
Leveraging Audio-LLMs to Filter Speech-to-Speech Training Data
Source: arXiv:2606.13507 · Published 2026-06-11 · By Qixu Chen, Satoshi Nakamura
TL;DR
This paper addresses a foundational problem in end-to-end speech-to-speech translation (S2ST): large-scale mined paired speech corpora, while abundant, are noisy and misaligned, degrading model quality. The authors propose training an audio-language model (audio-LLM) to perform keep/drop decisions directly on paired speech audio, bypassing transcript-only heuristics that miss important acoustic fidelity and alignment issues. Key to this approach is a two-stage Rank→Distill training pipeline: first, a lightweight ranker trained on noisy/synthetic speech quality signals ranks the mined pairs to produce high-confidence pseudo-labels; second, an audio-LLM is fine-tuned on these pseudo-labeled data to predict filtering decisions directly from raw audio. The method combines acoustic, perceptual, and semantic signals to capture both fidelity and cross-lingual consistency. Experiments on the CVSS-C and SpeechMatrix corpora demonstrate consistent improvements in downstream S2ST BLEU scores compared to unfiltered training and various baselines, with gains as high as +1.4 ASR-BLEU. Ablations show both stages contribute meaningfully, and the audio-LLM filter outperforms large text-only LLM filters despite being only 8B parameters.
Key findings
- Using the proposed two-stage audio-LLM filtering approach yields 22.72 BLEU on CVSS-C+SpeechMatrix (French→English), improving +1.4 BLEU over unfiltered baseline (21.32 BLEU).
- The audio-LLM filter keeps approximately 477k pairs from the mined 614k SpeechMatrix subset, balancing data quality and quantity.
- Acoustic and perceptual quality filters alone (SNR, MOS thresholds) improve BLEU modestly (~21.15-21.46) and are sensitive to thresholds, indicating limited utility by themselves.
- Semantic filtering using large text LLMs (70B with LLaMA) achieves 22.42 BLEU but retains more data (577k pairs) than the audio-LLM approach, suggesting lower data efficiency.
- The lightweight ranker trained in Stage I alone achieves 21.91 BLEU at 477k pairs and 22.49 BLEU at 577k, outperforming many baselines but not surpassing full two-stage audio-LLM filtering.
- Ablations reveal that removing Stage I (no ranker) leaves filtering ineffective, keeping almost all data (~98%), confirming the importance of pseudo-labeling.
- Replacing the audio-LLM with Audio Flamingo 3 reduces BLEU to 21.53 due to model input constraints, highlighting architecture dependence.
- Generalization to German→English data also yields substantial +1.87 BLEU gain after filtering, confirming cross-lingual robustness.
Threat model
The adversary is the uncontrolled noise and misalignment inherent in large-scale mined speech-to-speech corpora which degrade model training quality. The adversary has no capability to strategically manipulate data (no adversarial attacks). The defense system assumes no manual labels and limited trusted supervision, aiming to filter out acoustic and semantic noise by automatically identifying reliable pairs via quality metrics and model inference.
Methodology — deep read
Threat Model and Assumptions: The adversary is not explicitly modeled as a malicious attacker; rather, the 'threat' is noisy, misaligned, or low-quality mined speech pairs in large-scale S2ST corpora. The assumption is that no manual labels exist for filtering, and model supervision must be derived automatically from quality signals combined with synthetic degradations. The system aims to filter out acoustic noise, semantic misalignment, and transcription mismatches to improve downstream S2ST model training.
Data: The main datasets are CVSS-C (French→English) providing clean, high-quality pairs with synthetic target speech and real source speech, and SpeechMatrix, a large mined multilingual speech-to-speech set with diverse noise and domain characteristics. The authors construct 15,902 high-confidence clean positive pairs from SpeechMatrix using strict thresholds on acoustic (SNR ≥35 dB), perceptual (MOS ≥2.0), and semantic signals (LLM adequacy ≥90 and BLEURT ≥0.8). Negative pairs are generated by applying controlled degradations such as acoustic noise, reverberation, cropping, reordering, and compression artifacts, in light, medium, and heavy presets with a 3:6:1 ratio. Additional mined hard negatives with acceptable acoustic quality but poor semantics are also included.
