
Security Engineering of OpenClaw: Analyzing Attack Surface Expansion and Trust-Boundary Violations
Source: arXiv:2606.15008 · Published 2026-06-12 · By Saeid Jamshidi, Arghavan Moradi Dakhel, Kawser Wazed Nafi, Foutse Khomh
TL;DR
This paper investigates the security risks that arise when large language model (LLM) agents have the capability to execute privileged system actions, focusing on the OpenClaw self-hosted multi-agent system. The core problem is the shift from traditional text generation alignment challenges to broader architectural and configuration vulnerabilities when LLM outputs trigger system commands, browser automation, or tool calls. The authors present a formal structural analysis that quantifies how the aggregation of multiple agents under permissive execution policies dramatically increases the system's probability of compromise, boundary failures, and privilege escalation beyond that of any individual agent. They introduce new metrics including attack surface entropy, cumulative boundary instability, privilege drift, and escalation curvature to capture nuanced systemic risk dynamics. Empirical results show compromise probability rises from 0.24 with one agent to 0.86 with seven agents when execution occurs if any agent proposes an action. Defensive controls such as policy gating and execution filtering reduce compromise probability by 0.10 and privilege drift by 0.02, but with trade-offs in task utility and latency. Different LLM backends exhibit varying injection mitigation success rates, shaping overall system exposure. This work provides structured methodologies and quantitative insights into the expanded attack surfaces and trust-boundary violations emerging from multi-agent LLM deployments with direct execution capability.
Key findings
- Compromise probability increases from 0.24 with a single agent to 0.86 when seven agents operate under a permissive aggregation policy, representing a 3.58× amplification.
- Attack surface entropy rises from 0.42 to 0.71 when moving from one to multiple agents, indicating a broader distribution of exploit paths.
- Mean privilege drift (unintended authority gain) increases from 0.03 to 0.21 in multi-agent scenarios, showing stronger privilege escalation.
- Positive escalation curvature of 0.08 demonstrates that privilege grows super-linearly as attacker capability increases.
- Defensive controls reduce compromise probability by 0.10, boundary failures by 0.10, and privilege drift by 0.02, all statistically significant at p < 0.0001.
- Injection mitigation effectiveness varies by model: 0.37 for GPT-5.2, 0.35 for Llama-4-Maverick, and 0.31 for DeepSeek-R1.
- Under permissive aggregation, the agent with the highest vulnerability dictates overall system exposure.
- Mitigation strategies reduce task utility slightly (0.93 to 0.89) and increase median latency from 420 ms to 468 ms.
Threat model
The adversary is capable of network-level access ranging from local to full internet reach, can inject and manipulate messages consumed by the agents (e.g., via Slack, Telegram), can introduce malicious skills or extensions persuading users to activate them, and may hold local system access from standard user to elevated privileges. However, the adversary does not control the LLM models internally nor can subvert cryptographic protections or trusted components directly. The attacker model is explicit and bounded by a normalized 4-dimensional vector representing capabilities across network, injection, skill exploitation, and local privilege domains, supporting monotonic threat escalation analysis.
Methodology — deep read
The authors analyze OpenClaw, a self-hosted multi-agent LLM system where model outputs are directly mapped to executable system operations such as shell commands, filesystem access, network calls, and skill invocation. The system architecture includes multiple trust boundaries: between untrusted external inputs and internal reasoning, and between reasoning agents and execution engines. OpenClaw runs multiple LLM agents instantiated from three backends—GPT-5.2, DeepSeek-R1, and Llama-4-Maverick—in parallel, each generating action proposals. A controller module aggregates agent outputs into executable commands according to defined policies, either permissive (any single agent proposal triggers execution) or consensus-based (majority or more agree).
The threat model assumes adversaries who can control input channels (e.g., messaging connectors like Slack), publish malicious skills, and escalate privileges locally. Attacker capability is represented as a normalized 4-dimensional vector capturing network reachability, message injection ability, skill exploitation, and local privilege level. The authors define a scalar norm over this space to enable monotonic escalation analysis.
To evaluate risk, the system state is formalized as sets of accessible credentials and executable primitives, combined via a scalar privilege function weighting credential count and action breadth logarithmically to model diminishing returns. Privilege drift is measured as changes in privilege state across system transitions induced by adversarial inputs.
The attack surface aggregates multiple exposure vectors (gateway ports, skill installations, tool-execution interfaces) with each vector characterized by measured probability of exploit, impact, privilege amplification ratio, and persistence, all normalized to [0,1]. Attack surface entropy quantifies risk distribution, and curvature measures acceleration of risk growth with attacker strength.
Prompt injection is modeled as adversarial payload concatenation into task inputs, with an Injection Amplification Factor (IAF) defined as the ratio of privilege change under injection versus benign tasks. Experiments systematically vary attacker capabilities and multi-agent configurations to measure system-level compromise probability, boundary failure rates, privilege drift, and injection success per agent and at aggregation policy level.
Algorithm 1 implements a deterministic security evaluation with fixed random seeds controlling LLM stochasticity, simulating attacks on a fixed set of exposure vectors and trust boundaries, and performing static and dynamic analysis of installed skills to assess risks. The process runs independently per agent and aggregates policy-level metrics, enabling attribution of vulnerabilities to specific agents or aggregation dynamics.
