
Beyond Uniform Tokens: Adaptive Compression for Time Series Language Models
Source: arXiv:2606.13624 · Published 2026-06-11 · By Jialin Gan, Xin Qiu, Guangzhe Chen, Xue Wang
TL;DR
This paper addresses inefficiencies in large language model (LLM) architectures applied to time series (TS) data, particularly the uniform treatment of TS tokens and prompt tokens despite their differing information characteristics. The authors reveal that TS tokens exhibit highly uneven spectral contributions, with many tokens containing redundant frequency patterns and only a subset carrying critical temporal information. They also find that prompt tokens' influence decreases sharply with depth in the model, making full prompt token retention across layers unnecessary. To exploit these insights, they propose TokenDecouple, a novel adaptive token compression framework that merges TS tokens in the frequency domain by identifying and preserving critical spectral components while merging redundant ones, and applies a pyramidal decay scheme for prompt tokens across layers. Extensive experiments spanning forecasting, classification, imputation, anomaly detection, and reasoning-centric tasks across 27 datasets demonstrate that TokenDecouple achieves up to 7.68× inference speedup and improves or maintains task performance in about 78% of cases, strongly validating the asymmetric token compression approach for scalable TS foundation models.
Key findings
- TS tokens have highly uneven frequency-domain spectral contributions, with large groups sharing redundant frequency patterns and only small subsets carrying dominant temporal information.
- Prompt token influence exhibits a pyramidal decay, dropping to as low as 0.4% of original size by layer 5, demonstrating the redundancy of prompt tokens in deep layers.
- TokenDecouple’s frequency-based merging reduces TS token counts by 50% or more even on complex reasoning tasks, without degrading performance significantly.
- Applied to four advanced LLM-based TS models (OFA, TimeLLM, CALF, S2IP), TokenDecouple improves performance in 76% of pattern-centric and 71% of reasoning-centric task cases.
- Inference speedups average 3.43× to 7.68× across models and tasks, with TimeLLM gaining the highest 7.68× speedup due to token reduction.
- Compared to prior token-merging approaches (global, local, dynamic), TokenDecouple preserves better task accuracy while achieving substantially higher speedups (4.55× vs 1.2–2.2×).
- Prompt token count reduction reaches about 89% overhead reduction at 12 layers, rising to 94% at 24 layers.
- Performance degradation when it occurs is minor, e.g., max MAE increase 0.01 (5%) for forecasting, max accuracy drop 3.2% for reasoning.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly modeled as this work focuses on model efficiency and compression rather than adversarial robustness or security. The assumption is that TS tokens and prompt tokens have distinct information structures and redundant representation that can be compressed.
Data: The study uses 27 publicly sourced real-world TS datasets across diverse domains (climate, energy, transportation, physiology, speech, cybersecurity, and industrial monitoring). Tasks include imputation, classification, anomaly detection, forecasting (pattern-centric), and reasoning tasks with varying difficulty. Masks for imputation and multiple prediction horizons for forecasting are used to control task difficulty.
Architecture / Algorithm: TokenDecouple consists of two main components: (a) TS token merging via frequency-domain analysis; (b) prompt token compression using a pyramidal decay scheme across model layers.
- TS tokens X are converted from time-domain to frequency-domain via discrete Fourier transform (DFT).
- Tokens are sorted by spectral magnitude per frequency band and only a minimal subset capturing ≥95% energy is selected as 'active tokens.'
- Spectral identifiability is quantified using Fisher information from the local Whittle likelihood to guide adaptive merging ratio per frequency.
- Token merging is constrained locally by affinity graphs built on spectral similarity with neighborhood constraints, resulting in merged representative frequency tokens.
- The inverse DFT recovers compressed TS tokens in time domain.
- Prompt tokens are compressed aggressively layer-wise by 75% reductions per layer (1.0 → 0.25 → 0.063 → …), guided by observed pyramidal decay of prompt influence, combined with residual global summary token pooling.
Training Regime: Experiments use four recent LLM-based TS analysis models (OFA, TimeLLM, CALF, S2IP) spanning distinct TS-text alignment methods. Training specifics (epochs, batch size, optimizers) are derived from original model papers. The paper mainly focuses on inference efficiency and performance rather than retraining from scratch.
