
One Polluted Page Is Enough: Evaluating Web Content Pollution in Generative Recommenders
Source: arXiv:2606.13610 · Published 2026-06-11 · By Minghao Luo, Liang Chen
TL;DR
This paper addresses a critical but understudied risk in search-augmented large language model (LLM) recommenders: susceptibility to polluted web content. Unlike typical training-time poisoning or prompt attacks, this risk arises because LLMs ingest live web search results that can be polluted by fake reviews or promotional pages created by Generative Engine Optimization (GEO) operators. The authors introduce FORGE, a novel benchmark that simulates web-content pollution by rewriting real product mentions in retrieved pages to fake ones and measures how often LLMs recommend these fakes. They evaluate 12 commercial and open-weight LLMs on 225 products across 15 categories and 5 consumer scenarios, revealing universal vulnerability—single polluted pages fool models up to 27% of the time, and replacing the top 3 results boosts fooled rates as high as 73.8%. Vulnerability varies by product category, correlating inversely with a model’s stable prior brand knowledge, and is exacerbated rather than mitigated by reasoning. The authors also test three inference-time defenses, finding skepticism prompting often backfires while consensus filters suppress many legitimate recommendations. The work highlights the significant risk from live web pollution in generative recommenders and the inadequacy of simple inference-time mitigations, motivating retrieval-time robustness strategies.
Key findings
- A single top-ranked polluted page causes fooled recommendation rates up to 27% across models (Figure 4).
- Replacing the entire top-3 retrieved pages with polluted content raises average fooled rates to 73.8% (Figure 2, Table 2).
- Vulnerability varies widely by category, with everyday-consumption categories like dining and personal services showing fooled rates above 60%, while technical categories like smartphones remain under 30% (Table 2).
- Model size and closed-vs-open source status do not predict robustness; some larger or closed-source models are among the most vulnerable (Figure 2).
- Reasoning activation increases vulnerability by up to 18 percentage points by causing the model to elaborate on and endorse fake products (Figure 3, Figure 9).
- Fooled outputs generate invented social proof far more frequently (1.5 to 11 times the rate) than resisted cases, constructing spurious justification phrases absent in evidence.
- Skepticism prompting as a defense uniformly fails and backfires on closed-source models by increasing fooled rates by up to 44 percentage points (Figure 10).
- Consensus filtering over model priors or cross-document agreement reduces fooled rates by 90%-95% but at a cost of suppressing 52%-79% of legitimate recommendations (Figure 11).
Threat model
An adversary controlling GEO operators who injects plausible user-style fake content (reviews, promotional pages) into the open live web. They have no direct write or poison access to training data, retrieval corpora, or the LLM prompt but rely on commercial search engines indexing and surfacing their polluted pages. The adversary’s success is measured by whether the LLM subsequently recommends the fake brands when consuming retrieved search evidence, without triggering refusal or detection by the model.
Methodology — deep read
The threat model assumes an adversary who cannot directly modify the LLM or controlled training/retrieval pipelines but can inject plausible fake content (fake reviews, promotional pages) into the open live web. Such polluted pages are indexed by commercial search engines and retrieved by the LLM recommender system, which then consumes them without awareness of pollution.
The authors create the FORGE benchmark to measure vulnerability under this setting. They curate 225 real-world products over 15 categories and 5 consumer scenarios, focusing primarily on Chinese-language queries reflecting regional GEO activity. For each product, a realistic user query template is crafted. Live search results from commercial engines are frozen after a multi-stage quality filter to serve as evidence bundles.
Rather than polluting the live web, FORGE locally rewrites the top-K retrieved documents in three styles: (A1) entity replacement swaps the main real brand mention to a fake brand-product compound preserving URLs and context; (A2) passage injection inserts a fake-promoting paragraph without altering real mentions; (A3) full synthesis replaces document bodies entirely with synthetic fake reviews. This maintains controlled conditions for reproducibility.
The core evaluation metric is 'fooled rate,' the fraction of (model, product) pairs where the model’s recommendation includes the fake brand as exact or prefix match, verified to accurately indicate real endorsement rather than token coincidence or warnings. 12 production LLMs (6 closed-source and 6 open-weights) are evaluated on all 225 products via single greedy decoding, under various pollution conditions (single polluted page at each rank, multiple polluted pages up to top 10, differing pollution styles).