Mitigations are formalized as hardening operators transforming the baseline system, evaluated counterfactually under identical attacker scenarios. Defensive controls analyzed include policy gating, execution filtering, consensus enforcement, and injection detection. These are measured for impact on security metrics as well as trade-offs in task utility and latency.
As a concrete example, the single-agent baseline with GPT-5.2 has compromise probability 0.24, which rises to 0.86 when 7 agents operate under permissive aggregation. Applying policy gating reduces compromise by 0.10 and privilege drift by 0.02 but adds latency overhead from 420 to 468 ms. Injection mitigation success rates differ among agents, highlighting heterogeneous model robustness. This quantitative, stepwise evaluation shows how system architecture and policy decisions interact with adversarial capability to reshape risk beyond individual LLM vulnerabilities.
Technical innovations
- A formal risk framework quantifying how multi-agent aggregation policies amplify system-level compromise beyond individual model vulnerabilities.
- Introduction of novel metrics capturing cumulative boundary instability (CBI), attack surface entropy, privilege drift, and escalation curvature to analyze systemic privilege escalation dynamics.
- A scalar attacker capability vector combining network reach, message injection, skill exploitation, and local privilege enabling monotonic escalation analysis.
- Deterministic security evaluation algorithm integrating structural modeling, adversarial stimulation, runtime instrumentation, and policy-based aggregation for repeatable multi-agent risk assessment.
- Counterfactual mitigation evaluation formalized as hardening operators enabling measurable comparison of defensive controls under fixed adversary models.
Baselines vs proposed
- Single-agent baseline (permissive policy): compromise probability = 0.24 vs seven agents: 0.86
- Defended system: compromise probability reduced by 0.10 vs baseline
- Defended system: boundary failures reduced by 0.10 vs baseline
- Defended system: privilege drift reduced by 0.02 vs baseline
- Task utility baseline: 0.93 vs defended: 0.89
- Median latency baseline: 420 ms vs defended: 468 ms
- Injection mitigation success: GPT-5.2 = 0.37, Llama-4-Maverick = 0.35, DeepSeek-R1 = 0.31
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.15008.
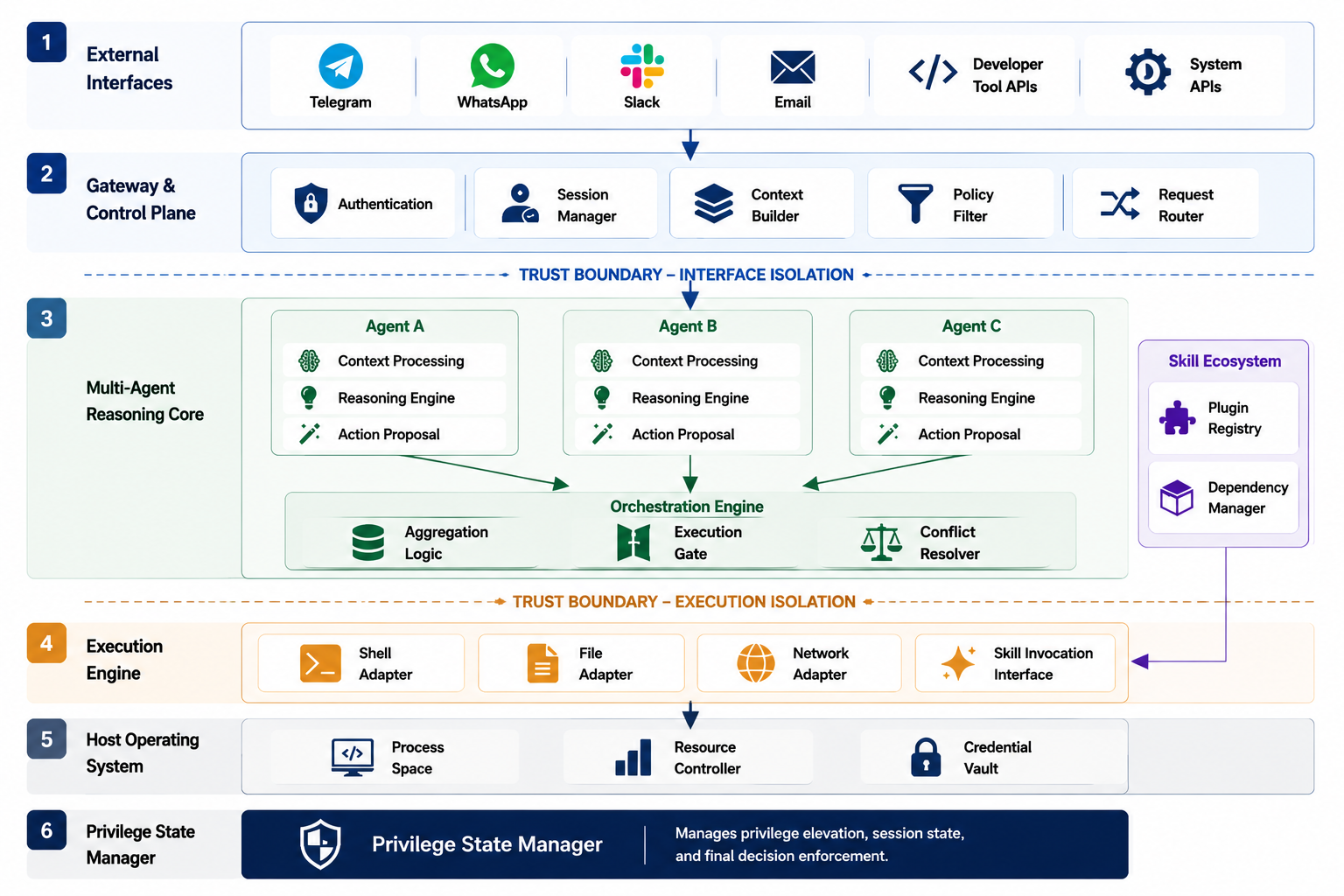
Fig 1: OpenClaw execution-coupled multi-agent system architecture.
