
CARE: Controlling LLM-Generated Policies through Auditable Review of Evidence in Scientific Experimentation
Source: arXiv:2606.14581 · Published 2026-06-12 · By Guanyu Liu, Weiyi Kong, Zeyu Wang, Boer Zhang, Baiqing Li, Peiyu Zhang et al.
TL;DR
This paper addresses a critical challenge in deploying large language models (LLMs) to control real-world scientific experiments, specifically high-throughput experimentation (HTE). Allowing LLMs direct control risks unsafe exploration and unstable results due to irreversible and costly experiments. However, completely removing LLM creativity limits potential optimization gains. To resolve this tension, the authors present CARE, an auditable control framework that combines a reliable non-LLM incumbent optimizer with LLM-generated challenger policies. CARE uses a public-evidence intervention gate to authorize challenger actions only when supported by pre-reveal public evidence, with all decisions recorded in an audit log. This design separates LLM proposals from action authority, maintaining safety while leveraging LLM creative policy revisions.
CARE is evaluated on two real-world HTE replay benchmarks, Minerva/Olympus and ChemLex, achieving large improvements over strong classical and LLM-based Bayesian optimization baselines. Compared to the public incumbent, CARE improves Minerva/Olympus final best from 80.0 to 88.5 and ChemLex from 83.9 to 92.1, also reducing regret and improving anytime performance. Ablations show that the policy planner, the public-evidence gate, and proposal modes each contribute to gains. Results confirm the key insight that LLMs are best deployed as proposal space expanders within a fixed public decision framework rather than direct experiment selectors. The fixed, pre-reveal auditing enforces safety and accountability.
Key findings
- CARE improves final-best score on Minerva/Olympus from public incumbent 80.0 to 88.5 and best-so-far AUC from 73.4 to 84.4.
- CARE raises final-best on ChemLex from 83.9 to 92.1 and best-so-far AUC from 77.2 to 81.6 over the public incumbent.
- CARE cuts mean simple regret on Minerva/Olympus to 0.7 from 9.2 and on ChemLex to 7.9 from 16.1.
- Ungated LLM-evolving and non-evolving LLM policies perform considerably worse than CARE (e.g., 68.8 and 63.3 final-best on Minerva/Olympus).
- Ablation removing Policy Planner, gate, or either proposal mode reduces final-best performance by 1.2 to 10.4 points, confirming all components contribute.
- The intervention gate authorizes challenger actions sparsely (52/197 on Minerva/Olympus and 36/225 on ChemLex), maintaining safety.
- Replacing the proposal LLM backend (Gemini-2.5-Flash) maintains comparable performance, showing that CARE's control interface generalizes across LLMs.
- Replay protocol variations (different initializations and reveal budgets) do not change the advantage of gate-assigned action authority.
Threat model
The adversary is the LLM agent proposing experiment selection policies under budget constraints. It can observe only public information before action selection and attempt to deviate from the incumbent optimizer. However, it cannot access unrevealed outcomes, oracle knowledge, or private caches, and cannot bypass the public-evidence intervention gate. Thus, the adversary can only submit challenger policies that must be authorized based on admissible public evidence before deployment. The system prevents unsafe or poorly supported experiment execution by restricting direct LLM action authority.
Methodology — deep read
Threat model & assumptions: The adversary is effectively the LLM agent proposing experiment policies that can impact costly, irreversible scientific experiments (HTE). The system assumes experiments have limited reveal budget and public information constraints. The LLM only has access to public revealed outcomes, public candidate features, and logged optimizer state before action selection. It cannot access unrevealed outcomes, oracle ranks, evaluator private caches, or post-hoc information. The controller explicitly disallows direct LLM action authority without public-evidence support, preventing unsafe or unstable exploration.
Data: The evaluation uses two real high-throughput experimentation replay datasets: Minerva/Olympus Suzuki Coupling (5,670 candidates with 7 ligand indicators plus other variables, target yield) and ChemLex Acid–Amine Wetlab (11,088 conditions, categorical and continuous variables, target conversion). Both datasets have preprocessed duplicates removed and public candidate features are available for gating. Experiments run on matched seeds (30 each) to enable direct policy comparisons, starting with 5 initial observations and 10 reveal budget.
Architecture / algorithm: CARE combines three modules in sequence for each round: (a) a public incumbent non-LLM optimizer ensembles multiple existing Bayesian optimization and heuristic experts producing a default action by scoring candidate pool; (b) an LLM-based Policy Generator proposes a challenger ranking policy that revises or replaces the incumbent ranking; (c) a Public-Evidence Intervention Gate compares challenger versus incumbent candidates using admissible public margins (support, rank bonuses, novelty) and public risks (missing rank, low support). The gate computes an authorization score κ allowing challenger actions only when public evidence supports improvement, else defaults to incumbent. The gate decision is logged pre-reveal for auditability. The LLM never overrides the incumbent without gate approval.
The LLM Policy Planner decides to reuse, patch, or create challenger policies based on public trajectory states (history, prior gate decisions). Challenger candidates include bounded proposal modes: recovery (backup candidates with public support) and frontier (schema-conditioned alternatives). After validation checks on public compliance and scoring invariances, the gate accepts or rejects the challenger candidate.