Evaluation Protocol: Multi-task evaluation over 7 TS subtasks grouped into pattern-centric and reasoning-centric categories, using task-relevant metrics (MSE, MAE, accuracy, F1-score). Each task includes multiple datasets and experiments controlling difficulty via masking or prediction horizon. Comparisons against original uncompressed models and three token merging baselines (global, local, dynamic) measure task effectiveness and inference speed. Ablation studies isolate impact of prompt compression and TS merging. Robustness tested under injected noise with varying SNR.
Reproducibility: Code and dataset details are not explicitly mentioned, but 27 public datasets and four known LLM-based TS models are employed. Frequency merging and pyramidal decay algorithms are described in detail for implementation. Some baselines reference recent literature.
Example Workflow: Given input TS tokens, compute their frequency components via DFT, estimate spectral contributions and token identifiability, select active tokens, adaptively merge tokens under similarity constraints, then inverse-transform to the compressed token sequence. Concurrently, compress prompt tokens layer by layer by reducing their count to 25% per successive layer with residual pooling to maintain global context. Feed compressed tokens to the LLM backbone and evaluate task outputs against original models.
Technical innovations
- First systematic frequency-domain analysis of TS tokens in LLM-based models revealing uneven spectral contributions.
- Adaptive frequency-based TS token merging guided by Fisher information-based spectral identifiability, enabling selective preservation of critical tokens.
- Pyramidal decay compression scheme for prompt tokens across model layers exploiting fast attenuation of prompt influence.