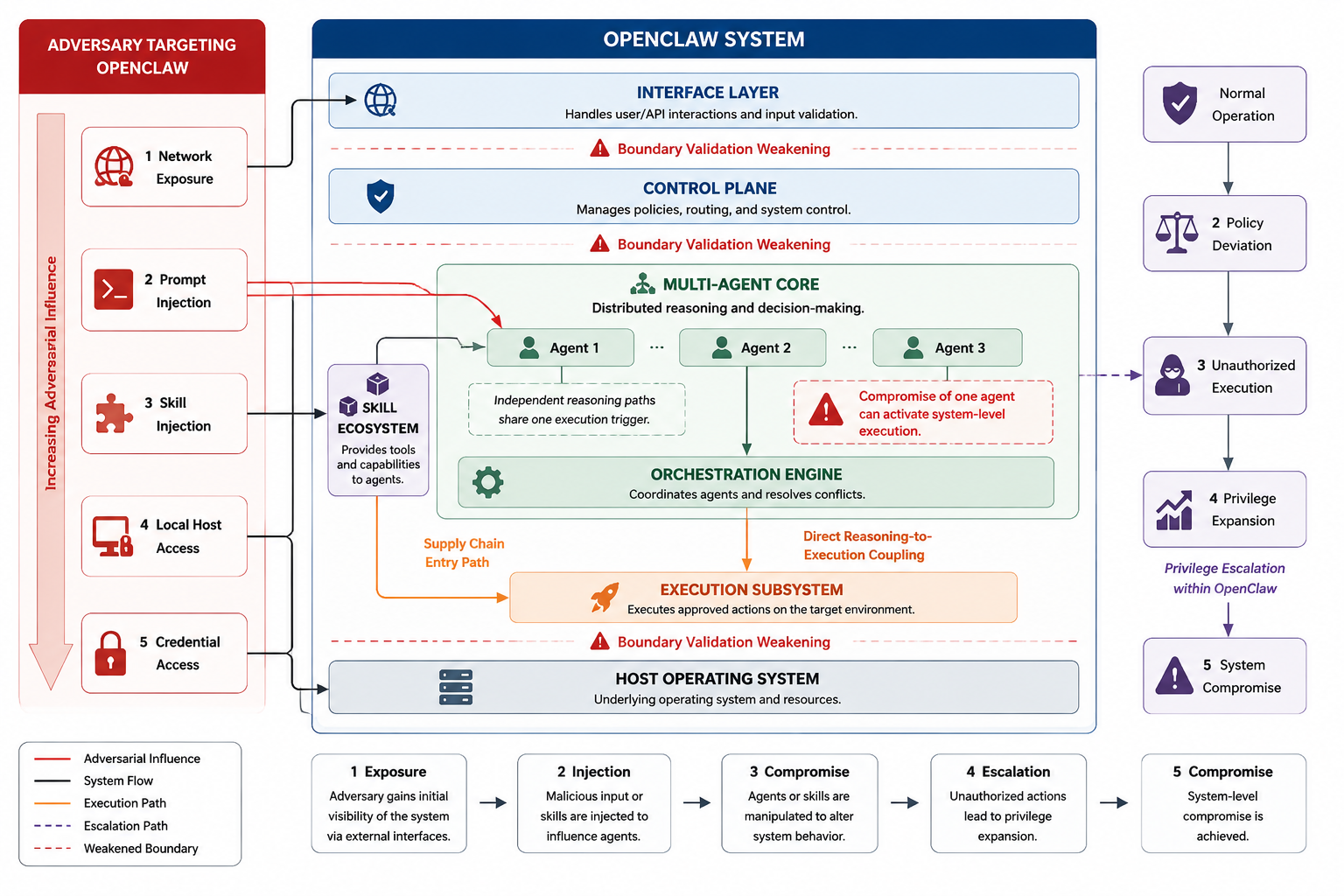
Fig 2: Adversarial escalation paths in OpenClaw, illustrating how network exposure, prompt