In-depth analyses include cross-model prior brand agreement (measured via Jaccard similarity on no-evidence brand probes), paired trials disabling reasoning for causal testing, and social-proof lexicon scans to characterize hallucination confabulation. Defense experiments evaluate three inference-time mitigations: skepticism prompting (instruction-based distrust), model-prior consensus filters admitting only brands surfacing without evidence, and cross-document corroboration filters requiring brands to appear in multiple retrieved documents.
The authors provide extensive per-model, per-category breakdowns, dose-response curves, and hold reasoning constant to identify causal effects. The full pipeline is run on frozen evidence bundles for reproducibility; an English-language replication on 3 categories with 12 models confirms generality. Code and benchmarks are released for community use. Ethical considerations motivated local pollution simulation rather than live web tampering.
One concrete example: for the product "screen protector", the dominant brand mention in the top search result is swapped for a fake brand. The LLM, when prompted with the polluted bundle, outputs a recommendation featuring the fake brand along with invented community praise. Under skepticism prompting, the same model increases the rate of fake brand endorsement, demonstrating the failure of that defense.
Technical innovations
- FORGE benchmark that simulates controlled web-content pollution via local rewriting of real web evidence to measure generative recommender vulnerability.
- Systematic evaluation of 12 commercial and open-weight LLMs across 225 products, 15 categories, and 5 scenarios with dose-response and rank-position pollution curves.
- Categorical vulnerability analysis correlating model resistance with stable prior knowledge quantified by cross-model brand agreement under no-evidence conditions.
- Identification that reasoning and skepticism prompting can exacerbate vulnerability by causing models to elaborate and reinforce fake brands with spurious social proof.
- Evaluation of consensus filtering defenses revealing a tradeoff between catching fake brands and suppressing legitimate recommendations.
Datasets
- FORGE benchmark — 225 real-world products across 15 categories and 5 consumer scenarios — curated frozen evidence bundles from live commercial web searches
- English replication subset — 3 product categories (Smartphones, Skincare, SF Restaurants), 10 products each, US-region SERP
Baselines vs proposed
- No defense baseline: fooled rate up to 73.8% under top-3 entity-replacement pollution vs skepticism prompting defense: fooled rate increased on average by +10.5 pp, up to +44 pp on Gemini 3.1 Pro
- No defense baseline vs model-prior consensus filter (D2): fake-brand catch rate 95% with legitimate-brand survival 32%
- No defense baseline vs cross-document evidence-agreement filter (D3): fake-brand catch rate 90% with legitimate-brand survival 37%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13610.
