
EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
Source: arXiv:2606.13662 · Published 2026-06-11 · By Amy Xin, Jiening Siow, Junjie Wang, Zijun Yao, Fanjin Zhang, Jian Song et al.
TL;DR
This paper addresses the challenge of autonomous scientific discovery by shifting focus from prescribing rigid agent workflows to engineering rich, reliable environments in which large language model (LLM)-based agents operate. The authors argue that as LLM capabilities grow, the bottleneck is no longer agent design but the environment's affordances—including resources, constraints, and interfaces—that encourage productive research behaviors and suppress failure modes like reward hacking and contamination. To this end, they present EurekAgent, a system that orchestrates off-the-shelf CLI agents within a carefully engineered environment emphasizing permissions, artifact management, budget constraints, and human oversight. EurekAgent significantly outperforms prior approaches in metrics-driven scientific tasks across mathematics, kernel engineering, and machine learning, notably achieving state-of-the-art 26-circle packing results with under $11 in API cost, showcasing the power of environment-level design for reliable, efficient autonomous research.
Key findings
- EurekAgent outperforms previous best AI results on three mathematical optimization problems: Circle packing (score 2.635999 vs 2.635986), Erdös minimum overlap (0.380870 vs 0.380876), and 1st autocorrelation inequality (1.502861 vs 1.502863), remaining training-free compared to prior test-time training methods.
- In kernel engineering (TriMul benchmark on A100 GPU), EurekAgent’s top solution achieves median runtime 2005.03µs vs previous best leaderboard solution at 2096.04µs, a 4.3% improvement, and surpasses the previous best test-time training method by 10.8%.
- On a curated 7-task subset of MLE-Bench Lite machine learning competitions, EurekAgent reaches 85.71% any-medal rate and 71.43% gold-medal rate, outperforming strong commercial-model baselines while using an open-source LLM (GLM-5.1).
- EurekAgent completes the 26-circle packing task at a fraction of the API cost ($11) compared to typical large-scale exploratory runs, demonstrating budget-aware exploration and efficient agent-resource coordination.
- The system’s permissions engineering prevents agents from tampering with evaluator code or manipulating results by sandboxing runs in Docker containers with isolated evaluation services and enforcing same-round isolation.
- The artifact engineering design uses Git-tracked shared filesystems for reproducibility, traceability, and cross-session communication among agent sessions, supporting long-term memory across research iterations.
- Budget engineering actively tracks and constrains API token usage and wall-clock time per stage with warning injections, enabling controlled exploration and graceful run suspension/resumption.
- Human-in-the-loop engineering provides web and terminal UI monitoring, live progress inspection, and interactive communication channels allowing seamless human supervision and intervention.
Threat model
The adversary is an autonomous research agent acting freely to optimize a given scientific metric by proposing and implementing solutions within a controlled computing environment. The agent has access to task inputs, previous round artifacts, web search, and limited sandboxed computing resources but cannot directly access or modify the hidden evaluation code, peer same-round implementation sessions, or system-owned files. Resource budgets and permissions serve as constraints to prevent reward hacking, evaluator tampering, and unbounded resource usage.
Methodology — deep read
The authors' threat model assumes an autonomous research agent acting to optimize a scientific metric via iterative proposal and implementation of solutions, without the ability to directly access or manipulate hidden evaluators or other agents' in-progress solutions within the same round. Adversarial rewards or contamination are addressed through environment-level constraints rather than adversarial black-box tests.
The experimental data spans three domains: mathematics (three classical optimizable tasks including 26-circle packing), kernel engineering (TriMul GPU matrix multiplication benchmark), and machine learning (7 selected Kaggle-style competitions drawn from MLE-Bench Lite). Labels are derived from objective evaluators run on submitted candidate solutions for final scoring. Evaluation protocols use hidden evaluators to forbid direct interference.
Architecturally, EurekAgent employs off-the-shelf CLI LLM agents (notably Claude Code) and GLM-5.1 as the base large language model, orchestrated by a four-dimensional environment engineering framework: permission engineering (Docker sandboxing, isolated evaluation with hidden graders, session-level resource gating), artifact engineering (shared Git-tracked filesystems for hypotheses, code, and logs), budget engineering (wall-clock and API token tracking with time warnings and stop signals), and human-in-the-loop interfaces (web and terminal UIs for monitoring and interaction).
The core iterative process divides into three stages each cycle: PREPARE (one-time initialization and consistency checks with human-in-the-loop fallback), PROPOSE (single session generates up to P hypotheses using past results, web search, and literature), and IMPLEMENT (P parallel independent sessions further develop, test, and submit solution candidates, each isolated to prevent same-round copying). This loop proceeds for up to R rounds or until budgets are exhausted.