manipulation, skill injection, local
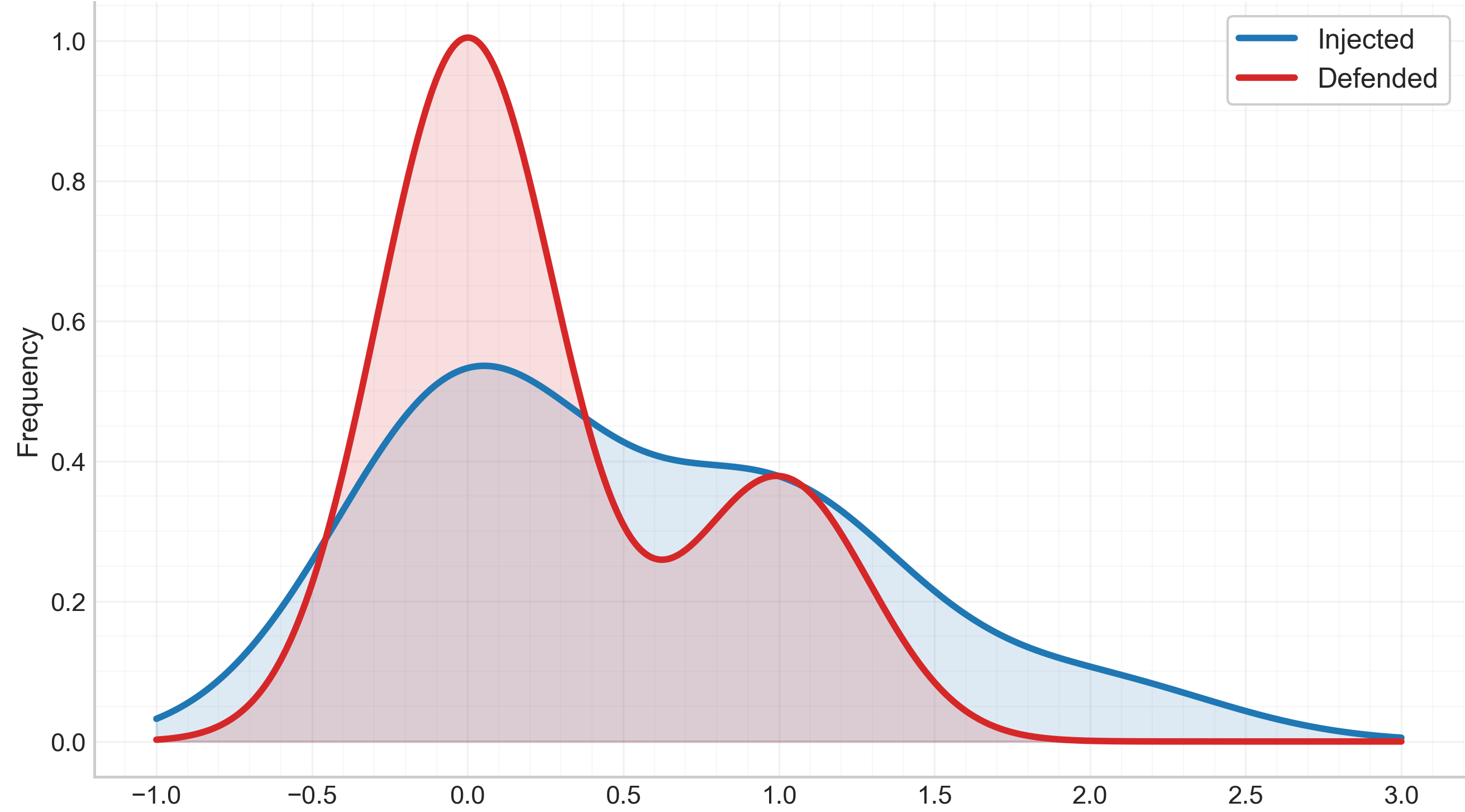
Fig 3: Compromise probability versus number of agents.
