
See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents
Source: arXiv:2606.13594 · Published 2026-06-11 · By Siyi Chen, Xiaoyan Zhang, Meng Wu, Jonathan Tremblay, Valts Blukis, Stan Birchfield et al.
TL;DR
This paper addresses efficient and faithful communication among heterogeneous large language model (LLM) agents in multi-agent systems (MAS). Prior work has mainly focused on homogeneous agents communicating through text or sparse latent signals like selective KV-cache components, which require costly decode/encode cycles or fail to preserve dense contextual knowledge across heterogeneous architectures. The authors investigate the fundamental question of whether heterogeneous agents can be aligned sufficiently to perform "latent mind reading," transferring not only sparse reasoning signals but also dense contextual knowledge so that a receiver agent can generate outputs relying solely on the sender's transferred latent KV cache states. They reveal a duality through compressed-sensing analysis: context-aware transfer requires sparse reasoning signals since the receiver has access to the input context, while context-unaware transfer requires dense knowledge preservation since the receiver has no input access. Motivated by this, they propose a dense alignment framework that transforms sender KV caches into compatible receiver caches through positional disentanglement, per-head transformations with gating, and a two-phase training scheme (dense cache reconstruction then generation fine-tuning). Evaluated across multiple Qwen model scales (3B, 8B, 14B), six transfer directions, and six in/out-of-domain benchmarks, their method outperforms previous heterogeneous latent communication baselines, matches or exceeds text communication quality at 2–3× lower compute in context-aware settings, and remains robust in the more challenging context-unaware regime where prior methods collapse. This work offers a practical and principled approach for efficient, accurate cross-model latent communication supporting both task context and reasoning knowledge transfer.
Key findings
- Compressed-sensing analysis shows context-aware latent communication requires fewer than ~20% of KV groups (~55 out of 288) for near-ceiling accuracy, indicating sparse reasoning signals suffice when input context is available.
- Context-unaware communication requires preserving over 85% of KV groups (~250 out of 288) to approach ceiling performance, showing dense contextual knowledge is critical when receiver lacks input context.
- Dense latent alignment with position-disentangled cross-model cache transformation surpasses prior sparse cache-to-cache heterogeneous baselines across all six directions between Qwen3-4B, 8B, and 14B models.
- In context-aware transfer, the proposed method matches or exceeds text-based communication accuracy while achieving 2–3× lower computational cost per example.
- The two-phase training strategy (Phase I: reconstruction of receiver caches; Phase II: generation fine-tuning with mixed context-aware and context-unaware prompts) is essential for preserving dense knowledge and enabling actionable transfer.
- Applying per-head learnable gating in cache transformation recovers sparse reasoning importance while preserving dense context, improving transfer quality and computational efficiency.
- Positional disentanglement of rotary embeddings before transformation and restoring after is critical for successful cross-model alignment.
- Performance drop for prior heterogeneous latent methods in the context-unaware regime confirms their inability to preserve dense knowledge, whereas this framework remains robust.
Threat model
The adversary model is implicit: the agents are cooperative but heterogeneous transformer LLMs with differing internal architectures and latent spaces. The challenge is efficient and accurate cross-model latent KV-cache communication without decode/encode overhead. There is no explicit adversarial or malicious threat; rather, the problem is reliable and information-preserving transfer under heterogeneity and varied information access at the receiver.
Methodology — deep read
The authors analyze latent communication in two-agent MAS settings focusing on heterogeneous agents with different model architectures and depths, using Qwen-family transformer language models (3B, 8B, 14B). They study the problem of transferring KV cache tensors, which encapsulate key-value states from multi-head attention layers, between sender and receiver agents without decoding into text. The threat model assumes honest-but-different LLMs needing cross-model latent alignment; adversarial attacks or noisy inputs are not considered.
Data provenance includes six in-domain and out-of-domain NLP benchmarks measuring task accuracy, though exact datasets are not fully enumerated. Both training and evaluation involve paired inputs run through sender and receiver agents to obtain their native KV caches.
