
EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Source: arXiv:2606.13681 · Published 2026-06-11 · By Jundong Xu, Qingchuan Li, Jiaying Wu, Yihuai Lan, Shuyue Stella Li, Huichi Zhou et al.
TL;DR
This paper addresses a significant gap in the evaluation and deployment of large language model (LLM) agents, which traditionally assume static environments, whereas real-world settings are dynamic with persistent environmental changes. The authors introduce EvoArena, a benchmark suite modeling environment evolution across terminal workflows, software engineering projects, and social/preference domains as chains of progressive changes. To cope with evolving environments, they propose EvoMem, a novel patch-based memory system that records memory evolution as structured update histories with rationales and evidence. This enables agents to track, reason about, and adapt to environment version changes rather than collapsing memory into a single latest state. Experimental evaluation reveals existing LLM agents struggle on EvoArena, achieving only 39.6% average accuracy and much lower chain-level accuracy. Integrating EvoMem consistently improves step-level accuracy by 1.5%, chain-level accuracy by 3.7%, and boosts performance on other benchmarks by 4.8-6.1%. Mechanistic analyses confirm EvoMem enhances evidence capture and retention of evolving states, illustrating the importance of reasoning over memory evolution for robustness in dynamic real-world deployments. The work thus provides a carefully designed empirical framework, a new memory paradigm, and foundational insights for reliable long-horizon agent performance under environment drift.
Key findings
- Current LLM agents obtain only 39.6% average accuracy on EvoArena across terminal, software, and social preference evolution domains.
- Step-level accuracy is substantially higher (e.g., GPT5.5 achieves ~50.8%) than chain-level accuracy (range ~19.2%-29.2%), indicating difficulty in sustained sequential adaptation over environment evolution.
- EvoMem patch-based memory consistently improves average step accuracy on EvoArena by 1.5% over baseline memory designs.
- EvoMem also enhances performance on standard benchmarks: GAIA improves by 6.1% and LoCoMo by 4.8% when integrating EvoMem memory.
- Chain-level accuracy on EvoArena improves by 3.7% with EvoMem, supporting agents in completing multi-step evolved subtask sequences.
- On PersonaMem-Evo (preference domain), EvoMem yields stronger gains on temporal trajectory and multi-pattern synthesis questions that require tracking dispersed evolving preferences.
- EvoMem leads to better row-level evidence capture in memory, preserving complete states and update rationales essential for robust reasoning.
- Terminal-Bench-Evo includes 352 evolved versions from 89 tasks, with version chains averaging ~5 steps and diverse evolution categories such as I/O changes and policy updates.
Threat model
The adversary corresponds to the dynamic environment itself, which evolves persistently over time without explicit notification to the agent. The agent must infer changes from observations and maintain robust behavior under incremental environment drift. The adversary cannot arbitrarily spoof or remove evidence but can change interfaces, rules, dependencies, and preferences in ways that may conflict or override previous states. No active attacker or misinformation-based adversary is assumed.
Methodology — deep read
The paper focuses on robust agent behavior under persistent environment evolution where interfaces, rules, codebases, and preferences change progressively over time.
Threat model and assumptions: The adversary is effectively the dynamic environment itself, continuously evolving operational constraints and knowledge required by deployed agents. Agents must adapt to incremental changes while preserving still-valid prior behaviors. Agents have access only to episodic observations and memory; they do not have oracle knowledge of environment changes.
Data Provenance and construction: EvoArena is composed of three domain benchmarks representing major real-world dynamic environment regimes:
- Terminal-Bench-Evo: 89 original terminal workflow tasks extended into 352 versioned evolved tasks in chains averaging 5 versions, created by systematically introducing file, environment, CLI/API, dependency, and policy changes while preserving the core task.
- SWE-Chain-Evo: 50 chains from 12 real GitHub repositories, each chain composed of 5-15 milestone commits grouped into logical development objectives, spanning Go and Python project snapshots. Each milestone is testable with fail-to-pass and pass-to-pass tests constructed.
- PersonaMem-Evo: Evolving user preferences represented as long multi-turn conversations built on PersonaMem-v2, with structured persona profiles, cleaned preference inventories, and temporal evolution annotations. Tasks are multiple-choice questions requiring preference inference across evolving state trajectories.
- Agent architecture and EvoMem memory: Baseline agents use standard episodic or retrieved memory representations typically consolidating into a single latest state. EvoMem introduces a git-like patch-based memory system where memory updates are recorded as append-only patches. Each patch stores pre- and post-update memory state snapshots, textual rationale for the update, and supporting evidence from interaction context, enabling traceable environmental memory evolution.
At inference, agents retrieve the latest memory by default but selectively consult relevant patches to reconstruct earlier states if prior environment versions or overwritten information are pertinent to the query. This avoids state collapse seen in naive memory consolidation.
Training regime: While the paper does not specify training from scratch, it applies EvoMem to several backbone LLM agent architectures (Gemma4-31B, GPT5.5, GLM-5.1, MiniMax-M2.7, etc.) by integrating EvoMem memory as part of episodic state management during multi-step evaluation episodes across the benchmark tasks. Hyperparameter details are not explicitly described, but evaluation is zero-shot or few-shot.