Training regime: Not applicable as this is primarily a control framework and policy evaluation on fixed replay datasets. The LLM policy generation uses fixed prompts and sampling temperatures (1.0), with the gate parameters frozen prior to evaluation.
Evaluation protocol: Policies run for 30 matched random seeds, starting from identical initial observations and facing the same finite candidate pool with fixed reveal budgets. Metrics include final best target value, best-so-far area under the curve (AUC), and simple regret relative to dataset oracle. Baselines include random, stratified random, fixed heuristics, classical BO variants (GP, random forest, TPE, Gryffin, EDBO), LLM-BO hybrid (LMABO), ungated and non-evolving LLM policies, and expanded public incumbents. Ablations remove core CARE components (gate, planner, proposal modes) to confirm their impact. Robustness tested with alternate reveal budgets and initializations. Statistical confidence is reported as 95% bootstrap intervals.
Reproducibility: The paper states gate coefficients, planner thresholds, budgets, and prompt interfaces are fixed and detailed in appendices, with prompt interfaces and audit log specifications publicly described. Full weights or code availability unclear, but benchmarks are public or well-documented replay suites. Gemini-2.5-Flash backend shows CARE's modularity.
Example end-to-end: At round t, the public incumbent ensemble scores remaining candidates and chooses a default experiment aref_t. The LLM Policy Generator receives history and pool features, generating a challenger policy πch_t that scores candidates Sch_t. The top challenger candidate ach_t is assembled with a public rationale and passed to the intervention gate. The gate calculates the authorization score κ_t(ach_t) weighing gain vs risk from public features. If above threshold, challenger action authority is granted; else incumbent action is selected. The pre-reveal audit record logs all inputs and the gate decision before revealing the experiment outcome y_{a_t}, which updates the public history for next round. This flow repeats until reveal budget is exhausted.
Technical innovations
- Formulating auditable control of LLM-generated experiment policies under a strict public-information boundary to enforce safety.
- Designing a hybrid controller that keeps a strong non-LLM incumbent optimizer as the default while using LLMs as challenger policy proposers subjected to a pre-reveal public-evidence intervention gate.
- Introducing the Public-Evidence Intervention Gate that quantifies admissible public support and risk from observable features to authorize challenger actions before any outcome is revealed with an immutable audit log.
- Expanding proposal space via LLM policy revisions and bounded proposal modes (recovery and frontier) without relinquishing direct action authority, balancing exploratory creativity and reliability.
Datasets
- Minerva/Olympus Suzuki Coupling — 5,670 candidates — public high-throughput experimentation replay dataset
- ChemLex Acid–Amine Wetlab — 11,088 conditions — public high-throughput experimentation replay dataset
Baselines vs proposed
- Public incumbent: final-best = 80.0 vs CARE: 88.5 on Minerva/Olympus
- TPE-style BO: final-best = 77.6 vs CARE: 88.5 on Minerva/Olympus
- LMABO-style LLM-BO: final-best = 76.6 vs CARE: 88.5 on Minerva/Olympus
- Ungated LLM-evolving policy: final-best = 68.8 vs CARE: 88.5 on Minerva/Olympus
- Public incumbent: final-best = 83.9 vs CARE: 92.1 on ChemLex
- Gryffin-style categorical BO: final-best = 89.8 vs CARE: 92.1 on ChemLex
- EDBO-style descriptor GP-EI: final-best = 88.9 vs CARE: 92.1 on ChemLex
- Ungated LLM-evolving policy: final-best = 81.2 vs CARE: 92.1 on ChemLex
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.14581.