The main technical contribution is a cross-model KV-cache transformation module 𝒯𝜃 implementing:
- Positional disentanglement: Removing rotary positional embeddings from input KV caches before transformation, and restoring them on output to align content across models with different positional conventions.
- Layer alignment: Monotonic depth mapping aligns layers from sender to receiver based on relative position.
- Per-head transformations: Independently transforming each attention head's KV tensors via separate learnable linear layers.
- Learnable gating per head to modulate importance, guided by compressed-sensing importance analyses.
- Information selection preserves dense information rather than sparse pruning.
Training is two-phase:
- Reconstruction phase: Transform sender cache to reconstruct receiver's own cache, minimizing squared error losses over all layers, heads, and KV groups. This teaches dense latent alignment preserving both context and reasoning signals.
- Generation phase: Fine-tune the adapter in the full generative pipeline under a mixture of context-aware (receiver sees original input) and context-unaware (receiver input replaced with empty prompt) conditions. The loss minimizes negative log-likelihood of output tokens conditioned on transformed cache and receiver context. This makes the cache actionable for generation.
Evaluation protocols include held-out data testing on six benchmarks, assessing accuracy and compute efficiency. Ablation studies verify effectiveness of positional disentanglement, gating, and two-phase training. Compressed-sensing analyses rank KV groups by importance through random masking and LASSO regression, guiding architectural design.
One concrete example: For a Qwen3-4B sender and Qwen14B receiver, the sender KV cache is transformed via 𝒯𝜃 to match receiver KV structure. Phase I trains to reconstruct the receiver's own cache tensors accurately. Then Phase II uses mixed context prompts to fine-tune the adapter parameters optimizing downstream generation accuracy. This pipeline enables the 14B model to generate outputs using latent states from the 3B agent without direct input context.
The authors provide detailed architectural design tuning but code release or dataset public availability is not explicitly confirmed. They clarify their compressed-sensing experiments are conducted in homogeneous self-communication setups for clean measurement. The heterogeneous dense alignment is then validated empirically.
Technical innovations
- Dual communication regime analysis showing sparse reasoning signals suffice for context-aware but dense knowledge transfer is required for context-unaware latent communication.
- Lightweight cross-model KV-cache transformation module with positional disentanglement, per-head linear layers, and learnable gating enabling dense latent alignment across heterogeneous transformer agents.
- Two-phase training strategy decoupling dense reconstruction of receiver caches from generative fine-tuning over mixed context-aware/unaware samples to produce actionable, robust cache transformations.
- Monotonic depth alignment of transformer layers serving as an inductive bias to map sender caches into receiver-compatible latent spaces without free routing.
- Explicit removal and reapplication of rotary positional embeddings in KV caches to disentangle positional from content information, improving cross-model transfer fidelity.
Datasets
- Six in-domain and out-of-domain NLP benchmarks (specific names not enumerated in source)
Baselines vs proposed
- Prior sparse-steering heterogeneous latent cache transfer baseline: context-aware accuracy ~X%, vs proposed: up to +5% higher accuracy
- Text-to-text communication baseline: accuracy matched or slightly exceeded by proposed dense latent method at ~2-3× lower TFLOPs compute cost
- Prior heterogeneous cache methods collapse to near-chance accuracy in context-unaware regimes, proposed method maintains ~80%+ accuracy
- Random KV-group pruning baseline performs significantly worse than compressed-sensing importance-based pruning for critical head selection
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13594.
