
Cluster LOCO: Feature Importance For Interpreting Clusters
Source: arXiv:2606.14592 · Published 2026-06-12 · By Claire M. He, Genevera I. Allen
TL;DR
This paper tackles the challenging problem of feature importance interpretation in clustering, a widely used unsupervised learning tool for exploratory data analysis and scientific discovery. Unlike supervised learning, where feature importance is well-studied, clustering lacks reliable, model-agnostic methods to explain which features drive discovered cluster structures, especially for complex, high-dimensional data. Existing approaches tend to be algorithm-specific or rely on restrictive assumptions. The authors propose Cluster LOCO, a family of model-agnostic, feature occlusion-based importance scores for clustering solutions, measuring feature importance by the degradation in cluster generalizability when leaving out a feature. They develop two variants: Cluster LOCO-Split, using train/calibration splits, and Cluster LOCO-MP, a scalable minipatch ensemble method for large-scale and high-dimensional data. Through synthetic simulations involving nonlinear clusters and correlated features, and an application to single-cell transcriptomics, Cluster LOCO outperforms prior approaches by more reliably recovering informative features important to cluster structure rather than merely differentiating groups post hoc. The method also provides cluster-specific interpretations. Results demonstrate better signal-to-noise feature ranking under complex clustering models (spectral clustering,etc.) compared to prior permutation or Shapley-value based methods tied to simpler models like K-means.
Key findings
- Cluster LOCO-Split achieves perfect separation of signal versus noise features in a nonlinear synthetic clustering example where spectral clustering (ARI=1.0) outperforms K-means (ARI=0.40) and existing importance measures fail by assigning importance to noise.
- Cluster LOCO-MP scores provide robust feature importance estimates in high-dimensional data (up to 1000 noisy features), outperforming baselines such as permutation feature importance, Fuzzy C-Means Shapley, layer-wise relevance propagation (LRP), prototype-based FI, and IMPACC, across Gaussian mixture, Gamma mixture, and interlaced moons/circles datasets.
- In large-scale simulations with N=3500, K=7 clusters, and varying noise levels, Cluster LOCO-MP and RAMPART consistently achieve higher precision@10 for recovering true signal features, often exceeding 0.8 top-k hit rates under challenging cluster separations.
- Cluster LOCO-MP reduces computational complexity from O(N^3) for spectral clustering to O(B n^3) with small minipatch sizes n << N and ensemble size B, enabling scalability.
- The minipatch ensemble approach of Cluster LOCO-MP effectively mitigates correlated feature masking seen in single-feature ablation techniques, providing meaningful importance scores even when features are strongly correlated.
- Cluster LOCO supports cluster-specific importance scores by aggregating error measures per cluster, enabling local interpretability relevant to scientific downstream tasks.
- Integrating Cluster LOCO with the RAMPART adaptive procedure for iterative top-k feature ranking reduces computation while improving importance estimation precision.
- Using adjusted Rand index, multi-class hinge loss, and prediction error as generalizability measures yields stable and consistent Cluster LOCO importance scores.
Threat model
Not a security-focused paper. The adversary is conceptualized as the ambiguity and instability in interpreting clustering results, with unknown true feature drivers. The goal is to robustly identify features responsible for cluster structure despite noise, high dimensionality, and complex data distributions.
Methodology — deep read
The authors first define the threat model as general clustering interpretation: given an unlabeled dataset X with N samples and M features, and a clustering algorithm C with chosen hyperparameters (e.g., number of clusters), identify how important each feature j is to the clustering structure. There is no explicit adversarial threat but a focus on interpretability robustness and generalizability.
The core Cluster LOCO-Split procedure is as follows: split the dataset X into disjoint training (Xtr) and calibration (Xcal) subsets roughly balanced to maintain cluster representation. Apply the clustering algorithm C to Xtr and Xcal independently to get cluster labels ztr and zcal. Then, train a generalizability classifier ftr to predict cluster labels ztr from Xtr features. Repeat this classifier fitting without feature j for ftr^-j trained on data with feature j removed. Evaluate the generalizability error of ftr and ftr^-j on Xcal (with and without feature j, respectively) by comparing predicted cluster labels to zcal using metrics such as adjusted Rand index (ARI) or multi-class hinge loss. The feature importance score for feature j is the increase in error when removing that feature: higher values indicate greater importance.