Training is not applied—agents act through zero-shot prompting with tool APIs. Hyperparameters include number of rounds (R), parallelism (P), stage time budgets, and API cost caps. Experiments run on GPUs (A100) and cloud API infrastructure.
Evaluation uses exact metrics per domain: sum of radii for circle packing, maximum overlap for Erdös problem, runtime averages for TriMul kernel, and medal scoring on MLE-Bench. Multiple baselines comprise prior published AI and human results, and top leaderboard solutions re-evaluated under identical local protocols.
Reproducibility is supported through open-sourced code, detailed artifact logs with Git-tracked changes, and full session transcripts accessible in the web UI. Some datasets and leaderboards are public, others (e.g. proprietary GPUMODE leaderboard) require local adaptation. Overall, the methodology exemplifies robust environment-level controls and empirical evaluation over multiple domains with concrete quantitative improvements.
A concrete example is the 26-circle packing task: the prepare stage sets up runtime and evaluator access; propose generates hypotheses by inspecting prior-best solutions and web data; implement launches three isolated parallel sessions, each searching solution variants, submitting candidates to the hidden evaluator; finally, results are ranked and shared as historical context for the next round. This iterative loop leads to new state-of-the-art sum of radii (2.635999) at low API cost ($11).
Technical innovations
- Framing autonomous scientific discovery as an environment engineering problem emphasizing shaping agent affordances rather than prescribing agent workflows.
- Implementation of four concrete environment engineering dimensions—permissions, artifact, budget, and human-in-the-loop engineering—to enable reliable, open-ended, and budget-aware agent exploration.
- Isolation of parallel implementation sessions with shared artifact memory but hidden same-round peers to prevent premature convergence or solution contamination.
- Use of Git-tracked shared filesystem as a persistent, traceable progress memory for distributed multi-agent scientific discovery sessions.
- Active and passive budget enforcement mechanisms, including a time-checking API and injected warnings, facilitating controlled exploration and possible run resumption.
Datasets
- Mathematical optimization problems (circle packing, Erdös minimum overlap, 1st autocorrelation inequality) — small benchmark tasks with known evaluators — public from prior AI literature
- TriMul kernel engineering benchmark — runtime tests with A100 GPU — public but original leaderboard closed, evaluated locally
- MLE-Bench Lite subset — 7 Kaggle-style ML competitions — public leaderboard-based dataset subset
Baselines vs proposed
- Previous best AI on circle packing: score = 2.635986 vs EurekAgent: 2.635999
- Previous best AI on Erdös minimum overlap: score = 0.380876 vs EurekAgent: 0.380870
- Previous best AI on 1st autocorr. inequality: score = 1.502863 vs EurekAgent: 1.502861
- Top GPUMODE leaderboard TriMul solution median runtime = 2096.04 µs vs EurekAgent best = 2005.03 µs
- TTT-Discover baseline TriMul median runtime = 2247.78 µs vs EurekAgent best = 2005.03 µs
- MLE-Bench Lite subset any-medal rate: AIBuildAI 71.43% vs EurekAgent 85.71%
- MLE-Bench Lite subset gold-medal rate: Famou-Agent 65.39% vs EurekAgent 71.43%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13662.

Fig 1: EUREKAGENT score evolution progress on the 26-circle packing problem.

Fig 2 (page 1).