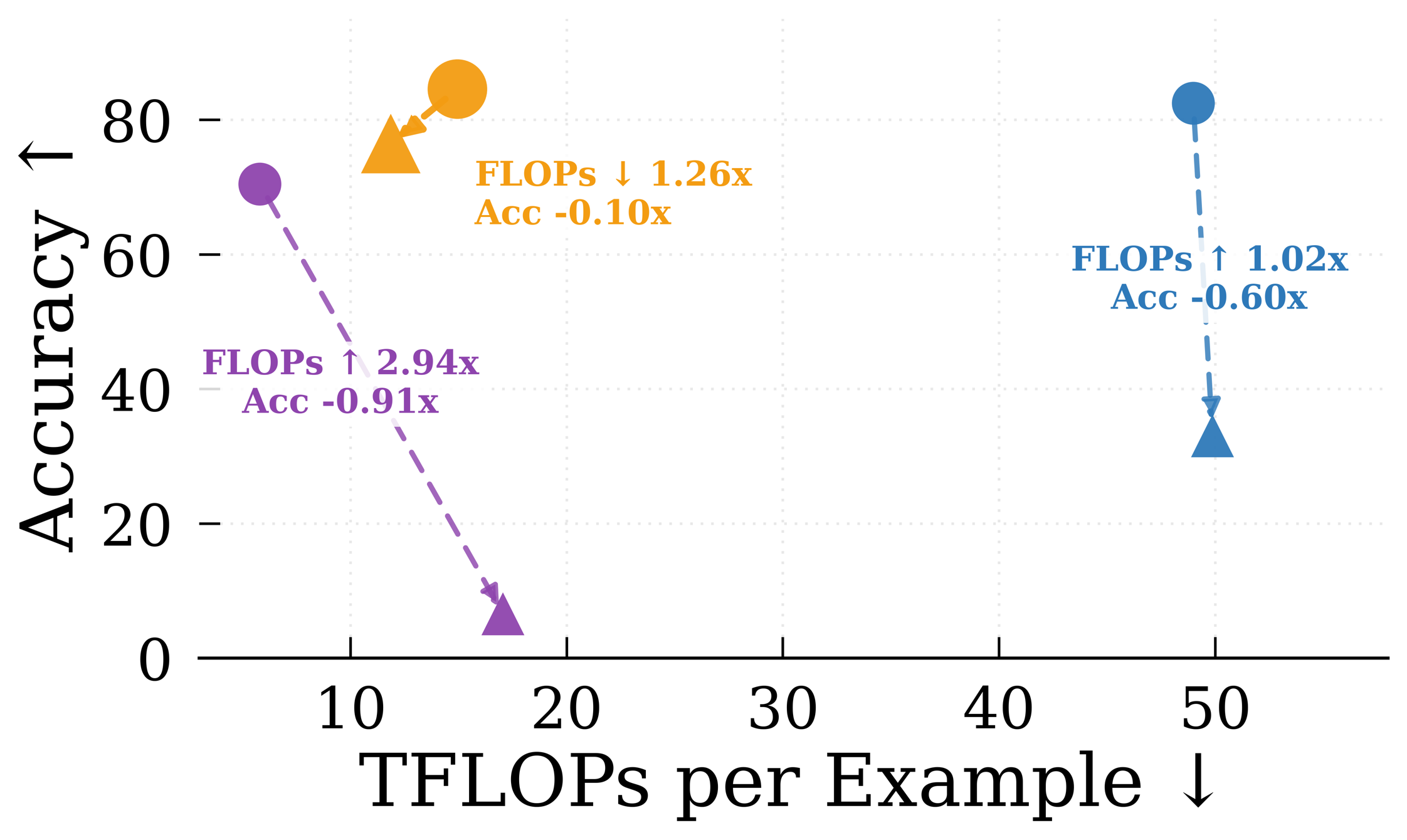
Fig 1: See what I see, know what I think. We study real