizes nodes occurring in ~50% of patients per care stage for structural relevance.
- Markov chains derived for each typical pathway capture dominant transition probabilities over common state space.
- Admixture model represents individual patient trajectories as probabilistic mixtures over K typical pathways (K=3 used here).
- Admixture weights inferred by EM and constrained numerical optimization, maximizing likelihood under simplex constraints.
- Framework yields consistent pathway graphs and admixture weights across repeated train-test splits (80% train / 20% test), demonstrating stability.
- Patient subgroups identified by clustering admixture weights exhibit clinically meaningful shared care patterns.
- Simulation study confirms ability to recover latent pathway structure and admixture proportions under known mixing.
Threat model
n/a — The paper does not explicitly address an adversarial threat scenario; it focuses on modeling and interpretable representation of heterogeneous healthcare trajectories rather than on security or attack resilience.
Methodology — deep read
Threat model & assumptions: The approach addresses structural heterogeneity of observational healthcare trajectory data without explicit adversary assumptions. The goal is to identify dominant cohort-level pathway structures despite patient-level variability. It assumes routine clinical event logs coded with ICD-10 and OPS codes, with event blocks (sets of codes at same timestamp) defining discrete care stages. Evaluation avoids information leakage by strictly separating train/test patient splits.
Data: Data comes from 995 prostate cancer patients undergoing radical prostatectomy at University Medical Center Freiburg between 2015-2020, totaling 6904 inpatient clinical events. Events include 4 ICD-10 admission codes and 162 OPS procedure codes mapped into 167 states. Each patient trajectory is a temporally ordered sequence of event blocks, each a set of codes recorded at one timestamp, including discharge as terminal event. Patient cohort is randomly split into 80% training and 20% test sets for reproducibility.
Architecture/algorithm: Step 1: Cohort-level typical pathway algorithm builds a prefix tree by sequentially inserting patient trajectories from training data, mapping event blocks at each stage to tree nodes. Each node Ni holds a set of events si, patient count ci, and patient IDs Ii. Directed edges connect nodes in temporal order with weights reflecting transition frequencies. Nodes within the same care stage are assigned an importance score calculated as min(pi, 1-pi) * total stage size, where pi is relative node frequency within the stage, prioritizing nodes that split patients evenly (~50%).
Four main tree simplification operations reduce complexity while preserving key structure: vertical collapsing merges nodes with overlapping important procedure subsets within the same care stage; horizontal collapsing merges consecutive nodes below importance threshold on linear branches; pruning removes infrequent nodes via absolute (α) and relative (β) patient count thresholds; backward merging re-assesses vertical collapsing bottom-up to capture latent merges missed forward.
Step 2: The simplified pathway graph defines K typical pathways as sequences of nodes from root to terminal node. For each typical pathway k, a discrete first-order Markov chain is modeled via empirical transition counts within that pathway, yielding transition matrix Pk. Patient trajectories in test data are modeled as probabilistic admixtures over these K fixed Markov chains; admixture weights qi reflect contribution of each pathway to patient i's trajectory.
Admixture weights are estimated by maximizing the log-likelihood of observed state transitions under the mixture model constrained to the simplex. Both EM algorithm and constrained numerical optimization (SLSQP) are used for inference, starting from uniform admixture weights, iterating until convergence.
Training regime: Training comprises building the prefix tree and pathway graph on 80% of data. Transition matrices are estimated from training pathways. Patient-level admixture weights are inferred for test set patients only, ensuring no data leakage. No explicit mention of epochs or batch sizes as optimization is deterministic likelihood maximization.
Evaluation protocol: Stability analyses are performed by repeating random 80-20 train-test splits multiple times. Consistency of pathway graphs and admixture patterns across splits is assessed. Subgroup identification is performed by clustering patients in the admixture weight space, associating clusters with distinct clinical event patterns. A simulation study evaluates recovery of latent pathways and admixture proportions under controlled mixing scenarios.
Reproducibility: Code availability or dataset access is not explicitly stated. Dataset is from a German university hospital clinical routine data with patient privacy considerations likely restricting public availability. The methodology uses interpretable algorithms with full parameter details allowing replication given access to similar data.