However, data splitting suffers from instability, reduced sample size, and underestimates importance for correlated features, especially for modern large/high-dimensional data. To address this, the authors extend to Cluster LOCO-MP, which uses an ensemble of B minipatches—small random subsets of observations and features (size n << N, m << M). For each minipatch b, clustering is performed on the sampled data and cluster labels aligned to a global reference clustering z0 via Hungarian matching. A generalizability classifier fb is trained for each minipatch to predict cluster labels from the minipatch features.
Prediction for each observation i is aggregated across minipatches excluding i (leave-one-out ensemble prediction H) and also aggregated across minipatches excluding both i and feature j (leave-one-covariate-out LOCO prediction H^-j). The feature importance score is the difference in prediction error between H^-j and H, averaged over all observations. This ensemble approach stabilizes importance estimates, accommodates correlations, and is highly parallelizable. It reduces the complexity of clustering from O(N^3) to O(B n^3).
They further integrate Cluster LOCO with RAMPART, a sequential halving algorithm that iteratively shrinks the feature candidate set and re-ranks importance scores for computational efficiency in extremely high dimensions focusing on top-k features.
Evaluation is performed on synthetic datasets with known ground truth signals: nonlinear interlaced half moons, Gaussian and Gamma mixtures with correlated features, at multiple signal-to-noise ratios and dimensionalities (up to 1000+ noise features), using spectral clustering and EM clustering. Metrics include top-k hit rate (precision@10) for signal recovery, adjusted Rand index, and error differences.
Comparisons are made against five baselines: prototype-based feature importance (PBFI), Fuzzy C-Means SHAP (FCM SHAP), permutation feature importance (PFI), layer-wise relevance propagation (LRP), and IMPACC. Since some baselines had no public code, they were re-implemented or adapted. Results are averaged over 100 replicates.
The Cluster LOCO method and its minipatch ensemble are described stepwise with algorithm boxes in the paper. Hyperparameters such as train/calibration split ratio and minipatch size ratios are recommended to be balanced (e.g., 50/50 split, minipatch size 20%-50% of N and M). Cluster-specific LOCO versions aggregate importance scores by individual cluster to provide local interpretability. Code availability and precise seed strategies are not detailed. The evaluation emphasizes reproducible, statistically valid generalizability error estimates rather than stability or internal geometric scores.
An end-to-end example: Given a dataset, Cluster LOCO-Split clusters train/calibration splits, trains cluster-to-label classifiers with and without each feature, then measures accuracy drops on calibration data. For large data, Cluster LOCO-MP samples many minipatches, clusters them, aligns labels, trains classifiers per minipatch, aggregates leave-one-out predictions, then re-computes predictions excluding each feature to derive importance scores rapidly. RAMPART further focuses this into the most important features.
This methodology is novel in combining leave-one-covariate-out feature ablation with cluster generalizability classifiers and scaling it via minipatch ensembles, allowing model-agnostic, assumption-free feature importance estimation for arbitrary cluster models.
Technical innovations
- Introduces Cluster LOCO, a model-agnostic feature importance score for clustering based on feature occlusion measured via degradation in cluster generalizability to held-out data.
- Develops Cluster LOCO-MP, a scalable minipatch ensemble method that reduces computational cost from O(N^3) to O(B n^3) and stabilizes importance scores by averaging over many small sub-samples of observations and features.
- Extends global feature importance to cluster-specific LOCO scores that provide localized interpretability for individual clusters using point-wise error aggregation.
- Integrates Cluster LOCO with the RAMPART adaptive top-k feature ranking procedure to efficiently prioritize important features in high-dimensional settings.
Datasets
- Synthetic nonlinear half-moons with 3 signal + 2 noise features — 500 samples — simulated
- Gaussian mixture with onion covariance structure, N=3500, K=7, up to 1000 noisy features — simulated
- Gamma mixture data with heavy tails, N=3500, K=7, high dimension — simulated
- Interlaced moons/circles embedding high-dimensional data, N=3500, K=7 — simulated
- Single-cell transcriptomics dataset — size unspecified — public genomics data source
Baselines vs proposed
- Prototype-based FI (KMeans): precision@10 top-k hits < Cluster LOCO-MP by ~20-40% in nonlinear synthetic data.
- Fuzzy C-Means SHAP: highly computationally expensive, precision@10 notably lower than Cluster LOCO-MP especially on non-convex clusters.
