
EconCSLib: AI-Assisted Lean Formalization for Economics & Computation research
Source: arXiv:2606.13306 · Published 2026-06-11 · By Nikhil Garg
TL;DR
EconCSLib introduces a novel AI-assisted human-in-the-loop formalization system and Lean 4 library specialized for Economics and Computation research papers. The core problem addressed is the difficulty and tedium of formalizing complex applied math papers in a proof assistant like Lean, where human expertise and time are bottlenecks. This work leverages state-of-the-art large language models (LLMs) such as GPT 5.5 Pro to automate much of the translation and proof writing, while Lean’s typechecker guarantees formal correctness of proofs once encoded. Humans then verify that paper claims are faithfully translated into formal language using dedicated dashboards and LLM judge modules to minimize errors at the translation boundary.
EconCSLib organizes formalization around individual research papers, preserving paper statement structures with reusable libraries for core EconCS areas like probability, auctions, matching markets, and graph theory. This modular, author-facing workflow is designed to allow researchers to formalize their own work, inspect generated Lean code, and contribute reusable components back to the library. The current public repository contains 11 fully formalized and 3 partially formalized notable EconCS papers. While LLM-assisted formalization is effective and Lean proofs verify correctness automatically, the major bottleneck remains human validation of translation accuracy. The system also provides dependency DAGs, validation reports, and a UI dashboard to aid human review.
The results demonstrate that the human-AI-Lean workflow can produce extensive formalizations efficiently—papers of tens of thousands of lines of math have been encoded accurately under LLM guidance. Cost estimates of LLM usage are detailed, and lessons about common proof patterns, missing assumptions, and failure modes are reported. The paper situates EconCSLib in the broader landscape of AI-assisted autoformalization, showing it as one of the first targeted, author-driven formalization efforts in an applied theory domain.
Key findings
- The public EconCSLib repository contains 11 fully formalized EconCS papers and 3 partial formalizations.
- LLM (Codex GPT 5.5) assisted formalization costs about $200/month to complete one paper—roughly a week of usage.
- Formalized papers are large: e.g., LG21 (Test-optional Policies) has 125,476 lines of Lean code; GN22 (Driver Surge Pricing) has 142,131 lines.
- LLM-assisted formalizations correctly translate paper-facing statements to Lean with >90% agreement by LLM-as-judge checks (e.g., 30/32 matches for [DSWG25]).
- The main bottleneck is human verification of translation accuracy; human review is still sparse with only 10/17 statements reviewed for one paper (MBJG25).
- Reusable foundational libraries in EconCSLib have ~50K lines for probability/stochastic processes and ~12K for auctions/mechanisms.
- Formalization sometimes revealed implicit assumptions (e.g., bounding success probabilities away from 0 and 1 for variance proofs) not explicit in original papers.
- Dependency DAGs and validation reports help humans track formalization progress and intervene when LLM agents stall or diverge.
Threat model
The project does not address a security adversary per se but considers errors as potential "adversarial" failure modes—primarily, an untrusted LLM translator that may misinterpret or incorrectly translate informal paper claims into formal statements, leading to false proofs. The trusted Lean compiler kernel ensures soundness of formal proofs once stated. Humans assist in verifying that formal statements align with paper claims to mitigate translation errors. The adversary capability is bounded by inability to directly corrupt Lean verification; the main risk is semantic mismatch at the translation interface.
Methodology — deep read
Threat model & assumptions: The adversary is not explicitly a security actor but the main challenge is correctness threats arising from LLM mis-translation of paper statements to Lean and proof errors. Lean's trusted kernel guarantees soundness of proofs once coded; the main risk is semantic mismatches between informal claims and formal statements. Humans assist in verifying these translations, supported by automated LLM judge verification and dashboards.
Data: The data are math research papers in Economics and Computation, mostly well-known and classic papers (e.g., Gale-Shapley 1962, Roth 1982) and recent author coauthored papers. The public repository currently holds 14 formalizations: 11 full, 3 partial. Papers range widely in length and complexity, and cover topics like matching markets, auctions, mechanisms, recommendation fairness, and online algorithms. For formalization, paper LaTeX or PDFs are used as input.
Architecture & algorithm: EconCSLib has two Lean layers: a reusable core library with domain-specific math modules (probability, graphs, auctions, etc.), and paper-specific folders preserving original notation, results, and proofs. The formalization agent is a workflow using LLMs (Codex GPT 5.5) to extract paper statements, translate definitions and theorems into Lean functions, and generate Lean proofs following paper logic. Human-readable PaperInterface.lean files contain paper-facing statements without proofs to enable concise human translation validation.