Architecture and Algorithms: The first stage uses a lightweight ranking model based on LambdaMART gradient-boosted decision trees implemented in LightGBM. Input features are composite quality metrics: SNR, MOS, LLM-based semantic adequacy, and BLEURT scores derived via ASR transcripts and MT outputs. The ranking objective is pairwise preference loss assuming clean pairs rank above noisy pairs. Top-K and bottom-K scored examples form pseudo-labeled keep/drop sets.
The second stage fine-tunes an audio large language model, specifically Qwen2-Audio (8B parameters) with 4-bit quantization and LoRA for efficient tuning. Input to the audio-LLM is paired raw source and target speech audios phrased as chat-style prompts with an instruction to predict keep or drop. The model is trained with causal language modeling loss for 2 epochs. This distillation step transfers the ranker’s weak, feature-level supervision into a unified audio-native classifier that jointly understands acoustic quality and cross-lingual semantic alignment directly from audio.
Training Regime: The ranker uses 300 trees, learning rate 0.05, max depth 6, and data splits of 80% train, 10% dev, and 10% test from the constructed pseudo-label set. The audio-LLM is fine-tuned with batch size 8, gradient accumulation 4, learning rate 2e-4, dropout 0.05, and LoRA rank 16 and alpha 32. Training uses 90% train and 10% dev split. Model training hardware involves 4x NVIDIA A100 GPUs for S2ST backbone training with 300k max updates, early stopping with patience 5.
Evaluation Protocol: Filtering methods are evaluated by training the Fairseq S2UT model (speech-to-unit translation) from scratch on filtered datasets and measuring ASR-BLEU on a fixed test set using a pretrained wav2vec 2.0 ASR. Baselines include random selection, acoustic-only filtering (SNR, MOS), semantic-only filtering (LLM, BLEURT, BLASER-QE), and the ranker stage alone. Ablations assess the impact of removing Stage I or II, subsets of quality signals, model choice (Audio Flamingo vs Qwen2-Audio), and language pairs (FR→EN and DE→EN).
Reproducibility: Ranker training data and augmentation configurations are to be released for reproducibility. Code for training and filtering uses publicly available frameworks (LightGBM, Fairseq). Qwen2-Audio and SpeechMatrix datasets are publicly known, though SpeechMatrix is large and mined which may vary per user. Specific seeds or hardware configs for deterministic runs are not detailed. The student model uses LoRA and 4-bit quantization for efficient fine-tuning.
Concrete Example: For instance, to generate pseudo-labels, clean SpeechMatrix pairs with SNR≥35, MOS≥2.0, LLM adequacy≥90, BLEURT≥0.8 are selected as positive. Noisy pairs are synthesized with acoustic noise or temporal perturbations. The LambdaMART ranker learns pairwise preferences to score unlabeled pairs. The top 15k and bottom 15k pairs become pseudo keep/drop labels. The audio-LLM is then fine-tuned on these samples with paired raw speech as input and an instruction prompt, directly predicting keep/drop. This filter is applied to the mined dataset before training the final S2ST model, leading to +1.4 BLEU gains on evaluation.
Technical innovations
- A two-stage Rank→Distill filtering framework that leverages a lightweight quality ranker to generate pseudo-labels for training an audio-LLM to predict keep/drop decisions directly from raw paired speech audio.
- Integration of multi-dimensional quality signals—acoustic fidelity (SNR), perceptual quality (MOS), and semantic alignment (LLM adequacy, BLEURT)—to bootstrap supervised filtering without manual labels.
- Application of instruction-following fine-tuning on paired raw audio inputs to train an audio-language model classifier for data filtering, bridging acoustic and semantic evaluation in a unified model.
- Demonstration that an 8B-parameter audio-LLM filter can outperform much larger (70B) text-only LLM-based filters in terms of translation quality under equal data retention budgets.
