
Person Identification from Contextual Motion
Source: arXiv:2606.13410 · Published 2026-06-11 · By Igor Kviatkovsky, Ehud Rivlin, Ilan Shimshoni
TL;DR
This paper addresses the problem of person identification based on motion patterns, moving beyond standard gait recognition to general body actions and especially introducing a novel interactive identification scenario. The authors propose a unifying probabilistic generative framework modeling the creation of action instances and the inference of person identity under three scenarios: smart home (passive observation, unknown action context), login/authentication (known action context set by system), and interactive (sequential mutual exchange with cues chosen to maximize identity information gain).
The interactive scenario, a novel contribution, frames the identification process as a closed-loop communication over a noisy channel between system and subject. The system presents visual cues to elicit discriminative motion responses, sequentially selecting optimal cues under a maximum mutual information principle to rapidly reduce identity uncertainty. The authors build a fully functional real-time system demonstrating this approach, and introduce a new CuedId dataset (4,476 recordings, 22 users, 15 cues) for this setting. Experiments on this and other publicly available datasets show high recognition rates, illustrating that combining heterogeneous action types and interactively chosen cues substantially improves person identification accuracy from motion, even under noise and partially unknown action contexts.
Key findings
- The proposed generative probabilistic framework enables person identification across three scenarios: Smart home (unknown action labels), Login (known action labels), and a novel interactive scenario.
- In the interactive identification scenario, cues are selected to maximize conditional mutual information I(u; x|c), accelerating convergence to correct identity with theoretical guarantees.
- On the CuedId dataset (22 subjects, 4,476 recordings, 15 cues), the interactive system achieves high recognition accuracy using heterogeneous sets of atomic actions.
- Combining multiple heterogeneous action types leads to better identity discrimination than using homogeneous sets of actions (Fig. 4 illustrates ambiguity resolved by heterogeneous combination).
- Action-specific PCA+LDA feature dimensionality reduction followed by Mahalanobis distance-based KDE likelihood estimate improves identity classification.
- Leave-one-subject-out training ensures action classifiers used to estimate p(a|x) generalize fairly to unseen users, avoiding bias.
- Temporal normalization (resampling actions to fixed sequence length) improves user identification performance despite rate variation carrying user-specific style information.
- The framework and system handle noisy motion capture data from low-cost sensors like Kinect, demonstrating robustness.
Threat model
The identity inference system considers an adversary who is a legitimate subject whose identity is unknown and must be estimated from noisy motion responses. The adversary is passive and not adversarial in a spoofing sense; they provide motion according to cues but do not deliberately deceive. The system cannot handle unknown users outside the closed registered set and relies on probabilistic models built on training data.
Methodology — deep read
- Threat Model and Assumptions:
- The adversary is modeled implicitly as a system trying to identify a subject based on motion response patterns.
- Subjects belong to a closed set of known identities with recorded training samples.
- Interaction follows a sequential process where the system actively selects cues to elicit maximally informative responses.
- The subject's response action class p(a|c,u) and motion pattern p(x|a,u) are probabilistic and possibly noisy.
- Data:
- Five publicly available action datasets adapted for identification evaluation.
- The new CuedId dataset: 22 subjects, 4,476 recordings responding to 15 predefined visual cues; real-time Kinect-based skeleton tracking.
- The MSRC-12 dataset also used.
- Training/test splits use leave-one-subject-out to prevent data leakage.
- Architecture / Algorithm:
- A hierarchical generative probabilistic model for motion instance creation:
- User identity u
- Cue c (interactive scenario)
- Intended action type a conditioned on cue and user p(a|c,u)
- Motion instance x conditioned on a and u p(x|a,u)
- Identity posterior updated via Bayes rule considering the likelihood of observed motions and intended action types.
- Actions represented as sequences of 3D normalized joint positions (JP), temporally normalized to fixed length L=15 or 60.
- Dimensionality reduction per action class by PCA followed by LDA learned on identity labels, enabling Mahalanobis distance metric for kernel density estimation p(x|a,u).
- Action classification p(a|x) done using pre-trained linear SVM classifiers with a leave-one-user-out scheme.
- Interactive identification applies maximum mutual information cue selection:
- At each iteration t, choose cue c_t that maximizes expected information gain I(u; x_t| c_t)
- Observe subject response x_t, update posterior p_t(u)
- Iterate until posterior confidence exceeds threshold.
- Training Regime:
- Action classifiers trained on all users except the test user.
- PCA and LDA learned on labeled action instances from training users.
- No explicit mention of hardware or random seed strategy.
- Evaluation Protocol:
- Recognition accuracy measured on test users.