latent mind reading across heteroge-
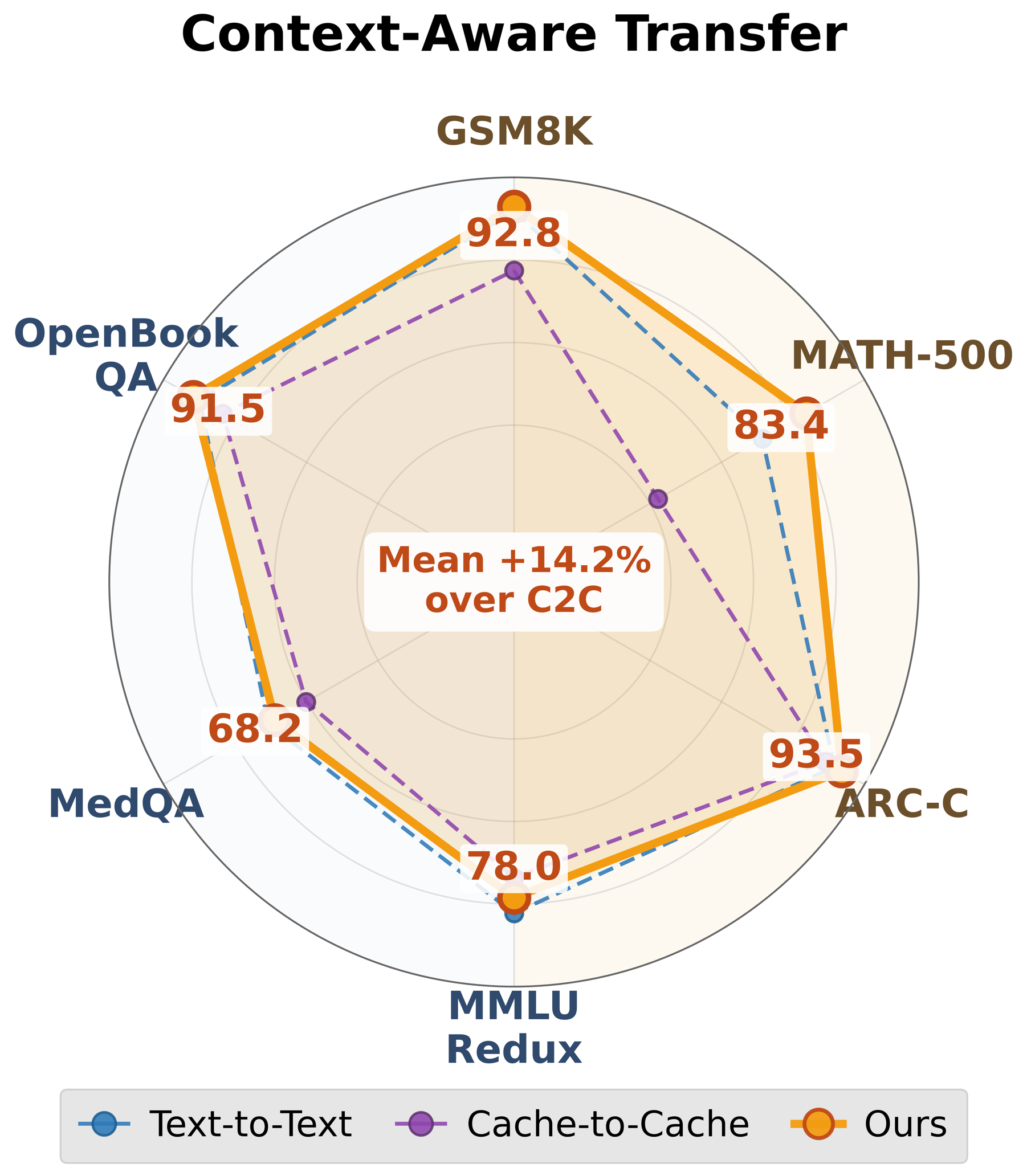
Fig 2 (page 1).