Datasets
- CVSS-C — ~207k pairs (FR→EN) — public high-quality synthetic target speech paired with real source speech
- SpeechMatrix — ~614k mined pairs (FR→EN subset used) — large-scale mined multilingual speech-to-speech corpus
Baselines vs proposed
- Unfiltered (CVSS-C + 20% SpeechMatrix): BLEU = 21.32 vs Audio-LLM filter: 22.72 (+1.4)
- SNR filtering (≥30 dB): BLEU = 21.46 vs Audio-LLM filter: 22.72
- MOS filtering (≥2.0): BLEU = 21.06 vs Audio-LLM filter: 22.72
- LLM filtering (LLaMA 70B ≥80): BLEU = 22.42 vs Audio-LLM filter: 22.72 (lower data retention)
- BLEURT filtering (≥0.7): BLEU = 21.94 vs Audio-LLM filter: 22.72
- Stage I ranker only (477k pairs): BLEU = 21.91 vs full pipeline: 22.72
- Stage I ranker only (577k pairs): BLEU = 22.49 vs Audio-LLM filter: 22.72
- Audio Flamingo 3 model: BLEU = 21.53 vs Qwen2-Audio: 22.72
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13507.
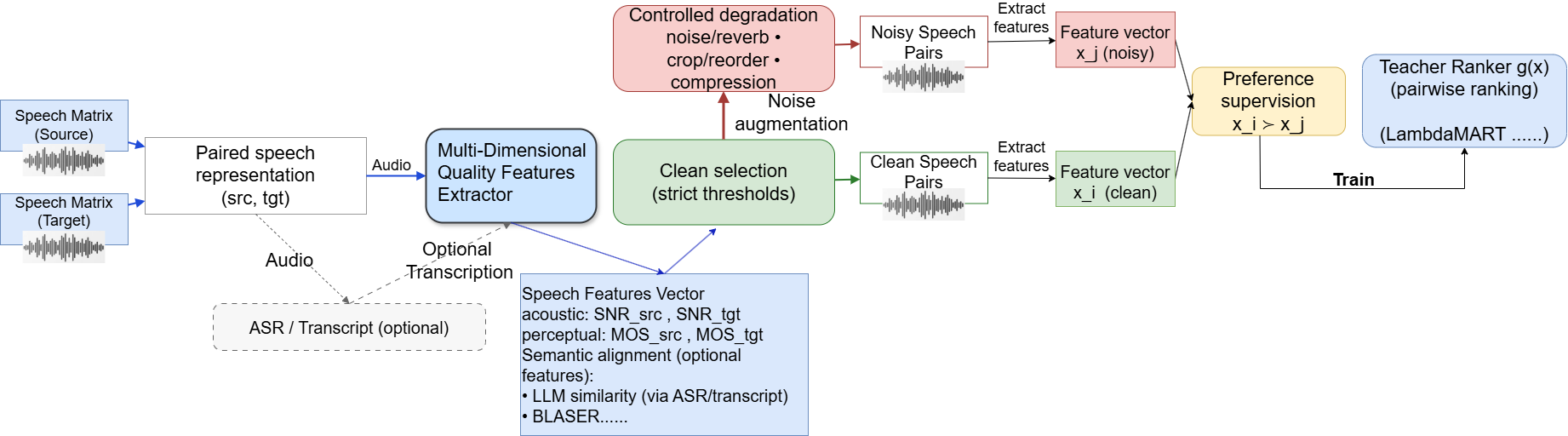
Fig 1: Construction of supervised training pairs and ranker training pipeline. Clean speech pairs are selected using strict thresholds
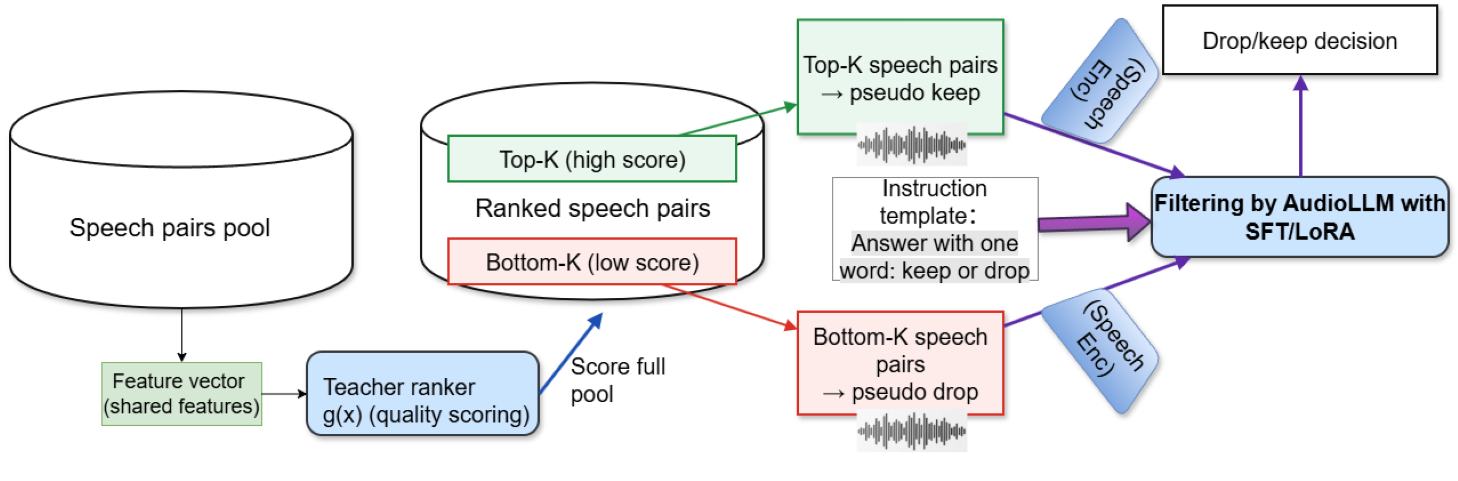
Fig 2: Overview of the proposed two-stage filtering framework. A lightweight ranker first scores the full speech pair pool and
Limitations
- Binary keep/drop classification limits flexible control over data retention size and quality tradeoffs; future work needed on probabilistic or budget-aware filtering.
- Pseudo-label supervision depends on heuristics and synthetic degradations, which may not capture all real noise or semantic mismatch patterns.
- Experiments mainly on French→English and some German→English; additional languages and domain evaluations are needed for wider applicability.
- Does not explore adversarial or malicious noise scenarios; robustness against crafted attacks on filtering is unknown.
- Ranker and audio-LLM models rely on multiple external pretrained components (LLMs, ASR, MT), which increase system complexity and may propagate errors.