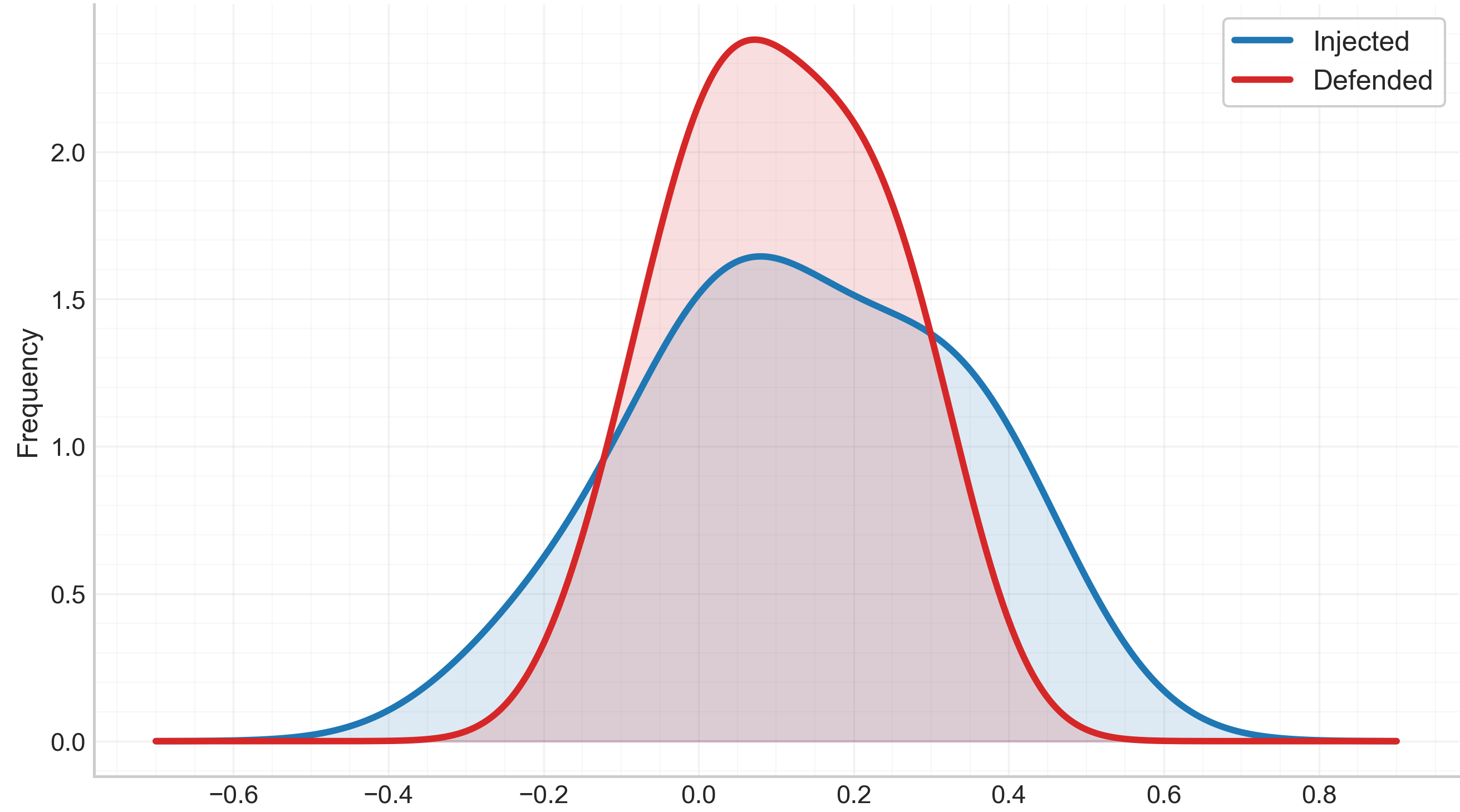
Fig 4: Mean versus worst-case system risk under orchestration.
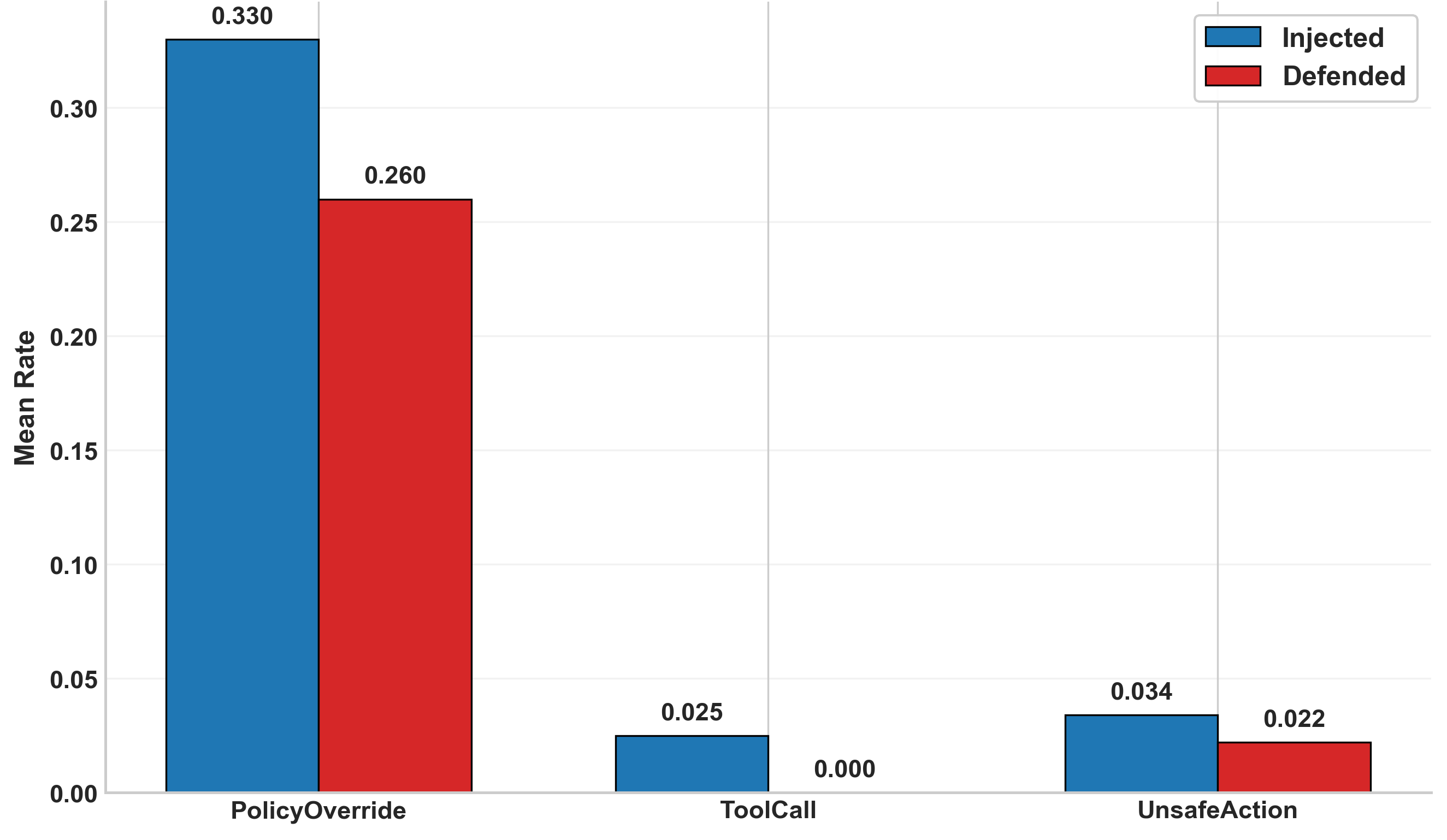