Example end-to-end: A patient trajectory from test set (not in training) is described as ordered event blocks. Using the fixed cohort-level pathway graph and associated Markov matrices from training data, pathway-specific transition probabilities for each observed state transition are obtained. The admixture weights are optimized to maximize the likelihood of the observed trajectory as a mixture of these pathway Markov chains, yielding a vector quantifying how much each typical pathway explains this patient’s care progression. This vector provides a low-dimensional embedding for patient subgroup analysis.
Technical innovations
- Rule-based algorithm to identify typical cohort-level healthcare pathways by compressing prefix trees through collapsing/pruning guided by node importance scoring favoring balanced splits.
- Use of pathway-specific Markov chains as structured components representing typical pathways over a shared state space, in contrast to purely clustering or topic modeling.
- Admixture model inference to represent each patient trajectory as a probabilistic mixture over multiple typical pathways instead of hard assignment, capturing complex heterogeneity.
- Development of a stable train-test separated framework ensuring cohort-level pathway graphs serve as fixed scaffolds for independent patient-level admixture inference.
Datasets
- Prostate cancer inpatient routine care data — 995 patients and 6904 clinical events — University Medical Center Freiburg (non-public)
- Simulation datasets — synthetic trajectories with known pathway mixing — generated for validation
Baselines vs proposed
- Comparison of EM vs SLSQP optimization methods for admixture weight inference showing stable convergence (exact values not specified).
- Repeated train-test splits (random 80/20 partitions) demonstrate stable typical pathway structures across splits (Fig 3).
- Patient admixture patterns consistent across splits enabling reproducible subgroup clusters (no exact cluster metrics provided).
- Simulation study confirms method robustly recovers latent pathways and admixture weights with high accuracy under controlled scenarios (details in supplement).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.14587.
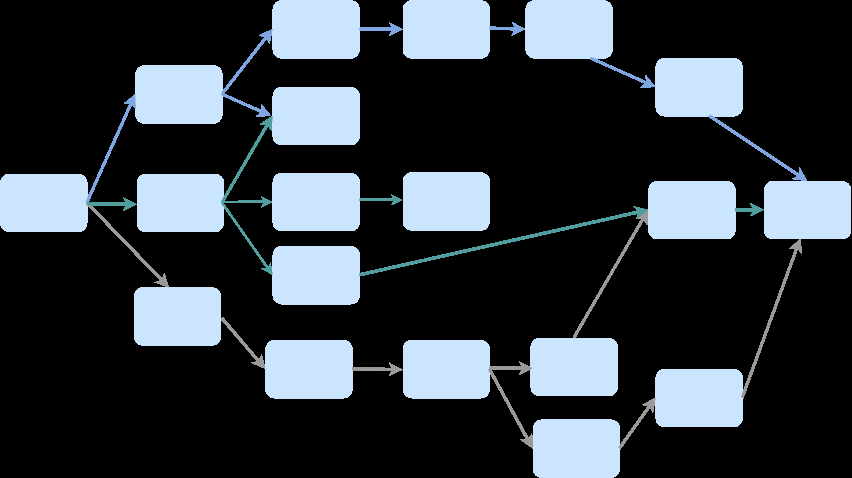
Fig 1: Overview of the proposed three-step framework for identifying typical healthcare path-

Fig 2: Illustration of the graph simplification operations used in the cohort-level pathway al-
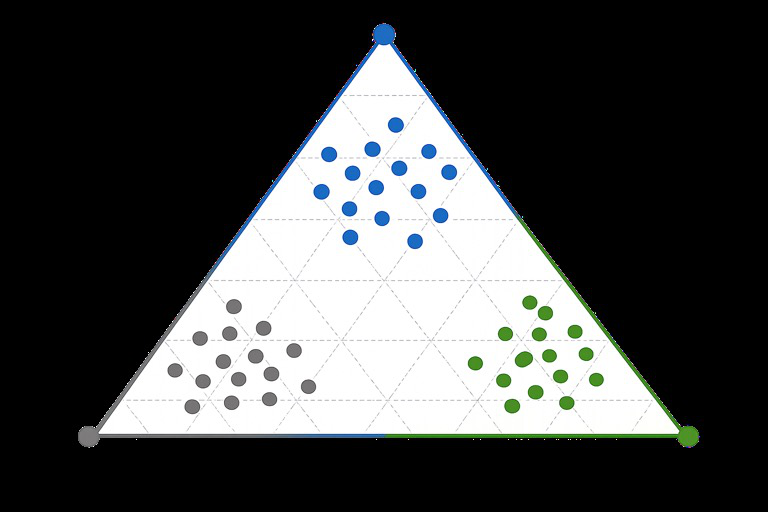
Fig 3 (page 6).