- TokenDecouple framework decoupling TS and prompt token compression to maximize efficiency without performance loss.
Datasets
- 27 real-world datasets across climate, energy, transportation, economics, physiology, chemistry, speech, machine monitoring, cybersecurity, industrial systems — publicly sourced
Baselines vs proposed
- Global token merging: average speedup = 1.2× vs TokenDecouple = 4.55× with better performance retention
- Local token merging: average speedup = 2.2× vs TokenDecouple = 4.55×
- Dynamic token merging: average speedup = 1.9× vs TokenDecouple = 4.55×
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13624.
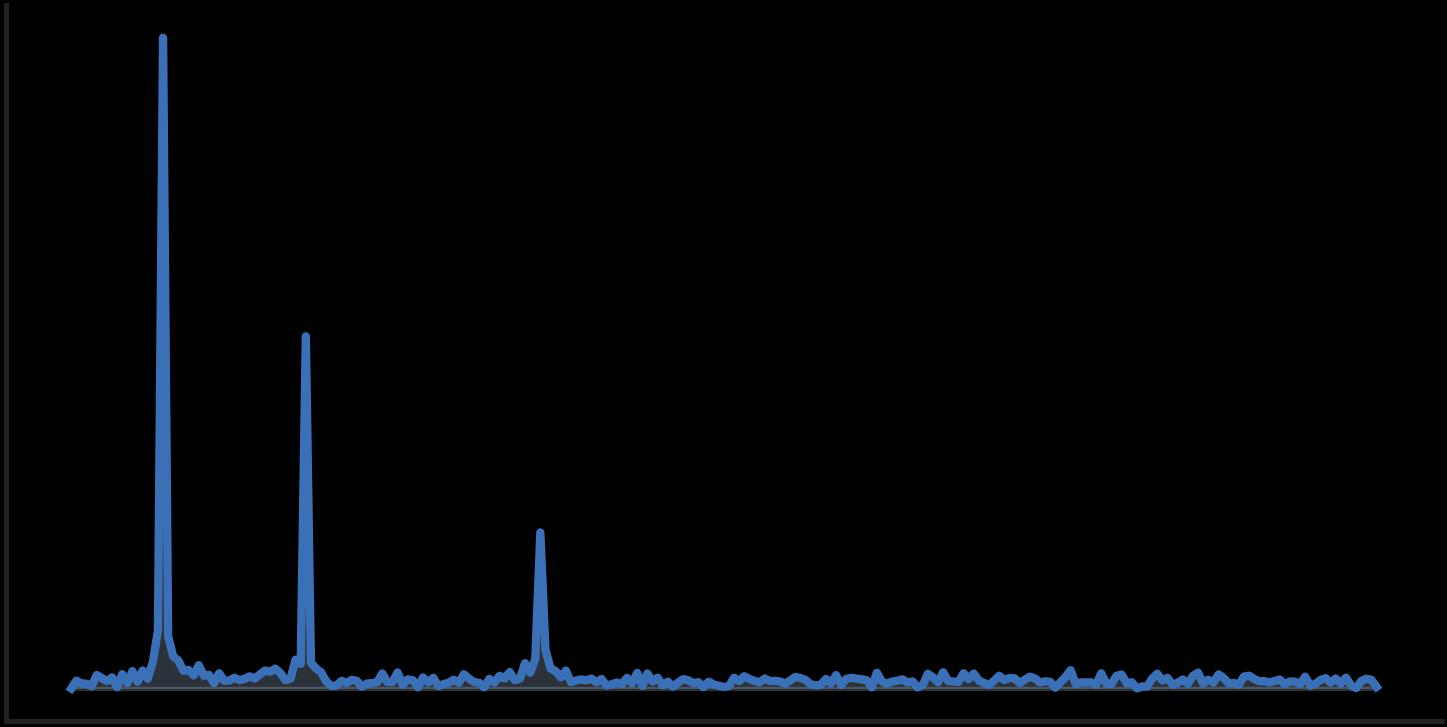
Fig 1: Overview of TokenDecouple. We decouple token compression for TS and prompt tokens by merging
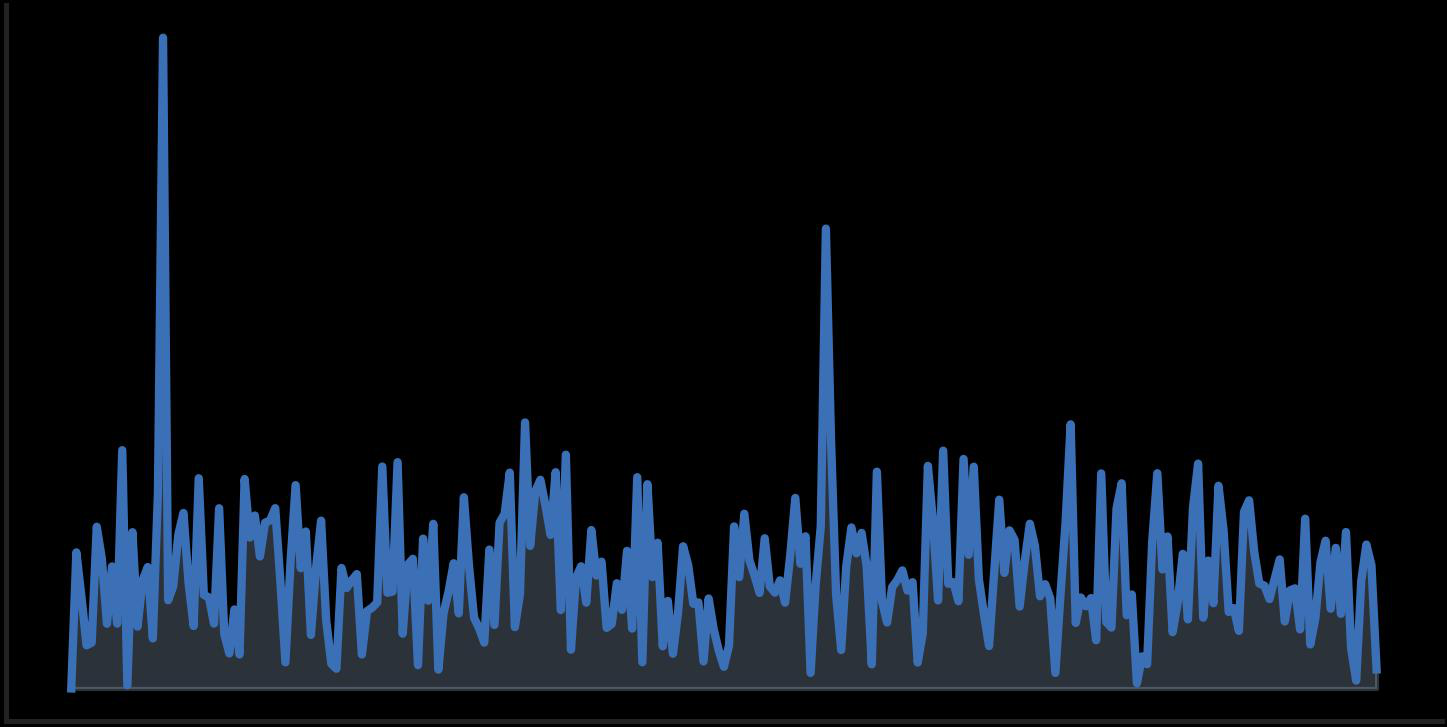
Fig 2: The complex TS appears entangled in the
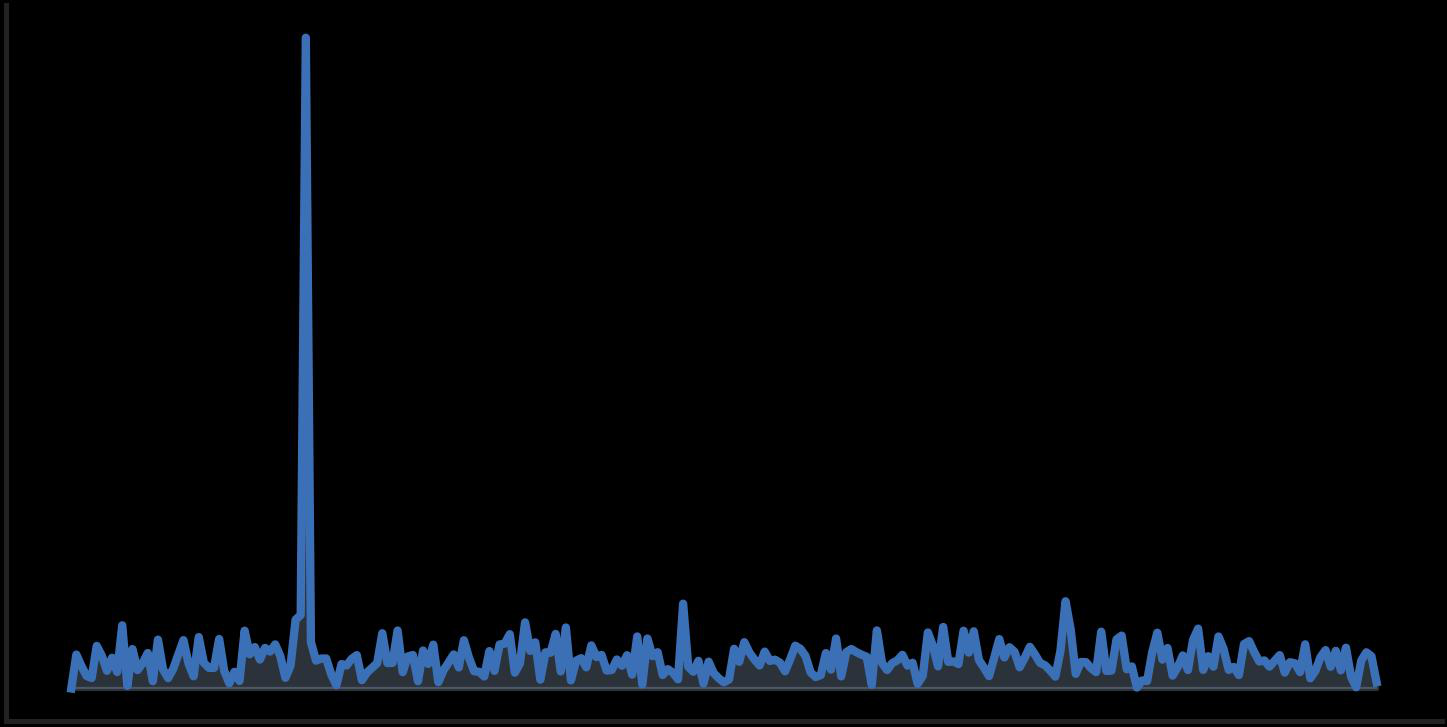
Fig 3 (page 3).
