
CANN-EUCLID: unsupervised constitutive artificial neural network model discovery from full-field data
Source: arXiv:2606.14565 · Published 2026-06-12 · By Benjamin Alheit, Siddhant Kumar, Mathias Peirlinck
TL;DR
This paper addresses the challenge of discovering interpretable, nonlinear constitutive material models directly from full-field displacement and reaction force data without requiring local stress measurements. Traditional constitutive artificial neural networks (CANNs) have been trained mostly in stress-supervised scenarios using homogenized stress-strain data from multiple mechanical tests, which is limiting for soft biological tissues due to sparse sampling of loading paths and the impracticality of repeated testing on heterogeneous samples. To overcome this, the authors introduce CANN-EUCLID, which integrates CANNs with the stress-unsupervised inverse identification framework EUCLID. This allows uncovering sparse, interpretable hyperelastic constitutive laws by minimizing equilibrium imbalance and applying sparsity-promoting regularization directly from full-field kinematic data in a single heterogeneous loading case.
They validate the method on synthetic benchmark problems involving isotropic and anisotropic hyperelastic models with known ground-truth laws. When the ground truth is exactly representable by the CANN basis functions, CANN-EUCLID recovers the correct constitutive terms with near-exact accuracy, including nonlinear exponential terms. In cases where the basis does not fully span the ground truth behavior, it retains shared terms and approximates missing contributions. The method’s generalization depends critically on the richness of the deformation states sampled: strain-stiffening exponential terms can be accurately identified if sufficiently probed but may extrapolate poorly out-of-domain. Forward finite element simulations using the discovered models show strong agreement with ground-truth behaviors. This establishes CANN-EUCLID as a promising framework for interpretable, sparse, full-field, stress-unsupervised constitutive model discovery.
Key findings
- CANN-EUCLID successfully identifies the exact active strain-energy basis terms when the ground truth model is contained within its representational basis (Fig. 4 and 5).
- Exponential hyperelastic terms with parameters inside nonlinear functions can be recovered with near-exact accuracy from displacement and reaction force data alone.
- When the ground-truth constitutive law is not fully representable by the CANN basis, the framework retains shared terms and approximates missing terms using available basis functions.
- Generalization accuracy depends strongly on deformation space coverage: strain-stiffening regimes must be well sampled to avoid large extrapolation errors in predictions (Fig. 7).
- The method outperforms standard black-box neural constitutive models by enabling sparse, interpretable term-level discovery with polyconvexity guarantees.
- Forward finite element validation on unseen geometry and loading confirms the discovered model accurately replicates ground-truth behavior (Fig. 8).
- Three-stage training with pre-regularization, sparsity-driven subset selection, and post-regularization polishing enhances stability and convergence during sparse model identification.
- The proposed sparsity-promoting Lp-norm regularizer directly penalizes the product of paired CANN weights (θijk, ϕijk), leading to compact, physically meaningful constitutive representations.
Methodology — deep read
Threat Model & Assumptions: The adversary is absent here as this is purely a model discovery framework for constitutive behavior; the assumptions are that full-field displacement data at mesh nodes, aggregated reaction forces on constrained boundaries, and approximations of microstructural structural vectors are available. Local stress fields are not assumed known.
Data: Synthetic datasets are generated from finite element simulations of a benchmark geometry consisting of a plate with a circular hole under biaxial loading ramped over 10 time steps. Both isotropic and anisotropic hyperelastic ground-truth models are used, including NeoHookean, Demiray, Isihara, Arruda-Boyce, Gent-Thomas, Ogden for isotropic; and Anisotropic NeoHookean, Holzapfel-Gasser-Ogden, Meaney, Merodio-Ogden, Humphrey-Yin, and Gasser-Ogden-Holzapfel for anisotropic cases. Structural vectors (fiber directions) are set accordingly. The data include displacement fields u_I,t at nodal points and reaction forces R_β,t at boundary constraints.
Architecture/Algorithm: The core model is the Constitutive Artificial Neural Network (CANN), a five-layer sparse branching neural network representing the strain energy density Ψ as a sum of interpretable tensor invariant-based terms. Inputs are carefully chosen pseudo-invariants (K_i) ensuring zero energy and stress at undeformed state and polyconvexity. Layer 1 takes deformation gradient F and structural vectors A_i, layer 2 computes pseudo-invariants K_i. Layer 3 applies a set of power functions f_j (e.g., powers), and layer 4 applies either identity or exponential minus one functions g_k to generate nonlinear parameter dependence. Outputs of layer 4 are weighted by trainable positive weights φ_ijk and θ_ijk, which are sparsified via regularization to select active terms. The output layer sums these to yield Ψ.