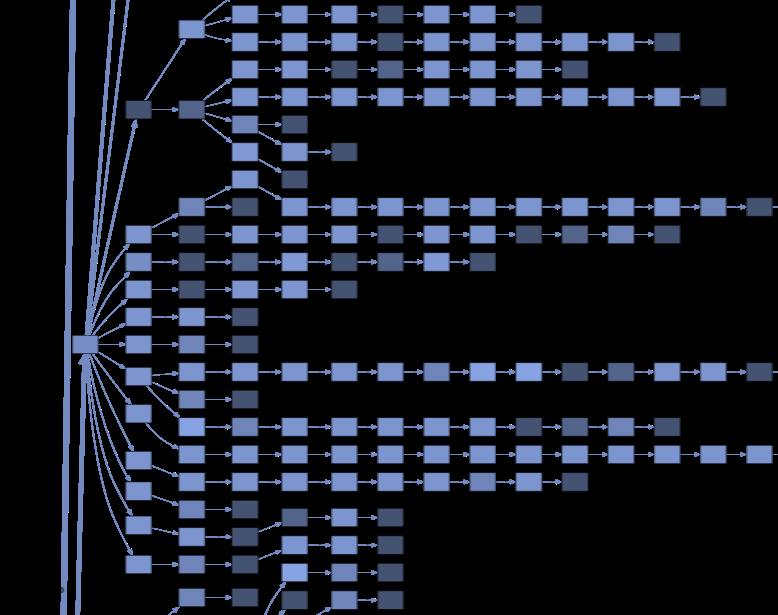
Fig 4 (page 6).
Fig 5 (page 6).

Fig 6 (page 7).
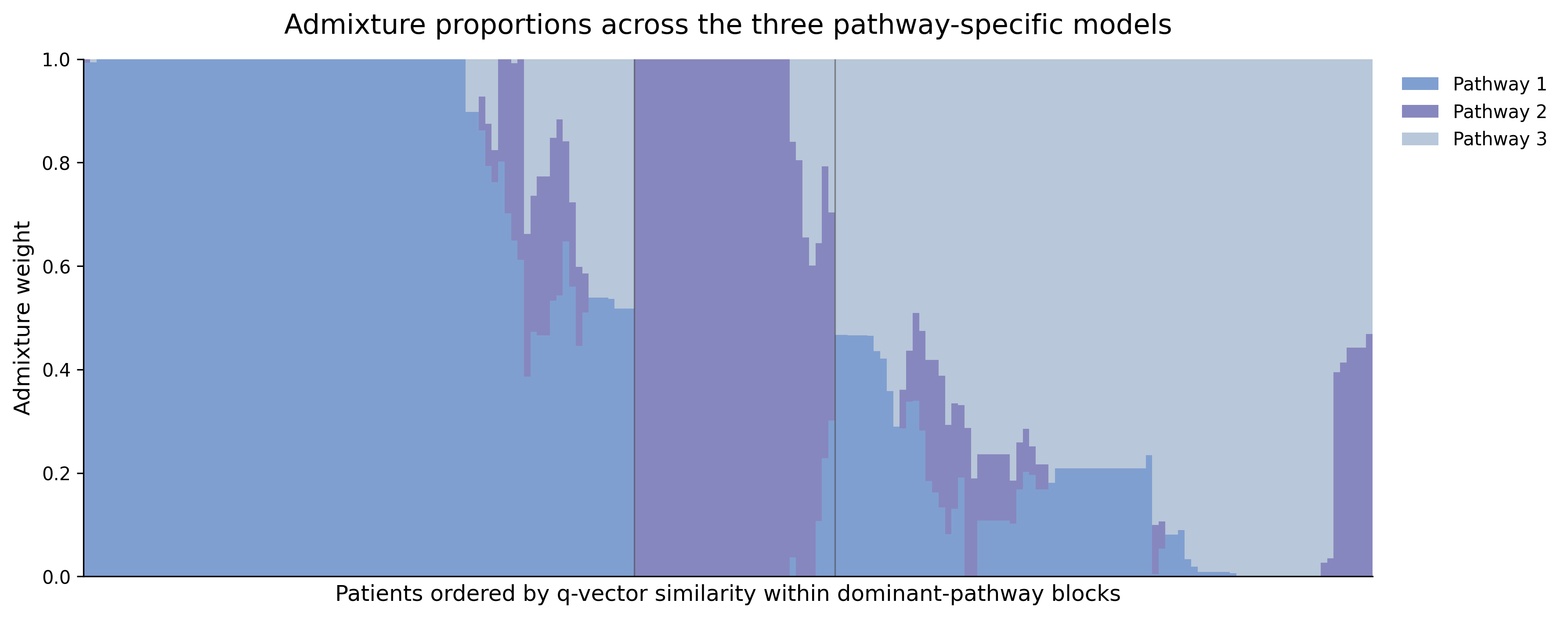
Fig 4: Stacked bar plots showing admixture proportions across the K = 3 inferred pathway
Limitations
- Method relies on first-order Markov assumption which may oversimplify longer-range temporal dependencies in healthcare trajectories.
- Event coding variability and documentation practices may introduce noise not accounted for beyond importance-based pruning.
- No adversarial or noisy-data robustness evaluation reported; practical EHR datasets may include errors or missing events.
- Dataset is limited to inpatient prostate cancer radical prostatectomy patients from a single center limiting generalizability.
- No explicit open code or data release limits external reproducibility and benchmarking.
- Choice of importance thresholds and number of typical pathways K requires user input and heuristic tuning.
Open questions / follow-ons
- Can the admixture model be extended to capture higher-order or non-Markov temporal dependencies in patient trajectories?
- How robust is the pathway identification and admixture inference framework under noisy or partially missing EHR data?
- How does the framework generalize across different diseases, hospital systems, or outpatient care settings with different coding practices?
- Can the admixture representations improve downstream predictive models, e.g., for patient outcomes or clinical decision support?
Why it matters for bot defense
