
Automated reproducibility assessments in the social and behavioral sciences using large language models
Source: arXiv:2606.13670 · Published 2026-06-11 · By Tobias Holtdirk, Pietro Marcolongo, Anna Steinberg Schulten, Felix Henninger, Stefan Rose, Sarah Ball et al.
TL;DR
This paper addresses the challenge of scaling reproducibility assessments in the social and behavioral sciences, where conventional approaches rely on independent human reanalysts to manually reconstruct and verify original study findings—an expensive and time-consuming process. The authors investigate whether large language models (LLMs), specifically Claude Opus 4.7, can automate this reproducibility evaluation by independently analyzing raw datasets paired with published claims and manuscripts. Using a corpus of 76 studies from the Multi100 project, they task the LLM to generate, execute, and interpret statistical code aimed at reproducing the original results without access to the original analysis code. Their pipeline successfully recovered the original effect sizes within a ±0.05 tolerance in Cohen’s d for 41% of evaluated studies and matched the published qualitative conclusions (supports/opposite/inconclusive) in 96% of cases. Comparatively, prior human reanalysts achieved 34% effect size recovery and 74% conclusion concordance on the same dataset. These findings suggest LLMs can serve as scalable, first-pass reproducibility auditors, reducing human workload and enabling systematic auditing across large literatures.
Key findings
- LLM pipeline recovered original standardized effect sizes within ±0.05 Cohen’s d in 41% of 69 analyzed studies.
- LLM qualitative conclusion matched original study claim in 96% of cases, versus 74% for human analysts.
- 7 out of 76 studies could not yield a valid effect size from any of the LLM’s 5 independent runs and were excluded.
- LLM effect sizes correlated weakly with original effect sizes (r=0.10) and with human reanalysis effect sizes (r=0.11), indicating substantial variation in continuous estimates.
- LLM recovered effect sizes within ±0.05 Cohen’s d of human reanalysis effect sizes in 29% of studies.
- LLM analyses involved 5 independent code-writing runs per study to capture variance and select majority vote conclusions.
- The LLM was never provided original analysis scripts but only raw data, claims, and optionally paper text, enforcing independent code generation.
- Selection limited to studies from economics, political science, and psychology (2009–2018) with available data, totaling 76 of 100 Multi100 project studies.
Threat model
The adversary considered is not an attacker but an automated agent (LLM) tasked with independently reproducing published empirical claims from provided datasets and manuscripts without access to original code or external metadata. It cannot consult additional external resources or the original analysts. The challenge lies in overcoming underspecified analytical choices and avoiding errors in code generation rather than resisting malicious inputs.
Methodology — deep read
Threat model & assumptions: The adversary is implicit—aiming to automate reproducibility checks rather than defend against malicious attacks. The LLM is assumed to have access only to the original datasets, the paper’s claims, and the full text (including methods). The adversary cannot access original analysis scripts or external metadata beyond the provided inputs. The system assumes availability of raw data and paper text, but no ground-truth code, requiring independent specification of analyses.
Data provenance and preprocessing: The evaluation corpus is composed of 76 published empirical studies from the Multi100 reanalysis project, spanning psychology, political science, and economics, published between 2009 and 2018. Studies lacking accessible data were excluded. Each study package includes the original dataset (in various formats), the published statistical claim, metadata, and a Markdown-version full text extracted by OCR (Mistral OCR). Data preprocessing involves automatic loading via scientific libraries, with no manual curation reported beyond file format handling.