Training Regime: Training minimizes a loss combining internal equilibrium imbalance (based on weak form residual forces computed via FE basis functions and CANN-derived stresses), external equilibrium imbalance (difference between predicted nodal internal forces summed on constrained boundaries and observed reaction forces), and a sparsity-promoting L_p norm regularization on the product weights α_i = θ_ijk φ_ijk. A three-stage procedure is used: (a) pre-regularization focusing on equilibrium terms without sparsity, (b) sparsity-driven subset selection applying L_p regularization to prune terms, and (c) post-regularization polishing to refine parameters. Weights θ_ijk and φ_ijk are constrained ≥0 for polyconvexity. Hyperparameters λ_int, λ_ext, and λ_p weight the loss terms. Optimization is gradient based with custom gradient computations through the equilibrium residuals.
Evaluation Protocol: Performance metrics include R^2 score for global fit of strain energy and stress, and normalized local error for detailed accuracy. The discovered model’s responses are compared path-wise against ground-truth stress responses along multiple loading paths (uniaxial tension, confined compression, biaxial tension, simple shear). Generalization is tested on deformation states beyond training data. Forward finite element simulations on a separate geometry with elliptical holes and distinct loading are performed to assess practical predictive fidelity.
Reproducibility: The paper reports synthetic data generation details and training hyperparameters in appendices but does not explicitly mention public code or dataset release. The approach uses standard FE simulations for synthetic data, enabling reproducibility if replicated.
Concrete Example Walkthrough: For the NeoHookean isotropic benchmark, displacement fields from biaxial loading of a plate with a hole are generated by FE with a known NeoHookean material model. The CANN architecture with pseudo-invariants K_1=I1-3, K_2=I2-based, K_3=J-volume term is initialized with non-negative sparse weights. The training minimizes the combined loss over 10 time steps of displacement and reaction forces. The trained CANN recovers weights corresponding to the NeoHookean terms, showing near-exact match in stress predictions across canonical paths and excellent R^2 scores, demonstrating successful unsupervised sparse term identification without direct stress inputs.
Technical innovations
- Integration of CANNs with the stress-unsupervised EUCLID framework enables constitutive discovery directly from displacement and reaction force data without local stress supervision.
- Introduction of a sparsity-promoting Lp-norm regularizer applied to the product of paired CANN weights (θijk, ϕijk) for automatic compact term selection in nonlinear constitutive models.
- Use of carefully chosen pseudo-invariants and nonlinear activation functions (identity and exponential minus one) in a polyconvexity-preserving CANN architecture to capture complex hyperelastic behaviors including exponential strain stiffening.
- Three-stage training scheme (pre-regularization, sparsity subset selection, post-regularization) that stabilizes convergence and enables robust sparse constitutive model identification.
Datasets
- Synthetic biaxial plate-with-hole hyperelastic deformation dataset — ~nn nodes × 10 time steps — generated by finite element simulations with prescribed benchmark hyperelastic models
Baselines vs proposed
- Ground-truth NeoHookean isotropic model: R² stress prediction ≈ 0.99 vs. CANN-EUCLID discovered model: R² ≈ 0.99