- Performance analyzed for homogeneous versus heterogeneous action instance sets.
- Ablations include: impact of combining multiple actions, effect of interactive cue selection versus random cues.
- Results shown on CuedId and MSRC-12 datasets.
- No explicit statistical significance testing mentioned.
- Reproducibility:
- Authors commit to releasing both CuedId dataset and source code for research.
- Details sufficient to replicate action representation and classification pipeline.
- Some model parameters like PCA/LDA dimensions are empirically chosen.
Concrete Example:
- In the interactive scenario, at iteration t=1, system has prior p_0(u), selects cue c_1 maximizing mutual information.
- Subject performs action x_1 in response.
- System estimates updated posterior p_1(u) using p(x_1|a,u) and p(a|c_1,u) from training data.
- Next cue c_2 chosen similarly to further reduce uncertainty until confident identification.
Technical innovations
- Introduction of a novel interactive person identification scenario formalized as a closed-loop communication over a noisy channel with sequential cue selection.
- Probabilistic generative model separating cue, intended action type, and motion response, enabling Bayesian posterior updates for identity inference.
- Application of maximum mutual information (MMI) principle to actively select visual stimuli (cues) that elicit motion responses maximizing identity information gain.
- Action-specific metric learning combining PCA and LDA for dimensionality reduction and Mahalanobis distance to model identity-discriminative likelihoods p(x|a,u).
- Development and public release of the CuedId dataset consisting of interactive cue-response motion sequences for person identification research.
Datasets
- CuedId — 4,476 recordings from 22 subjects responding to 15 cues — collected by authors, to be publicly released
- MSRC-12 — skeleton-based action recognition dataset — publicly available
Baselines vs proposed
- Using single homogeneous action type: lower recognition accuracy (exact numbers not provided) vs heterogeneous action sets: significantly higher accuracy
- Random cue selection in interactive scenario: slower convergence and lower identification accuracy vs proposed MMI-based cue selection: faster, higher accuracy
- JP-SVM action classifier used for p(a|x) with leave-one-user-out training to ensure identity generalization, achieving good classification margins
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13410.
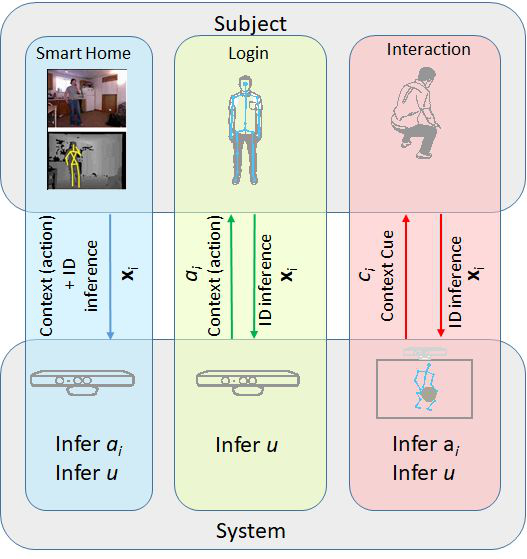
Fig 1: (a) Different scenarios for person identification from motion
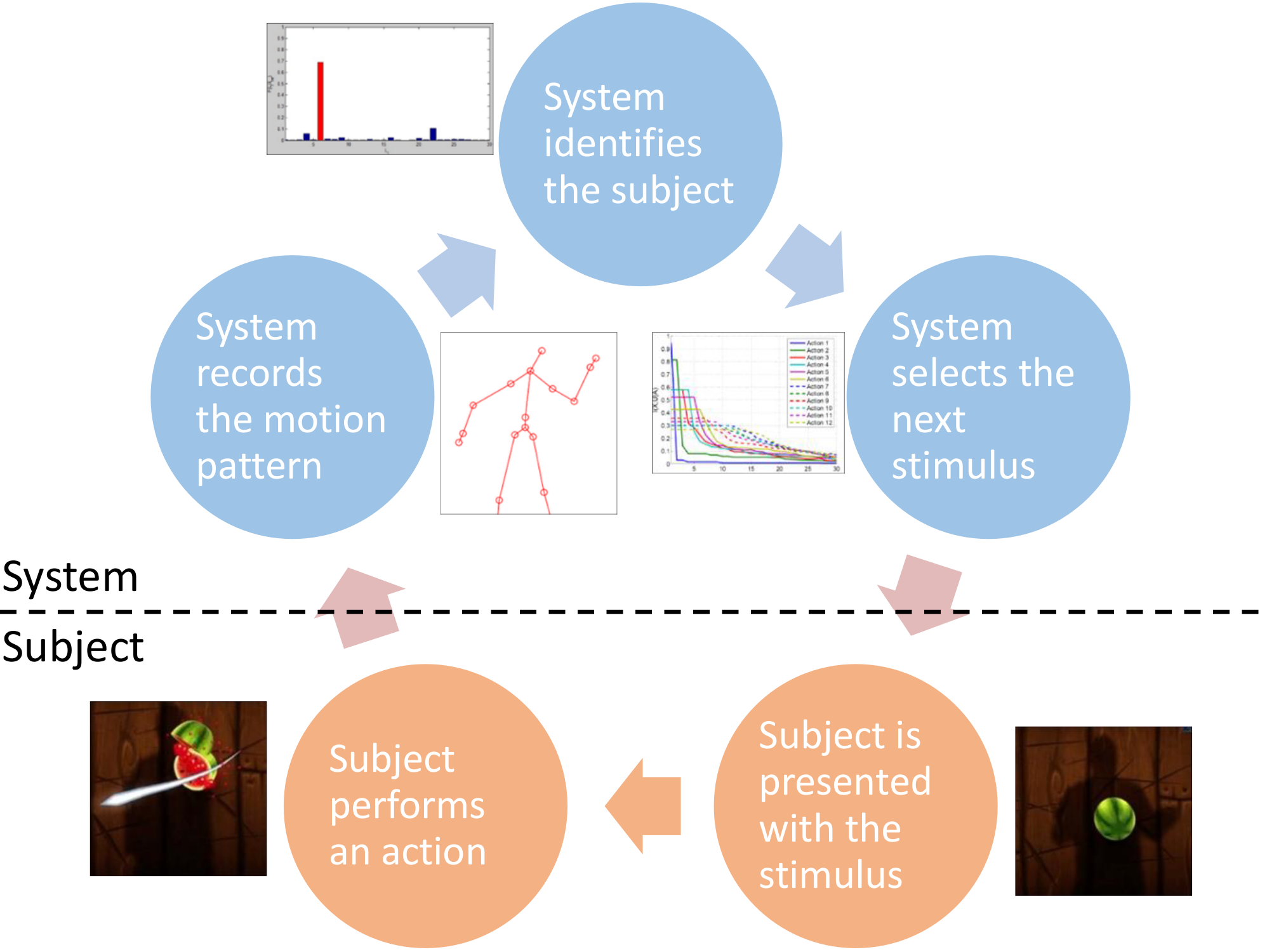