Evaluation: Two main metrics assess agent performance: step accuracy (accuracy on solving individual evolved task steps) and chain accuracy (fraction of consecutive steps in an evolution chain solved before failure). Baselines include standard memory agents without EvoMem. Evaluation slices compare performance per domain (terminal, software, social), question types, and evolutionary update categories. Chain-length analyses examine sustained reliability. Additional tests measure evidence capture quality in memory via row-level recall metrics. Statistical tests and oracle reference solutions validate environment executability and task solvability.
Reproducibility: Code for EvoArena and EvoMem is publicly released at https://github.com/Aiden0526/EvoArena, and the dataset is available via HuggingFace. The benchmark environment uses Docker containers to guarantee execution consistency. Reference solutions and tests are provided for oracle validation.
Example walkthrough: In Terminal-Bench-Evo, a fixed terminal workflow goal (e.g., deploy static web files) evolves across 4-5 versions introducing changes to deployment mechanisms, file paths, permissions, and branch policies. The agent sees the task instruction, current container/workspace snapshot, and must adapt commands accordingly. EvoMem tracks memory patches representing each environment version's changes, enabling the agent to refactor its workspace and commands according to the latest context while preserving prior rationale for fallback or compatibility reasoning. Agent accuracy is evaluated by passing version-specific test suites executing commands within containers.
Technical innovations
- EvoArena benchmark suite models persistent environment evolution as chains of progressively changing environment versions across terminal workflows, software repos, and social preference domains.
- EvoMem patch-based memory paradigm records an append-only history of memory states with textual rationales and evidence, enabling agents to track and reason over evolving environment states rather than collapsing memory into a single state.
- The cleaning and grouping of commits into milestone objectives and assembling them into evolution chains in SWE-Chain-Evo provide a novel, realistic evaluation of agent adaptation to evolving software repositories.
- Integration of temporal preference evolution into PersonaMem-Evo adds an explicit environment versioning dimension to preference inference benchmark scenarios, requiring agents to infer current preferences over evolving multi-turn conversation histories.
Datasets
- Terminal-Bench-Evo — 352 evolved versioned tasks grouped into ~70 chains from 89 base terminal workflow tasks — constructed from open terminal benchmarks with added evolution design
- SWE-Chain-Evo — 493 total chain-step instances from 50 evolution chains covering 145 unique milestones from 12 diverse GitHub repositories — public codebases with curated commit windows
- PersonaMem-Evo — Multi-turn conversational datasets with evolving preferences spanning thousands of turns and multiple user personas — extends PersonaMem-v2 datasets with temporal evolution annotations
Baselines vs proposed
- Baseline agent average accuracy on EvoArena: 39.6%; with EvoMem: 41.1% (step-level improvement +1.5%)
- Chain-level accuracy on EvoArena baseline: range ~19.2% to 29.2% across eight backbone LLMs; with EvoMem: improved by 3.7% on average