While this paper does not address bot defense or CAPTCHA directly, the methodology for deriving cohort-level typical pathway graphs and modeling individual sequences as admixtures of typical pathways offers conceptual parallels to behavioral biometrics in bot detection. That is, it models heterogeneous sequential data with structured probabilistic components to identify subgroups, which is akin to identifying typical human and bot interaction patterns. The pathway identification and admixture inference methods provide interpretable, low-dimensional embeddings summarizing complex sequences that could inform anomaly or subgroup detection in user behavior logs.
For CAPTCHA practitioners, the rule-based graph simplification and admixture modeling approach suggests a principled way to reduce high-dimensional sequential event data (e.g., mouse movements, click patterns) into a compact representation capturing mixture membership over typical behavioral pathways. Such embeddings could support distinguishing human users from bots by characterizing shared and divergent interaction trajectories. However, adaptation would require addressing real-time constraints and adversarial evasion not studied here.
Cite
@article{arxiv2606_14587,
title={ Typical Healthcare Pathways as a Basis for Admixture Modeling of Patient Trajectories },
author={ Maryam Farhadizadeh and Carola S. Heinzel and August Sigle and Harald Binder and Frederik Wenz and Jan Hasenauer and Peter Pfaffelhuber and Nadine Binder },
journal={arXiv preprint arXiv:2606.14587},
year={ 2026 },
url={https://arxiv.org/abs/2606.14587}
}