
Influcoder: Distilling Decoders' Gradient Influence Rankings into an Encoder for Data Attribution
Source: arXiv:2606.13668 · Published 2026-06-11 · By Dimitri Kachler, Damien Sileo, Pascal Denis
TL;DR
Influcoder addresses the computational inefficiencies of influence function-based Data Attribution (DA) methods for large language models (LLMs). Traditional influence function approaches estimate the impact of individual training samples on model outputs but are costly and slow, limiting practical use on large datasets. Influcoder proposes to distill influence rankings derived from LoRA-adapter gradients of a target decoder model into a dedicated encoder model. This encoder then quickly predicts influence rankings at inference time, achieving massive speedups and reduced storage while maintaining competitive accuracy.
The key novelty is treating influence estimation as a ranking distillation problem where ground truth cosine similarities between LoRA gradient embeddings of pool and query samples are computed offline and used as supervision to train the encoder. Empirically, Influcoder matches or nearly matches the ranking quality of more expensive methods like LESS but with up to 100x faster inference time and 10x smaller storage. It is also effective for toxicity filtering downstream, achieving strong attribution-based toxic example retrieval in seconds versus thousands of seconds for baselines. This work provides a promising scalable path for influence-based data attribution at LLM scale by shifting costly gradient computations offline and trading them for efficient embedding similarity during online use.
Key findings
- Influcoder (68m parameters) achieves 15x faster inference than closest proxy model and 45x faster than full LoGRA (rank=16), with 100x speedup over LESS while using 30 MB of storage vs 320 MB for LESS (Table 1).
- Influcoder matches or outperforms all baselines except LESS on mean per-anchor and mean aggregated Spearman correlation for influence rankings (Fig. 2).
- On toxicity filtering (XSTest-response task), Influcoder reaches AUPRC ~0.698 (heterogeneous) and ~0.692 (homogeneous) vs LESS ~0.707 and ~0.756, but inference takes 32s instead of ~2248s (Table 2).
- Semantic similarity-based baselines perform poorly (AUPRC 0.35) compared to gradient-based influence methods illustrating the utility of gradient-informed data attribution.
- Training Influcoder requires only ~0.73 hours to process 10K Dolly samples on SmolLM2-360m model, faster than LoGRA processing time (Table 1).
- Random projection of gradients with a dimension of 65,536 preserves influence ranking correlations with dense gradients over 0.97 Spearman (Appendix A.1).
- DataInf baseline performs substantially worse on toxicity filtering in these experiments, with AUPRC near 0.22 despite tuning attempts (Table 2 & Appendix A.5).
- The inclusion of Fisher Information Matrix (FIM) improves LoGRA performance considerably, highlighting the benefit of curvature-aware influence methods.
Threat model
Adversaries are those interested in tracing back model outputs to specific training samples (e.g., to identify toxic data responsible for harmful behavior). They can access query samples and the trained model parameters but cannot directly observe or modify the target model's internal gradients on all training data; influence estimation must be efficient and scalable to large datasets.
Methodology — deep read
The paper's methodology unfolds through several detailed steps:
Threat Model & Assumptions: The adversary model is implicit in the DA context—potentially LLM trainers or auditors seeking to identify training data impact on specific outputs such as toxic generations. Influcoder assumes access only to pooled training examples and query samples, focusing on influence estimation using gradients from LoRA adapters in a target decoder model without incorporating inverse Hessian curvature to avoid instability.
Data: The experiments use Dolly-15K as the training pool set and BBH as the query set for influence ranking estimation. For toxicity filtering, an 8K subset of UltraChat is used with 66 toxic examples. The datasets are carefully split to prevent leakage, e.g. unseen queries sourced separately. Gradient projections are computed from response-only LoRA adapter gradients with prompt masked.
Architecture / Algorithm: Influcoder introduces an encoder model (from the ettin-encoder suite with versions of 68m and 150m parameters) that inputs raw text samples and outputs low-dimensional influence embeddings (768 dimensions). Ground truth influence labels are first computed by passing pool and query samples through the target decoder model producing LoRA gradients, then applying CountSketch random projection for dimensionality reduction, followed by cosine similarity to generate influence rankings. The encoder is trained to replicate these cosine similarity influence rankings by minimizing a combined loss of batch-wise Pearson correlation and softmax KL divergence to encourage matching the ranking distributions.
Training Regime: The training is done on NVIDIA H100 GPUs for influence ranking and A100 GPUs for toxicity filtering, with batch sizes of 12 and 4 respectively, learning rates between 1e-5 and 5e-5, weight decay 0.01, and 10-20 epochs depending on task. For each batch, samples of pool and query are passed through the encoder to get embeddings, cosine similarity is taken, and losses computed against pre-stored ground truth influence scores from the target decoder. Seeds are fixed to ensure reproducibility.
Evaluation Protocol: Influence ranking quality is measured by mean aggregated and per-anchor Spearman rank correlations between ground truth and method rankings over 200 pool and 200 query samples. Efficiency is measured by GPU inference wall-clock time and FLOPs. Ablations include varying encoder sizes and comparison to untrained semantic, TF-IDF, RDS+, LESS, LoGRA with/without FIM, and DataInf baselines. The toxicity task is evaluated by AUPRC for retrieving toxic data points. Experiments are run with 3 different seed splits and averaged.