Lean's typechecker provides proof verification. The system automatically generates DAGs representing theorem dependencies and validation reports capturing proof deviations or additional assumptions. An LLM-as-judge module translates Lean statements back to LaTeX and compares to paper statements for automated equivalence checking, flagging uncertain matches. A web dashboard displays original LaTeX, Lean statements, AI translations, and allows humans to verify matches and log judgments.
Training regime: Not applicable since this is a system/build paper; however, LLM prompting is done iteratively with human oversight, numerous sessions across multiple machines, with logging of tokens and costs. Skills and workflow markdown files collect lessons learned by agents to improve formalization over time. Agent reuses prior lemmas elevated to the common library. Refinements to skills target common proof strategy and translation patterns.
Evaluation protocol: Evaluation centers on successful Lean compilation without 'sorry' or 'admit' placeholders, correctness of formal proofs via Lean kernel, coverage of paper statements, human review of translation accuracy, and LLM-as-judge translation matching to paper claims. Quantitative metrics include lines of code, number of formalized lemmas/theorems, and human-verified translation match counts. Partial formalizations highlight missing dependencies (e.g., complexity theory libs).
Reproducibility: The entire system is publicly released at https://github.com/nikhgarg/EconCSLib with extensive documentation, scripts, and dashboards. The underlying LLM models and proof assistant are publicly accessible tools (Lean 4, Codex GPT 5.5), although computational expense and expert Lean knowledge limit wide reproducibility. Some datasets (papers) are publicly known research papers; formalizations serve as enduring artifacts.
Technical innovations
- A human-AI-Lean integrated workflow that leverages LLMs to write Lean formalizations, Lean to verify proofs, and humans to validate translation from paper statements to Lean.
- Paper-oriented organization preserving original paper statement structures and numbering, enabling author-facing review and modular reusable library components.
- Automated generation and maintenance of dependency DAGs and validation reports to assist formalization progress tracking and human intervention.
- LLM-as-judge module enables bidirectional translation validation by translating Lean statements back to LaTeX and comparing to paper text without paper context, flagging mismatches.
- Self-documenting agent 'skill' files that codify workflow best practices and proof patterns to improve formalization quality and automation over time.
Datasets
- 11 fully formalized EconCS papers — public academic EconCS research papers, size ranging from 600 to 142,000 lines of Lean code — available in EconCSLib repository
- 3 partial formalizations of classic EconCS papers — public academic EconCS papers — EconCSLib repository
Baselines vs proposed
- No explicit baseline comparison reported; evaluation is against LLM-assisted formalization correctness and human verification metrics.