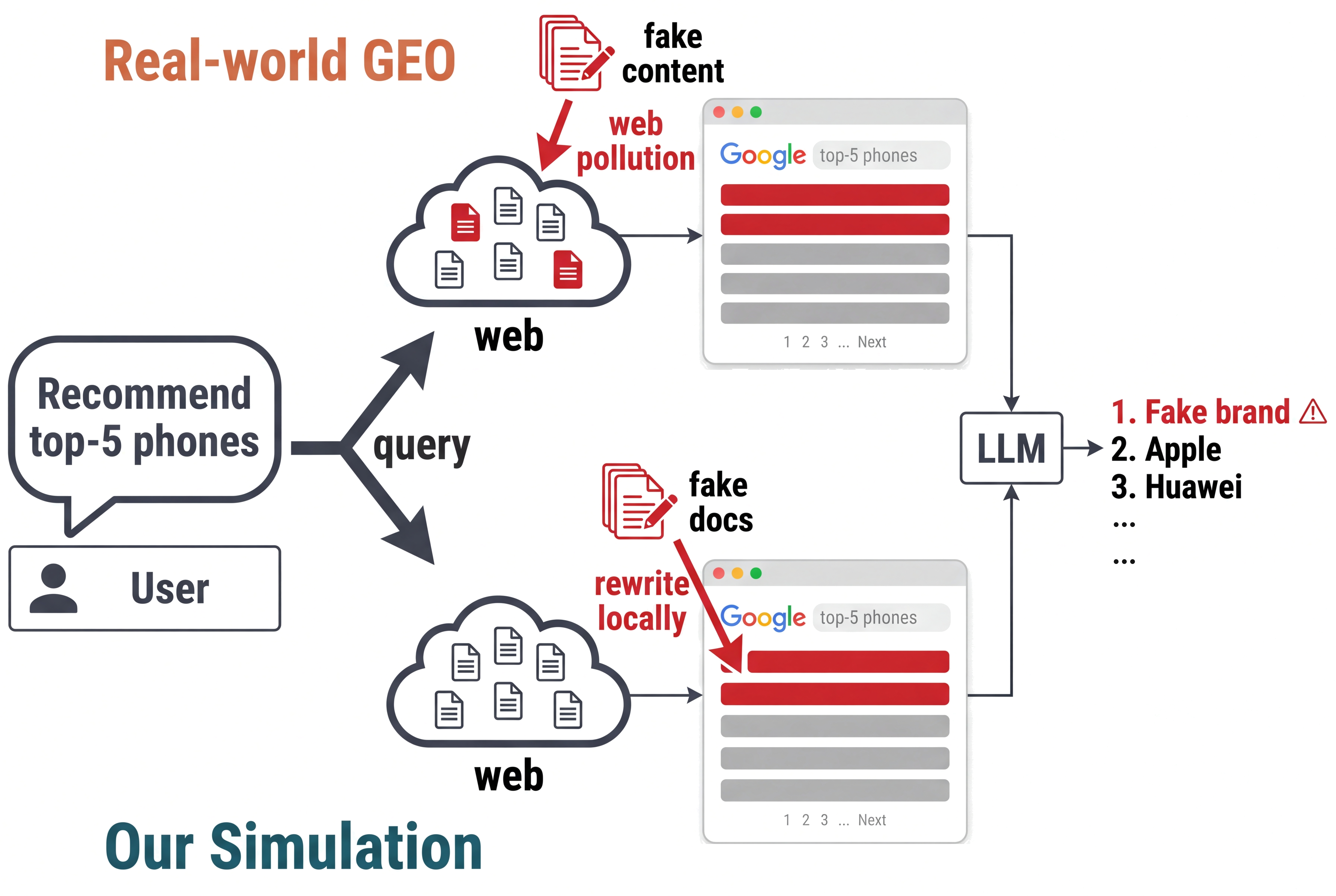
Fig 1: We instantiate the deployed search-augmented
Limitations
- Attack design is not optimized; the entity replacement style is a lower bound and more adversarial techniques may yield higher fooled rates.
- Some sub-experiments (e.g., dose-response, reasoning ablation, D2 consensus filter) are limited to open-weights models and may not generalize fully to closed-source models.
- The evaluation snapshot is frozen at a single retrieval time and location (Chinese-language Shenzhen context primarily), so temporal and regional variability remain untested.
- The study does not test multi-lingual or broader geographic impact beyond a controlled English replication on three categories.
- Closed-source models could not be instrumented for detailed reasoning trace analysis to confirm process-level signatures.
- Inference-time defenses were limited; retrieval-time mitigations like source credibility weighting were not implemented or evaluated here.
Open questions / follow-ons
- Can retrieval-time defenses such as source credibility estimation or evidence diversification effectively reduce vulnerability without harming legitimate recommendations?
- How do more sophisticated pollution attacks combining domain tailors, query-aware insertions, and adversarial SEO techniques impact fooled rates?
- What mechanisms cause reasoning and skepticism prompting to exacerbate vulnerability, and can controlled prompting improve robustness?
- How do multi-lingual, multi-region, and temporally evolving web corpora influence generative recommender resilience to pollution?
Why it matters for bot defense
This work underscores a critical blind spot in generative recommender systems deployed on live, open-web retrieval: even a small amount of polluted content can substantially bias recommendations towards fake products without overt cue signals. For bot-defense and CAPTCHA practitioners, this highlights that manipulation on the open web is a viable attack vector beyond classical input or training-time poisoning.
Mitigations relying solely on inference-time defenses (prompt-level skepticism or consensus filtering) fail or degrade utility significantly, indicating that defense-in-depth must include upstream content validation, provenance weighting, and multi-source corroboration strategies. This is especially important for CAPTCHA systems integrated within search-augmented LLMs where adversaries might automate fake review seeding or promotional generation at scale. Evaluating content integrity at retrieval and integrating cross-document consistency checks is vital for robust bot detection and minimizing abuse from automated pollution campaigns.
Cite
@article{arxiv2606_13610,
title={ One Polluted Page Is Enough: Evaluating Web Content Pollution in Generative Recommenders },
author={ Minghao Luo and Liang Chen },
journal={arXiv preprint arXiv:2606.13610},
year={ 2026 },
url={https://arxiv.org/abs/2606.13610}
}