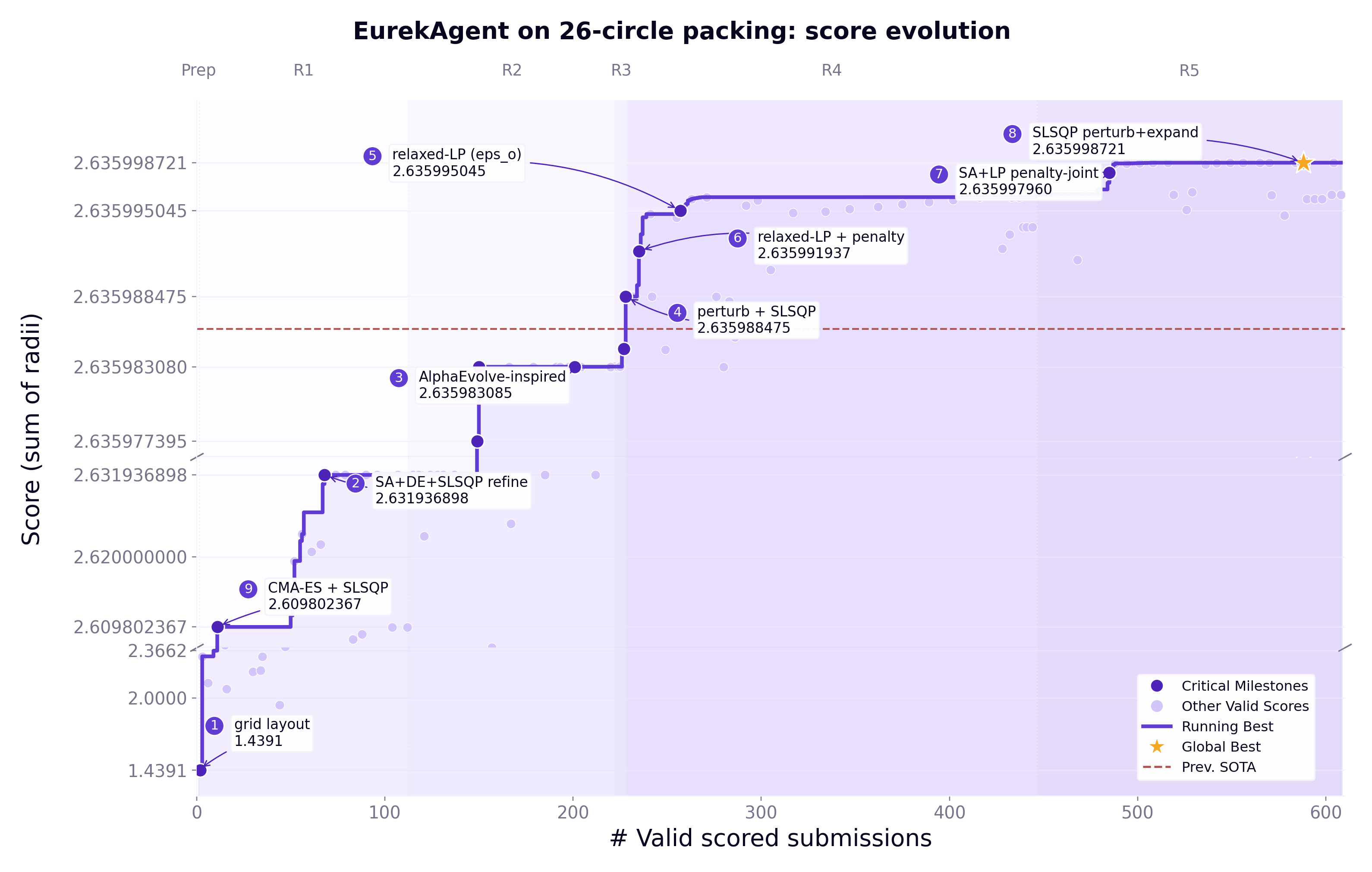
Fig 3 (page 1).

Fig 4 (page 1).
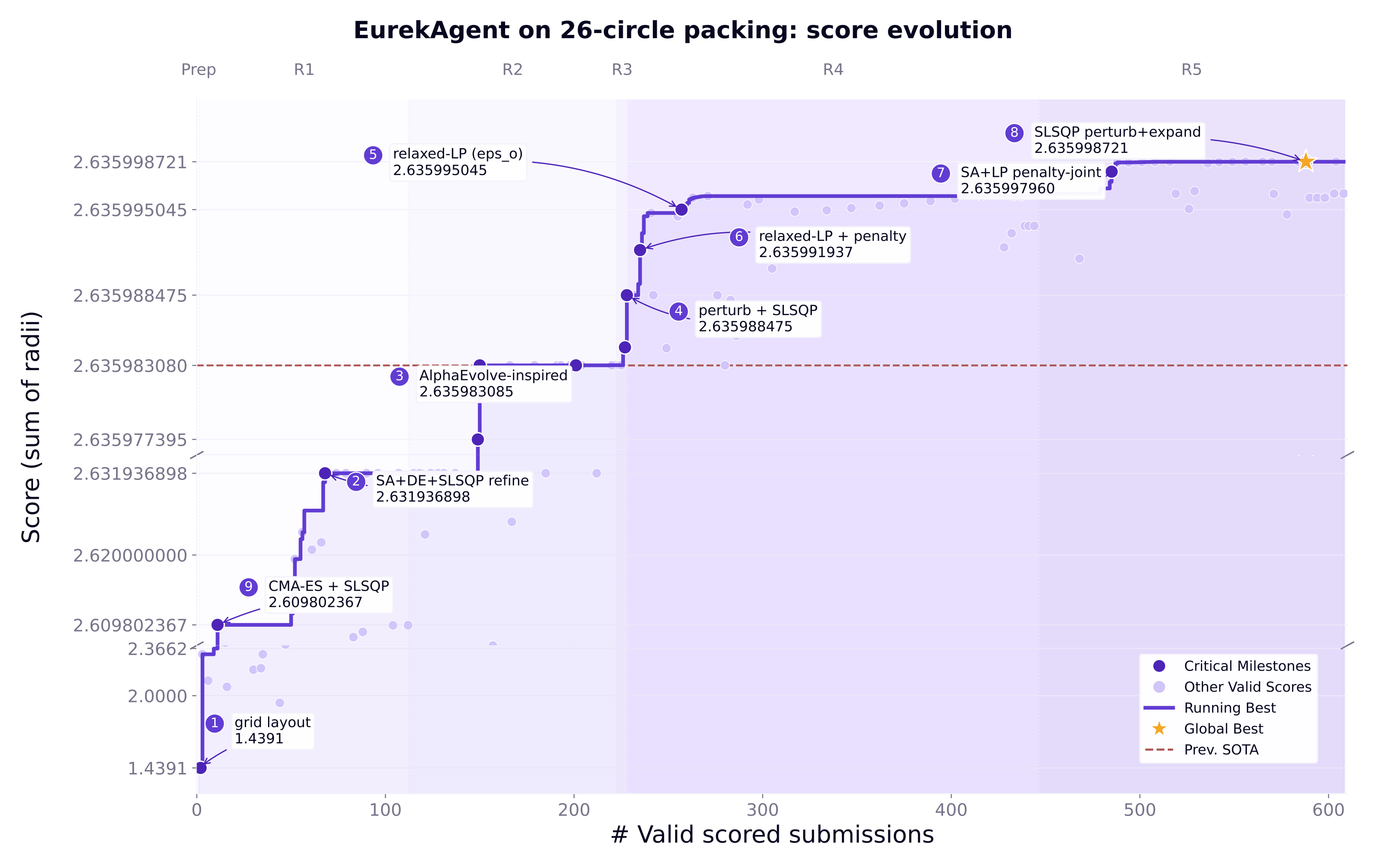
Fig 5 (page 1).

Fig 2: Overview of EUREKAGENT. Given task inputs and budgets, EUREKAGENT executes a

Fig 3: The EUREKAGENT web monitor interface. The monitor provides a user-friendly overview
Fig 8 (page 4).
Limitations
- Experiments focus on metric-driven tasks with executable evaluators; applicability to open-ended or qualitative scientific discovery untested.
- Relies on pre-existing capable base LLM agents (Claude Code, GLM-5.1); environment engineering complements but does not replace model capabilities.
- Kernel engineering evaluation performed locally due to closed official GPUMODE leaderboard, possibly limiting direct comparability.
- Human-in-the-loop intervention capabilities require expert users and may not scale to fully autonomous deployments.
- No explicit adversarial testing of environment robustness against sophisticated reward hacking or intentional protocol violations presented.
- Current system prioritizes single-agent generalist CLI agents over tightly coupled multi-agent coordination strategies.
Open questions / follow-ons
- How does environment engineering scale to broader, more open-ended scientific discovery domains beyond metric-driven tasks with executable evaluators?
- What are optimal permissions and artifact abstractions to balance agent creativity with research integrity in multi-agent collaborative scenarios?
- How effective are the proposed environment controls against adaptive or adversarial agents explicitly attempting to circumvent safeguards?