Architecture / algorithm: The system frames the LLM (Claude Opus 4.7) as an 'agentic analyst' that autonomously writes and executes statistical code based on the input data and claim. It uses a ReAct-style reasoning framework with access to a Python interpreter, bash shell, and a 'think' tool for intermediate reasoning. The Python environment has preinstalled common scientific/statistical packages (e.g., pandas, numpy, scipy, statsmodels). Each run involves generating complete, self-contained scripts to extract appropriate statistics most directly tied to the claim (e.g., t, F, z, χ2, r) and convert them into Cohen’s d for comparability.
Training regime: The LLM is an off-the-shelf model (Claude Opus 4.7) with no retraining, fine-tuning, or hyperparameter tuning for this task. Decoding parameters were default (temperature 1.0, top-p 1.0), with five independent runs per study to capture stochastic variation and produce majority vote results. Each run is limited to 100 messages or a $5 API usage cap.
Evaluation protocol: Effect sizes extracted from the LLM-generated analyses are converted to Cohen’s d and aggregated across runs per study. Comparisons are made against original published effect sizes and human reanalysis distributions from Multi100. Key metrics are effect-size recovery rate within tight (±0.05) and looser (±0.20) Cohen’s d tolerances and qualitative conclusion agreement (supports, opposite, inconclusive). Statistical correlations (Pearson’s r) between LLM and benchmark effect sizes were computed. Studies for which LLM runs failed to produce valid effect sizes were excluded. No explicit cross-validation or adversarial testing was reported.
Reproducibility: The authors provide detailed prompt configurations, code execution framework, and toolchain descriptions. The dataset (Multi100) is publicly available via OSF. The LLM model weights are closed (Claude Opus 4.7). The study relies on publicly accessible open datasets and detailed reporting but does not release frozen checkpoints or modified models. The evaluation code and pipeline details appear to be documented, enabling partial reproducibility of the workflow.
One concrete example end-to-end: For a given published study, the system receives the study’s raw data files, a formatted textual claim (e.g., 'X increases Y'), and the Markdown of the full article. The LLM agent initializes a fresh sandbox, loads data using pandas or other format readers, parses the claim and methods to define variables and model specification, generates Python code to test the claim statistically (e.g., computing a t-test or regression coefficient), and executes it to obtain test statistics. It converts these results into Cohen’s d, logs intermediate reasoning via the ’think’ tool, and submits a structured JSON report containing numerical results and qualitative conclusions. Five independent runs produce effect size averages and majority vote conclusions to compare against the published and human benchmark results.
Technical innovations
- Use of an agentic LLM workflow combining ReAct prompting with sandboxed code execution to autonomously generate and run reproducibility analyses from raw data and paper text.
- Framing reproducibility assessment as an automated code-writing, execution, and interpretation task without access to original analysis scripts, relying solely on provided study materials and claims.
- Aggregation of multiple independent LLM runs per study and application of standardized effect size transformations (to Cohen’s d) enabling quantitative benchmarking against original and human-reanalyzed results.
- Implementation of a versatile multi-tool environment (Python interpreter, bash shell, internal 'think' tool) allowing the LLM to iteratively reason, script, run code, and self-correct during reproducibility assessments.
Datasets
- Multi100 dataset — 76 studies with accessible original data from economics, political science, and psychology — publicly available at https://osf.io/mkwhn
Baselines vs proposed
- Human reanalysis (Multi100): Effect size recovery within ±0.05 Cohen’s d = 34% vs LLM: 41%
- Human reanalysis: Qualitative conclusion match = 74% vs LLM: 96%
- LLM effect sizes within ±0.05 Cohen’s d of human reanalysis effect sizes: 29%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13670.
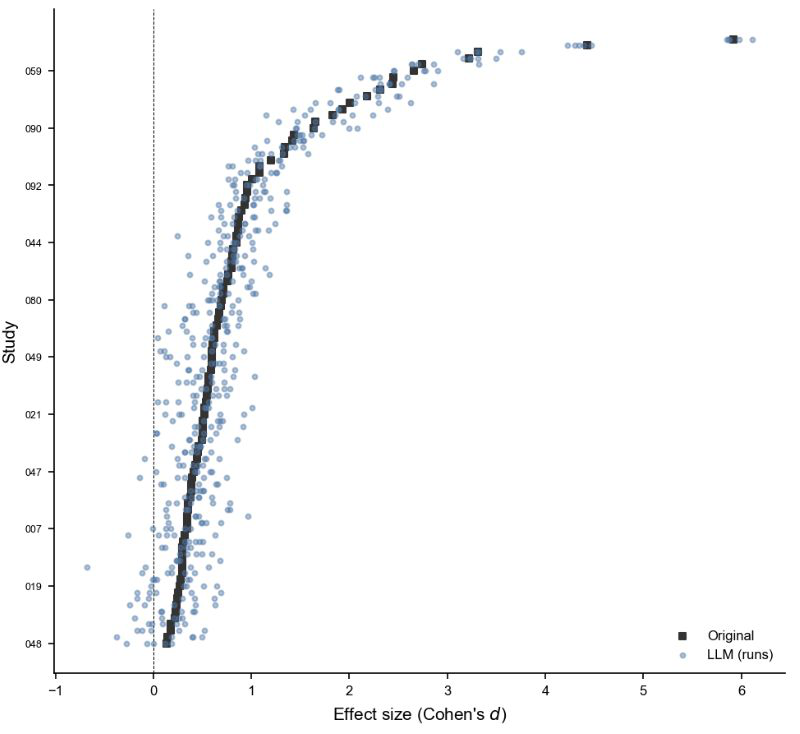
Fig 1: Automated reproducibility workflow using LLMs. a, A corpus of published stud-