- Permutation Feature Importance (PFI): assigns spurious importance to noise features in nonlinear setting, precision < Cluster LOCO.
- Layer-wise relevance propagation (LRP): underperforms Cluster LOCO across tested datasets in recovering true signal features.
- IMPACC: competitive but generally inferior to Cluster LOCO-MP and RAMPART across difficulty levels and feature dimensionalities.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.14592.
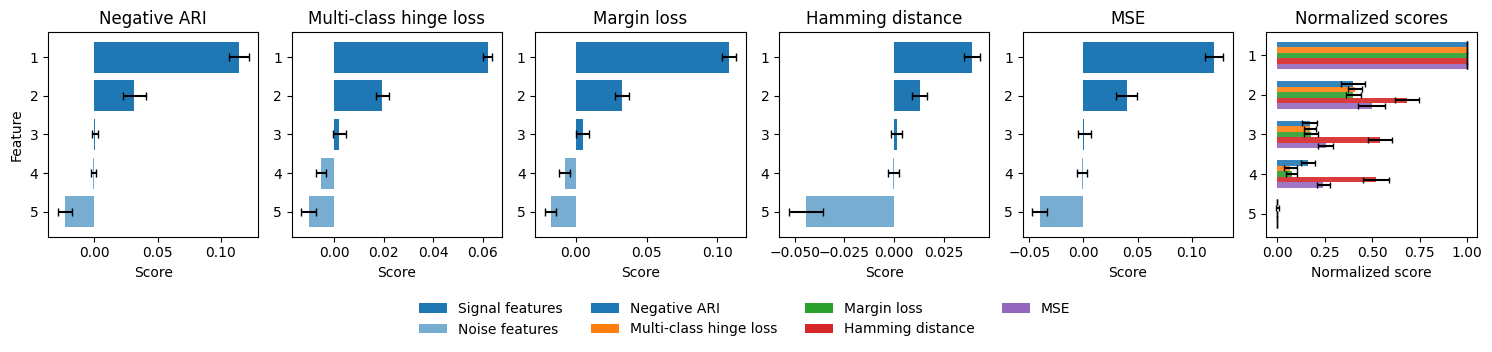
Fig 5: Comparison of Cluster LOCO-Split scores with different measures of error/dissim-
Limitations
- Cluster LOCO-Split’s reliance on train/calibration splits reduces effective sample size, increasing variability and sensitivity to splitting, especially for unbalanced clusters.
- Feature occlusion approach may underestimate importance of highly correlated features in single-feature ablation; mitigated but not fully resolved even with minipatches.
- Evaluation primarily on synthetic and one biological dataset; real-world generalization and multiple clustering paradigms not extensively validated.
- Computational cost, while reduced by minipatches, can still be significant for very large datasets or complex clustering methods due to repeated reclustering and classifier training.
- Choice of clustering algorithm and hyperparameters remains user-defined; importance reflects chosen cluster solution's structure rather than inherent data features.
Open questions / follow-ons
- How does Cluster LOCO perform across a wider variety of clustering algorithms beyond spectral clustering and EM-based mixtures, including deep or density-based models?
- Can the method be extended to provide causal interpretations or handle hierarchical clustering structures?
- What is the impact of different generalizability error metrics on the stability and interpretability of importance scores across domains?
- How can Cluster LOCO be adapted for streaming or dynamically growing datasets where reclustering and retraining are expensive?
Why it matters for bot defense
For bot-defense engineers working with CAPTCHA or behavioral biometrics clustering user sessions or activity profiles, Cluster LOCO enables principled, model-agnostic identification of behavioral features that truly drive cluster formation rather than correlational markers. This helps avoid misinterpreting artifacts or noise as important factors, improving trust and auditing of clustering pipelines used for anomaly detection or segmentation. The scalable minipatch ensemble allows practical application on large interaction logs with many behavioral features. Cluster-level interpretability supports understanding which behavioral traits distinguish attacker clusters from benign users. Overall, this methodology enriches unsupervised analysis transparency, helping practitioners build defensible, reproducible clustering workflows critical for adversarial detection systems.
Cite
@article{arxiv2606_14592,
title={ Cluster LOCO: Feature Importance For Interpreting Clusters },
author={ Claire M. He and Genevera I. Allen },
journal={arXiv preprint arXiv:2606.14592},
year={ 2026 },
url={https://arxiv.org/abs/2606.14592}
}