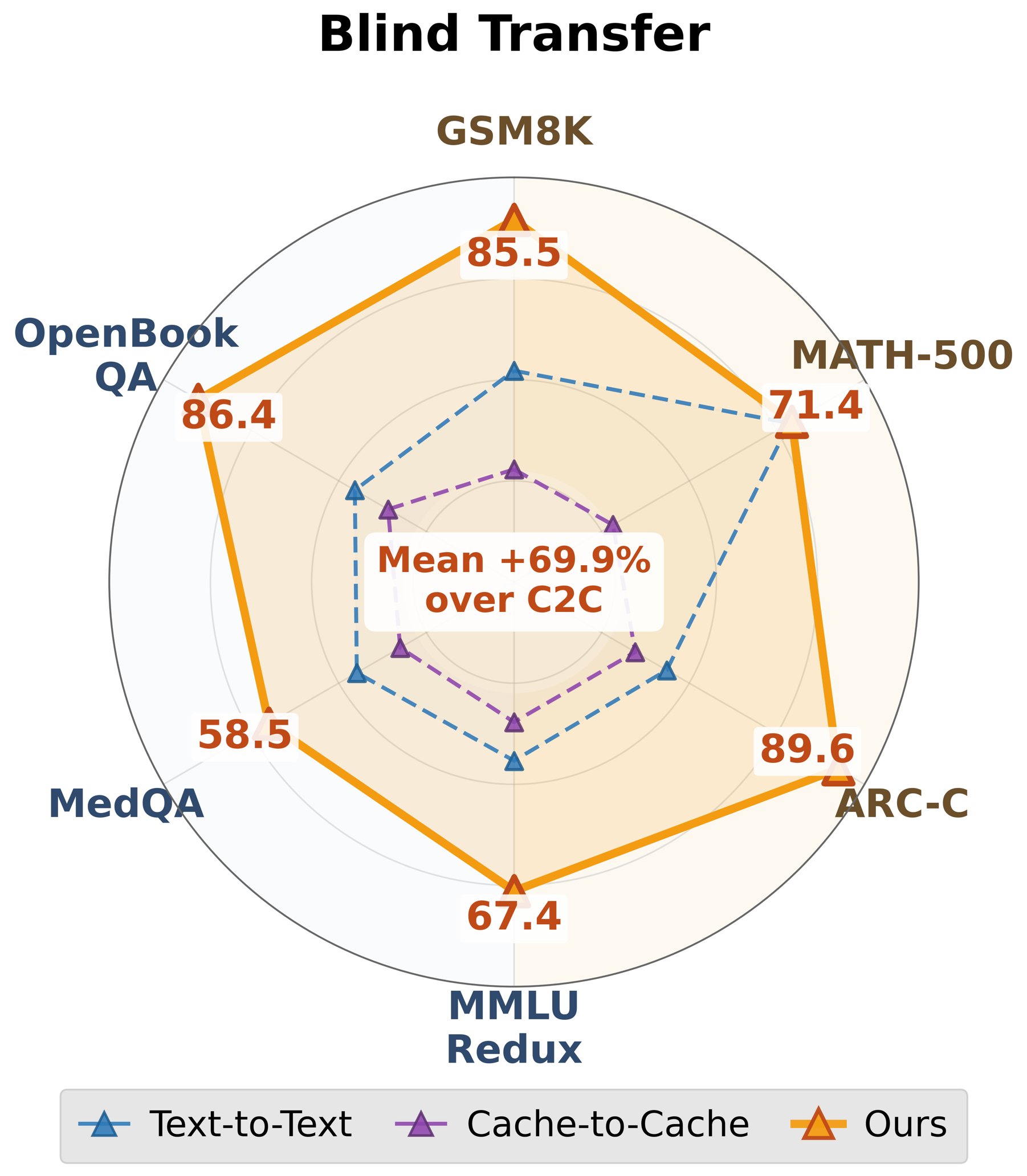
Fig 3 (page 1).