- Ground-truth Demiray exponential model (out-of-basis): Shared terms retained; approximated missing terms with reduced accuracy; normalized local errors increased compared to exact-basis cases
- Forward FE validation error: Average L2 displacement error < 5% for discovered models vs unseen loading cases
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.14565.

Fig 3: Schematic illustration of geometries used in training and validation. The training geometry (a) consists of

Fig 2: Schematic summary of the CANN-EUCLID framework. (a) the structural vector and deformation gradient
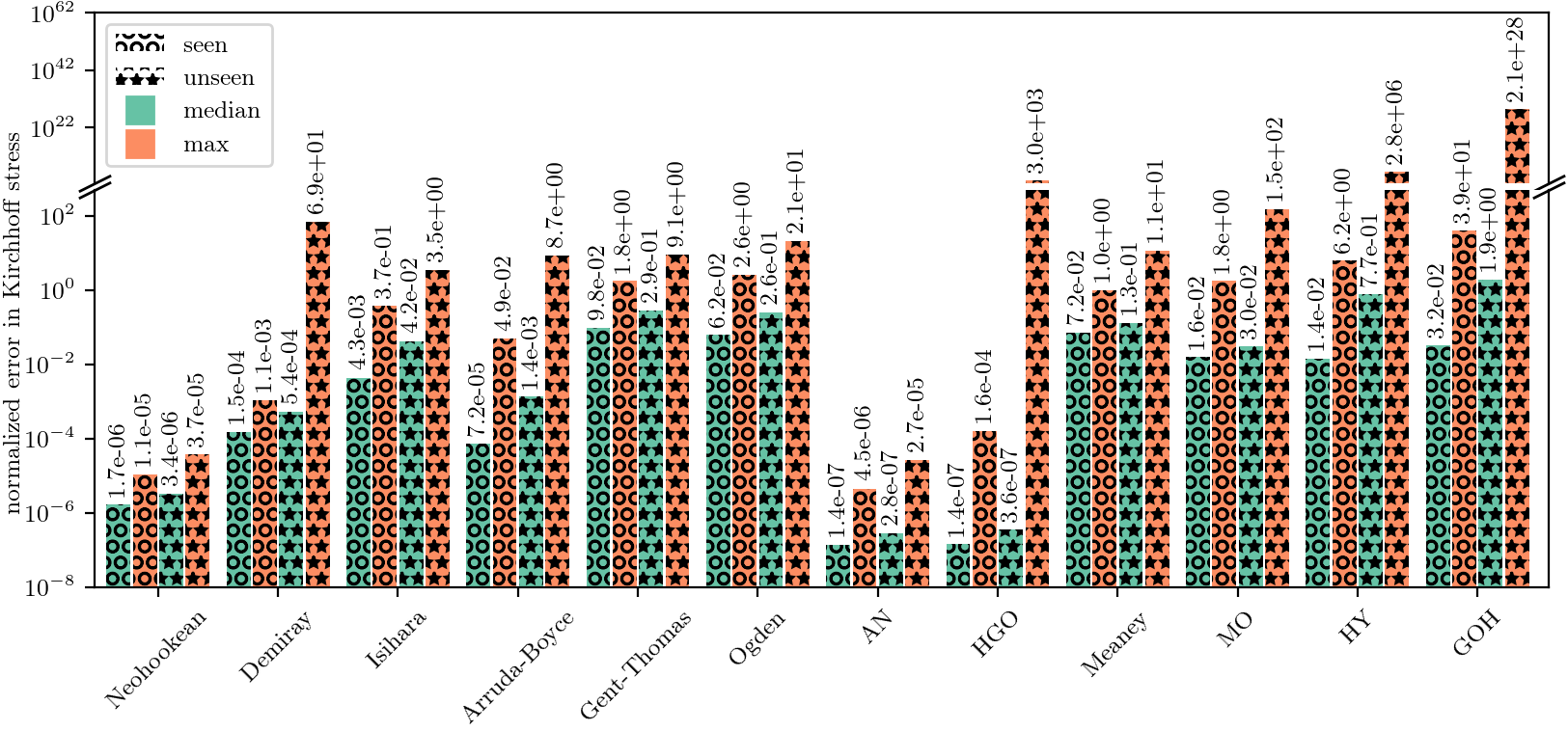
Fig 8: Statistics for CANNs stress prediction accuracy on seen and unseen deformations. The median and
Limitations
- Dependence on sufficient sampling of deformation states to recover nonlinear exponential strain stiffening accurately; poor extrapolation outside sampled domains
- Validation only on synthetic data with prescribed ground truths; no experimental or noisy data validation
- No explicit assessment under noisy measurement, experimental variability, or heterogeneous material property distributions
- Local stress fields are not required but structural vectors A must be approximated or known, which may be non-trivial in practice
- Sparsity regularization hyperparameters and initialization sensitivity require careful tuning; real-world convergence robustness needs further study
- No adversarial or model robustness evaluation to complex loading beyond brittle regimes or dynamic effects
Open questions / follow-ons
- How does CANN-EUCLID perform with experimentally measured displacement fields including noise and measurement error?
- Can the approach be extended to path-dependent or viscoelastic constitutive behaviors beyond hyperelasticity?
- How sensitive is term discovery and generalization to incomplete or partial knowledge of the structural vector fields?
- What are the theoretical guarantees for uniqueness and identifiability of discovered sparse models under limited data?
Why it matters for bot defense
From a bot-defense or CAPTCHA practitioner's standpoint, CANN-EUCLID illustrates advanced model discovery that leverages indirect measurement data (displacement fields and reaction forces) to extract interpretable, sparse artificial neural networks modeling complex systems without direct supervision on internal variables (stress). This parallels situations in bot detection where only higher-level interaction data is available, and interpretable models must be inferred without direct observation of internal bot decision processes. The stress-unsupervised training and sparsity constraints provide a compelling example of balancing model expressivity, interpretability, and data availability constraints—a conceptual approach potentially translatable to bot behavior modeling. However, application requires adaptation of analogous invariant inputs and domain-specific function spaces appropriate to bot interaction data rather than mechanical deformation invariants. The emphasis on generalization across unobserved conditions resonates with dynamic bot defense challenges where attack vectors evolve beyond training samples. Thus, the methodological insights into sparse interpretable discovery from indirect equilibrium conditions may inspire novel techniques in CAPTCHA and bot behavioral analytics, emphasizing minimal supervision and physical consistency analogs.
Cite
@article{arxiv2606_14565,
title={ CANN-EUCLID: unsupervised constitutive artificial neural network model discovery from full-field data },
author={ Benjamin Alheit and Siddhant Kumar and Mathias Peirlinck },
journal={arXiv preprint arXiv:2606.14565},
year={ 2026 },
url={https://arxiv.org/abs/2606.14565}
}