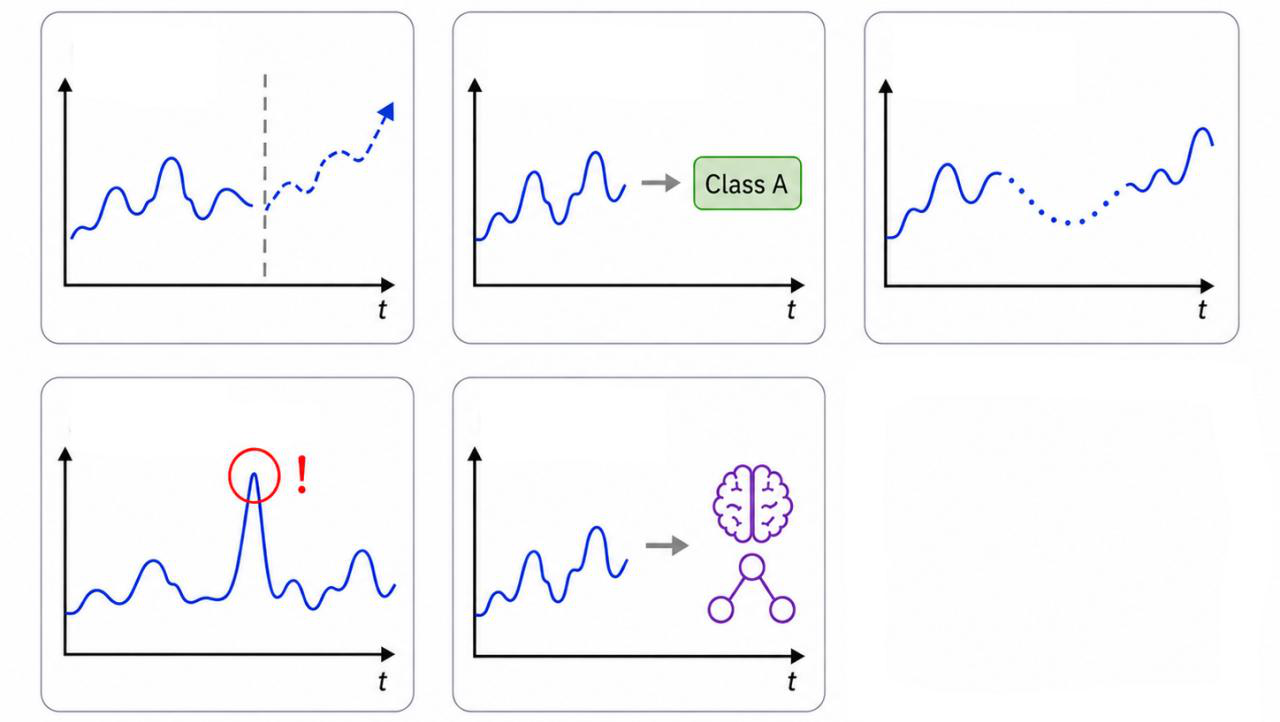
Fig 4 (page 3).
Fig 5 (page 3).

Fig 8: Layer-wise Prompt Contribution Ratio over
Limitations
- Not evaluated on highly non-stationary or irregularly sampled time series common in some real-world scenarios.
- Robustness to extreme noise or rapidly evolving time series distributions remains unclear beyond limited SNR noise injection tests.
- Focuses on token-level compression during inference without integration or evaluation alongside other efficiency optimizations like pruning or quantization.
- Effectiveness and scalability on extremely large-scale LLMs or in strict resource-constrained settings are not assessed.
- Does not address security or adversarial robustness of the compressed token representations.
Open questions / follow-ons
- How effective is frequency-domain token merging under non-stationary or irregular TS sampling conditions?
- Can TokenDecouple be synergistically combined with pruning, quantization, or other model-level accelerations for cumulative efficiency gains?
- How does token compression affect robustness and interpretability under adversarial attacks or anomalous inputs?
- What is the impact of token compression on online or continual learning scenarios with streaming TS data?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners leveraging LLMs for time series analysis, this work highlights the importance of considering the distinct informational roles of TS versus prompt tokens. The asymmetric frequency-domain token compression approach improves inference efficiency drastically while preserving downstream task accuracy, valuable in scenarios demanding low-latency real-time TS signal understanding, such as behavioral biometrics or sensor data validation. Incorporating a frequency-domain perspective may enable more scalable TS-language model deployments for anomaly detection or reasoning tasks relevant to bot detection pipelines. The progressive prompt token compression also suggests that prompt design can be optimized layer-wise to reduce overhead without compromising model guidance, which could inform prompt engineering for TS-aware LLMs in security contexts. However, one should consider the limitations around non-stationary or irregular TS data often occurring in the wild, which may require further robustness evaluation before applying such compression techniques in sensitive security environments.
Cite
@article{arxiv2606_13624,
title={ Beyond Uniform Tokens: Adaptive Compression for Time Series Language Models },
author={ Jialin Gan and Xin Qiu and Guangzhe Chen and Xue Wang },
journal={arXiv preprint arXiv:2606.13624},
year={ 2026 },
url={https://arxiv.org/abs/2606.13624}
}