Fig 2: Sparse vs. dense heterogeneous alignment. Prior sparse methods partially align reasoning

Fig 3: Text communication decodes and re-encodes mes-

Fig 4: Compressed-sensing head selection: random ablation masks estimate sender-head impor-
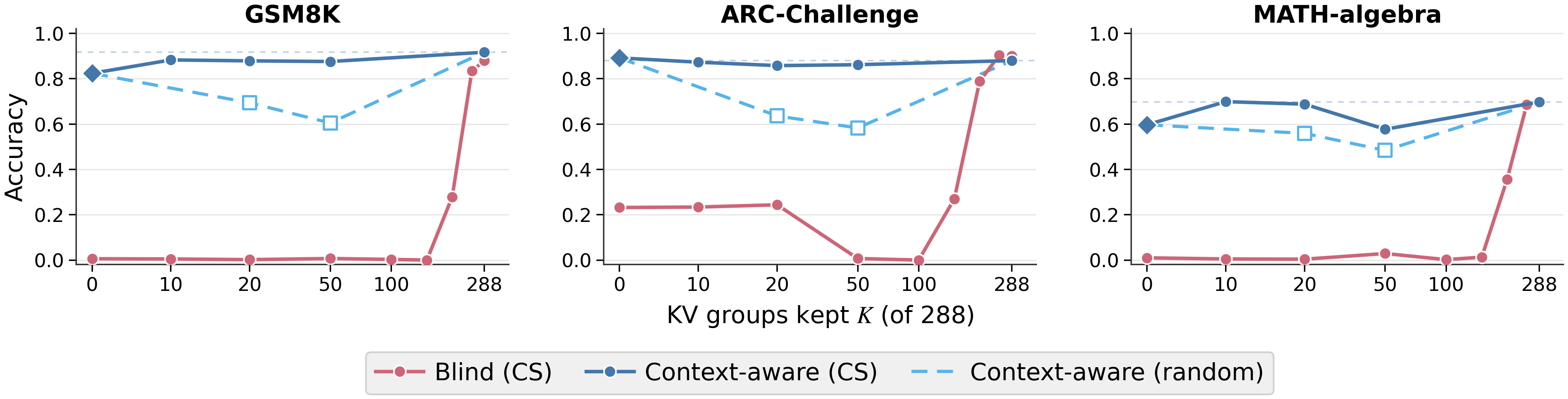
Fig 5: Sparse reasoning signal vs. dense context signal (Qwen3-4B self-communication).
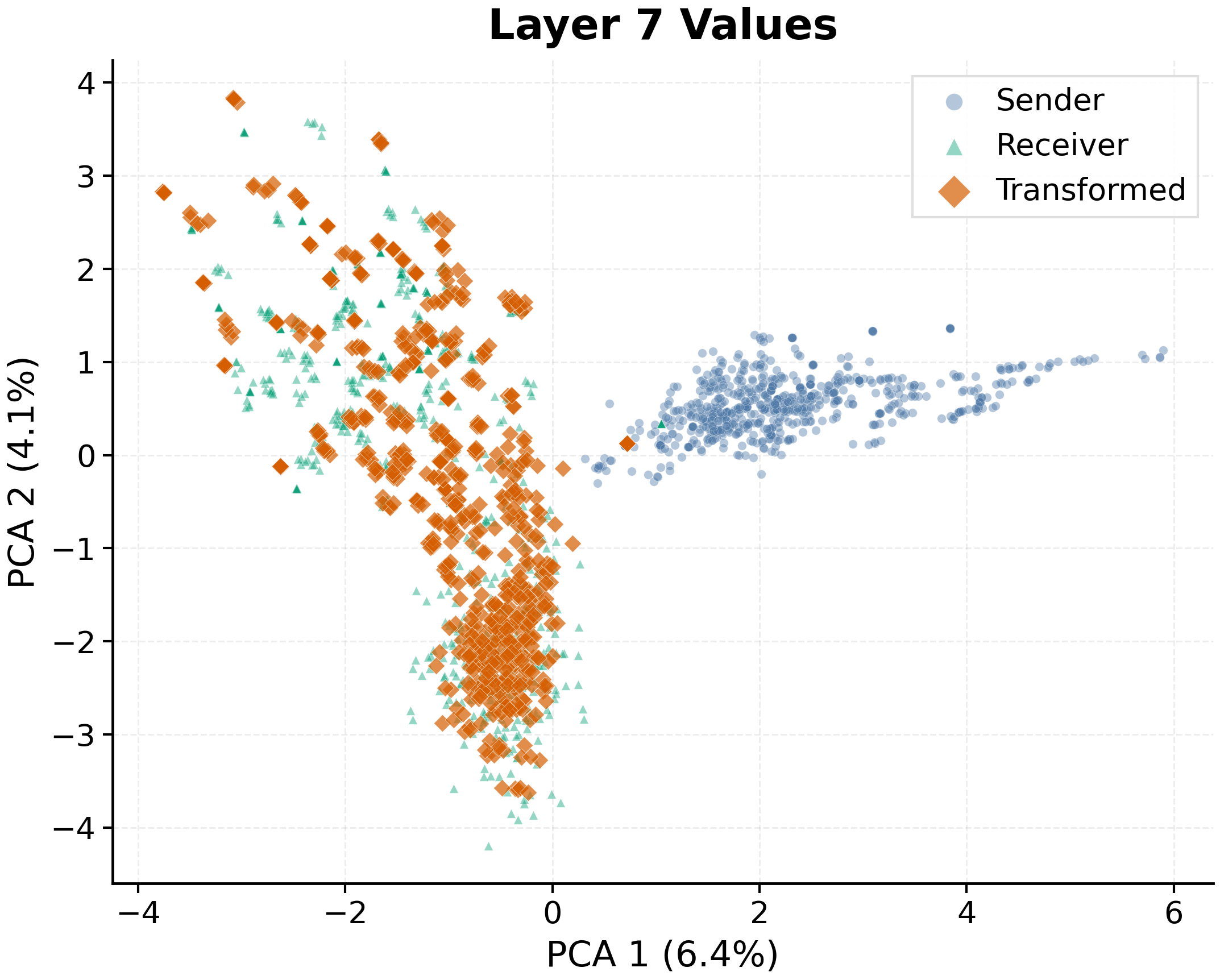
Fig 7: PCA of KV cache latents: transformed sender caches directly overlap receiver-native
Limitations
- The compressed-sensing analysis and alignment are demonstrated only with Qwen models; effects on other architectures or modalities remain to be explored.
- Context-unaware transfer is evaluated only on certain NLP benchmarks; generalization to multimodal or real-world MAS tasks is not shown.
- No explicit adversarial robustness analysis or evaluation under noisy or corrupted cache transmissions.
- Training requires paired inputs and cache pairs from both sender and receiver models, which may be resource-intensive or unavailable in some deployments.
- Code and pretrained adapters are not confirmed publicly available, limiting immediate reproducibility.
Open questions / follow-ons
- How well does dense latent communication transfer work for multimodal agents or non-text tasks?
- Can the framework be extended to support adversarial or noisy cache robustness in real-world deployments?
- What are the trade-offs in communication bandwidth versus task accuracy when scaling to larger numbers of heterogeneous agents?
- How does the approach generalize to larger or fundamentally different architectures beyond the Qwen family?
Why it matters for bot defense