Reproducibility: While precise code release details are not stated, architectures come from external open-source ettin-encoder models and the datasets used are partially public (Dolly, BBH, UltraChat). The paper provides extensive appendix details on hyperparameters, projection dimensions, and training/time details to allow reproduction where data access permits.
Concrete Example End-to-End: For example, to evaluate influence on smolLLM2-1.7B, they first collect LoRA gradient vectors for each pool and query sample, reduce dimensionality using CountSketch to 65k dimensions, compute pairwise cosine similarities forming ground truth influence matrices. These similarity matrices serve as label supervision to train the encoder to produce influence embeddings whose cosine similarities match these rankings. After training for 10 epochs on 2k pool and 1k query samples, the Influcoder encoder can rapidly produce influence scores for unseen queries without recomputing gradients, vastly reducing computation time from hours to minutes or seconds.
Technical innovations
- Distillation of influence rankings from expensive LoRA gradient computations into a compact encoder producing influence embeddings for fast inference.
- Using a combined differentiable ranking loss combining batch-wise Pearson correlation with per-query softmax KL divergence to directly optimize influence ranking predictions.
- Application of CountSketch random projection on LoRA adapter gradients to reduce storage while faithfully preserving influence ranking correlations.
- Restricting influence computations to response-only LoRA gradients (prompt masked) and excluding LM head/vocab embeddings to reduce noise in the influence signal.
Datasets
- Dolly — ~15,000 samples — open-source instruction-tuning dataset
- BBH (Big Bench Hard) — evaluation benchmark of challenging queries — public
- UltraChat subset — 8,000 samples with toxic example labels — source detailed in Appendix A.4
Baselines vs proposed
- LESS (dim=8192): Spearman per-anchor = higher than Influcoder by a small margin; Inference time = ~2248s vs Influcoder 32s
- LoGRA (rank=16): Inference time ≈ 0.85h vs Influcoder ≈ 0.02h processing 10K samples (Table 1)
- DataInf: AUPRC ≈ 0.216 (heterogeneous), significantly lower than Influcoder 0.698 (Table 2)
- Semantic similarity baseline: AUPRC ≈ 0.35, substantially lower than gradient-based methods
- Influcoder (68m): FLOPs usage 5x less than nearest proxy, 44x less than LESS (Fig 2)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13668.
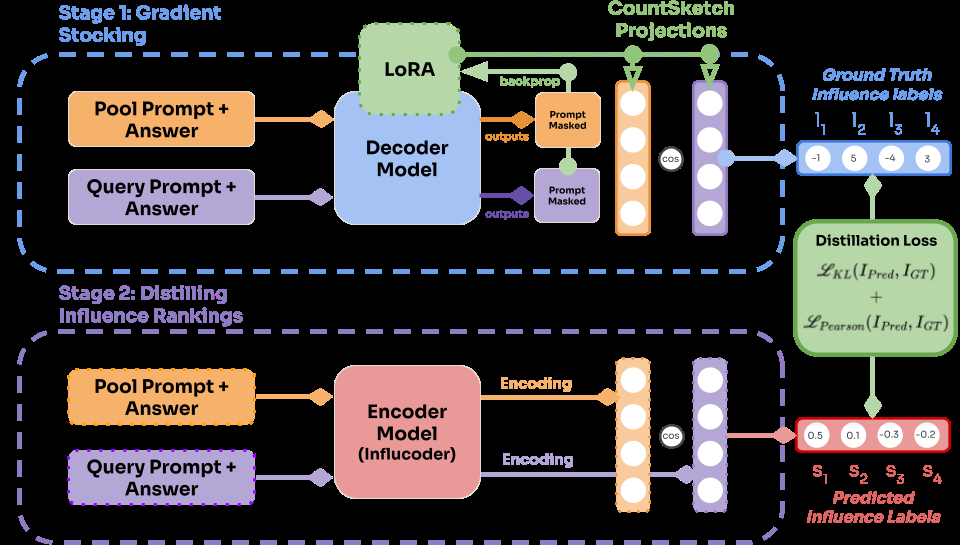
Fig 1: Schema for the training pipeline of the Influcoder. Stage 1: full pool and query samples are passed to the
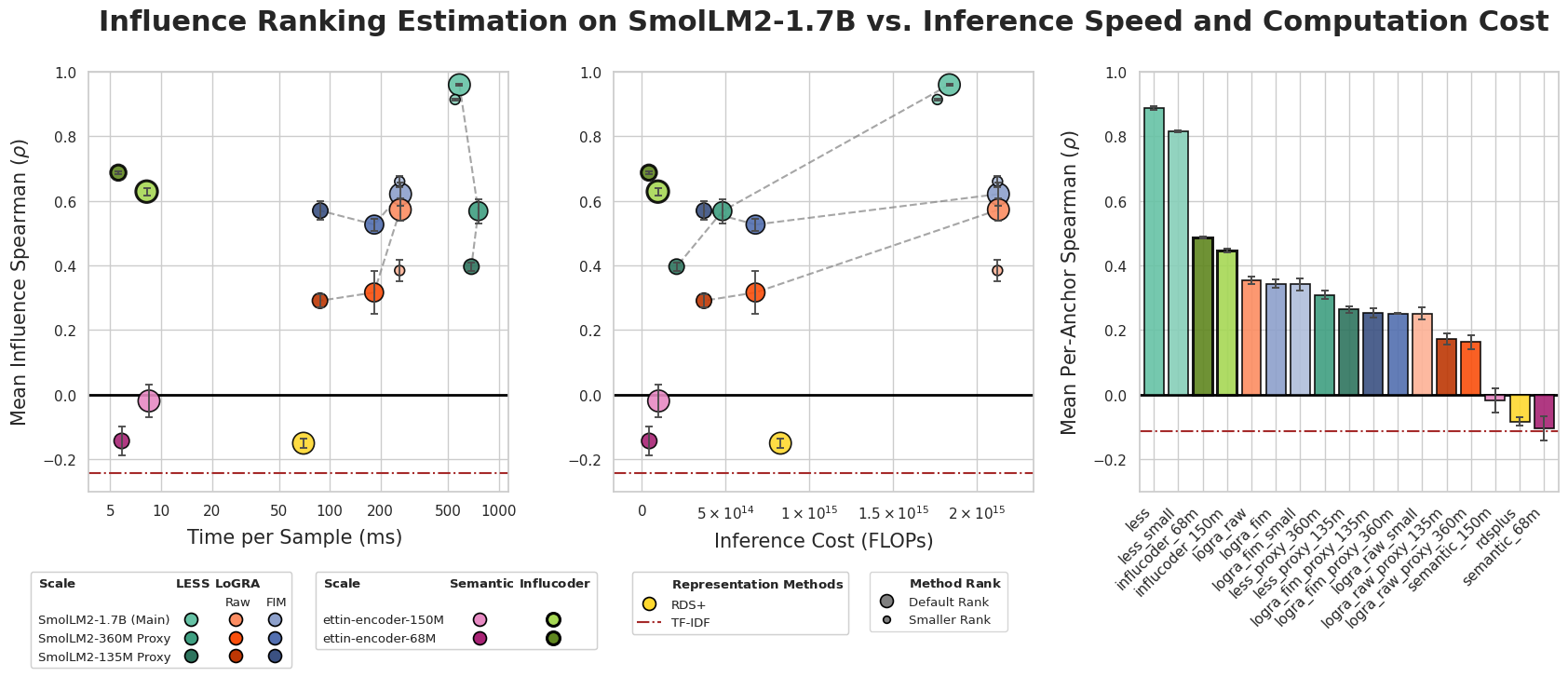
Fig 2: We evaluate influence estimation from Dolly to BBH samples using SmolLM2-1.7B as the target model.
Limitations