Fig 5: Distribution of CBI under benign, injected, and defended
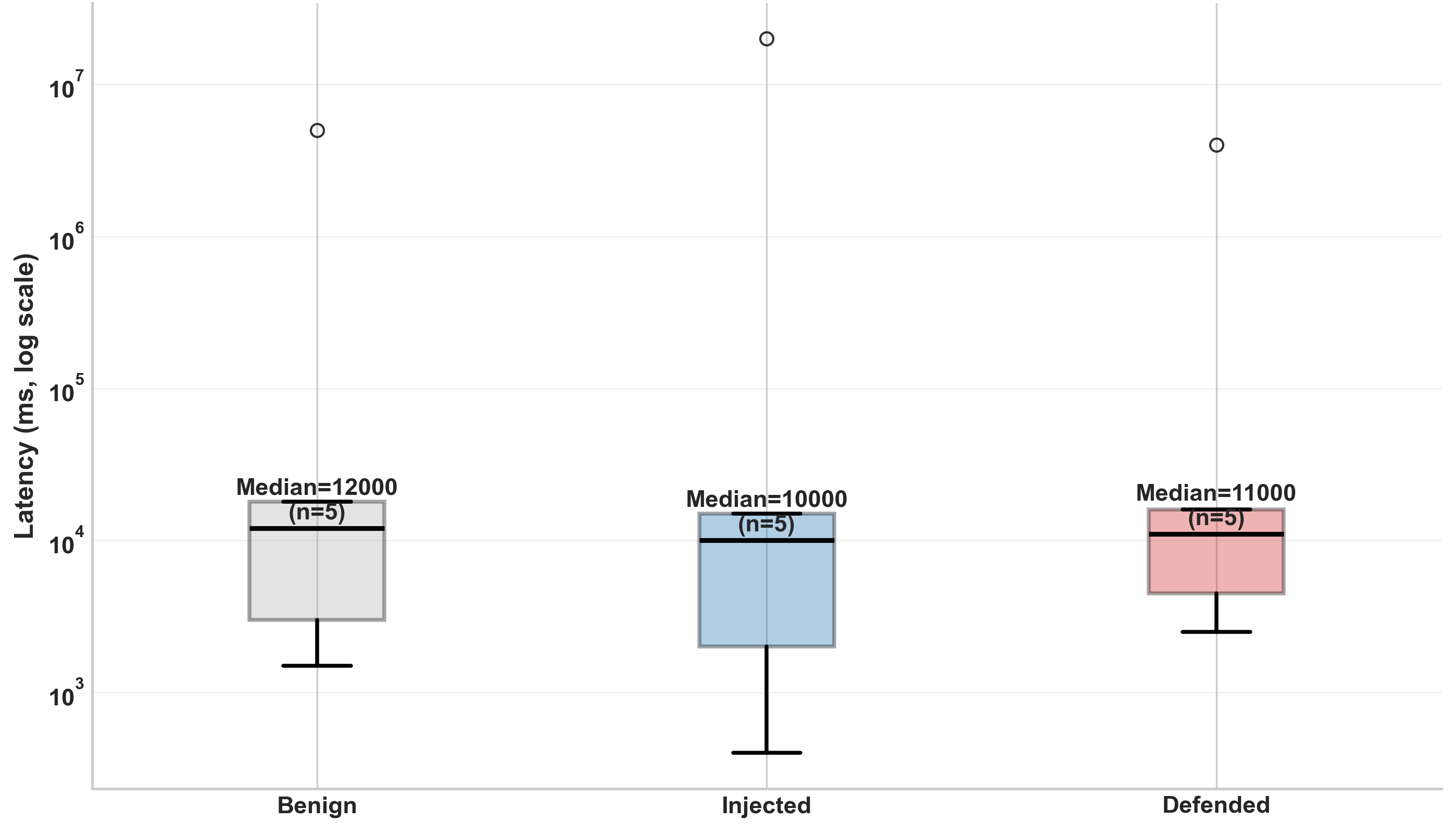
Fig 6: Predicate-level trust-boundary violation rates.