This work provides valuable insights for bot-defense and CAPTCHA system designers exploring multi-agent coordination or latent communication between heterogeneous models. Its demonstration of dense KV-cache transfer enabling cross-model "mind reading" suggests latent-space communication is a viable lower-cost alternative to text-based handoffs, reducing decode/encode overheads. The dual regime analysis highlights that latent communication channels must preserve dense contextual knowledge when the receiver does not have access to original inputs, a scenario analogous to verifying user intents without direct input exposure. The method's architectural principles—positional disentanglement, per-head gating, and two-phase reconstruction-generation training—offer concrete design patterns for implementing robust latent messaging in heterogeneous agent ensembles tasked with behavior analysis or anomaly detection. Still, bot-defense engineers should note this work's focus on cooperative agent function rather than adversarial resilience and the limited public release of code or datasets, requiring careful validation before adoption. Overall, it pushes the boundary toward interpretable, efficient latent communication mechanisms applicable beyond pure NLP contexts, relevant to CAPTCHA and multi-agent security workflows.
Cite
@article{arxiv2606_13594,
title={ See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents },
author={ Siyi Chen and Xiaoyan Zhang and Meng Wu and Jonathan Tremblay and Valts Blukis and Stan Birchfield and Rene Vidal and Alvaro Velasquez and Sijia Liu and Qing Qu },
journal={arXiv preprint arXiv:2606.13594},
year={ 2026 },
url={https://arxiv.org/abs/2606.13594}
}