- Reproducibility depends on access to large-scale mined datasets and models like Qwen2-Audio, which may not be fully open or easy to reproduce.
Open questions / follow-ons
- Can the binary keep/drop decision be generalized to continuous or probabilistic quality scores allowing fine-grained, budget-aware filtering?
- How well does the audio-LLM filtering framework perform on other language pairs, domains, and extremely low-resource conditions?
- Can adversarial robustness or defense against intentional poisoning of mined speech data be integrated into this audio-native filtering approach?
- To what extent can end-to-end training of the audio-LLM jointly with downstream S2ST models improve filtering and translation quality compared to the current separated Rank→Distill pipeline?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners interested in voice or audio-based challenges can draw insights from this work’s audio-native evaluation approach for speech quality and semantic consistency. The two-stage Rank→Distill method demonstrates a scalable way to learn filtering or classification on paired speech data without costly manual labels, which could inform anti-fraud filters where genuine human audio responses must be distinguished from automated or manipulated inputs. Unlike text-only models, audio-language models conditioned on raw audio better capture acoustic characteristics relevant for bot detection in voice CAPTCHAs or anti-spoofing. However, the filtering approach is currently specialized for translation data quality rather than adversarial attack detection. Therefore, adapting similar audio-LLM classifiers with appropriate threat models and training data could enhance voice bot-defense systems by jointly assessing acoustic fidelity and semantic congruence of voice interactions.
Cite
@article{arxiv2606_13507,
title={ Leveraging Audio-LLMs to Filter Speech-to-Speech Training Data },
author={ Qixu Chen and Satoshi Nakamura },
journal={arXiv preprint arXiv:2606.13507},
year={ 2026 },
url={https://arxiv.org/abs/2606.13507}
}