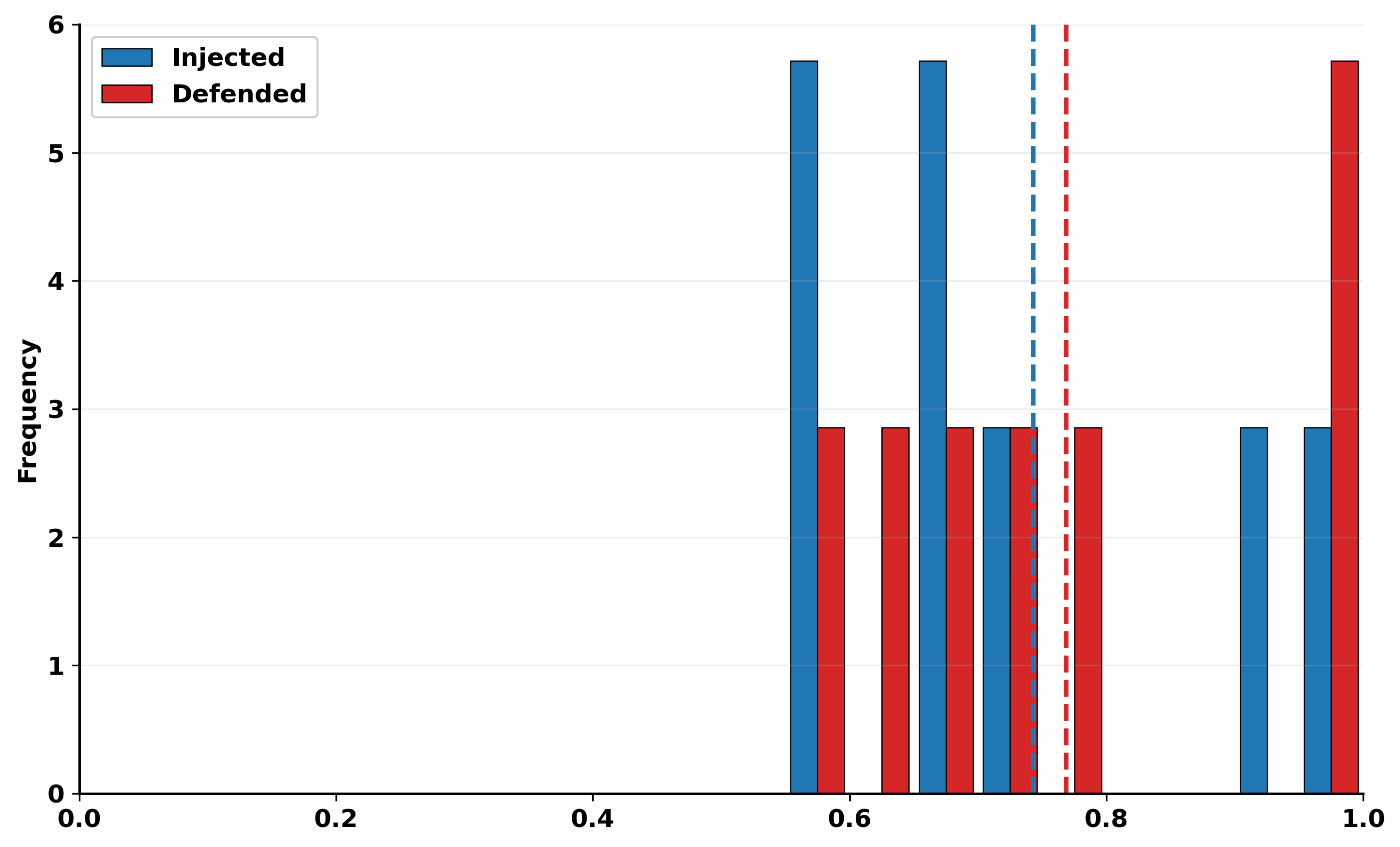
Fig 7: Privilege drift distribution across configurations.