- LLM-as-judge translation verification matches 100% of statements in some papers (e.g., 27/27 for Roth 1982) vs human review sparse but critical.
- Reusability: Common library components used by multiple papers (e.g., probability library used by 7 papers) versus stand-alone paper formalizations.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13306.
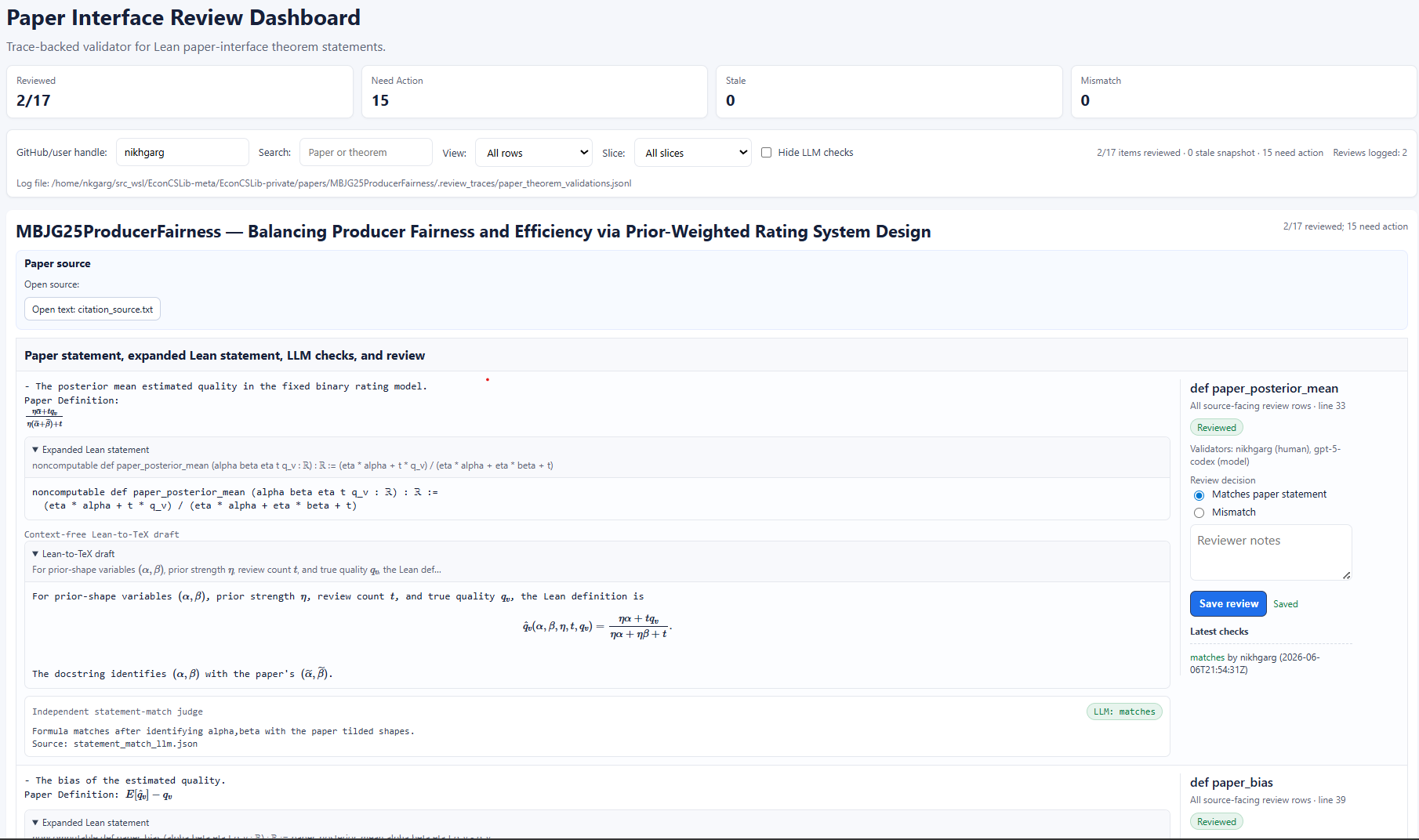
Fig 2: Screenshot of the paper-interface review dashboard for [MBJG25]. For each paper mathematical statement,
Limitations
- Human translation verification of paper-facing statements is a major bottleneck and remains incomplete for most formalizations.
- LLM agents occasionally stall or diverge by omitting implicit paper assumptions or struggling with non-pointwise measure-theoretic proofs.
- Parts of some formalizations require external libraries (e.g., computational complexity) not yet developed and out of scope for EconCSLib.
- Current automated LLM-as-judge validation is vulnerable to self-preferencing or correlated errors since same Codex agent generates and judges.
- Relies on expert users familiar with Lean to perform validation and intervene, limiting scalability and accessibility.
- High cost and computation expense for LLM usage may constrain adoption (e.g., $16K in approximate token costs logged over sessions).
Open questions / follow-ons
- How to scale and incentivize human verification of translation accuracy for large and complex papers effectively?
- How to robustly detect and handle implicit assumptions or omissions in original papers during formalization?
- What mechanisms can reduce correlated errors in LLM-as-judge verification to improve automated translation validation?
- How to extend EconCSLib infrastructure to support computational complexity and other currently missing subdomains for full formalization coverage?
Why it matters for bot defense
While EconCSLib focuses on formal verification of mathematical research rather than bot defense or CAPTCHAs directly, its methodology exemplifies how human-AI workflows aided by formal verification tools can critically improve correctness guarantees in complex domains. A bot-defense engineer might find inspiration in the human-in-the-loop validation dashboard and dependency DAGs as design principles for ensuring transparency and auditability of AI-driven decisions. The layered verification strategy—LLM generation, formal verification, and selective human review—could analogously inform CAPTCHA design approaches needing strong correctness confidence under adversarial uncertainty. Moreover, the use of LLM-as-judge modules demonstrates a practical technique for automating equivalence checks between informal inputs and formal system states, which can be adapted in security-critical AI system evaluations.
Cite
@article{arxiv2606_13306,
title={ EconCSLib: AI-Assisted Lean Formalization for Economics & Computation research },
author={ Nikhil Garg },
journal={arXiv preprint arXiv:2606.13306},
year={ 2026 },
url={https://arxiv.org/abs/2606.13306}
}