- On GAIA benchmark, baseline: X% (not specified exact); with EvoMem: +6.1% improvement
- On LoCoMo benchmark, baseline: X% (not specified exact); with EvoMem: +4.8% improvement
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13681.

Fig 1: Step accuracy vs. chain accuracy on EvoArena. The closer to the upper-right corner the better.
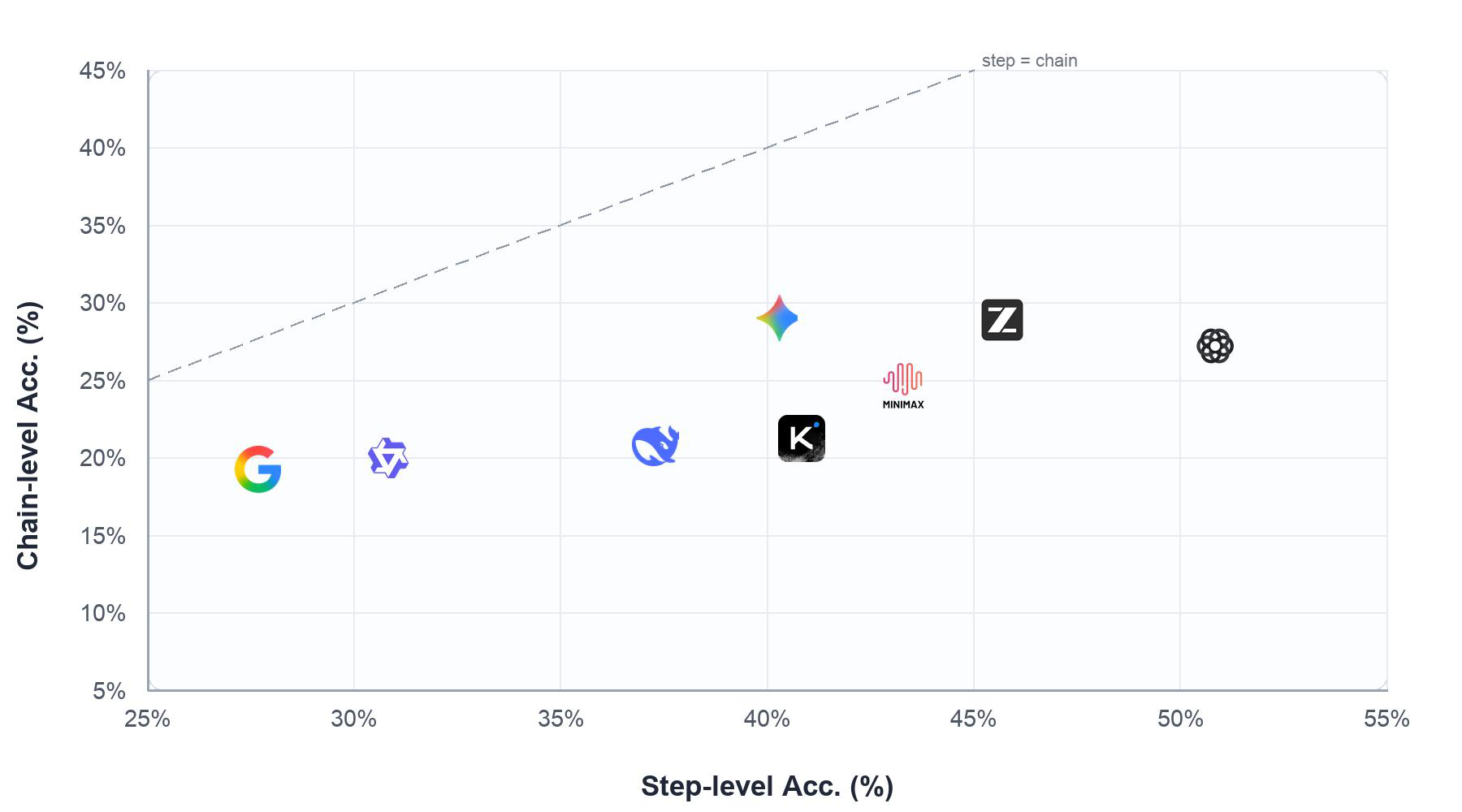
Fig 2 (page 1).
Fig 2: EvoArena construction. We convert static agent benchmarks into versioned evolution chains across
Fig 4: An example of Terminal-Bench-Evo. The end goal stays fixed: push hello.html and serve it
Fig 5: Example evolution chain in SWE-Chain-Evo. The aiohttp chain evolves across four milestones,

Fig 6 (page 6).

Fig 7 (page 6).

Fig 8 (page 6).
Limitations
- Relatively modest absolute accuracy gains with EvoMem (1.5% step and 3.7% chain-level) suggest that environment evolution remains a very challenging setting.
- Evaluation lacks strong adversarial environment changes or malicious perturbations; focuses on realistic but benign evolution.
- Training and fine-tuning strategies for EvoMem-augmented agents are not detailed; results mainly evaluate zero-shot or few-shot adaptation.
- Chains have limited maximum lengths (up to 15 steps), leaving longer-horizon adaptation untested.
- Memory retrieval and patch selection methods rely on heuristic relevance; scalability to large histories or very frequent updates remains unclear.
- Detailed hyperparameter tuning, ablations on patch contents, and robustness under distribution shifts are not fully explored.
Open questions / follow-ons
- How can agents scale EvoMem to long, complex environment histories with many overlapping or conflicting patches?
- Can learning-based approaches improve patch relevance retrieval and memory update reasoning for more efficient adaptation?
- How does EvoMem interact with agent reflection or skill accumulation strategies in self-improving LLM agents?
- What are the limits of persistent memory evolution in non-benign or adversarially changing environments?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, EvoArena and EvoMem highlight the importance of evaluating agent robustness in environments that evolve persistently rather than assuming static challenge conditions. Captcha systems often update protocols, interfaces, and detection heuristics over time to thwart automation. Agents incorporating version-aware memory management like EvoMem can better adapt to changing verification logic or user interaction patterns, potentially increasing their persistence and evasion capabilities.
Thus, bot-defense practitioners should consider dynamic environment evolution effects when designing CAPTCHA challenges and detection pipelines. Modeling challenge evolution as stateful version chains and testing automation agents under chain-level success metrics can reveal vulnerabilities hidden in static snapshot evaluations. Additionally, exploring patch-based memory tracking could inform defenses by understanding how persistent bots store and adapt to evolving challenge versions.
Cite
@article{arxiv2606_13681,
title={ EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments },
author={ Jundong Xu and Qingchuan Li and Jiaying Wu and Yihuai Lan and Shuyue Stella Li and Huichi Zhou and Bowen Jiang and Lei Wang and Jun Wang and Anh Tuan Luu and Caiming Xiong and Hae Won Park and Bryan Hooi and Zhiyuan Hu },
journal={arXiv preprint arXiv:2606.13681},
year={ 2026 },
url={https://arxiv.org/abs/2606.13681}
}