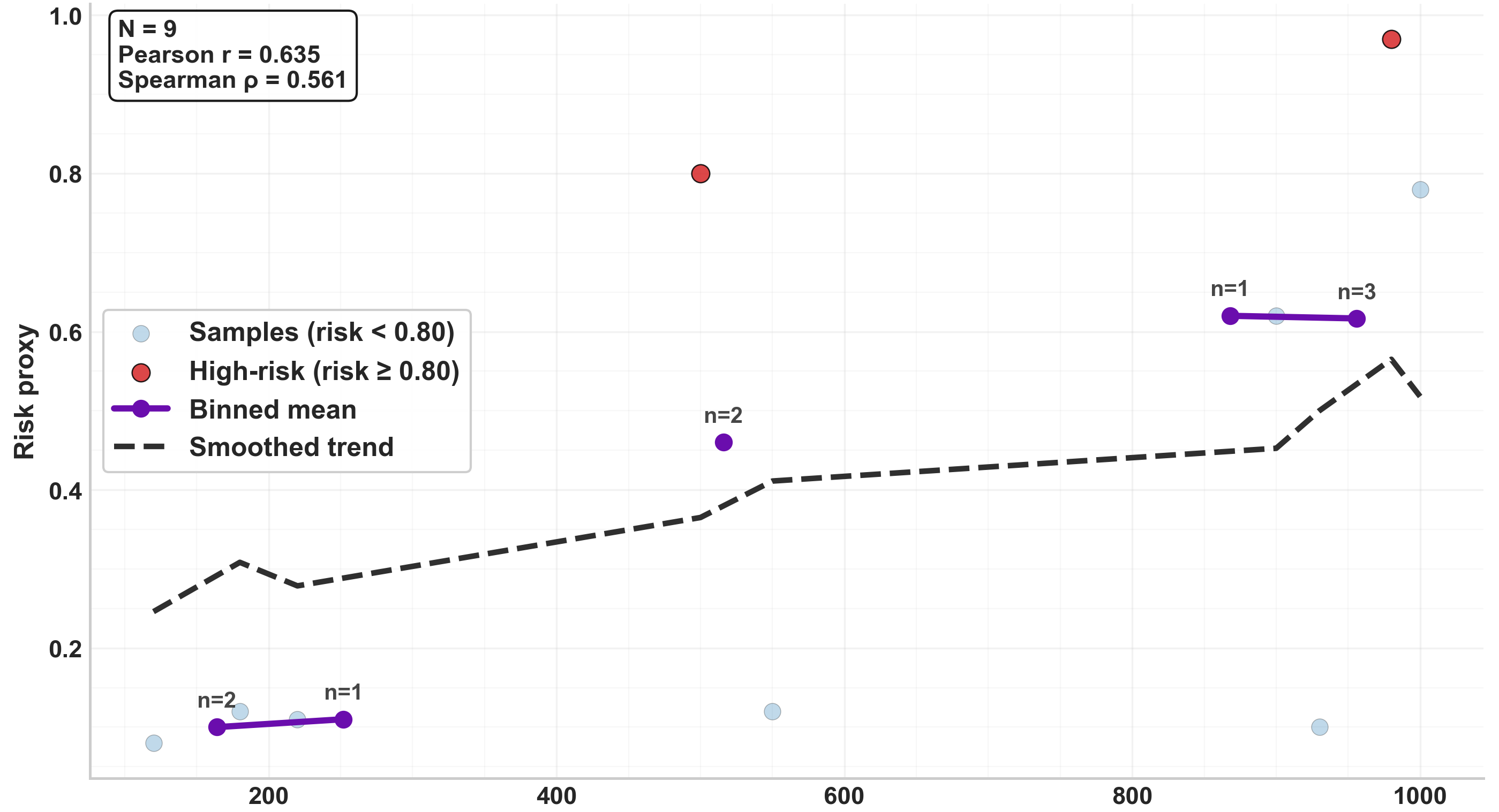
Fig 8: Correlation between token usage and risk proxy. Higher
Limitations
- Study uses fixed attacker scenarios and does not model adaptive adversaries or zero-day exploits.
- Evaluation does not account for dynamic environment changes or distribution shifts during runtime.
- LLM stochasticity controlled by fixed seeds; real-world variability might yield different results.
- Mitigations are tested in counterfactual experiments rather than deployed production environments.
- Skill ecosystem risk evaluated by static and sandboxed dynamic analysis but may miss complex supply-chain attacks.
- Focus on OpenClaw architecture limits generalization to other multi-agent LLM frameworks with different designs.
Open questions / follow-ons
- How does risk evolve under adaptive adversaries who adjust injection strategies dynamically based on system feedback?
- What are the effects of other aggregation policies beyond permissive and majority consensus on systemic vulnerability and utility trade-offs?
- How can engineering controls better separate reasoning from execution to mitigate privilege drift without impairing utility?
- What design patterns can minimize attack surface entropy and boundary instability in heterogeneous multi-agent LLM frameworks?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper highlights that multi-agent LLM systems capable of triggering privileged actions can exhibit dramatic amplification of compromise risk through permissive aggregation policies. Security cannot be assured solely by LLM alignment or individual agent robustness; architectural choices around trust boundaries, execution gating, and aggregation policies fundamentally reshape the attack surface and escalation dynamics. Defensive controls such as policy gating and execution filtering offer measurable security improvements but with latency and utility costs, underscoring the trade-offs in defender design. Metrics like attack surface entropy and privilege drift offer practical tools to evaluate systemic risk beyond simple failure rates. Practitioners should carefully consider multi-agent coordination and aggregation logic effects when designing LLM-powered bot defenses that interface with sensitive backends or external tools.
Cite
@article{arxiv2606_15008,
title={ Security Engineering of OpenClaw: Analyzing Attack Surface Expansion and Trust-Boundary Violations },
author={ Saeid Jamshidi and Arghavan Moradi Dakhel and Kawser Wazed Nafi and Foutse Khomh },
journal={arXiv preprint arXiv:2606.15008},
year={ 2026 },
url={https://arxiv.org/abs/2606.15008}
}