- Can environment engineering integrate with online learning or model adaptation (e.g. test-time training) to further accelerate discovery without sacrificing reliability?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, EurekAgent’s environment engineering approach offers key insights into designing secure, controlled agent environments that simultaneously encourage productive autonomous behavior while preventing manipulation and contamination. Analogous to how CAPTCHAs seek to allow legitimate human interaction while deterring bots, careful permissions and artifact controls can ensure that research agents cannot subvert evaluation protocols or abuse resource budgets. The system’s modular budget enforcement, sandboxing, and isolation strategies are applicable to managing large-scale agent populations in bot defenses. Furthermore, the emphasis on persistent, Git-tracked artifact management and human-in-the-loop supervision can inform frameworks for auditability and intervention in automated systems. While EurekAgent targets scientific discovery, its methodology illustrates how environment-level constraints, auditing, and resource accounting can augment underlying AI capabilities to achieve trustworthy autonomous workflows, a principle equally valuable in bot detection and CAPTCHA challenge design.
Cite
@article{arxiv2606_13662,
title={ EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery },
author={ Amy Xin and Jiening Siow and Junjie Wang and Zijun Yao and Fanjin Zhang and Jian Song and Lei Hou and Juanzi Li },
journal={arXiv preprint arXiv:2606.13662},
year={ 2026 },
url={https://arxiv.org/abs/2606.13662}
}