Fig 2: Automated reproducibility assessment (using Claude Opus 4.7). a. Effect size of

Fig 3 (page 5).

Fig 4 (page 5).

Fig 5 (page 5).

Fig 6 (page 5).
Limitations
- Potential training data contamination as some studies predate the LLM’s data cutoff, possibly inflating reproducibility performance.
- LLM-generated code can contain errors or misinterpretations, and the approach conflates legitimate analytic variation with errors in causal under-specification.
- Corpus limited to published studies with accessible data from selected disciplines and years (2009–2018), limiting generalizability to recent or less open domains.
- Standardization to Cohen’s d assumes homogeneity in effect size conversion that may not hold across diverse statistical models or measurement types, reducing precision.
- The approach assesses computational reproducibility from original data, but does not address replication or generalizability to new samples.
- The tool's stochastic outputs and lack of explicit adversarial evaluation mean some results may vary between runs or under challenging study designs.
Open questions / follow-ons
- How can automated reproducibility systems better distinguish between legitimate analytical flexibility and true errors or irreproducible results?
- What are the effects of incorporating domain-specific knowledge or expert-in-the-loop feedback on LLM-assisted reproducibility accuracy?
- Can this approach extend to other scientific disciplines with different data types, analysis methods, or data-sharing cultures?
- What impact would fine-tuning or training on reproducibility-specific code corpora have on LLM performance and reliability in this task?
Why it matters for bot defense
While this work focuses on scientific reproducibility in social and behavioral sciences, the core insight—that advanced LLMs can autonomously parse, code, and validate complex datasets given natural language claims—provides useful parallels for bot-defense and captcha developers. Automating the interpretation of challenging structured inputs into executable analyses suggests LLMs could similarly analyze suspicious interaction patterns or human responses. However, limitations around code generation errors, ambiguity in natural language instructions, and stochastic outputs highlight the need for careful human oversight and robust safety checks. Practitioners aiming to harness LLMs for automated validation or anomaly detection in bot defense might adopt multi-run majority voting and standardized metrics analogous to effect size recovery as reliability guards. Moreover, this study underscores the promise and perils of replacing resource-intensive manual verifications with AI-driven scalable audits, a tradeoff relevant to too-good-to-be-true bot filtering tactics and CAPTCHA robustness evaluation.
Cite
@article{arxiv2606_13670,
title={ Automated reproducibility assessments in the social and behavioral sciences using large language models },
author={ Tobias Holtdirk and Pietro Marcolongo and Anna Steinberg Schulten and Felix Henninger and Stefan Rose and Sarah Ball and Bolei Ma and Frauke Kreuter and Markus Weinmann and Stefan Feuerriegel },
journal={arXiv preprint arXiv:2606.13670},
year={ 2026 },
url={https://arxiv.org/abs/2606.13670}
}