Fig 2: Interactive identification process. A cue is displayed, a person
Limitations
- Closed-set assumption: system can only identify subjects from previously seen identities (no open-world unknown identity handling).
- Subject responses constrained to predefined atomic cues and action sets; variability and ecological validity of free-form responses unclear.
- Experiments focus on Kinect-based skeleton data which may be noisy; robustness to different sensors or real-world deployment conditions not extensively evaluated.
- No explicit adversarial evaluation; robustness to spoofing or deliberate imitation attacks is not analyzed.
- Limited user pool sizes (22 subjects in CuedId) and moderate dataset sizes; larger-scale evaluations would increase confidence.
- The system assumes subjects do not deliberately try to deceive or manipulate their motion to avoid identification.
Open questions / follow-ons
- How to extend the interactive identification framework to open-set scenarios with unknown or novel users?
- What is the resilience of the system to active adversarial attacks such as mimicry, deception, or spoofing of motion patterns?
- Could deep learning models jointly trained end-to-end improve modeling of p(x|a,u) and cue selection for better accuracy and faster convergence?
- How would the system perform under realistic real-world constraints such as occlusions, multi-person scenes, or cross-sensor variations?
Why it matters for bot defense
This work introduces a fundamentally different modality and interaction paradigm for identity verification—motion patterns elicited via interactive cueing rather than passive observation or static biometrics. For bot-defense and CAPTCHA practitioners, the concept of driving interaction to extract discriminative biometrics with maximum information gain is instructive.
Implementing such active challenge-response systems leveraging human motion responses could supplement traditional CAPTCHAs, especially in privacy-sensitive or visually constrained environments. However, one must consider system complexity, required hardware (depth sensors), and user experience tradeoffs. The probabilistic framework and mutual information cue optimization strategies presented provide a principled foundation that could inspire more adaptive and interactive challenge designs targeting human motor patterns or behavioral biometrics.
Cite
@article{arxiv2606_13410,
title={ Person Identification from Contextual Motion },
author={ Igor Kviatkovsky and Ehud Rivlin and Ilan Shimshoni },
journal={arXiv preprint arXiv:2606.13410},
year={ 2026 },
url={https://arxiv.org/abs/2606.13410}
}