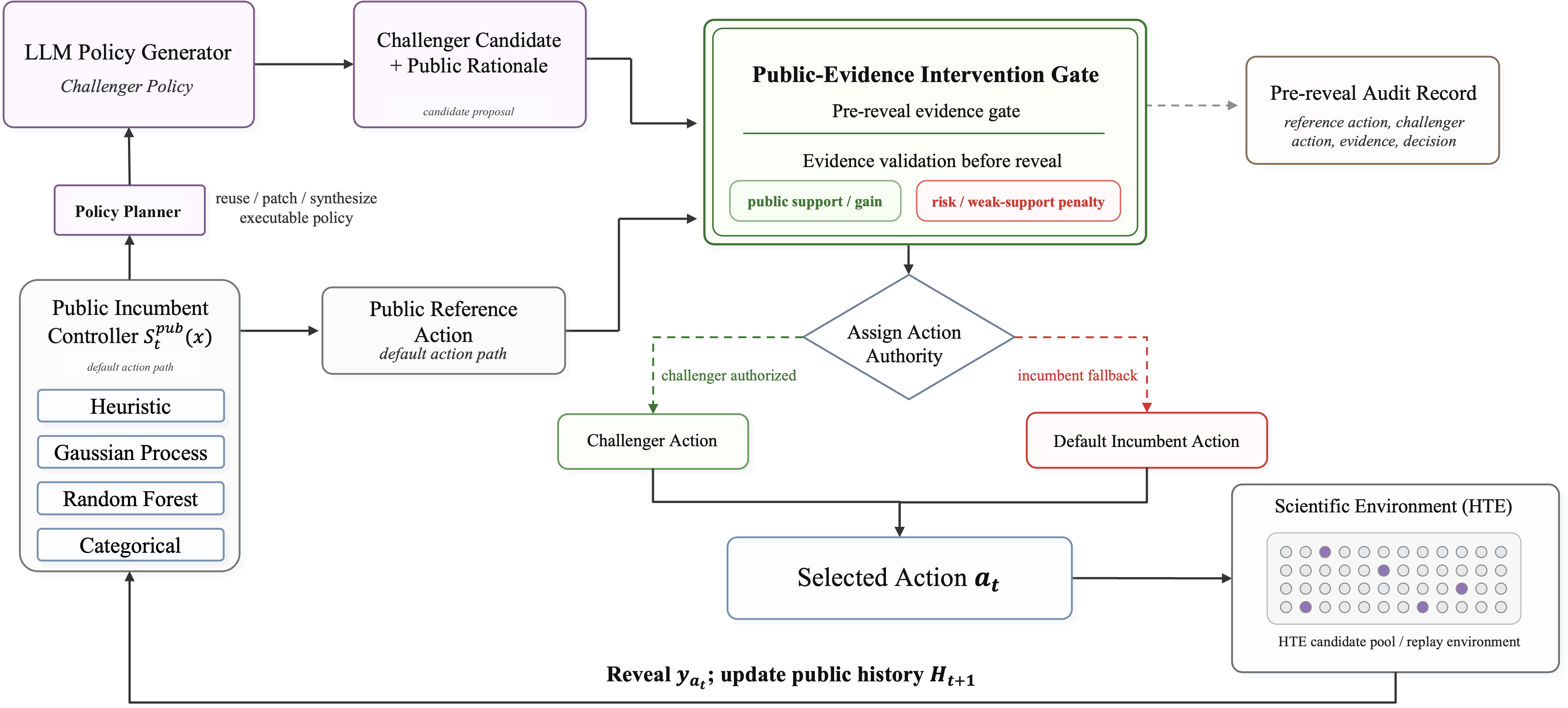
Fig 1: CARE pipeline. The public incumbent controller computes a public reference action as the

Fig 3: Replay-protocol robustness over 10

Fig 3 (page 15).
Fig 4: ChemLex public-incumbent case study.
Limitations
- Evaluation is limited to matched finite-pool replay without live closed-loop deployments or real-world laboratory constraints such as robot scheduling and measurement delays.
- The approach assumes richly informative public candidate features for the intervention gate; sparse or uninformative features reduce authorized challenger actions.
- Only single-objective, batch-free sequential experiments with finite pools are considered; multi-objective optimization, cost-awareness, batching, and safety constraints remain future work.
- The audit log and gate specification remain fixed and pre-specified; transferability of gate weights, planner thresholds, and acquisition portfolios across different HTE contexts is uncertain.
- Proposal modes like frontier exploration rely on availability of schema-conditioned features and fallback on recovery or incumbent policies otherwise.
- Comparisons center on gate-authorized LLM challenger policies; extending the gate to non-language proposals or adversarially robust policies is unexplored.
Open questions / follow-ons
- How well do CARE's gate weights and thresholds generalize across diverse scientific domains and live closed-loop robot deployment scenarios?
- Can the public-evidence gate be extended to multi-objective, cost-aware, batched, or safety-constrained HTE optimization?
- How might non-language proposal families (e.g., genetic algorithms or model-based planners) perform behind the same gate control framework alongside LLM-generated challengers?
- What are the robustness properties of CARE under adversarial or distribution-shifted LLM proposals, and can the gate adapt dynamically?
Why it matters for bot defense
For bot-defense and CAPTCHA engineers, CARE exemplifies an auditable control paradigm where powerful but imperfect, potentially unsafe agents (LLMs) generate proposals while a transparent, rule-based gate enforces safety and accountability before any irreversible action is executed. This pattern — separating proposal space expansion from direct authority, gating actions by verifiable public evidence, and logging decisions pre-execution — can inspire stronger bot mitigation frameworks that leverage ML models for creativity and adaptability while constraining risk. Analogously, CAPTCHA systems might experiment with hybrid agent control, where ML-driven challenge generation is monitored and authorized by fixed, interpretable heuristics. The emphasis on transparent, pre-execution audit logs aids forensic analysis and compliance. CARE's framework also highlights the importance of public state boundaries and reproducible control logic, which could inform CAPTCHAs requiring transparent bot assessments under adversarial conditions.
Cite
@article{arxiv2606_14581,
title={ CARE: Controlling LLM-Generated Policies through Auditable Review of Evidence in Scientific Experimentation },
author={ Guanyu Liu and Weiyi Kong and Zeyu Wang and Boer Zhang and Baiqing Li and Peiyu Zhang and Tianyu Shi },
journal={arXiv preprint arXiv:2606.14581},
year={ 2026 },
url={https://arxiv.org/abs/2606.14581}
}