- Influence embeddings are trained and perform well only on the training distribution of pool and query samples; performance degrades outside that data domain.
- Requires nontrivial initial setup and offline training with gradient storage and projection, affecting plug-and-play usability compared to direct influence function baselines.
- Needs sufficient training data to properly distill influence relationships, making it less practical for very small datasets or rare domains.
- Excludes Hessian/inverse curvature information by relying on first-order gradient cosine similarities; may miss subtleties captured by second-order influence methods.
- The approach currently focuses on response-only gradients and LoRA adapters, which may omit some contributions from other model parameters.
- Direct comparison with some related distillation methods like IProX is complicated due to differences in gradient space (full versus LoRA).
Open questions / follow-ons
- Can Influcoder embeddings generalize influence estimation across multiple target models or data distributions beyond training time?
- How can second-order information, e.g. inverse Hessian, be stably integrated into the distillation to improve accuracy without sacrificing efficiency?
- What are the tradeoffs in influence ranking quality versus embedding dimension and encoder size, and can more compact yet effective embeddings be found?
- Could fast approximate nearest neighbor search on Influcoder’s compact embeddings be leveraged for scalable interactive influence querying or adversarial data detection?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners interested in data provenance and model behavior auditing, Influcoder offers a scalable approach to estimate which training data points influence specific model outputs efficiently. While traditional influence methods are often prohibitively expensive for large datasets, Influcoder’s distillation into a fast encoder enables practical real-time or near-real-time influence queries, facilitating fine-grained data filtering or toxic content mitigation.
Since bot detection increasingly relies on understanding model failure modes and data origins, Influcoder’s speed and compact storage are appealing tradeoffs. However, its dependency on training distribution alignment suggests careful dataset curation for robustness is needed. Moreover, the conceptual approach of distilling gradient influence into embeddings could inspire future embedding-centric mechanisms for bot interaction attribution or model output justification in CAPTCHA scenarios.
Cite
@article{arxiv2606_13668,
title={ Influcoder: Distilling Decoders' Gradient Influence Rankings into an Encoder for Data Attribution },
author={ Dimitri Kachler and Damien Sileo and Pascal Denis },
journal={arXiv preprint arXiv:2606.13668},
year={ 2026 },
url={https://arxiv.org/abs/2606.13668}
}